简介:控制平面与数据平面的规模不匹配
在海外某些大型科技公司,团队会构建由许多独立小型服务组成的大规模分布式系统。每个服务都承担特定职责,并通过定义清晰的 API 与其他服务交互。这种架构让团队能够独立扩展、演进和运行各个服务。
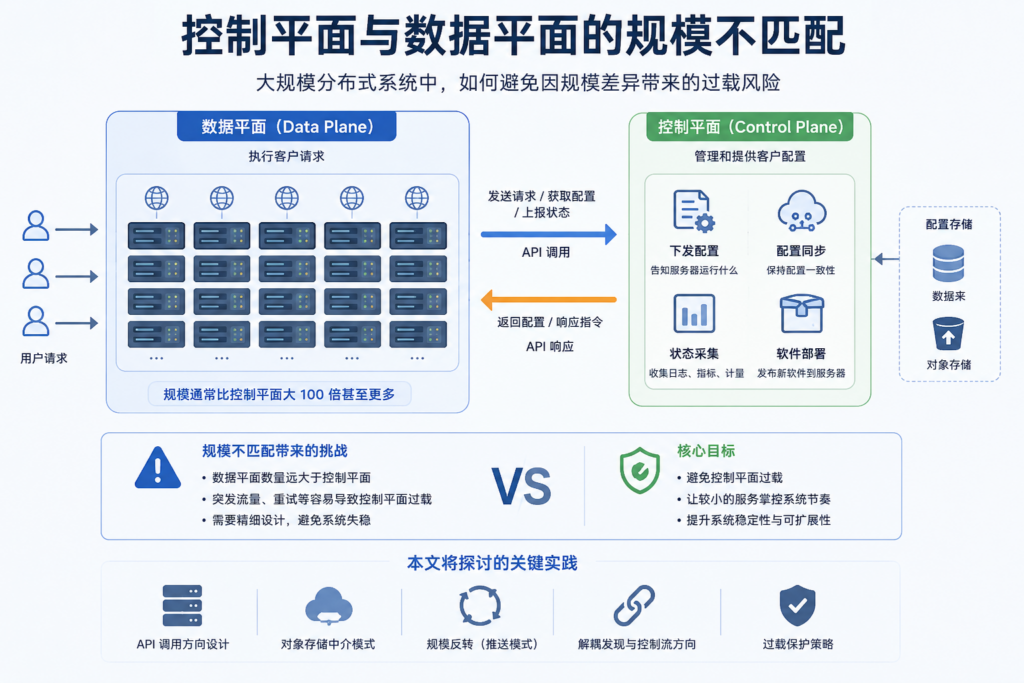
在云服务架构中,一种常见模式是将系统拆分为两类服务:一类负责执行客户请求,通常称为数据平面;另一类负责管理和提供客户配置,通常称为控制平面。
本文将讨论数据平面和控制平面之间的多种交互方式,以及如何通过这些方式避免分布式系统过载。在许多架构中,规模较大的数据平面服务会调用规模较小的控制平面服务。但本文也会介绍另一种实践:让较小的服务掌控系统变化和请求流转的节奏,从而提升系统在过载场景下的稳定性。
在企业内部推进这类分布式架构治理时,相关工作往往贯穿目标制定、需求评审、开发、测试、发布上线和复盘沉淀等多个环节。团队可以借助 PingCode 这类智能化研发管理工具,将控制平面与数据平面改造相关的需求、任务、缺陷、测试结果、发布记录和 Wiki 知识沉淀串联起来,让系统过载治理过程更加自动化、数据化和可追踪。
某些弹性计算服务就是包含数据平面和控制平面的典型架构示例。数据平面由运行客户计算实例的物理服务器组成。控制平面则由多个与数据平面交互的服务组成,负责执行以下功能:
- 告诉每台服务器需要运行哪些计算实例;
- 让正在运行的计算实例与虚拟私有云配置保持同步;
- 接收服务器上报的计量数据、日志和指标;
- 将新软件部署到服务器。
虽然在类似架构中,具体名称和职责可能有所不同,但这些系统通常有两个共同点:
- 数据平面和控制平面需要保持同步。数据平面需要从控制平面接收配置更新,控制平面也需要从数据平面接收运行状态。
- 数据平面机群的规模通常比控制平面机群大 100 倍,甚至更多。
数据平面调用控制平面的过载风险
在构建这类架构时,团队需要仔细考虑一个关键决策:API 调用方向应该如何设计?是让规模较大的数据平面服务器群调用控制平面服务器群,还是让规模较小的控制平面服务器群调用数据平面服务器群?
