








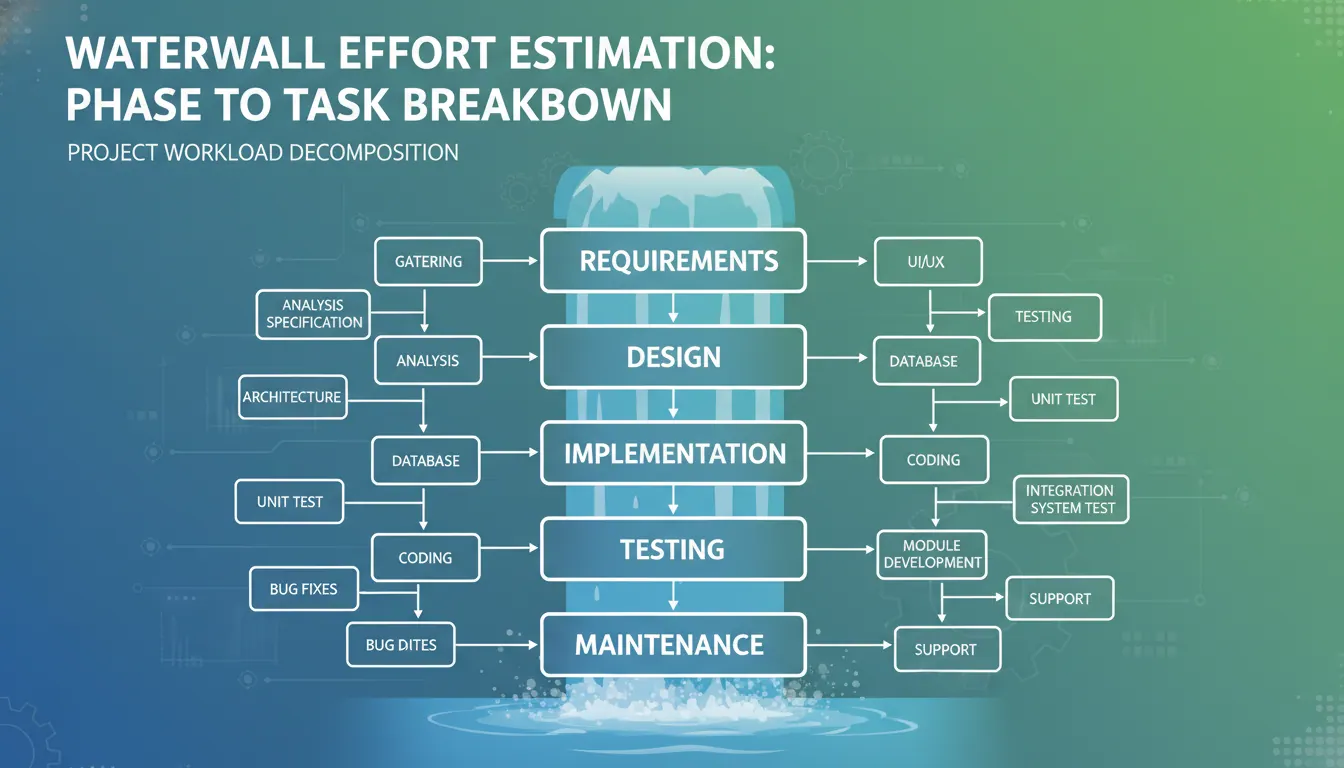
瀑布模型项目工作量估算怎么拆?从阶段到任务
在瀑布模型中,项目推进有明确的阶段边界。如果不按阶段拆分工作量,很容易出现需求、设计、开发和测试之间的责任不清,导致估算偏差扩大。按阶段拆分可以让团队更清楚每一段要交付什么、投入多少人力、有哪些依赖关系,也便于管理进度和控制风险。
按阶段拆分能让估算更贴近实际交付节奏
瀑布模型的特点是阶段清晰、文档完整、交付有序。将工作量按需求、设计、开发、测试、上线等阶段拆开,可以把每一段的目标和产出对应起来,估算时更容易识别遗漏项。这样做还能帮助识别跨阶段返工成本,提升整体排期和资源配置的准确性。
很多项目在拆任务时,往往只看到编码和测试这类显性工作,却忽略了评审、沟通、环境准备、文档整理、缺陷修复和验收支持等隐性工作。尤其在瀑布模型里,阶段间交接较多,如果不把这些辅助任务算进去,实际工时通常会明显高于预估。
隐性任务往往比显性开发任务更容易造成漏算
容易被漏算的内容包括需求澄清、方案评审、接口联调、测试数据准备、回归修复、上线支持和文档更新等。估算任务时,建议把每个阶段的交付物拆到可执行动作,再补充沟通和管理成本,这样工作量会更完整,也更接近真实投入。
如果只是根据经验粗略给出总工时,很容易忽略项目复杂度、接口数量、历史遗留问题和团队熟练度差异。很多项目表面上规模相近,实际工作量却差很多。项目经理需要有一套可追踪的拆分方法,把总目标分解到阶段,再分解到具体任务,并结合历史数据校准。
用分解、对标和校准三种方式可以减少主观误差
避免拍脑袋估算的关键在于把大目标拆成可衡量的任务项,并参考历史同类项目的工时数据。还可以结合复杂度分级、接口数量、页面数量、异常场景数量等指标进行修正。估算完成后,建议组织技术、测试和业务一起复核,能有效降低单人判断带来的偏差。
任务拆得太粗,估算会失真,执行时也很难跟踪;拆得太细,又会增加管理成本,影响估算效率。很多团队会困惑到底要拆到模块、功能、页面,还是拆到接口和用例。合理粒度需要兼顾可估算、可执行、可追踪这三个目标。
以“可独立估算和验收”为粒度参考更实用
一般建议把任务拆到团队成员可以单独理解、单独执行、单独验收的程度。比如开发任务可拆到具体功能点、接口、页面或复杂逻辑单元,测试任务可拆到测试设计、用例编写、执行和缺陷验证。只要拆分后能清晰判断工作范围、依赖关系和交付结果,这个粒度通常就比较合适。