近年来,随着深度学习技术的快速发展,基于AI的超分辨技术在图像恢复和图像增强领域呈现出广阔的应用前景,受到了学术界和工业界的关注和重视。但是,在RTC视频领域中,很多AI算法并不能满足实际场景下的应用需求。本文将着眼于AI技术从研究到部署的落地问题,分享超分辨技术在RTC领域落地应用所面临的机遇与挑战。
作者:袁振 网易云信音视频算法工程师
一、超分辨技术概述
1. 超分辨技术的提出


超分辨这一概念较早是在20世纪60年代由Harris和Goodman提出的,是指从低分辨率图像,通过某种算法或模型生成高分辨图像的技术,并且尽可能地恢复出更多细节信息,也称为频谱外推法。但是在研究初期,频谱外推法只是用于一些假设条件下的仿真,并没有得到广泛的认可;直到单张图像的超分辨方法提出后,超分辨技术才开始得到广泛的研究和应用。目前,它已经成为图像增强乃至计算机视觉领域的重要研究方向。
2.超分辨技术的分类

单张图像的超分辨方法根据原理不同,可以分为基于插值、基于重构和基于学习的方法。前面两种方法分别由于算法原理简单以及应用场景受限,在实际场景中的超分辨效果并不理想;基于学习的方法,是实际效果较好的超分辨方法,其核心包括两个部分:算法模型的建立,以及训练集的选取。根据算法模型和训练集,基于学习的方法又可以分为传统学习方法和深度学习方法。一般来说,传统学习方法的算法模型比较简单,训练集也比较小。深度学习方法一般是指采用大量数据训练的卷积神经网络方法,也是目前学术界研究的热点。因此接下来我将重点介绍基于深度学习的超分辨方法的发展过程。
3. DL-based SR

SRCNN是深度学习方法在超分辨问题的首次尝试,是一个比较简单的卷积网络,由3个卷积层构成,每个卷积层负责不同的职能。名列前茅个卷积层的作用主要是负责提取高频特征,第二个卷积层则负责完成从低清特征到高清特征的非线性映射,最后一个卷积层的作用是重建出高分辨率的图像。SRCNN的网络结构比较简单,超分辨效果也有待改善,不过它确立了深度学习方法在处理超分辨这类问题时的基本思想。后来的深度学习方法,基本都遵循这一思想去进行超分辨的重建。
后来的 ESPCN、FSRCNN等网络基于SRCNN进行了一些改进,网络层数仍然比较浅,卷积层数不会超过10,超分辨的效果也不是特别理想。因为在当时,深度卷积网络的训练是存在问题的。一般对于卷积神经网络来说,当网络层数增加的时候,性能也会增加,但在实际应用中,人们发现当网络层数增加到了一定程度,由于反向传播原理,就会出现梯度消失的问题,导致网络收敛性变差,模型性能降低。这个问题直到ResNet提出残差网络结构之后,才得到比较好的解决。
VDSR是残差网络以及残差学习思想在超分辨问题上的首次应用,将超分辨网络的层数首次增加到了20层,优点是利用残差学习的方式,直接学习残差特征,网络收敛会比较快,超分辨效果也更好。后来一些卷积神经网络提出了更复杂的结构, 比如SRGAN提出使用生成式对抗网络来生成高分辨的图像,SRGAN由2部分组成,一个是生成网络,另一个是判别网络。生成网络的作用是根据一张低分辨率的图像来生成一张高分辨的图像,而判别网络的作用是将生成网络生成的高分辨图像判定为假,这样网络在训练的时候,生成网络和判定网络两者之间不断博弈,最终达到平衡,从而生成细节纹理比较逼真的高分辨图像,具有更好的主观视觉效果。其他深度卷积网络方法比如SRDenseNet、EDSR、RDN,使用了更复杂的网络结构,网络的卷积层越来越深,在单张图像上的超分辨效果也越来越好。

超分辨技术发展的总体趋势,基本上可以概括为从传统方法,到深度学习方法,从简单的卷积网络方法到深度残差网络方法。在这个过程中,超分辨模型结构越来越复杂,网络层次越来越深,单张图像的超分辨效果也越来越好,不过这也会有一定的问题。
二、实时视频任务的需求与SR的挑战

