









回归数据软件有哪些
常见的回归数据软件包括R、Python、SPSS、SAS、Stata和Excel等,不同工具在统计严谨性、易用性、扩展能力和企业级支持方面各有优势。R和Python适合高阶建模与机器学习扩展,SPSS和Stata更偏向应用统计与社会科学研究,SAS适用于大型企业级数据管理,而Excel适合基础回归分析。选择合适的软件应结合数据规模、行业需求与团队能力综合判断。未来回归分析工具将向智能化、自动化与云端化方向发展。
 Joshua Lee
Joshua Lee- 2026-04-03

数据回归有哪些方法
数据回归方法包括线性回归、多项式回归、岭回归、Lasso回归、逻辑回归、支持向量回归、决策树回归以及集成回归等类型。不同方法在模型假设、非线性处理能力、抗过拟合能力和计算复杂度方面存在差异。线性回归适合简单结构数据,正则化回归解决多重共线性问题,支持向量与决策树适用于复杂非线性数据,而集成回归在高维复杂场景下表现更优。实际应用中应结合数据规模、特征结构与业务目标综合选择合适模型,并通过交叉验证进行效果评估。随着数据规模增长,回归方法正向高性能与可解释方向发展。
- Joshua Lee
- 2026-04-03
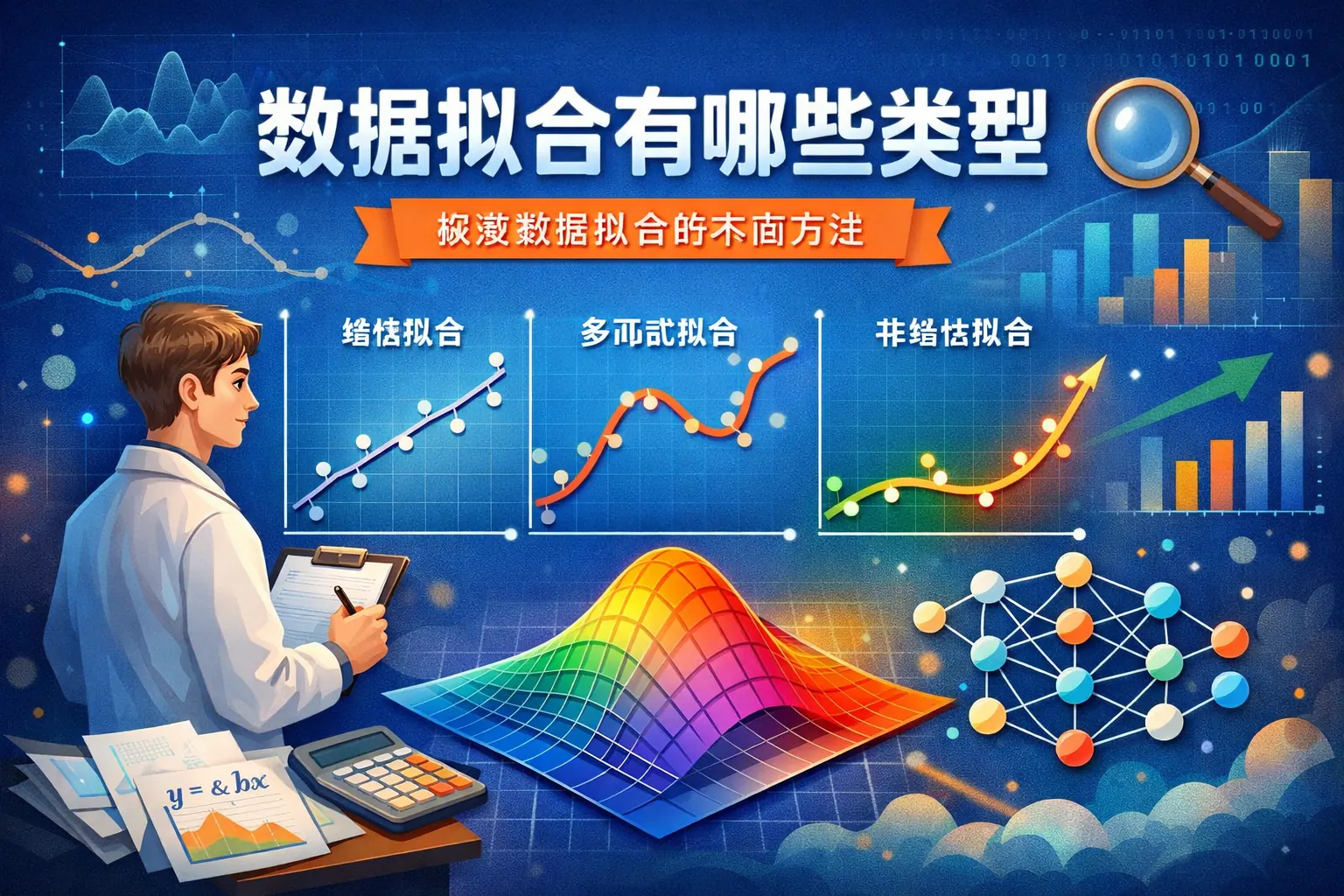
数据拟合有哪些类型
数据拟合主要包括线性拟合、多项式拟合、非线性拟合、指数与对数拟合、分段与样条拟合、回归模型拟合以及基于机器学习的复杂模型拟合等类型。不同方法在函数形式、复杂度和适用场景上存在明显差异。选择合适的数据拟合类型需结合数据分布特征、噪声水平、业务目标及模型复杂度权衡,在保证预测精度的同时兼顾解释能力与泛化性能。随着人工智能发展,数据拟合正向自动化与高复杂度方向演进。
- Rhett Bai
- 2026-04-03

