在 IM 场景的客户端需求上,基于本地数据的全文检索(Full-text search)扮演着重要的角色。所谓全文检索,就是要在大量文档中找到包含某个单词出现位置的技术。
作者介绍:李宁 网易云信高级前端开发工程师
一、前言
在以往的关系型数据库中,只能通过 LIKE 来实现,这样有几个弊端:
- 无法使用数据库索引,需要遍历全表,性能较差
- 搜索效果差,只能首尾位模糊匹配,无法实现复杂的搜索需求
- 无法得到文档与搜索条件的相关性
在网易云信 IM 的 iOS、安卓以及桌面端中都实现了基于 SQLite 等库的本地数据全文检索功能,但是在 Web 端和 Electron 上缺少了这部分功能。在 Web 端,由于浏览器环境限制,能使用的本地存储数据库只有 IndexDB,暂不在讨论的范围内。在 Electron 上,虽然也是内置了 Chromium 的内核,但是因为可以使用 Node.js 的能力,于是乎选择的范围就多了一些。
我们先来具体看下该如何实现全文检索。
二、基础技术知识点
要实现全文检索,离不开以下两个知识点:
这两个技术是实现全文检索的技术以及难点,其实现的过程相对比较复杂,再聊全文索引的实现前,我们先来具体聊一下这两个技术的实现。
(一)倒排索引
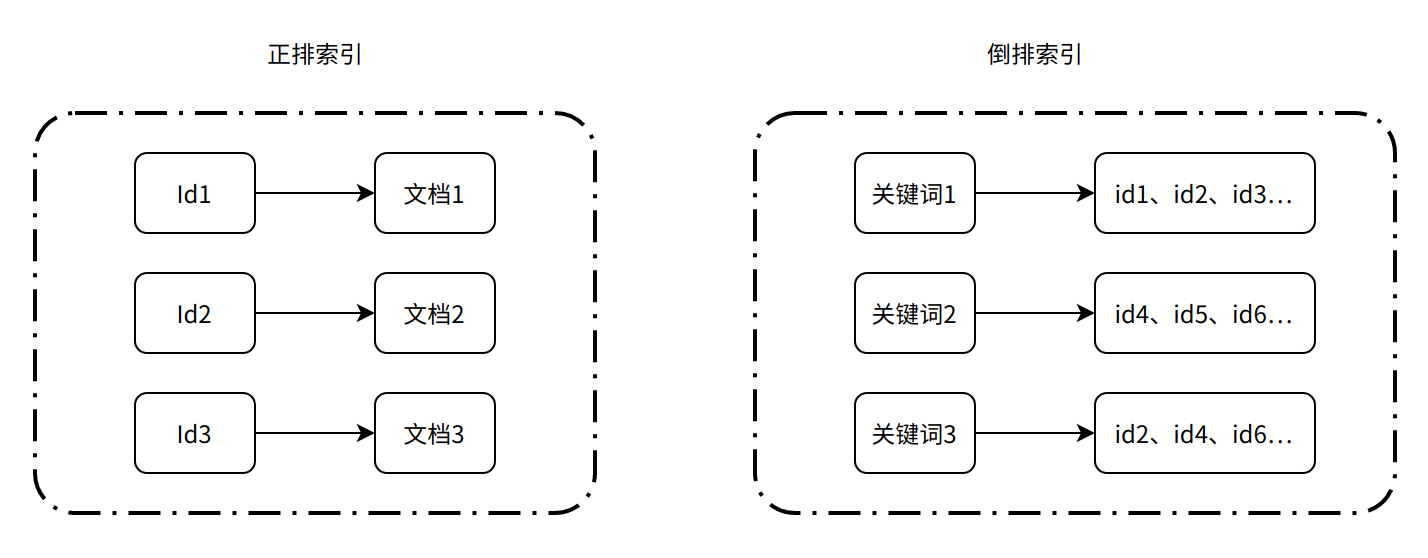
先简单介绍下倒排索引,倒排索引的概念区别于正排索引:
- 正排索引:是以文档对象的少数 ID 作为索引,以文档内容作为记录的结构
- 倒排索引:是以文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构

