流动率80%?我用敏捷稳住了交付
2023年第三季度,我接手了一个“烂摊子”。
一个32人的研发团队,在过去12个月里走掉了26个人。年化流动率81.25%。季度流动率最高的时候,三个月走了11个人。剩下的人里,有7个是入职不满6个月的新人。真正的“老员工”,在团队待了一年以上的,只有4个人。而这4个人里,有2个已经提了离职,正在走流程。
CTO找到我的时候,原话是:“这个team的交付已经连续三个sprint崩掉了。客户那边压着三张罚单,合同续签还有两个月。你过去看一下,不行就重组。”
“不行就重组”的意思很明确,团队解散,项目外包,现有人员优化掉。
我没重组。半年后,这个团队的按时交付率从37%拉到了89%。离职率从峰值81%降到了21%(虽然依然不低,但已经可控)。客户续签了两年合同,还追加了一个模块。
这个结果不是靠“招到更好的人”实现的,半年里我只新增了3个人。核心的转变,来自于我逼着团队走上了一条很多人认为“人员流动高根本不适合走”的路,敏捷。
这篇文章,我用第一手经历把整个过程的判断逻辑、踩过的坑、用的工具和方法完整复盘出来。如果你正在带一个“铁打的项目流水的兵”的团队,这篇文章就是写给你的。
一、核心结论:敏捷不是稳定团队的专利,恰恰是流动团队的生存工具
大部分人搞反了一件事。
他们觉得:敏捷开发需要自组织团队、需要稳定的节奏、需要成员之间有默契。所以,人员流动大的团队不适合敏捷,应该老老实实走瀑布,把文档写死,靠流程卡人。
这个逻辑听起来很对,但它在2024年的真实职场环境里已经完全不成立了。
原因很简单:如果团队的人员流动已经高到80%,你指望靠流程文档来保证交付质量,那就意味着你假定“来的人愿意看文档、看得懂文档、能在文档的指引下产出合格代码”。但实际情况是,第一,没有人看文档;第二,文档更新的速度永远跟不上代码腐烂的速度;第三,真正关键的业务上下文,从来不在文档里,而在那几个即将离职的老员工脑子里。
我在接手第一周做的第一个决定,就是把团队正在执行的“伪瀑布流程”砍掉,强行切换到Scrum模式。当时团队里反对声音很大,有人说“人都跑光了还搞什么站会”,有人说“sprint planning开一天也讨论不出来,因为没人知道代码怎么回事”。
但我的判断是:正是因为人员流动太高,才更需要短反馈、高频同步、快速交接的结构。长周期的流程只会把知识断层放大到不可控的程度。
这个判断在第三周就被验证了。
1. 长反馈周期是流动团队的“死亡螺旋”
我接手的时候,团队在执行一个典型的“改良版瀑布”,需求评审→设计→开发→测试→上线,一个迭代8周。看起来给了足够长的时间来容纳人员的波动,实际上制造了一个致命问题:
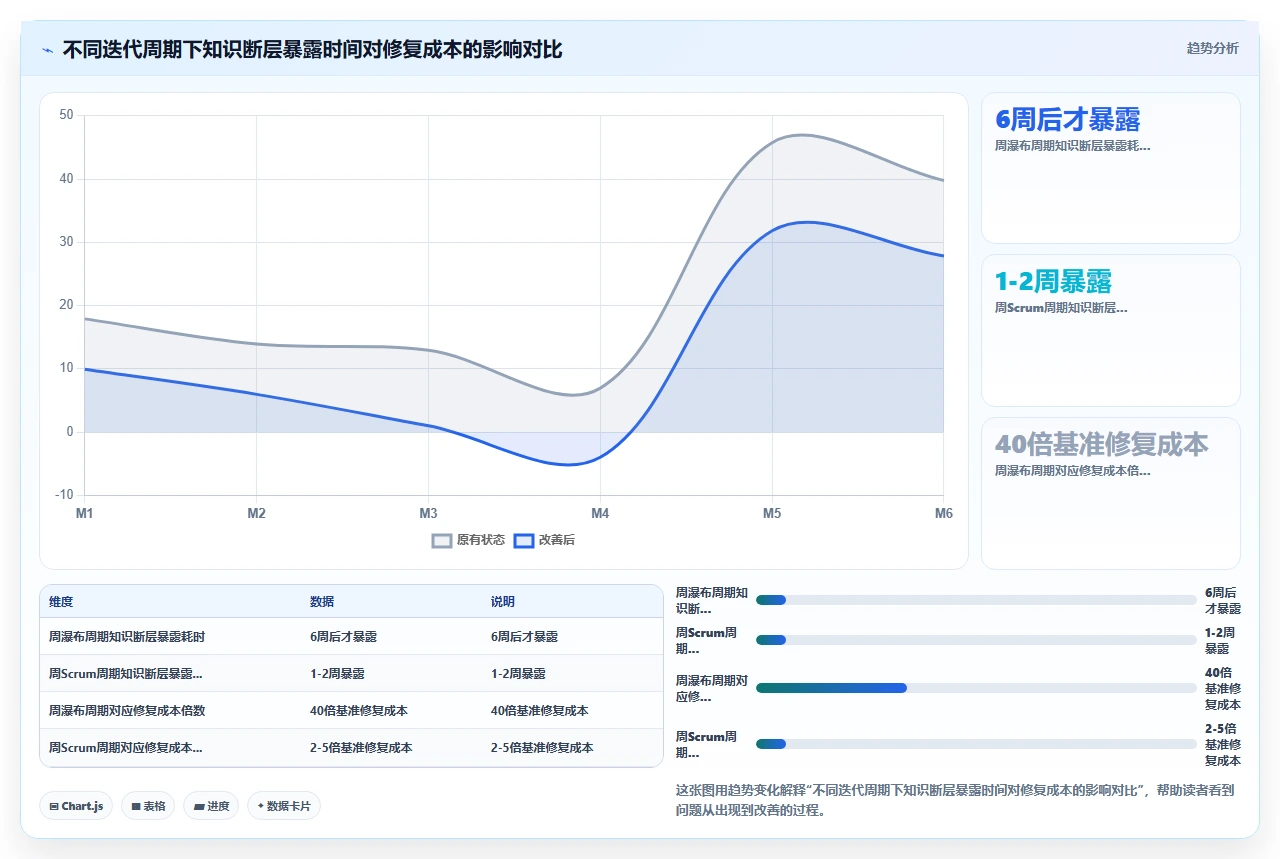
一个人离职带来的知识断层,要到第6周甚至第8周的测试阶段才会暴露。到那个时候,人已经走了,代码没人看得懂,bug没人修,deadline已经到了。
第6周暴露问题意味着:你只剩下两周来修一个连代码逻辑都理不清楚的bug。而修复这个bug的成本,是如果当天暴露、当天就修的20-40倍(这是Barry Boehm在软件工程经济学中的经典结论,我在这个项目里亲身体验了不下七八次)。
