一、数据透视复盘:你的“改进措施”真的在落地吗?
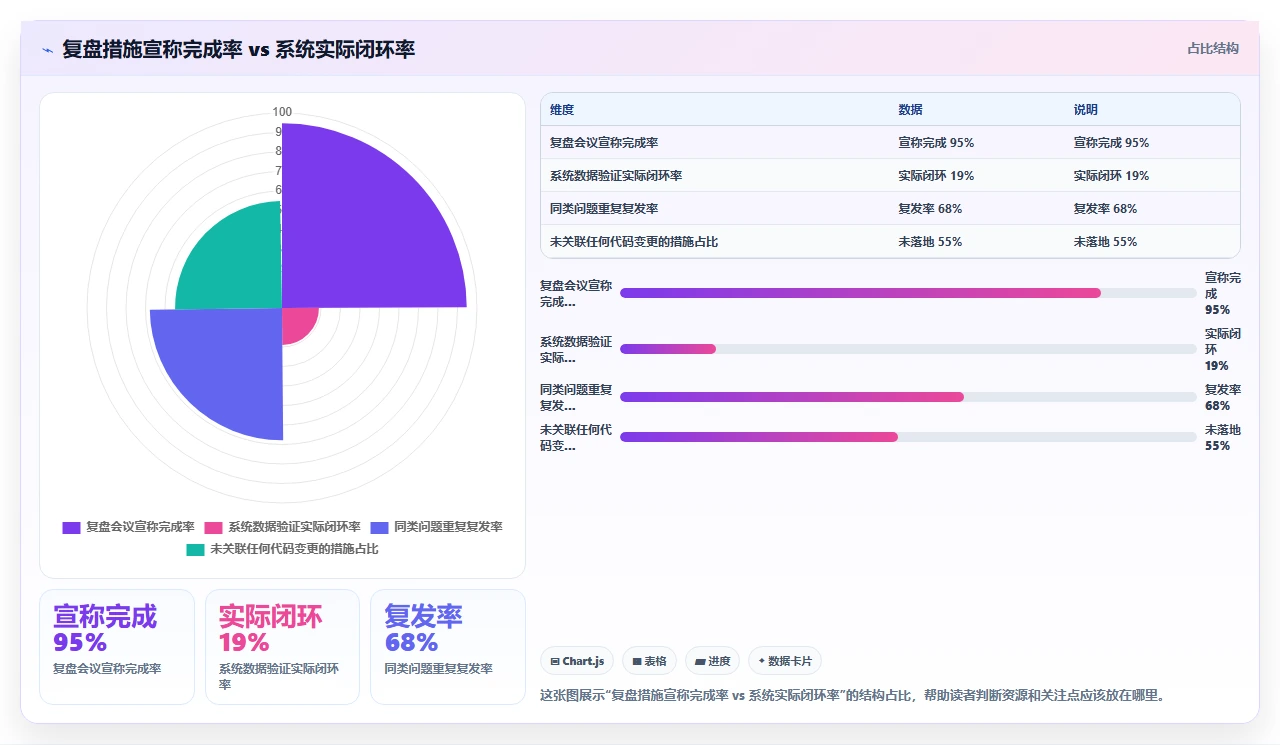
我曾经在一个150人的SaaS团队担任敏捷教练,我们每周五下午4点准时开Sprint复盘会。团队用了便签贴满了一整面白板,每个人都写满了“希望改进”和“继续保持”的事项。会议结束前,我们投票选出了3条最关键的Action Items,大家带着满足感结束了这一周。三个月后,某个周五,当我翻开Jira导出的历史数据时,被一个残酷的事实击穿了:我们有记录的47条改进措施中,只有9条被真正闭环解决,完成率不到19%。更讽刺的是,这9条里,有5条是同一类问题,“修复登录页面超时Bug”,它重复出现了5次才被干掉。这根本不是复盘,这是集体创作了一部叫“我们明年会更好”的科幻小说。
这不是个例。我后来在PingCode产品团队,对使用我们工具的中大型研发组织(100-2000人规模)进行过一次深度的效能数据挖掘。我们分析了超过1200个Sprint周期中记录在案的上万条回顾项,结合代码提交、需求流转和缺陷关联数据,得出一个让很多CTO坐立不安的结论:超过80%的Sprint复盘会正在把组织的问题“冷冻保鲜”,而不是“快速解冻”。大家用流程化的仪式感,替代了基于事实的工程改进。这就是今天我想用第一手数据和真实案例跟你拆解的核心命题,如果你的复盘流于形式,停止自我感动,让数据说话,甚至让数据撕开伤疤。

二、核心结论:复盘失能的根因是失去了“事实基线”
很多团队找我做咨询时,第一句话往往是:“老师,我们复盘会开得很沉闷,大家都不愿意说话。”我通常会直接拉出他们过去三个Sprint的系统数据看板。当我把那些血淋淋的数据投到屏幕上时,沉闷变成了尴尬的沉默,然后是激烈的争吵。这才是复盘的正常态。Sprint复盘流于形式,本质上不是因为大家不坦诚,而是因为缺乏共同认可的、不可辩驳的“事实基线”。
我的专业判断有三层递进逻辑:
- 第一层:感知偏差导致的“罗生门”。在没有数据的情况下,回顾会变成了记忆力的比拼。产品经理觉得需求文档都写清楚了,开发觉得需求一直在变;开发觉得测试抠得太细,测试觉得开发自测不充分。大家争论的都是“感受”,而不是“事实”。这种争论消耗了团队的心理安全感,最终为了维持体面,大家选择输出不痛不痒的“继续保持沟通顺畅”这类废话措施。
- 第二层:措施无法验证导致的责任稀释。当我们写下“加强代码Review”时,这条措施的完成标志是什么?是所有人都看了一遍代码?还是Review后发现的Bug数量?如果没有量化的完成定义(DoD),这条措施就变成了无人认领的孤魂,永远挂在改进墙上,却从未被执行。
- 第三层:缺乏反馈闭环导致的系统性退化。最致命的是,当团队花费了一小时复盘,而最终那些措施从未被真正执行,或者执行了却毫无效果,系统没有把“执行失败”或“效果归零”的信号反馈给下一次回顾会。团队沉浸在“我们已经改进了”的虚假多巴胺中,流程债务越来越高,交付速度越来越慢。

