迭代深度优先搜索与深度有限搜索的区别:1、概念不同;2、深度不同;3、原理不同。概念不同是指迭代深度优先搜索是一个用来寻找最合适的深度限制的通用策略,而深度有限算法是在深度优先搜索的基础之上,限制搜索深度。
一、迭代深度优先搜索与深度有限搜索的区别
1、概念不同
迭代深度优先搜索:迭代深度优先搜索是一个用来寻找最合适的深度限制的通用策略,它经常和深度优先搜索结合使用。
深度有限搜索:深度有限搜索是一种搜索方法,首先扩展根节点,然后扩展根节点的所有后继,接着再扩展它们的后继,从而一层一层的对节点进行扩展,但是限制搜索深度。
2、深度不同
迭代深度优先搜索:迭代加深搜索实质是限定下界的深度优先搜索,即首先允许深度优先搜索搜索 k 层搜索树,若没有发现可行解,再将 k+1 后再进行一次以上步骤,直到搜索到可行解。这个“模仿广度优先搜索”搜索法牺牲了时间,但节约了空间。如果有解,迭代深度优先搜索可以找到最浅的解,迭代深度优先搜索的深度是不断增加的。
深度有限搜索:深度有限搜索设定一个最大深度dmax,当搜索深度大于dmax的时候立即回溯,从而避免了在无穷状态空间中陷入深度无限的分支,深度有限搜索限制了搜索深度。
3、原理不同
迭代深度优先搜索:迭代深度优先搜索扩展根节点的一个后继,然后扩展它的一个后继,直到到达搜索树的最深层,那里的节点没有后继,于是迭代深度优先搜索回溯到上一层,扩展另外一个未被扩展的节点。在有限状态空间中,DFS是完备的,因为它可以把所有空间遍历一遍;而在无限空间中,DFS则有可能会进入深度无限的分支,因此是不完备的。DFS的时间复杂度为为O(b),而空间复杂度仅为O(d),因为我们只需要保存当前分支的状态,因此空间复杂度远远好于BFS。然而DFS并不能保证找到优异解。
深度有限搜索:深度有限搜索设定一个最大深度dmax,开始我们把dmax设为1,然后进行深度受限搜索,如果么有找到答案,则让dmax加一,并再次进行深度有限搜索,以此类推直到找到目标。这样既可以避免陷入深度无限的分支,同时还可以找到深度最浅的目标解,从而在每一步代价一致的时候找到优异解,再加上其优越的空间复杂度,因此常常作为优选的无信息搜索策略。
二、深度优先探索的迭代实现
DFS的迭代实现
DFS 的非递归的实现类似于BFS的非递归的实现但在两个方面与它不同:
- 它使用一个 stack代替queue。
- DFS 应该只在弹出顶点之后标记发现,而不是在推送它之前。
- 它使用反向迭代器而不是迭代器来产生与递归的 DFS 相同的结果。
代码实现
#include <iostream>
#include <stack>
#include <vector>
using namespace std;
// 存储Graph边的数据结构
struct Edge {
int src, dest;
};
// 表示Graph对象的类
class Graph
{
public:
// 表示邻接表的VectorVector
vector<vector<int>> adjList;
// Graph构造器
Graph(vector<Edge> const &edges, int n)
{
// 调整Vector的大小以容纳 `n` 类型为 `vector<int>`
adjList.resize(n);
for (auto &edge: edges)
{
adjList[edge.src].push_back(edge.dest);
adjList[edge.dest].push_back(edge.src);
}
}}
// 从顶点 `v` 开始对Graph执行迭代 DFS
void iterativeDFS(Graph const &graph, int v, vector<bool> &discovered)
{
// 创建一个用于迭代 DFS 的Stack
stack<int> stack;
// 将源节点压入Stack中
stack.push(v);
while (!stack.empty())
{
v = stack.较好();
stack.pop();
if (discovered[v]) {
continue;
}
discovered[v] = true;
cout << v << " ";
for (auto it = graph.adjList[v].rbegin(); it != graph.adjList[v].rend(); it++)
{
int u = *it;
if (!discovered[u]) {
stack.push(u);
}}}}
int main()
{
// 根据上Graph的Graph边Vector
vector<Edge> edges = {
{1, 2}, {1, 7}, {1, 8}, {2, 3}, {2, 6}, {3, 4},
{3, 5}, {8, 9}, {8, 12}, {9, 10}, {9, 11}
};
// Graph中的节点总数(标记为 0 到 12)
int n = 13;
// 从给定的边构建一个Graph
Graph graph(edges, n);
// 跟踪是否发现了一个顶点
vector<bool> discovered(n);
for (int i = 0; i < n; i++)
{
if (discovered[i] == false) {
iterativeDFS(graph, i, discovered);
}
}
return 0;
}三、搜索算法概述
搜索算法
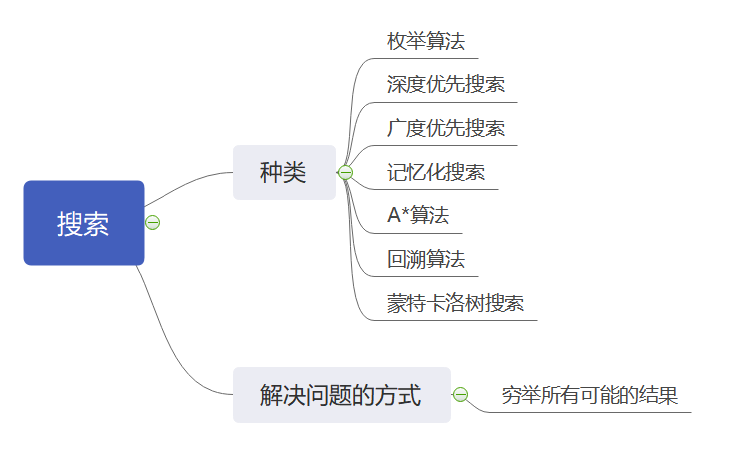
搜索算法是利用计算机的高性能来有目的的穷举一个问题解空间的部分或所有的可能情况,从而求出问题的解的一种方法。现阶段一般有枚举算法、深度优先搜索、广度优先搜索、A*算法、回溯算法、蒙特卡洛树搜索、散列函数等算法。在大规模实验环境中,通常通过在搜索前,根据条件降低搜索规模;根据问题的约束条件进行剪枝;利用搜索过程中的中间解,避免重复计算这几种方法进行优化。

递归树的引入
我们会发现无论是我们的正向穷举算法还是我们的递归式搜索枚举都可以产生一棵搜索树,而这颗搜索树也通常是辅助我们解决问题的关键,当然正向递推枚举会比递归枚举要快的多,其差别之一就是迭代式的搜索算法不会用到系统栈,而递归的搜索会大量的调用系统栈,因此引入了递归树。
延伸阅读
python实现深度有限搜索的算法原理
- 节点目标测试:通过,则返回成功;否则,判断 limit 是否为0,为0则返回失败。
- 设置限制标志:cutoff_occurred,初始值为False。
- 遍历节点的所有动作:每个动作产生子节点,递归子节点,参数中的深度:limit-1。递归结果返回到变量result,result如果为成功,则返回成功;如果是cutoff,则cutoff_occurred=True。(result有三种返回状态:failure,cutoff,node)。
- 如果cutoff_occurred为true:则返回cutoff,否则返回失败。
文章包含AI辅助创作:迭代深度优先搜索与深度有限搜索有什么区别,发布者:Z, ZLW,转载请注明出处:https://worktile.com/kb/p/48176
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 