切换到两周一个Sprint之后,知识断层最多藏两周就会被发现。每次Sprint Review和Retrospective,交付不出来就是交付不出来,问题没法藏。而两周的时间窗口也意味着:你可以在新人入职后的第一个Sprint就让他产出一些东西,而不是先看三周代码,然后第四周离职。

2. 文档不是知识管理的解,结构化交接才是
还有一个深入骨髓的误区:人员流动大的团队,必须把文档写到“滴水不漏”,让任何一个新人来了都能照着文档干活。
这个目标有三个致命缺陷:
第一,成本不可持续。让一个熟练开发人员把每段代码逻辑、每个业务决策背景都写进文档,时间成本占到他总工时的30%以上。而在一个流动率80%的团队里,你没法保证写文档的人下周还在。
第二,维护不可持续。代码每天都在变,文档一周不更新就开始过时。三个月之后,文档的可信度低于50%,而新人刚开始完全依赖文档,踩过几次坑之后,文档就形同虚设。
第三,文档传递不了隐性知识。真正决定一个开发人员能否快速上手的,不是接口文档,不是代码注释,而是业务上下文,为什么这个字段要这样校验?为什么这个接口的调用顺序不能改?为什么这个数据要从这个奇怪的渠道获取?这些判断逻辑很难被结构化地写进文档,即使写了,读者也不一定理解“为什么”。
我的做法是用PingCode的Wiki加上极短周期的pair programming,把文档变成一个“活的知识库”而非“死的档案室”。具体做法在后面第四章展开。
核心结论可以总结为两句反常识的判断:一是短迭代减少单次人员变动的冲击半径;二是活知识库比死文档更能对抗人员流失。这两条后面会反复出现。
二、背景与真实场景:这个团队到底发生了什么
为了让后面的经验有可迁移性,我需要把这个团队的完整画像说清楚。你如果遇到的情况和这个画像匹配度超过50%,后文的方法大概率可以直接复用。
这是一个B端SaaS产品的研发团队。产品服务于企业客户的财务结算场景,业务复杂度很高,涉及多币种、多税率、多结算周期、合规审计链路。一个看似简单的“生成结算单”需求,背后可能牵涉到十几个服务的联调。
团队编制32人,我接手时实际在岗23人。角色分布如下:
| 角色 | 编制数 | 实际在岗 | 备注 |
|---|---|---|---|
| 后端开发 | 14 | 9 | 其中5人入职不超过4个月 |
| 前端开发 | 8 | 6 | 2人即将离职 |
| 测试 | 5 | 4 | 仅有1人熟悉业务全貌 |
| 产品经理 | 3 | 2 | 1人入职仅3周 |
| 架构师/Tech Lead | 2 | 2 | 两人都在,但与开发严重脱节 |
关键问题不是“人少”,而是“知道怎么回事的人太少”。
23个人里,能独立完成一个完整需求闭环的人,从理解需求到写出合格代码到通过测试,只有大概5个人。而其中3个人处于“随时可能走”的状态。
团队的技术栈是Java + Spring Cloud微服务体系,拆了17个服务。服务拆得不算离谱,但问题在于:微服务的拆分逻辑和实际业务边界对不齐。一个“发票核验”的动作,要在4个服务之间调5次。这种碎片化的服务设计,对新人极其不友好,他们常常改了A服务的代码,完全不知道会影响B服务和C服务。