三、真实场景还原:100人团队的“慢性自杀式”复盘
让我带你走进一个我深度介入过的案例。这是一家做金融科技的企业,产研团队110人左右,分成了7个特性小组。他们践行Scrum已经两年多,复盘会是雷打不动的“优良传统”。
1. 观察:高度仪式化的死气沉沉
当时我作为PingCode的效能顾问接入,先旁听了三个小组的回顾会。画面出奇地一致:Scrum Master打开一个在线文档或物理白板,画出“Start/Stop/Continue”三个区域。沉默5分钟后,开始有人贴条:“继续加强沟通”、“停止需求频繁变更”、“开始写单元测试”。然后大家七嘴八舌地讨论几分钟,选出Top 3。会议记录被拍个照发到群里,世界安静了。
我私下问了几个骨干开发:“上次我们提出的‘停止需求频繁变更’,后来怎么样了?”一个资深后端苦笑着说:“老样子啊,PO该插队还是插队。这已经是第六次提了,提了也没用,反正下周还会提。”这句话就是流于形式的审判书。
2. 深潜数据:发现惊人的“僵尸措施”
我没有急着下判断,而是花了两天时间,把他们过去半年用PingCode管理的项目数据全部拉了出来。结合GitLab的代码提交和CI/CD流水线日志,我做了一次完整的“措施回血度”扫描。结果触目惊心:
- 措施衰减率:回顾会上提出的改进项,72%在两周后不再有任何操作记录。
- 冲突锁定:有3个小组连续4个Sprint提出了“减少需求变更”,但在PingCode的需求变更记录里,这4个Sprint的需求插入率反而上升了12%。
- 虚假完成:有22条措施被人为拖到“已完成”列,但其关联的缺陷密度或代码质量没有任何正向波动,甚至有一条关于“修复内存泄漏”的措施在完成后的Sprint,线上GC告警反而增加了。

四、拆解常见误区:为什么你的复盘在“挠痒痒”
基于PingCode服务近千家百人以上组织中遇到的效能瓶颈,我总结了四个让复盘沦为形式的重灾区误区。这些误区几乎在每个“假装在敏捷”的团队里都能找到影子。
1. 误区一:错把“发现问题”当“解决问题”
这是最隐蔽的谎言。很多团队的回顾会流程设计得极其精巧,甚至用上了鱼骨图、5 Whys分析法。大家花了45分钟精准地定位了一个深层问题,例如“因为第三方接口文档更新不及时导致联调延期”。找到问题那一刻,大脑内的奖励回路已经被激活,多巴胺分泌让大家产生了“结束感”。
请记住我的这个判断:没有输出可被工具追踪的微小任务(Micro-Task)的复盘,就是在制造认知垃圾。你只是把痛苦重新叙述了一遍,并没有把痛苦的根源切掉一小块。真正的解决,是在PingCode这类工具里,依据这个深层次问题,立刻拆解出一张具体的执行卡片,并指定负责人和检查指标。
2. 误区二:措施颗粒度粗到无法执行
