Cross-device和Cross-Silo的联邦学习区别有:1、模式不同;2、面对的客户端不同;3、客户端状态不同;4、可定位性不同;5、发展瓶颈不同等。模式不同是指Cross-device联邦学习是多设备联邦的模式,而Cross-Silo联邦学习适合共享训练模型不想分享数据的模式。
一、Cross-device和Cross-Silo的联邦学习的区别
1、模式不同
Cross-device联邦学习:多设备联邦的模式。
Cross-Silo联邦学习:与跨设备联合学习的特征相反,Cross-Silo 联邦学习在总体设计的某些方面非常灵活。许多组织如果只是想共享训练模型,而不想分享数据时,cross-silo设置是非常好的选择。Cross-Silo 联邦学习的设置主要有以下几个要点:数据分割、激励机制、差异隐私、张量因子分解。
2、面对的客户端不同
Cross-device联邦学习:Cross-device FL针对的则是便携式电子设备、穿戴式电子设备等,统称为物联设备(Internet of Things, IoT devices)。
Cross-Silo联邦学习:Cross-silo FL面对的客户端是企业级别、机构单位级别的。
3、客户端状态不同
Cross-device联邦学习:无状态,每个客户可以仅会参与一次任务,因此通常假定在每轮计算中都有一个从未见过的客户的新样本。
Cross-Silo联邦学习:有状态,每个客户端都可以参与计算的每一轮,并不断携带状态。
4、可定位性不同
Cross-device联邦学习:没有独立编号,无法直接为客户建立索引。
Cross-Silo联邦学习:有独立编号,每个客户端都有一个标识或名称,该标识或名称允许系统专门访问。
5、发展瓶颈不同
Cross-device联邦学习:计算传输开销、通信不稳定。
Cross-Silo联邦学习:数据异构。
6、通信情况不同
Cross-device联邦学习:不稳定、不可靠。
Cross-Silo联邦学习:稳定且可靠。
7、数据划分依据不同
Cross-device联邦学习:横向划分。
Cross-Silo联邦学习:可横向纵向划分。
二、联邦学习概述
联邦学习定义
首先,关于联邦学习的定义就分为很多种,也有很多不同场景下的联邦学习。首先,引用一下大综述摘要里面对联邦学习的介绍:
Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized.
翻译过来为:联邦学习是一种机器学习范式,可以在一个中心服务器的协调下让多个客户端互相合作,即便在数据分散在客户端的情况下也可以得到一个完整的机器学习模型。
这里的客户端有不同层级的指代,在不同的任务中可以指代不同的事物。比如,在手机输入法预测下一个词语的任务中,一般需要使用自然语言处理中的N-Gram模型(Natural Language Models)来预测下一个词语,这个任务中客户端就是很多部用户的手机;在医疗领域,使用图像识别分割等机器学习技术对病例进行诊断需要大量的数据支持,而这些数据正往往是涉及大量用户隐私的,因此在这种情况下需要一种安全的方法来协同多个医疗机构的数据进行训练,在这个情况下,客户端就是一家家的医疗机构。
联邦
如何做到隐私保护呢?联邦学习给出了答案。首先解释一下为何叫“联邦”学习,联邦这个词原本指的是多个成员单位(州、邦、国等)组成的统一国家,总体上遵循共同的法律约束,但又保留了每个成员相对独立的立法、司法和行政机关,设有中央政府,并约定各成员忠诚。在联邦学习里面,各个客户端通过中心服务器进行协调,在各个客户端和中心服务器彼此信任的情况下(无恶意猜测和攻击)可以达到很理想的隐私保护要求,中心服务器只负责协调、聚合等功能,模型还是根据客户端本地的数据进行训练,允许一定程度上的个性化训练方式。总结来说,“联邦”一词在实际政治和机器学习领域所涉及的主体、事物、功能,对应如下:
- 中央政府 <–> 中心服务器
- 成员单位 <–> 客户端
- 总体上遵循共同的法律约束 <–> 中心服务器协调、聚合
- 相对独立的立法司法行政 <–> 一定程度上的个性化训练
- 成员单位忠诚 <–> 客户端和中心服务器彼此无恶意猜测、攻击
故而,McMahan采用了联邦学习这个词。目前为止,已经引出了联邦学习涉及的两大核心主体:中心服务器、客户端。并且其功能大致为:中心服务器负责宏观上协调各个客户端,客户端负责在本地训练机器学习模型。那么中心服务器如何协调呢?大概的流程又如何呢?