以倒排索引库 search-index 举个实际的例子。在网易云信的 IM 中,每条消息对象都有 idClient 作为少数 ID,接下来我们输入「今天天气真好」,将其每个中文单独分词(分词的概念我们在下文会详细分享),于是输入变成了「今」、「天」、「天」、「气」、「真」、「好」,再通过 search-index 的 PUT 方法将其写入库中,最后看下存储内容的结构:
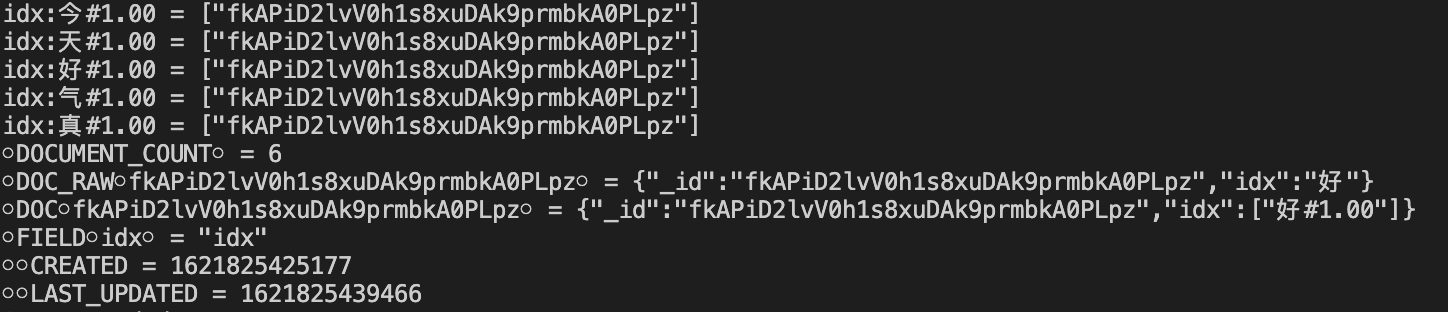
如图所示,可以看到倒排索引的结构,key 是分词后的单个中文,value 是包含该中文消息对象的 idClient 组成的数组。当然,search-index 除了以上这些内容,还有一些其他内容,例如 Weight、Count 以及正排的数据等,这些是为了排序、分页、按字段搜索等功能而存在的,本文就不再细细展开了。
(二)分词
分词就是将原先一条消息的内容,根据语义切分成多个单字或词句,考虑到中文分词的效果以及需要在 Node 上运行,我们选择了 Nodejieba 作为基础分词库。以下是 jieba 分词的流程图:
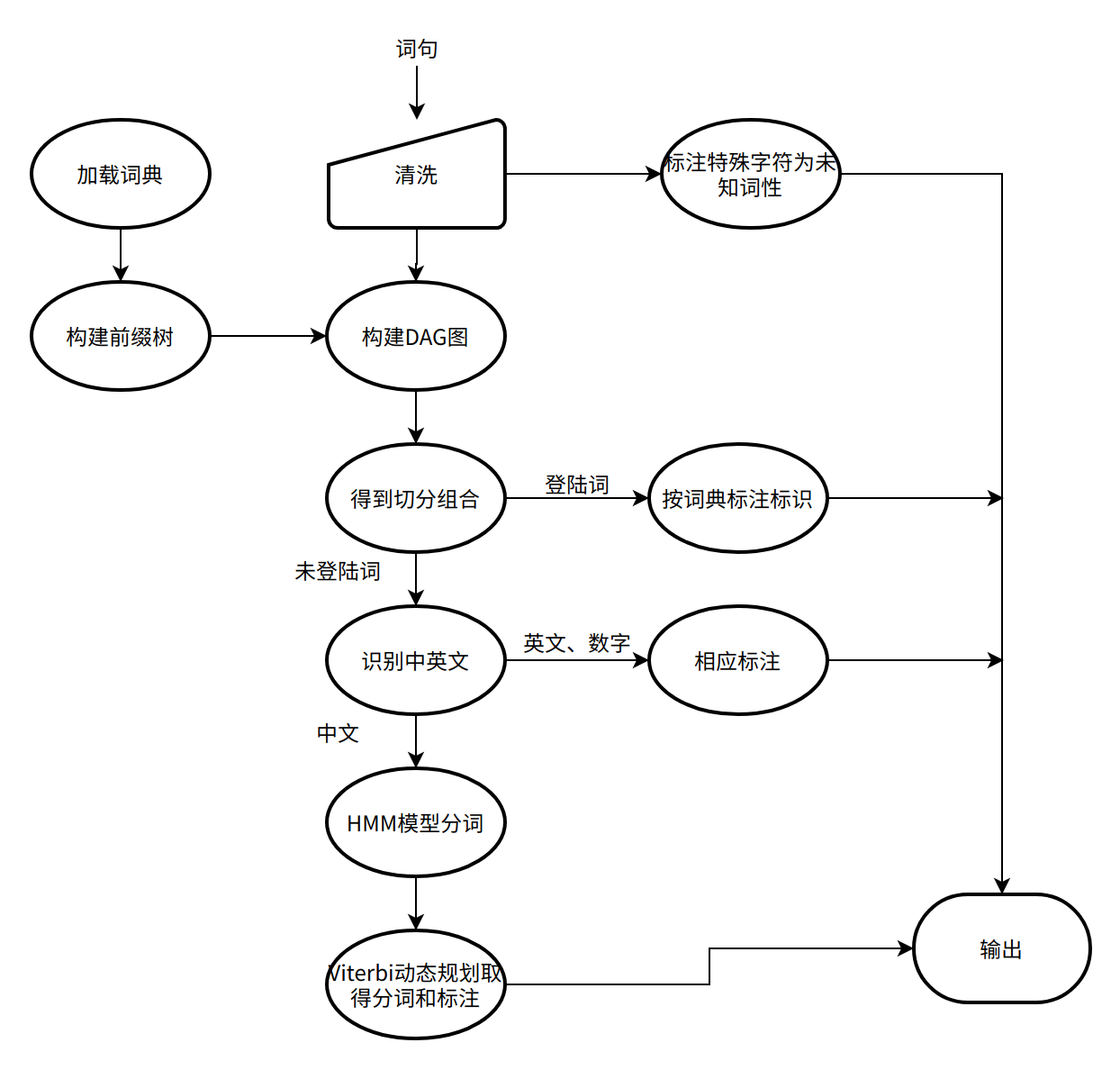
以「去北京大学玩」为例,我们选择其中最为重要的几个模块分析一下:
- 加载词典
jieba 分词会在初始化时先加载词典,大致内容如下:
- 构建前缀词典
接下来会根据该词典构建前缀词典,结构如下:
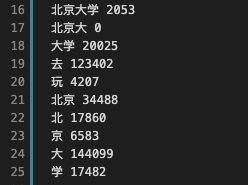
其中,「北京大」作为「北京大学」的前缀,它的词频是0,这是为了便于后续构建 DAG 图。
- 构建 DAG 图
DAG 图是 Directed Acyclic Graph 的缩写,即有向无环图。