回归分析哪些数据能用
回归分析可使用的数据类型包括连续型数值数据、计数型数据、分类数据、时间序列数据和面板数据,前提是变量可量化、样本充足且存在逻辑关系。不同数据需匹配不同回归模型,如连续数据适合线性回归,计数数据适合泊松回归,分类因变量适合逻辑回归。关键不在行业,而在数据结构与模型匹配程度。理解变量类型与统计假设,是判断数据是否适合回归分析的核心。
- William Gu
- 2026-04-03

回归数据有哪些方法
回归数据方法包括线性回归、多项式回归、岭回归、Lasso回归、逻辑回归、支持向量回归、决策树回归、随机森林回归和神经网络回归等。不同方法适用于不同数据结构与业务场景:线性模型强调可解释性,正则化方法提升稳定性,树模型和支持向量回归适合非线性关系,神经网络适用于复杂大规模数据。选择回归方法的关键在于数据特征、样本规模、变量关系及预测目标,在偏差与方差之间取得平衡。随着自动化建模与可解释性技术发展,回归分析正向智能化与融合化方向演进。
- William Gu
- 2026-04-03

假定数据包含哪些数据
假定数据是基于统计理论和业务逻辑构建的结构化数据体系,通常包含变量定义、样本规模设定、分布假设、参数区间、时间维度与情景边界等核心要素。它不同于真实数据,但在模型验证、趋势预测与风险评估中具有重要作用。高质量的假定数据需要满足逻辑一致性与统计合理性,并能够支持情景分析与参数敏感度测试。随着模拟与智能生成技术发展,假定数据将在数据分析与决策支持领域发挥更重要作用。
- Joshua Lee
- 2026-04-03

哪些数据算是高维数据
高维数据通常指变量数量接近或超过样本数量,或维度高到影响模型性能与计算效率的数据形态。其典型特征包括维度灾难、距离度量失效与过拟合风险增加。判断是否属于高维数据,应结合特征数量、样本规模及模型表现综合评估,而非仅看绝对数值。文本分析、图像处理与基因数据是常见高维场景。随着数据结构日益复杂,高维数据处理能力将成为数据分析的重要基础能力。
- Rhett Bai
- 2026-04-03

有哪些数据是平稳数据
平稳数据是指统计特征如均值、方差和自协方差在时间上保持稳定的时间序列。常见的平稳数据包括白噪声序列、满足稳定条件的自回归模型以及经过差分或对数变换后的趋势序列。判断平稳性通常结合图形分析和单位根检验等统计方法。由于大量实际数据原始状态下并不平稳,因此通过差分和变换将其转化为平稳形式,是时间序列建模和预测分析的重要前提。理解平稳性的本质,有助于提升数据建模的准确性与稳健性。
- Rhett Bai
- 2026-04-03

哪些数据是时间序列数据
时间序列数据是指以时间为索引、按顺序连续记录并具有时间依赖性的观测数据。凡是存在趋势、季节性或自相关结构,且分析结果依赖时间顺序的数据,都属于时间序列数据,如股票价格、销售额、气温变化和设备监测数据等;而单次静态统计或横截面调查数据则不属于时间序列范畴。理解时间序列数据的特征,有助于进行预测分析与趋势判断。
- Elara
- 2026-04-03

哪些数据属于高维数据
高维数据是指特征维度数量显著增加,并对模型计算、统计性质与算法表现产生实质影响的数据类型。当特征数量达到数十、数百甚至远超样本数量时,通常属于高维数据。图像、文本、基因测序、金融风控与物联网数据都是典型代表。高维数据常伴随维度灾难、数据稀疏、过拟合风险和计算复杂度上升等问题,因此需要通过降维、特征选择和正则化等方法进行处理。随着人工智能和大数据的发展,高维数据分析能力已成为核心竞争力。
- William Gu
- 2026-04-03

数据分析可以用哪些模型
数据分析可以使用多种模型,包括描述性模型、回归模型、分类模型、聚类模型、时间序列模型、因果推断模型以及机器学习和深度学习模型等。不同模型适用于不同数据类型与业务目标,例如回归模型适合连续值预测,分类模型用于类别判断,聚类模型用于用户分群,而时间序列模型强调趋势预测。随着人工智能发展,机器学习与深度学习模型在复杂场景中的应用日益广泛。企业应根据数据规模、分析目的与资源条件选择合适的数据分析模型,并构建系统化的数据分析能力。
- Joshua Lee
- 2026-04-03