先给出一张联邦学习常见框架图,图中描绘出了三个客户端和一个中心服务器,客户端和服务器之间有通信。
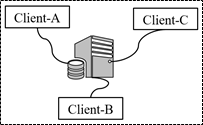

一般而言,联邦学习有以下四个步骤(以基于梯度训练深度神经网络为例):
- 所有客户端分别独立地在本地数据上进行训练
- 客户端对模型参数或者模型参数的梯度进行加密,上传到服务器
- 服务器对搜集到的客户端的模型参数或者梯度进行聚合,并且是安全聚合(Secure Aggregation)
- 服务器将模型下发到各个客户端;
联邦学习中的问题
- Non-IID问题:由于数据来自各个客户端,数据分布不再满足传统机器学习假设的数据独立同分布(IID)性质,反而是非独立同分布(Non-IID)的,这种情况下如何保证各个客户端训练的模型依旧可以被有效地全局聚合(Global Aggregation)?此外,即便能聚合出好的模型,如何将其部署下发到数据分布有所差异的客户端,即模型个性化问题(Personalization)?
- 数据传输问题:联邦学习严重依赖于数据传输,如何降低数据传输的开销以及如何确保通信不稳定的情况下系统依旧可以正常工作?
- 隐私保护措施:什么是安全聚合,怎么样才能做到安全多方计算(Secure Multi-Party Computing, Secure MPC)? 现有的解决方法有差分隐私(Differential Privacy)、同态加密(Homomorphic Encryption)等等。
联邦学习的应用
- 输入法:Gboard是Google 推出一款针对 iOS 设备和Android设备的虚拟键盘,QuickType是Apple在iOS 8中开始采用的全新预测文本功能,都属于智能输入法的范畴,可以结合用户的喜好和常识性短语进行自动预判用户下一步的输入,方便用户聊天打字等。一方面,手机、便携电脑随处可见,有大量用户的地方最容易诞生人工智能,因此智能输入的作用和潜在价值无须多提;另一方面,用户输入的东西既包含用户自身隐私相关的内容,比如年龄、住址、家庭状况等,又同时包含普遍用语、网络流行用语等,因此既要保护数据隐私、又要综合考虑大部分用户想看到的下一步输入。因此,需要联邦学习。
- 医疗:doc.ai致力于将人工智能应用到智能健康领域,加速医疗数字化进程,运用联邦学习解锁了医疗数据具有很大价值和医疗数据涉及隐私的矛盾,原文为:Unlock the value of health data with privacy-preserving solutions。
- 金融:微众银行基于数据安全联合建模,可以更好地支撑信贷行业的价值创造,并提升信贷行业的风险控制能力,发展了通过联邦学习的智能风控等业务。FDN(Federated Data Network)致力于建立企业级保护数据安全的大数据合作网络。此外,阿里支付宝也将联邦学习应用到了各种金融工具的数据分析和机器学习建模过程当中。微众银行AI项目组发起组建了联邦学习生态圈,称为FedAI,并开源了联邦学习系统FATE,旨在开发和推广数据安全和用户隐私保护下的AI技术及其应用。
联邦学习相关的研究方向
主要包括:分布式优化(Distributed Optimization)和多任务学习(Multi-Task Learning)。
分布式优化致力于解决海量数据或者计算资源匮乏情况下的模型训练问题。随着数据海量增长,工业界急需大数据处理技术,特别是如何在数据分布在不同设备上时的机器学习训练。为了解决单一机器难以训练大量数据或者为了使用并行计算利用多台机器加速模型训练等目的,DistBelief等分布式训练框架被提出(NeurIPS 2012):

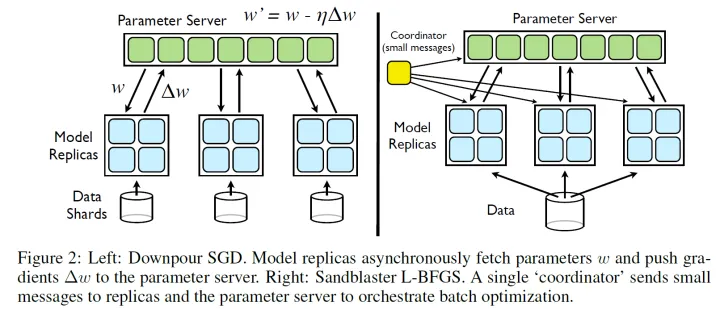
上面展示的框架中主要包括几个概念:
- Data Shards:数据碎片,也可以翻译为数据块
- Model Replicas:模型副本
- Parameter Server:参数服务器
一般来说,模型副本存储了模型的部分模块,使用数据块更新这部分参数之后将参数梯度上传至参数服务器,参数服务器更新模型之后再将模型下发下去。参数服务器保存完整的模型,模型副本只包含部分模型参数,不同模型副本之间更新过程是异步的。
延伸阅读
联邦学习的广泛定义
联邦学习是一种由多个实体(客户端)在中央服务器或服务提供商的协调下协作解决机器学习问题的机器学习设置。每个客户的原始数据都存储在本地,并且不会交换或转移;取而代之的是使用旨在及时信息聚合的局部更新来实现学习目标。局部更新是指范围狭窄的更新,其中包含针对特定学习任务所需的最少信息。在数据最小化服务中,尽可能早地执行聚合。
文章包含AI辅助创作:Cross-device和Cross-Silo的联邦学习区别,发布者:Z, ZLW,转载请注明出处:https://worktile.com/kb/p/48518
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 