基于前缀词典,对输入的内容进行切分。其中,「去」没有前缀,因此只有一种切分方式;对于「北」,则有「北」、「北京」、「北京大学」三种切分方式;对于「京」,也只有一种切分方式;对于「大」,有「大」、「大学」两种切分方式;对于「学」和「玩」,依然只有一种切分方式。如此,可以得到每个字作为前缀词的切分方式,其 DAG 图如下图所示:
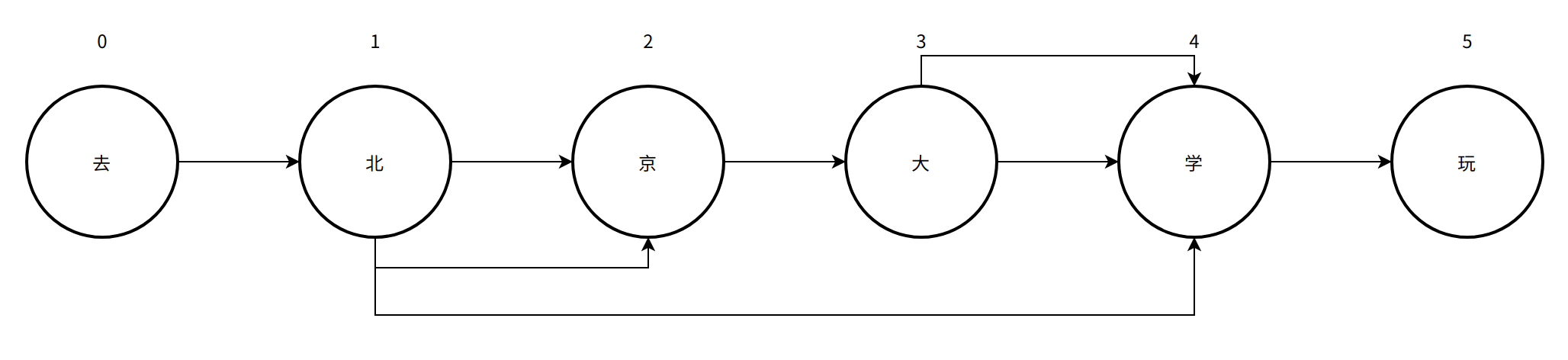
- 最大概率路径计算
以上 DAG 图的所有路径如下:
- 去/北/京/大/学/玩
- 去/北京/大/学/玩
- 去/北京/大学/玩
- 去/北京大学/玩
因为每个节点都是有权重(Weight)的,对于在前缀词典里的词语,它的权重就是它的词频。因此我们的问题就是想要求得一条最大路径,使得整个句子的权重较高。
这是一个典型的动态规划问题,首先我们确认下动态规划的两个条件:
- 重复子问题:对于节点 i 和其可能存在的多个后继节点 j 和 k:

即对于拥有公共前驱节点 i 的 j 和 k,需要重复计算到达 i 路径的权重。
- 优异子结构:设整个句子的优异路径为 Rmax,末端节点为 x,多个可能存在的前驱节点
 为 i、j、k,得到公式如下:
为 i、j、k,得到公式如下:
于是问题变成了求解 Rmaxi、Rmaxj 以及 Rmaxk,子结构里的优异解即是全局优异解的一部分。
如上,最后计算得出优异路径为「去/北京大学/玩」。
5. HMM 隐式马尔科夫模型
对于未登陆词,jieba 分词采用 HMM(Hidden Markov Model 的缩写)模型进行分词。它将分词问题视为一个序列标注问题,句子为观测序列,分词结果为状态序列。jieba 分词作者在 issue 中提到,HMM 模型的参数基于网上能下载到的 1998 人民日报的切分语料,一个 MSR 语料以及自己收集的 TXT 小说、用 ICTCLAS 切分,最后用 Python 脚本统计词频而成。