在RTC领域,对于视频处理任务来说,大多是直播和会议等即时通信场景,对算法的实时性要求比较高,所以视频处理算法的实时性是优先考虑的。然后是算法的实用性,由于用户在使用直播或会议时,摄像头采集到的视频质量有时比较低下,可能包含很多噪点;另外视频在编码传输时会先进行压缩,压缩的过程也会导致图像画质退化,所以RTC实际应用场景比较复杂,而很多视频处理方法,比如超分辨算法在研究中的是比较理想的场景。最后,如何提升用户尤其是移动端用户的体验,减少算法的计算资源占用,适用更多终端和设备,也是视频任务所必须考虑的。
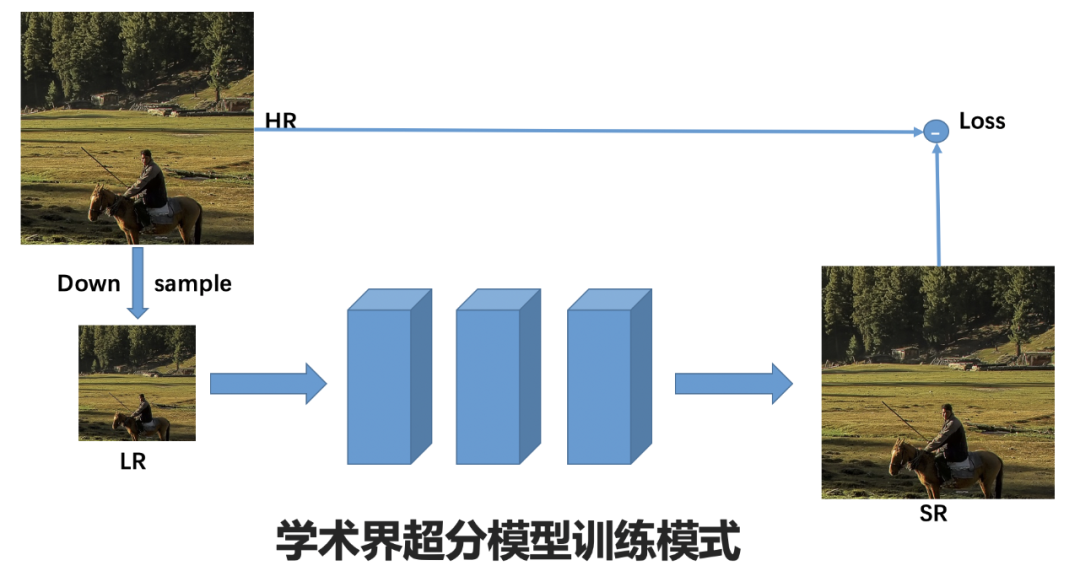
对于这些需求,目前的超分辨方法尤其是基于深度学习的超分辨方法是存在很多问题的。目前学术界关于超分辨的研究大多还是局限在理论阶段,图像超分,尤其是视频超分如果要大规模落地的话,必须要去解决一些实际问题。首先是网络模型的问题,目前很多深度学习方法为了追求更好的超分辨效果,采用的模型规模比较庞大,参数量越来越多,会耗费大量的计算资源,在很多实际场景无法实时处理。其次是深度学习模型的泛化能力问题,对于各种深度学习模型来说,都会存在训练集适配的问题,在训练的时候所使用的训练集不同,在不同场景上的表现也不同,用公开数据集训练的模型,在实际应用场景中未必会有同样良好的表现。最后是真实场景下超分效果的问题,目前学术界的超分方法,大都是关于比较理想的场景,完成从下采样图像到高分辨图像的重建,但在真实场景中,图像退化不仅包括下采样因素,还会有很多其他因素,比如图像压缩、噪点、模糊等。
综上而言,目前基于AI的超分辨方法,在RTC视频任务中,所面临的主要挑战可以概括为,如何凭借规模比较小的网络来实现具有良好真实效果的视频质量增强,也就是怎么样“既叫马儿跑得快,又让马儿少吃草”。
三、视频超分辨技术的发展方向
首先,深度学习方法依然会是超分辨算法的主流。
因为传统的方法在超分辨任务上的效果不够理想,细节比较差。深度学习方法为超分辨提供了一条新的思路。近年来基于卷积神经网络的超分辨方法,逐渐成为主流方法,效果也在不断改善。
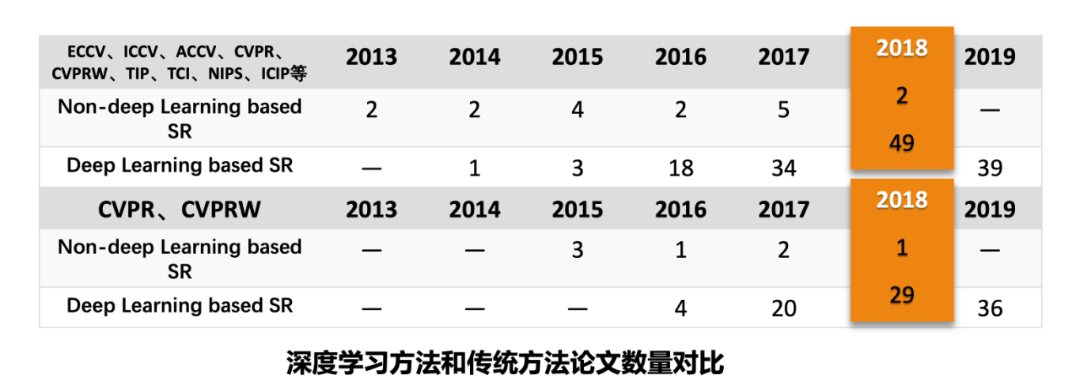