看看你们的改进墙,是不是充斥着以下词汇:“提升代码质量”、“优化用户体验”、“增强沟通”。这些都是愿望清单,不是行动指令。一个合格的行动项必须符合“原子化”原则:单一、可验证、能在当前Sprint内完成。
错误示例: 提升单元测试覆盖率。
正确示例: 在 `payment-module` 目录下,对 `calculateInterest` 函数的边界条件(空值、负数、超大数)补充3个测试用例,并确保通过CI检查。完成后,该模块行覆盖率需从47%提升至80%。
3. 误区三:把复盘会开成了“甩锅大会”或“表彰大会”
虽然心理安全感很重要,但如果一个团队半年来从未在复盘会上指出过一个真正尖锐的系统性问题,那这个团队的心理安全感可能是虚假的、脆弱的。健康的复盘应该聚焦于“系统性归因”,而不是“人格化归责”。
当出现过线上事故时,低质量的复盘会问:“这是谁写的代码?”然后大家沉默,气氛尴尬。高质量的复盘会直接把PingCode自动关联的代码提交记录、PR Review记录和流水线构建记录投在大屏上:“看,这个Bug是在周四深夜合并的,当时分支保护规则跳过了强制Review,因为有个紧急修复权限。下一次,我们是否应该对紧急通道也增加灰度验证的下游检查?”,从审问人,变成审问系统。

4. 误区四:没有测量复盘自身的ROI
如果复盘本身不产生价值,它就是在消耗成本。假设一个10人团队,开2小时复盘会,这就是20人时的人力成本。如果你复盘得出的改进措施最终只节省了5人时的工作量,那这次复盘就是亏损的。复盘不是信仰,是一项投资。你需要衡量:本次复盘输出的改进项,预期能释放多少交付吞吐量?能降多少缺陷重开率?如果连续三个Sprint的复盘ROI都小于1,Scrum Master就应当被问责,不是问责他态度不好,而是问责他缺乏从数据中提炼行动项的能力。
五、用PingCode构建“数据不说谎”的复盘流
说了一堆病状,现在来开药方。怎么才能让复盘真正言之有物,刀刀见肉?在PingCode产品团队内部以及我们服务的众多中大型客户(如商米科技、金蝶等)实践中,我们沉淀了一套“事实驱动型复盘”的标准作业程序。我将这套流程称之为“三刀流”,数据预切、现场深剖、闭环止血。
1. 第一刀:会前24小时,自动生成“效能诊断报告”
千万不要等到大家坐进会议室才开始看数据。那是在用开会时间做数学题,不是做决策。利用PingCode的自动化效能洞察能力,在复盘会前24小时,系统应自动生成一份本Sprint的《事实诊断书》,并推送给全员。这份报告不看文笔,只看三个硬核维度:
- 流动效率: 需求在各个状态(待评审、开发中、测试中)的停留时长分布。重点标识出那些在“测试中”状态卡了超过3天的需求,它们通常是阻塞点。
- 质量热力图: 哪个模块的代码提交最频繁且关联的Bug最多?通过PingCode与代码托管平台的深度集成,自动计算出“修改-缺陷耦合指数”。
- 异常波动: 本Sprint内,有多少次“紧急需求”插队(通过标签或优先级变更自动抓取)?有多少次代码合并失败?