该模型由一个五元组组成,并有两个基本假设。
五元组:
- 状态值集合
- 观察值集合
- 状态初始概率
- 状态转移概率
- 状态发射概率
基本假设:
- 齐次性假设:即假设隐藏的马尔科夫链在任意时刻t的状态只依赖于其前一时刻t-1的状态,与其它时刻的状态及观测无关,也与时刻t无关。
- 观察值独立性假设:即假设任意时刻的观察值只与该时刻的马尔科夫链的状态有关,与其它观测和状态无关。
状态值集合即{ B: begin, E: end, M: middle, S: single },表示每个字所处在句子中的位置,B 为开始位置,E 为结束位置,M 为中间位置,S 是单字成词。
观察值集合就是我们输入句子中每个字组成的集合。
状态初始概率表明句子中的名列前茅个字属于 B、M、E、S 四种状态的概率,其中 E 和 M 的概率都是0,因为名列前茅个字只可能 B 或者 S,这与实际相符。
状态转移概率表明从状态 1 转移到状态 2 的概率,满足齐次性假设,结构可以用一个嵌套的 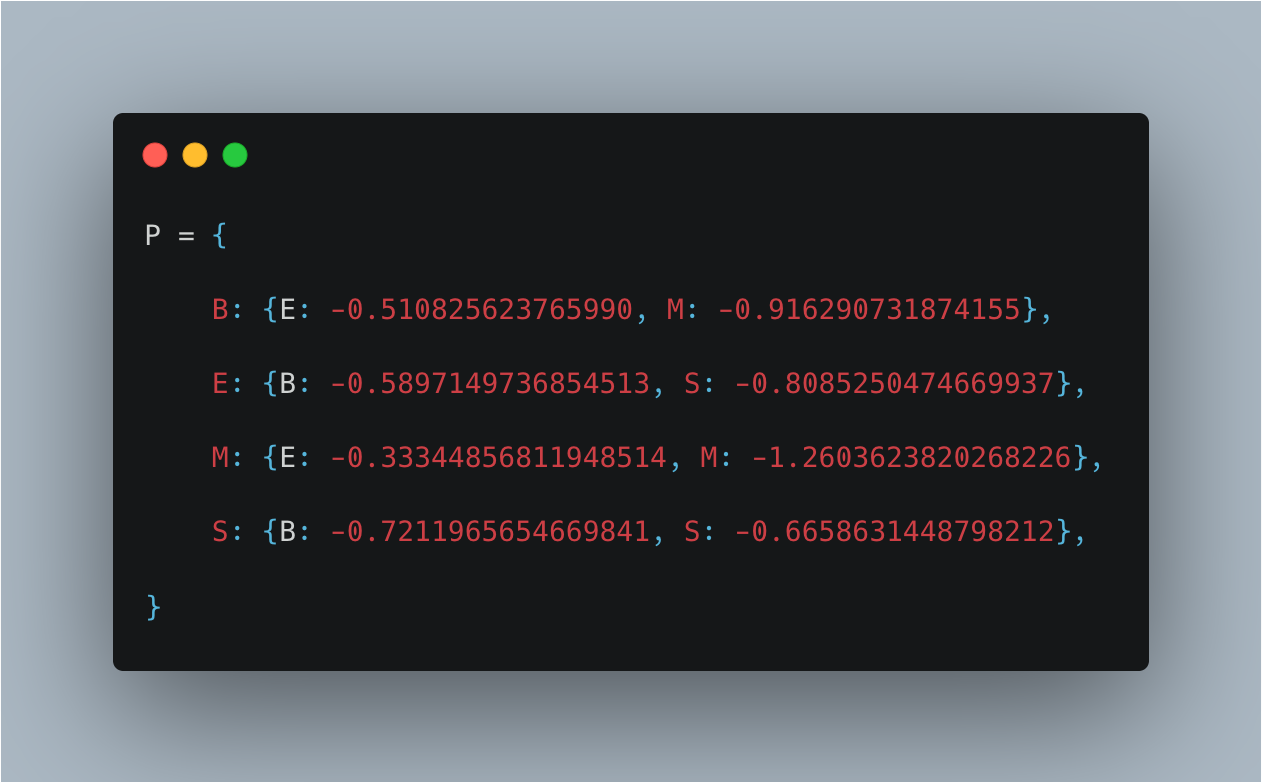 对象表示:
对象表示:
P[‘B’][‘E’] 表示从状态 B 转移到状态 E 的概率(结构中为概率的对数,方便计算)为 0.6,同理,P[‘B’][‘M’] 表示下一个状态是M的概率为0.4,说明当一个字处于开头时,下一个字处于结尾的概率高于下一个字处于中间的概率,符合直觉,因为二个字的词比多个字的词要更常见。
状态发射概率表明当前状态,满足观察值独立性假设,结构同上,也可以用一个嵌套的对象表示:

P[‘B’][‘突’] 的含义就是状态处于 B,观测的字是「突」的概率的对数值等于 -2.70366861046。