有哪些高维数据分析方法
高维数据分析旨在解决特征数量庞大带来的维度灾难、过拟合与计算复杂度问题,其核心方法包括降维、特征选择、正则化建模、流形学习、集成学习与深度表示学习。线性方法如主成分分析适合结构压缩,非线性流形学习用于复杂模式探索,稀疏建模与正则化提升泛化能力,深度模型强化自动特征提取。不同方法各有优势,实践中需结合数据特性与目标进行组合应用,以实现稳定、高效、可解释的高维数据建模。
- William Gu
- 2026-04-03

因子分析数据模型有哪些
因子分析数据模型主要包括探索性因子分析、验证性因子分析、主成分分析、高阶因子模型、双因素模型以及结构方程模型中的测量模型。不同模型在是否预设结构、是否强调理论验证以及应用阶段上存在明显差异。探索性因子分析用于结构发现,验证性因子分析用于理论检验,而高阶与双因素模型则用于构建更复杂的层级或综合结构。合理选择因子分析模型,应结合研究目标、样本规模与理论成熟度,从而提升数据建模的科学性与解释力。
- William Gu
- 2026-04-03

非线性数据的特点有哪些
非线性数据的核心特点在于变量之间不存在简单的比例或加和关系,而是呈现曲线型、多阶段或突变式变化,表现为边际效应不恒定、高阶交互显著、局部线性但整体复杂以及对扰动较为敏感等特征。与线性数据相比,非线性数据更贴近现实系统的运行规律,但建模难度更高,需要通过多项式拟合、特征变换或更灵活的建模方法进行分析。理解非线性数据的结构特征,是提升预测准确性和决策科学性的关键前提。
- William Gu
- 2026-04-03

数据拟合常用软件有哪些
数据拟合常用软件包括 MATLAB、Python、R、Origin、SPSS、SAS 和 Excel 等,不同工具在算法深度、可视化能力与自动化水平方面各有优势。科研与工程领域更偏好 MATLAB 与 Python,统计建模常用 R,实验数据处理常见 Origin,商业分析多使用 SPSS 或 SAS,而 Excel 适合基础拟合需求。选择合适的软件应结合数据规模、模型复杂度与团队技能,并关注未来智能化与自动化发展趋势。
- William Gu
- 2026-04-03

贝叶斯模型需要哪些数据
贝叶斯模型所需数据包括先验数据、观测样本数据以及描述数据生成机制的似然结构。先验数据来源于历史经验或领域知识,观测数据用于更新概率分布,而似然函数则定义数据与参数之间的关系。与传统统计方法不同,贝叶斯方法强调知识与数据融合,在小样本和不确定性较高的场景中具有明显优势。构建模型前需确保数据结构清晰、质量可靠,并验证分布假设。未来随着计算能力提升,贝叶斯模型将在预测分析与决策支持中发挥更大作用。
- Elara
- 2026-04-03

线性数据处理方法有哪些
线性数据处理方法是基于变量之间线性关系假设构建的一类基础数据分析技术,常见方法包括线性回归、线性判别分析、主成分分析、线性插值、线性滤波与矩阵分解等。这类方法具有计算效率高、模型结构清晰、解释性强等优势,广泛应用于预测建模、分类分析、降维处理与信号处理等场景。尽管在线性假设下存在一定局限,但在高维小样本与强调模型透明度的应用环境中仍具有重要价值,并将在未来与复杂模型融合发展。
- William Gu
- 2026-04-03

数据分析有哪些假定模型
数据分析中的假定模型是对现实数据结构与变量关系的理论设定工具,常见包括线性模型、概率分布模型、时间序列模型、因果模型、机器学习模型、贝叶斯模型与聚类模型等。不同模型基于不同前提条件,如分布假设、独立同分布假设或时间依赖假设,各自适用于不同分析目标。理解模型假定的逻辑基础与验证方法,是提升数据建模能力与决策科学性的关键。未来趋势将向弱假设化、融合化与可解释方向发展。
- Rhett Bai
- 2026-04-03

定量数据分析模型有哪些
定量数据分析模型主要包括描述统计、回归分析、时间序列、分类与聚类、因果推断以及预测与综合评价模型等类型。不同模型适用于不同的数据结构和分析目标:描述统计用于概括现状,回归模型用于解释变量关系,时间序列适合趋势预测,分类与聚类用于模式识别,因果模型用于效果评估。随着数据技术发展,多模型融合与智能化分析成为趋势,科学选择模型是实现数据驱动决策的关键。
- Joshua Lee
- 2026-04-03

哪些数据可以做虚拟变量
可以做虚拟变量的数据主要包括二元类别数据、多类别名义数据、分组后的连续变量、时间阶段变量以及实验处理变量,其核心特征是表达“类别差异”而非连续数值大小。通过合理编码,这些数据能够被纳入回归分析和机器学习模型中,提高解释力与分析稳定性。但在实际应用中需避免多重共线性和信息损失问题,结合业务逻辑选择合适的编码方式。虚拟变量作为统计建模基础方法,在数据分析与因果推断中具有长期价值。
- William Gu
- 2026-04-03