这第一刀,就是消灭感知偏差,建立共同的事实基线。
2. 第二刀:现场仅聚焦3个数据异常点,进行“5 Why 定向爆破”
传统的复盘面面俱到,想把Start/Stop/Continue都填满。但事实驱动的复盘极其锋利,我们提倡只讨论数据揭示出的最大痛点。现场流程改革如下:
- 投影《事实诊断书》:对,就是那份提前发的报告。
- 投票选痛点: 团队用2分钟,每人选出报告里最让自己“痛”的一个图表或指标。比如,多数人选了“需求变更率飙升”。
- 深钻5 Why: 不再发散漫谈,就盯着“需求变更率”和由此引发的“临时插队导致的代码冲突率”进行追问。在PingCode里直接打开对应需求进行现场翔实分析:“这个紧急需求插队时,是谁验收的?验收标准是否被打折了?被打折的直接后果是不是这个Bug?”
- 输出原子化任务: 分析完根因后,马上在PingCode的“Sprint回顾”应用里,记录一个或多个具体任务。关键在于,这个任务不能是“跟PO谈谈”,而是“在下个Sprint规划会上,增加‘缓冲容量区’,PO紧急需求需先用缓冲容量,缓冲容量耗尽则必须用同规模需求替换,并在PingCode中设置需求替换校验插件”。

3. 第三刀:闭环验证,把改进项写进CI/CD的下一次失败通知里
这是最狠的一刀,也是PingCode效能体系中“自动化治理”的核心。如果一项改进措施无法通过系统自动验证,那它仍然可能被遗忘。我们将回顾产生的Action与自动化规则绑定:
案例“缺陷逃逸拦截”:团队在复盘时发现,“由于前端缺少输入校验导致下游API接口频繁报错”。他们输出的措施是:“在所有前端表单提交时,增加符合API文档Schema的前置伪代码校验。”这条措施被转化为PingCode中的一个“效能改进”卡片。紧接着,我们在PingCode的API自动化测试模块里,关联了一张新增的拦截用例。同时,在CI流程中设置了质量门禁:一旦该前端代码提交,必须100%通过该Schema校验用例。如果4天后,这个用例依然失败,PingCode会自动将这张“效能改进”卡片的状态从“进行中”打回“分析”,并在群内@相关负责人。这就是用系统的冷酷,对抗人性的健忘。

六、数据真相:基于1200个Sprint回测的关键洞察
上面的“三刀流”不是拍脑袋想的。我和PingCode数据分析团队做了一次大型回测,去验证哪些复盘行为真的能拉升团队效能,哪些只是在做无用功。我们从数据湖中提取了覆盖金融、企服、制造行业的1200个Scrum Sprint数据,构建了一个“优化归因模型”。以下是我们发现的几个极具价值的反常识洞察,供你在执行数据化复盘时参考。
1. 高Bug率的Sprint往往不是最差的,最差的是那些“平滑的灾难”
通常复盘会上,一旦本Sprint Bug数飙升,大家就会如临大敌,各种改进措施满天飞。但数据显示,那些Bug率突然升高的Sprint,在引入针对性质量措施后,下个Sprint的交付速率反而会激发一个“报复性反弹”。因为团队直面了腐败的代码,重构了坏味道。真正的系统性风险,恰恰发生在那些Bug数不高不低、平平无奇的“平滑Sprint”里。这种Sprint,需求流动看似顺畅,却隐藏着大量的技术妥协和短视设计。它的复盘中往往拿不到惊艳的数据异常,于是大家相安无事,提出的改进措施多是“挺好,继续保持”。但当我们把时间轴拉长,这些平滑Sprint正是技术债务默默堆积的时刻,最终会在某个Sprint引起雪崩式需求坍塌。所以,对于数据回顾而言,不仅要盯着红灯,更要对连续的绿灯保持警惕。