最后,通过 Viterbi 算法,输入观察值集合,将状态初始概率、状态转移概率、状态发射概率作为参数,输出状态值集合(即最大概率的分词结果)。关于 Viterbi 算法,本文不再详细展开,有兴趣的读者可以自行查阅。
以上这两块技术,是我们架构的技术核心。基于此,我们对网易云信 IM 的 Electron 端技术架构做了改进。
三、网易云信 IM Electron 端架构
(一)架构图详解
虑到全文检索只是 IM 中的一个功能,为了不影响其他 IM 的功能,并且能更快的迭代需求,所以采用了如下的架构方案:
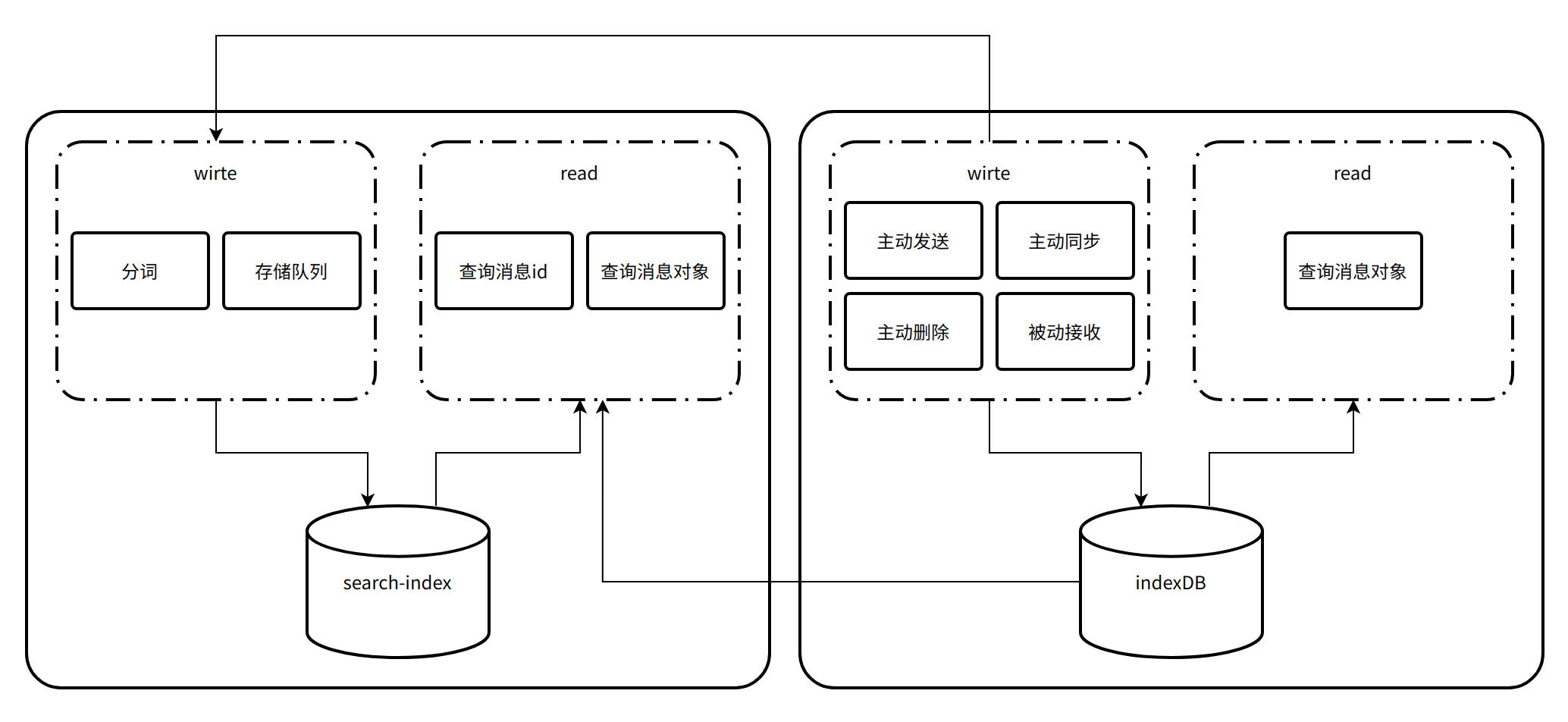
右边是之前的技术架构,底层存储库使用了 indexDB,上层有读写两个模块:
- 当用户主动发送消息、主动同步消息、主动删除消息以及收到消息的时候,会将消息对象同步到indexDB;
- 当用户需要查询关键字的时候,会去 indexDB 中遍历所有的消息对象,再使用 indexOf 判断每一条消息对象是否包含所查询的关键字(类似 LIKE)。
那么,当数据量大的时候,查询的速度是非常缓慢的。
左边是加入了分词以及倒排索引数据库的新的架构方案,这个方案不会对之前的方案有任何影响,只是在之前的方案之前加了一层,现在:
- 当用户主动发送消息、主动同步消息、主动删除消息以及收到消息的时候,会将每一条消息对象中的消息经过分词后同步到倒排索引数据库;
- 当用户需要查询关键字的时候,会先去倒排索引数据库中找出对应消息的 idClient,再根据 idClient 去 indexDB 中找出对应的消息对象返回给用户。
(二)架构优点
该方案有以下4个优点:
- 速度快:通过 search-index 实现倒排索引,从而提升了搜索速度。