从上图可以看到,近几年来,基于AI的超分辨方法相对于传统方法的论文数量呈现出一边倒的局面,并且这种局面在未来几年还会进一步扩大。因为虽然存在一些问题,但随着一些轻量级网络的出现,深度学习方法将来在落地应用方面可能会有更大的突破,这些问题也将会得以解决,深度学习方法依然会是超分辨的主流研究方向。
其次,一些参数较小的轻量级网络,在推动超分算法落地方面,会发挥更大的作用。
因为目前各种深度卷积网络方法,比如EDSR、RDN这类深度残差网络难以满足视频实时传输的需要,一些比较小的轻量级网络对于实时任务会有更好的效果。
第三,将来的超分辨方法会更加聚焦真实场景任务。
学术领域的SR方法多是针对下采样问题进行超分,在真实场景下的表现并不是很好,在真实场景中,图像退化因素是各种各样的,一些比较有针对性的方法,比如包含压缩损失、编码损失以及各种噪声的超分辨任务,可能会更加实用。
四、网易云信AI超分算法
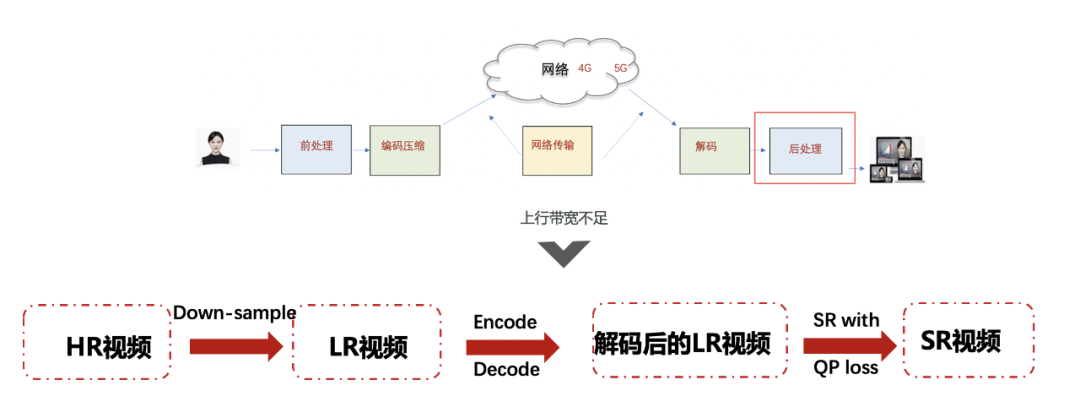
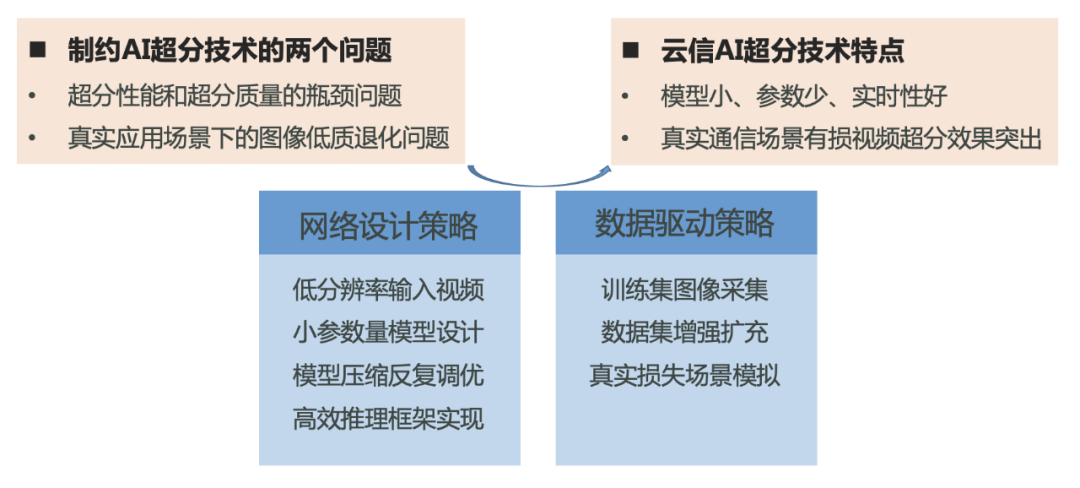
在RTC领域中,由于视频文件过于庞大,我们需要对其进行编码,然后再传输到接收端解码播放。由于编码的本质是对视频的压缩,当网络比较差时,编码量化参数会比较大,会造成严重的压缩,导致输出图像产生块效应和其他失真,造成画质模糊。这种情况下,如果直接将解码后的视频进行超分,压缩损失也会被放大,超分效果往往不够理想。针对这些问题,网易云信提出了基于编码损失复原的视频超分辨方法,采用数据驱动和网络设计并重的策略,通过数据处理模拟真实失真场景,并且从模型设计到工程化实现进行层层优化,对于制约AI超分技术的两大问题有了一定的突破,在模型实时性和真实场景超分效果方面取得了不错的效果。
以上就是网易云信在推进AI驱动的超分技术落地应用方面的一些实践经验,希望对大家有所启发和参考。
文章包含AI辅助创作:AI 驱动的超分辨技术落地实践,发布者:网易智企,转载请注明出处:https://worktile.com/kb/p/6049
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 