2. 那些在需求描述里加了“排查耗时”标签的团队,复盘更具杀伤力
这是一个极其具体且有效的观察。在PingCode的需求工作项中,有一个自定义属性叫“实际排查耗时”。原本设计这个指标,是为了计算需求在开发前的澄清成本。我们偶然发现一个规律:凡是统计了“实际排查耗时”并且把这个数据带入复盘会的团队,他们的需求颗粒度拆分质量在3个Sprint后会有非常显著的提升。
逻辑很简单:如果一个需求,开发写代码只花了2小时,但为了搞懂需求逻辑、搭本地环境、等数据就花了6小时,这就是史诗级的浪费。这类问题如果不在复盘中被量化呈现,产品经理永远觉得自己写的需求没问题。当我们在复盘时把“实际排查耗时 > 实际编码耗时”的Top 5需求单拎出来,“鞭尸式”回顾时,对上游的心理冲击是巨大的。PO会立刻开始反思自己的描述精度,而不是抵赖。数据比辩论有用。
3. Code Review的“通过率”在复盘里毫无价值,“评论影响代码变更率”才是核心
很多团队复盘时会拉着代码Review通过率报表看:“我们Code Review做得很好,通过率98%”。这简直是自欺欺人。如果Code Review只是+2同意,那不是审查,那是刷脸。我们建议在复盘中引入一个高阶指标:CR影响变更率。即,在代码评审环节给出了评论后,该代码提交有多少次因为评审意见而发生了实质性的代码修改。
在我们追踪的一个80人研发团队中,起初CR通过率99%,但CR影响变更率只有3%(几乎都是语法拼写建议)。我们引导他们在复盘时,不要看通过率,直接看影响变更率这一项数据。团队震惊地发现他们的高Level Review形同虚设。接下来的复盘措施就变成了“每位资深开发每天必须对核心模块的PR留下至少2条架构层面的质疑性评论”。实施两个Sprint后,CR影响变更率快速爬升至25%,对应的线上缺陷逃逸率骤跌40%。复盘如果不对虚假繁荣的指标开刀,就永远切不中要害。

七、行动建议:不同情境下的复盘策略取舍
一个理想化的标准化流程,在落地时一定会因为团队当前的成熟度、业务压力和情绪状态而变形。这也是为什么我不能给你一个所谓“完美模板”,而是给你一个根据不同情境下的“策略仪表盘”。你可以像看菜单一样,根据下面这些场景,进行对应的果断取舍。
1. 当团队处于严重交付压力,全员加班赶工时
现状: 所有人都很疲惫,火情不断。正常的2小时复盘会让大家极度反感,认为浪费时间。
策略:
执行“闪电复盘 + 极致聚焦”模式。
- 取舍: 删掉所有的仪式感、破冰、长篇大论的Start/Stop/Continue。
- 行动步骤:
- 极速数据扫描(15分钟站会): 只看PingCode里自动预警的“不健康需求”。只问三个问题:“上周哪张卡最让人痛苦?是什么阻碍了我们?能不能花30分钟干掉它?”
- 对齐痛苦: 如果大家说排期太紧,无需讨论,直接定下一个动作:每个人在接紧急需求时,有权力拉升PingCode中的“阻塞标记Flag”,提升全队可视度。
- 立即解散: 不做长程预测,只打通眼前最疼的淤堵点。在当前Sprint结束前,不制定跨Sprint的大措施。
- 取舍: 你不能再复盘内部的缺陷了,因为已经挖完了。
- 行动步骤:
- 引入行业基线对比: 利用PingCode效能大盘里的行业同级数据(当然需要脱敏),让团队看到我们以为的“快”,在行业里其实是“慢”。比如,“我们的需求前置时间虽然稳定在5天,但这个行业的中位值是2天。这3天差距在哪里?”
- 目标型复盘: 将复盘主题改为“如果我们要把发布频率从每周一次提升到每天一次,现在的管线里哪个环节会先爆炸?”