- 跨平台:因为 search-index 与 indexDB 都是基于 levelDB,因此 search-index 也支持浏览器环境,这样就为 Web 端实现全文检索提供了可能性。
- 独立性:倒排索引库与 IM 主业务库 indexDB 分离。当 indexDB 写入数据时,会自动通知到倒排索引库的写模块,将消息内容分词后,插入到存储队列当中,最后依次插入到倒排索引数据库中。当需要全文检索时,通过倒排索引库的读模块,能快速找到对应关键字的消息对象的 idClient,根据 idClient 再去 indexDB 中找到消息对象并返回。
- 灵活性:全文检索以插件的形式接入,它暴露出一个高阶函数,包裹 IM 并返回新的经过继承扩展的 IM,因为 JS 面向原型的机制,在新的 IM 中不存在的方法,会自动去原型链(即老的 IM)当中查找,因此,使得插件可以聚焦于自身方法的实现上,并且不需要关心 IM 的具体版本,并且插件支持自定义分词函数,满足不同用户不同分词需求的场景。
(三)使用效果
使用了如上架构后,经过我们的测试,在数据量 20W 的级别上,搜索时间从最开始的十几秒降到一秒内,搜索速度快了 20 倍左右。
四、总结
以上,我们便基于 Nodejieba 和 search-index 在 Electron 上实现了网易云信 IM SDK 聊天消息的全文检索,加快了聊天记录的搜索速度。当然,后续我们还会针对以下方面做更多的优化,比如:
- 写入性能提升 :在实际的使用中,发现当数据量大了以后,search-index 依赖的底层数据库 levelDB 会存在写入性能瓶颈,并且 CPU 和内存的消耗较大。经过调研,SQLite 的写入性能相对要好很多,从观测来看,写入速度只与数据量成正比,CPU 和内存也相对稳定,因此,后续可能会考虑用将 SQLite 编译成 Node 原生模块来替换 search-index。
