常见优化方法有:1、SGD;2、Momentum;3、Nesterov;4、Adagrad;5、Adadelta;6、RMSprop;7、Adam;8、Adamax。SGD是指,随机梯度下降,多用于支持向量机、逻辑回归(LR)等凸损失函数下的线性分类器的学习。
1、SGD
随机梯度下降(SGD)是一种简单但非常有效的方法,多用用于支持向量机、逻辑回归(LR)等凸损失函数下的线性分类器的学习。并且SGD已成功应用于文本分类和自然语言处理中经常遇到的大规模和稀疏机器学习问题。SGD既可以用于分类计算,也可以用于回归计算。
SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。(重点:每次迭代使用一组样本。)所谓随机是指每次迭代过程中,样本都要被随机打乱,这个也很容易理解,打乱是有效减小样本之间造成的参数更新抵消问题。
对于权值的更新不再通过遍历全部的数据集,而是选择其中的一个样本即可。一般来说其步长的选择比梯度下降法的步长要小一点,因为梯度下降法使用的 是准确梯度,所以它可以朝着全局优异解(当问题为凸问题时)较大幅度的迭代下去,但是随机梯度法不行,因为它使用的是 近似梯度,或者对于全局来说有时候它走的也许根本不是梯度下降的方向,故而它走的比较缓,同样这样带来的好处就是相比于梯度下降法,它不是那么容易陷入到局部优异解中去。
2、Momentum
在深度学习中,Momentum(动量)优化算法是对梯度下降法的一种优化, 它在原理上模拟了物理学中的动量,已成为目前非常流行的深度学习优化算法之一。该算法将一段时间内的梯度向量进行了加权平均,分别计算得到梯度更新过程中 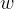 和
和 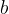 的大致走向,一定程度上消除了更新过程中的不确定性因素(如摆动现象),使得梯度更新朝着一个越来越明确的方向前进。
的大致走向,一定程度上消除了更新过程中的不确定性因素(如摆动现象),使得梯度更新朝着一个越来越明确的方向前进。
特点:
- 下降初期时,使用上一次参数更新,下降方向一致,乘上较大的
(动量因子)能够进行很好的加速
- 下降中后期时,在局部最小值来回震荡的时候,
,
- 在梯度改变方向的时候,
3、Nesterov
Nesterov动量优化算法是Momentum优化算法的一种改进。比较这两个算法的算法步骤,基本都一样,差别就在于应用临时更新这一句即先用当前的速度v先更新一遍参数,这样做后,Nesterrov算法比Momentum算法更新更快,因为在每一次更新的时候都是基于当前速度和梯度的更新,那我在求梯度之前就先进行一次对于当前速度的更新,就会加快收敛速度。nesterov项在梯度更新时做一个校正,避免前进太快,同时提高灵敏度。
4、Adagrad
Adagrad是解决不同参数应该使用不同的更新速率的问题,Adagrad自适应地为各个参数分配不同学习率的算法。Adagrad算法中有自适应调整梯度的意味(adaptive gradient),学习率需要除以一个东西,这个东西就是前n次迭代过程中偏导数的平方和再加一个常量最后开根号。该优化算法与普通的sgd算法差别就在于标黄的哪部分,采取了累积平方梯度。简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同。
5、Adadelta
Adadelta一种自适应学习率方法,是AdaGrad的扩展,建立在AdaGrad的基础上,旨在减少其过激的、单调递减的学习率。Adadelta不是积累所有过去的平方梯度,而是将积累的过去梯度的窗口限制为某个固定大小。使用Adadelta,我们甚至不需要设置默认学习率这一超参数,因为它已从更新规则中消除,它使用参数本身的变化率来调整学习率。
Adadelta可被认为是梯度下降的进一步扩展,它建立在AdaGrad和RMSProp的基础上,并改变了自定义步长的计算(changes the calculation of the custom step size),进而不再需要初始学习率超参数。 Adadelta旨在加速优化过程,例如减少达到优异值所需的迭代次数,或提高优化算法的能力,例如获得更好的最终结果。
6、RMSprop
针对 AdaGrad 算法每个元素的学习率在迭代过程中一直在降低(或不变),在迭代后期由于学习率过小,可能较难找到一个有用的解。为解决这一问题,RMSProp 算法对 AdaGrad 算法做了一点小小的修改。RMSProp优化算法和AdaGrad算法少数的不同,就在于累积平方梯度的求法不同。RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。
7、Adam
Adam是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam最开始是由OpenAI的DiederikKingma和多伦多大学的JimmyBa在提交到2015年ICLR论文(Adam:AMethodforStochasticOptimization)中提出的。
Adam与经典的随机梯度下降法是不同的。随机梯度下降保持一个单一的学习速率(称为alpha),用于所有的权重更新,并且在训练过程中学习速率不会改变。每一个网络权重(参数)都保持一个学习速率,并随着学习的展开而单独地进行调整。该方法从梯度的名列前茅次和第二次矩的预算来计算不同参数的自适应学习速率。
8、Adamax
是梯度优化算法的扩展,基于无穷范数的Adam的变体(a variant of Adam based on the infinity norm)。此算法对学习率的上限提供了一个更简单的范围,并可能对某些问题进行更有效的优化。AdaMax与Adam区别:本质上前者是将L2范数推广到L-infinity范数。AdaMax与Adam最终公式中仅分母的计算方式不同,AdaMax使用公式24,Adam使用公式20。
延伸阅读
Adam优化算法在非凸优化问题中的优势
- 直截了当地实现
- 高效的计算
- 所需内存少
- 梯度对角缩放的不变性(第二部分将给予证明)
- 适合解决含大规模数据和参数的优化问题
- 适用于非稳态(non-stationary)目标
- 适用于解决包含很高噪声或稀疏梯度的问题
- 超参数可以很直观地解释,并且基本上只需极少量的调参


文章包含AI辅助创作:常见优化方法有哪些,发布者:Z, ZLW,转载请注明出处:https://worktile.com/kb/p/34648
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 