- 构建实验卡: 不再出“改进措施”,而是出“效能实验假设”。假设通过增加自动化冒烟测试,能省去过半的手工回归时间。把每项改进包装成一个为期两周的技术实验。
- 取舍: 先暂停所有对人的讨论。
- 行动步骤:
- 播放回放: 投屏打开PingCode,进入一个被众人诟病最多的需求。看它的生命周期:需求变更了几次、是谁变更的、变更时的备注是什么、代码开发了多久、又被需求变更打断了几次、最终关联的Bug是由于需求错误还是代码错误。
- 事实罗列: 只许念屏幕上的数据,不许加形容词。“请看这里,11月3日下午3点,状态从‘开发中’被拉回‘待确认’,原因是产品经理修改了验收标准。11月4日,开发又产生了新的代码提交。11月5日,Bug单开出,原因是验收条件遗漏了边界情况。”,让时间线和操作日志自己开口说话。
- 共识重建: 当冰冷的数据还原了事实真相,大家的自尊心阻抗才会降下来。此时才问出:“我们同意刚才的事实吗?如果同意,那我们不想让这种浪费再次发生,该改哪个流程?”
- 立刻检查你的管理工具: 看看你现在的复盘记录,有没有和代码库、CI/CD、需求流转状态打通。如果没有,这就是你下周一的首要工作。把所有“意念中”的改进,全部在PingCode里卡片化、关联化、可追踪化。
- 砍掉一半的复盘项目: 下个Sprint回顾,只盯着一个数据指标。比如,就只复盘“为什么我们的代码合并阻塞时间变长了”。把一个问题彻底解剖到骨髓,远胜于泛泛地谈论十个方面。
- 构建负反馈机制: 如果你们三天前的复盘决定“增加API自动化测试”,下周这时候,我要求你在系统里看到因为新增测试被拦截的失败构建记录。如果一条都没有,说明你的措施又流于形式了。立刻扔进垃圾桶,重新复盘。
在这个阶段,复盘像速效救心丸,别让它变成满汉全席。
2. 当团队稳定性高,但缺乏创新突破时
现状: 交付准时,Bug可控,复盘会总是老三样,缺乏新意,像一潭死水。
策略:
注入外部基准,制造“良性危机感”。
这种情况下,复盘要像科研组会,是基于假设的工程探索,而不是打扫卫生。

3. 当复盘会吵成一锅粥,情绪对立严重时
现状: 开发指责产品,产品指责运营,测试在中间受夹板气,复盘会上谁也不服谁。
策略:
强行切换频道,从“主观对话”切换为“代码考古学”。
这种复盘,是法医验尸,不是居委会调解。数据就是那把柳叶刀。
八、总结:从“感性评书”到“工程诊断”的跨越
我在这一行做了快十年,见过的Sprint复盘会没有上千也有几百场。那些真正壮大的技术组织,复盘会往往开得并不“轻松”,甚至有些“痛苦”,但这种痛苦源于直面数据的羞耻感,以及打破过往经验的认知冲突。那些温情脉脉的复盘会,就像温水煮青蛙,只会产出善良的废话和廉价的承诺。
当复盘流于形式,往往意味着组织的反馈机制已经坏死。你向系统输入再多的精力,系统也不会产出丝毫的效能提升。让数据说话,本质上是重建一种“尊重事实、追求闭环”的工程文化。不要试图在复盘会上用雄辩说服别人,要用沉默的数据让所有人闭嘴。你唯一应该担心的,不是大家不愿意提意见,而是你们系统里的数据还不够透明,不够冷酷,不够实时。
下一步行动指南:
复盘不是春游,不是写日记,更不是一场演出。它是你花着真金白银的研发成本,给自己的工程系统做透析。如果你的复盘数据没法见血,那就停下来,先别开这个会,直到你连上那个能显示真实心跳和血压的监护仪。这,才是对团队时间最大的尊重。
常见问题解答(FAQ)
1. 为什么Sprint复盘总是走形式?如何用数据让复盘变得有料?