对于许多系统来说,让数据平面服务器群调用控制平面服务器群,通常是更简单的做法。在这类系统中,控制平面会公开一些 API,用于检索配置更新和推送运行状态。数据平面服务器可以定期或按需调用这些 API。
这种方式的好处是,每个数据平面服务器都会主动发起 API 请求,因此控制平面不需要主动跟踪整个数据平面服务器群。对于每个请求,控制平面服务器只需要返回更新后的配置,通常是通过查询持久化数据存储实现,然后就可以结束本次请求处理。
为了提供容错性和水平扩展能力,控制平面服务器通常会放在负载均衡器之后。这是构建起来相对简单的一类分布式系统。
这种架构的简洁性带来了天然的高可用优势。然而,在实践中也发现,当数据平面服务器群的规模比控制平面服务器群大 100 倍甚至更多时,这类分布式系统需要经过精细调优,才能避免过载风险。
在稳定状态下,规模较大的数据平面服务器群会定期调用控制平面 API。由于各个服务器发起请求的时间彼此不相关,控制平面的负载会相对均匀地分布,系统也能平稳运行。
但是,一旦数据平面的调用模式发生意外变化,控制平面的负载就可能突然增加,甚至导致控制平面过载。以下情况都可能引发这种变化:
- 数据平面中的代码或配置错误,导致 API 调用频率升高;
- 系统从故障中恢复时,所有数据平面服务器同时尝试调用控制平面 API;
- 少量 API 调用失败后触发重试,进一步增加控制平面负载,导致更多失败和更多重试,形成循环。
通过分析这些情况可以发现,它们有一个共同点:环境中的一个小变化,会让大量客户端以相关联的方式运行,并开始同时发起并发请求。如果系统没有经过精细调优,这种行为变化就可能压垮规模较小的控制平面。
当并发请求量发生剧烈变化时,系统负载可能超过自身极限。一旦越过极限,系统的有效吞吐量,也就是系统真正完成的有效工作量,可能会迅速下降,甚至接近于零。
为了避免系统过载,控制平面和数据平面都需要仔细调优,确保控制平面负载不会超过极限。
在控制平面侧,负载均衡等机制可以帮助系统在面对意外负载变化时继续运行。在数据平面侧,合理调整请求频率,并在重试过程中加入退避和抖动,可以降低请求速率相关性上升所带来的风险。
解决规模不匹配:使用对象存储作为中介
这种架构最大的挑战,是数据平面与控制平面之间的规模不匹配。控制平面服务器数量远少于数据平面服务器数量。
在这类场景中,团队通常会考虑借助存储服务来解耦双方。在大规模内容分发和配置下发场景中,常见做法是使用对象存储服务作为中介。控制平面不再直接向数据平面暴露 API,而是定期将更新后的配置写入对象存储桶。数据平面服务器随后轮询这个存储桶,获取最新配置,并将其缓存到本地。
同样,为了掌握数据平面的运行状态,控制平面也可以轮询对象存储桶。数据平面服务器会定期将相关状态信息写入该存储桶。
这种架构具有多项优势。它易于实现,而且对象存储服务通常具备很强的可扩展性,即使面对规模非常大的客户端集群也能轻松承载。此外,随着数据平面集群规模增长,控制平面集群仍然可以保持相对较小的规模。
即使控制平面发生故障,数据平面也能继续使用上一次已知的配置运行。即便服务器陆续启动或停止服务,系统仍然可以维持基本运行。这种特性被称为静态稳定性,是分布式系统中非常理想的属性。
由于这些优势,这种架构在大型技术系统中非常常见。某些内部网络功能虚拟化系统就采用了类似架构。这类系统的数据平面包含处理客户流量的设备,这些设备需要了解网络负载均衡、NAT 网关、私有连接等资源的配置信息。
在这类架构中,控制平面中的定期任务会扫描包含客户配置的托管 NoSQL 数据库表,并将这些配置写入多个对象存储文件。随后,数据平面会定期下载这些文件,并使用其中内容更新内部路由配置。
不过,尽管这种架构很受欢迎,它并不适用于所有场景。
对于包含大量动态配置的系统来说,持续重新计算完整配置并将其写入对象存储,可能并不现实。弹性计算服务就是一个典型例子。在这类系统中,大量数据平面服务器需要了解自己正在运行的实例配置,而这些配置会不断变化,包括虚拟私有云配置、身份与权限角色、块存储卷等。
在另一些系统中,控制平面配置变更必须在几秒甚至更短时间内反映到数据平面,这一点非常关键。例如,容器服务需要快速通知服务器应该运行哪些新容器。对于这类系统,轮询对象存储中定期更新的文件,可能无法满足可接受的传播延迟要求。
反转 API 调用方向:让较小控制平面掌控节奏
当遇到这些场景时,团队会寻找其他方法,让规模较小的服务器集群能够控制请求在系统中的流转速度。