- 可扩展性 :目前对于业务逻辑的解耦还不够彻底。倒排索引库当中存储了某些业务字段。后续可以考虑倒排索引库只根据关键字查找消息对象的 idClient,将带业务属性的搜索放到 indexDB 中,将倒排索引库与主业务库彻底解耦。
以上,就是本文的全部分享,欢迎关注我们,持续分享更多技术干货。最后,希望我的分享能对大家有所帮助。
作者介绍
李宁,网易云信高级前端开发工程师,负责网易云信音视频 IM SDK 的应用开发、组件化开发及解决方案开发,对 React、PaaS 组件化设计、多平台的开发与编译有丰富的实战经验。有任何的问题,欢迎留言交流。
关于网易云信
网易云信:网易智企旗下融合通信云服务专家、通信与视频 PaaS 平台。集网易 24 年 IM 以及音视频技术打造的融合通信云服务专家,稳定易用的通信与视频 PaaS 平台。提供融合通信与视频的核心能力与组件,包含 IM 即时通讯、5G 消息平台、一键登录、信令、短信与号码隐私保护等通信服务,音视频通话、直播、点播、互动直播与互动白板等音视频服务,视频会议等组件服务,并联合网易易盾推出一站式安全通信方案「安全通」。目前,网易云信已经成功发送 1.6 万亿条消息,覆盖智能终端 SDK 数累计超过 186 亿,我们期待每个智能终端都有云信的融合通信能力。
文章包含AI辅助创作:如何在Electron上实现IMSDK聊天消息全文检索,发布者:网易智企,转载请注明出处:https://worktile.com/kb/p/5962
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 