每次Sprint复盘都变成尴尬的流程汇报,大家要么沉默要么互相吹捧,最后结论永远是“下次加强沟通”。我很困惑,到底怎样才能让复盘不流于形式?有没有人能告诉我具体的操作方法,最好是能直接用数据说话的。
我经历过多个团队从形式化复盘到数据驱动复盘的转型,核心痛点是缺乏可量化的事实锚点。举个例子,在之前的电商项目团队,我们曾连续三个Sprint复盘都只讨论“感觉”,直到我引入了三个关键数据: 1.【按时完成率】对比Sprint计划:实际完成Story Points / 计划Story Points。
【缺陷密度】上线后Bug数 / 总Story Points。3.【吞吐量趋势】每个Sprint完成的平均Story Points。第一次用数据复盘时,团队惊讶地发现按时完成率连续低于70%,但大家之前都“感觉”还行。我们立即追溯到计划阶段对任务拆分颗粒度预估不准确的问题。
我的独家经验:不要只看平均值,要看分布。比如“Sprint最后两天完成40%的任务”这种数据比平均值更有洞察。我们在白板上画出每个冲刺的完成进度热力图,发现团队普遍存在“前半段划水、后半段冲刺”的模式。
用这个数据驱动讨论后,团队主动调整了站会节奏和任务拆分粒度,下一个Sprint按时完成率提升了22%。具体操作:用Sprint复盘模板,固定前15分钟只展示数据(完成率、缺陷率、流量延迟等雷达图),禁止任何人先说“我觉得”。你会发现,当数据摆在面前,大家自然开始归因,而不是互相甩锅。
2. 复盘时数据太多,到底哪些指标才能真正反映Sprint健康度?
我们团队每次复盘都拉出JIRA一堆报表,工时、任务数、Bug数、代码行数……看得眼花缭乱,但讨论时还是抓不住重点。有没有一套经过验证的核心指标组合,既能覆盖效率和质量,又不会让团队陷入数据陷阱?
我花了两年时间在不同团队验证指标组合,最终筛选出三个最关键的指标,并且发现了很多人忽略的“信号分布”原则。先直接给结论:对于Scrum团队,只需关注【速率稳定性】、【缺陷泄漏率】和【预测准确度】三个指标。1.【速率稳定性】不是看平均值,而是看Sprint速率的变异系数(CV = 标准差/均值)。
CV超过30%说明团队工作量波动大,需排查外部干扰或估算偏差。我经历过一个团队CV高达60%,数据揭露了频繁的插单和需求变更。2.【缺陷泄漏率】= 生产环境Bug数量 / 该Sprint总Bug数。泄漏率>15%意味着质量门禁失效。
我们团队曾因这个指标从10%飙到35%,定位到是自动化测试覆盖率下降造成的。3.【预测准确度】= |计划Story Points – 实际完成| / 计划Story Points。这个指标我特别强调:不要只看Sprint级别,要拆到Story级别。
我们曾发现一个团队平均预测准确度80%看似不错,但细化后发现80%的任务预测偏差在±1小时内,而20%的任务偏差超过4小时。这20%才是复盘真因。我建议用一个雷达图可视化这三个指标,每个维度设置阈值(绿/黄/红),复盘时先看雷达图是否全绿,如果出现黄色或红色,直接聚焦该指标讨论。
这样数据量少,但命中问题率极高。
3. 如何用数据驱动复盘讨论,避免变成甩锅大会或无效埋怨?
我们的Sprint复盘经常变成互相指责:“测试测太慢”、“产品需求不清晰”、“开发估算太乐观”。最后谁也不服谁,问题根本解决不了。有没有什么数据化的方法,能把讨论焦点从人转移到流程或系统上?