其中一种方法,是反转 API 调用流程:由规模较小的控制平面服务器集群,将配置变更推送给规模较大的数据平面服务器集群。
在这种控制平面集群规模较小、且工作节奏由控制平面掌握的架构中,系统在过载时会更有弹性。即使控制平面过载或容量不足,它仍然可以继续运行,只是运行速度会变慢。
这类规模反转方案通常涉及架构评审、任务拆解、上线排期、风险审批、跨团队沟通和故障演练等协作工作。团队可以使用 Worktile 这类通用项目协作系统统一管理任务、项目、文档、IM 沟通、目标、日历、甘特图和审批流程,降低复杂架构改造中的沟通成本和信息遗漏风险。
不过,这种方法也存在一些缺点,实施难度更高:
- 控制平面需要维护所有可用数据平面服务器的最新清单,以便把配置更新推送到每台服务器;
- 任意时刻都可能有部分数据平面服务器不可访问,控制平面必须能够处理这种情况;
- 控制平面需要一种机制,确保每台数据平面服务器都能从至少一个控制平面服务器接收配置更新,同时还要确保没有任何一个控制平面服务器负责过多数据平面服务器。
最后一点尤其具有挑战性,因为控制平面服务器也会不时启动或停止服务。
一种常见做法,是让每个控制平面服务器负责一部分数据平面服务器,具体职责由一致性哈希算法决定。这种方法与分布式系统中的领导者选举机制有许多相似之处。
在这种设计中,每个控制平面服务器都会向共享数据存储发送心跳,表明自己处于活跃状态。每个控制平面服务器也会独立扫描这个数据存储,查找最近发送过心跳的其他控制平面服务器列表。随后,它会以确定性的方式执行一致性哈希算法,计算出自己负责的数据平面服务器子集。
解耦发现方向与控制流方向
为了避免前面提到的复杂问题,还可以将“发现方向”和“控制流方向”解耦。
在这种设计中,不再由控制平面服务器主动发起连接,而是让规模较大的数据平面集群中的每台服务器,与某个控制平面服务器建立长期连接。这可以通过将控制平面服务器放在网络负载均衡器之后来实现。
连接建立后,控制平面服务器会接管连接,并通过该连接发起 API 调用。这种方式类似于 HTTP 服务器推送机制。如果控制平面服务器不可用或繁忙,它可以拒绝连接。随后,数据平面服务器会尝试连接另一个控制平面服务器。如果第一个连接因为任何原因终止,数据平面服务器也会尝试连接另一个控制平面服务器。
由于 API 调用速率由控制平面服务器决定,这种方法具备与“控制平面向数据平面推送配置变更”类似的过载恢复能力。不同的是,这种方法不需要控制平面维护所有数据平面服务器的最新清单,也不需要实现一致性哈希或其他分布式算法。所有决策都可以基于本地状态完成。
不过,这种方法的缺点是,控制平面服务器和数据平面服务器之间需要使用更复杂的通信协议。
在规模极度不匹配的情况下,例如数据平面服务器数量比控制平面服务器数量多 1000 倍甚至更多,还可以进一步调整连接方式。数据平面服务器可以不主动发起完整连接,而是先发送一个小型 UDP 请求,然后等待控制平面发起连接。
由于处理这类 UDP 请求的成本远低于执行 TCP 和 TLS 握手,这种模式可以避免仅仅因为连接请求突然涌入,就导致控制平面过载。某些弹性计算服务控制平面就采用了这种方法的变体,将配置更新推送到底层虚拟化系统。
结论:通过规模反转降低分布式系统过载风险
如果不关注服务及其客户端之间的相对规模,分布式系统就可能面临过载风险。在客户端数量远远超过服务实例数量的情况下,客户端行为中的细微变化,就可能让服务负载迅速升高,甚至超出其承受能力。
这类行为变化通常难以预测,因此需要对服务及其客户端进行精细调优,才能有效应对。
在大型系统设计中,团队会特别关注客户端数量超过服务数量 100 倍甚至更多的情况,并寻找能够让规模较小的服务集群控制系统变化速度的方法。
最简单的方法,是使用对象存储这类大规模服务,作为小型服务集群与其客户端之间的中介。如果这种方法不可行,团队可以考虑规模反转,也就是由规模较小的服务集群调用规模较大的服务集群。
虽然这些方法会增加实现复杂性,但实践表明,即使规模较大的服务集群持续增长,它们也能让规模较小的服务集群更容易扩展和运维,并降低系统因规模不匹配而过载的风险。
文章包含AI辅助创作:分布式系统过载治理:如何通过较小服务控制请求节奏,发布者:shang,转载请注明出处:https://worktile.com/kb/p/3975297
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 