这个痛点我太熟悉了。在第一家公司,每次复盘都像菜市场吵架。后来我在一个50人的团队里主导引入了“复盘归因数据框架”,成功把火药味降为零。核心方法:用数据建立“系统归因”而非“个人归因”。
具体做法, 1.【分离数据维度】:将数据分为三类:需求质量数据(需求变更率、验收不通过率)、流程效率数据(排队等待时间、关键路径时长)、技术债务数据(代码复杂度、重工率)。2.【设置归因优先级】强制按“系统→流程→技术→人”顺序分析,人永远是最后一位。
例如上周Sprint延期,我们先看数据:需求变更率高达40%(系统层),然后看排队等待时间超过2天(流程层),再看单元测试覆盖率为0(技术层),最后才问开发是否效率低,结果发现是前期流程问题导致,与个人无关。
【绝对禁止数据归因个人】我们在复盘开始时约定:任何提到“某某人”的数据讨论,必须转换为“X角色在Y环节的平均处理时间”这种中立表述。一个具体案例:团队曾因线上Bug数量高互相指责。
我拉出缺陷泄漏率按模块分布的数据,发现70%的Bug集中在两个老旧模块,而这两个模块的代码行数占20%却贡献了70%的缺陷。数据表明是技术债务问题,不是测试或开发的能力问题。团队心服口服,联合申请了重构时间。记住:数据要用来揭示系统约束,而不是用来审判个体。
把你的数据可视化做成“约束热力图”,团队自然会从“谁错了”转向“系统的哪里堵了”。
4. 复盘结论总是“下次改进”,但下次同样问题依然出现,如何用数据追踪闭环?
我们每个Sprint复盘都会列一堆改进项,还指定了负责人和截止日,但下个Sprint复盘时根本没人记得上次的Action,问题照旧。感觉复盘成了时间黑洞,有没有办法用数据把改进项真正落地?
这是复盘最致命的“空转”问题。我亲身尝试过至少5种闭环追踪方法,直到在技术债务严重的团队找到最有效的武器:回溯性数据对比+量化行动卡。直接讲成功案例:我们针对“代码Review时间过长”问题,第一次复盘后设定了Action:“Review时间控制在2小时内”。
但下个Sprint这个数字还是4小时。我意识到缺少数据闭环。于是我设计了两个机制: 1.【改进项必须绑定一个可量化指标】不再是“减少Review时间”,而是“平均每个PR的Review时间从4小时降到3小时”。指标阈值必须明确:达到3小时为绿,4小时为黄,超过4小时为红。
【在下次复盘中强制展示改进项仪表盘】我在JIRA中创建了Sprint复盘改进项跟踪看板,每个改进项都有一条数据曲线。展示时先看“绿/黄/红”状态,如果红色,直接进入深度归因,否则默认通过。具体数据:实施后,我们团队改进项关闭率从23%提升到78%。
最典型的例子:关于“测试环境部署时间过长”的改进项,我们设定目标从15分钟降到5分钟,连续三个Sprint跟踪数据。第一个Sprint降到12分钟(黄),第二个Sprint通过优化Docker镜像降到8分钟(黄),第三个Sprint通过并行部署降到4分钟(绿)。
每次复盘都基于数据讨论下一步方案,而不是重复制定Action。额外技巧:将改进项状态(红/黄/绿)放在Sprint回顾看板的显眼位置,每天站会后看一眼。数据追踪的本质是让改进变得可测量、可见,而不是依赖记忆。
文章包含AI辅助创作:Sprint复盘流于形式?数据说话,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3977194
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为CTO,这篇文章简直戳中痛点。我们团队每周复盘会开了两年,每次都是‘加强沟通’‘写单元测试’,但线上Bug该出还是出。看了文中19%的闭环率数据,我立刻让运维拉了半年Jira数据,发现至少60%的改进项从未关联任何代码提交。现在准备引入PingCode的效能诊断,先建立事实基线再说。文章里‘冷冻保鲜’的比喻太贴切了,复盘如果只是仪式,还不如不开。
作为一个被逼着写‘停止需求变更’写了8个Sprint的开发,读到这篇文章真是哭笑不得。每次复盘都像演戏,PO该插队还是插队,我们提了也没用。文中那个‘需求插入率反而上升12%’的数据,简直是我们团队的写照。最扎心的是那句‘集体创作科幻小说’,没错,我们就是在编‘我们明年会更好’的剧本。希望领导们能看看这篇,别再用形式主义麻痹自己了。
作为Scrum Master,这篇文章让我反思了很久。过去我一直在追求‘氛围和谐’,不敢让大家吵起来,结果复盘变成了茶话会。文中‘三刀流’方法给了我明确方向:会前自动生成效能报告、聚焦数据异常点做5 Why、输出原子化任务。特别是ROI的提法,让我意识到复盘本身也要衡量效果。我已经开始调整下周的复盘流程,先屏蔽主观感受,只对准数据开刀。