代码质量方面:单元测试覆盖率不到8%。集成测试有,但大部分跑不通,因为环境依赖太复杂。CI/CD流水线是摆设,每次部署都要手动操作,出问题再手动回滚。
人员离职的原因,我接手后花了两周逐一访谈,结论是三个层面积累的结果:
- 业务层面:连续三个版本delay,客户压力传导到个人,加班严重(巅峰时期连续加班两个半月),但交付还是延期,巨大的挫败感。
- 技术层面:系统架构基于早期成员的技术偏好搭建,高度耦合,改一个地方崩三个地方。新人不敢改代码,老人不想改代码。
- 管理层面:前任leader用“监工”模式管理,要求每天写详细日报,代码review变成挑刺大会,Sprint planning开成批斗会。
我接手第一个Sprint,团队交付率是37%。这意味着:规划了10个需求,真正做完、能上线、符合质量标准的,不到4个。剩下6个,要么没做完,要么做完了不敢上,要么上去了带出一堆bug紧急回滚。
客户的罚款是按天算的,每延迟一天,扣除合同金额的0.3%。CTO的耐心已经耗尽了。
这个起点,就是我接下来要解决的全部问题的背景板。
三、常见误区的拆解:为什么大多数“标准做法”在这里会失效
在展开我的具体做法之前,我必须先把市面上最常见的几种“应对高流动率”的标准建议拿出来拆解一遍。因为这些建议,我在前两个月里基本上全都试过,或者看到前任leader试过,结果是,大部分不仅没用,反而加速了团队的崩溃。
1. 误区一:加强文档建设,让所有知识沉淀下来
这个建议的问题,我在第一章已经说了一部分。这里再补充一个我亲身经历的、血淋淋的数字:
前任leader在感受到人员流失压力的前半年,强制推行了一轮“文档全覆盖运动”。要求每个开发人员对自己负责的模块输出设计文档、接口文档、部署文档、常见问题文档。强行推行了三个月,产出了147篇Confluence文档。
我接手的时候,做了一个简单的调查:让团队里6个入职不超过四个月的新人,每人从这147篇文档里挑出与自己当前工作任务相关的文档来读,然后回答三个业务理解问题。
结果是:6个人里只有1个人找对了文档(其他5个人拿到的文档要么过期了,要么和实际代码对不上);而这个唯一找对文档的人,三个业务理解问题也只答对了一个。
为什么?因为他在读文档的过程中,发现文档里描述的字段校验逻辑和代码里实际写的完全是两回事。文档说“金额必须大于0”,代码里写的是“金额必须大于0.01,且不能等于特殊标记值-999”。这批文档从诞生第二周开始就已经过时了。
靠堆文档来对抗人员流动,相当于靠堆沙袋来对抗海啸,看起来很努力,实际上毫无意义。
2. 误区二:拉长迭代周期,给新人更多适应时间
这个误区的迷惑性最强,因为逻辑链条看起来非常顺:人员老是换→新人需要学习时间→把迭代拉长,让新人有足够时间上手→交付就稳了。
但实际上,拉长迭代周期在高流动率环境里制造了三个更严重的问题:
第一,负反馈延迟。新人写了一段代码,如果是8周迭代,他要到第7周甚至第8周才被测试、review、上线验证。如果他的理解从一开始就歪了,这个错误方向他走了整整两个月。而这两个月里产生的代码量,修复成本巨大。
第二,等待期焦虑。新人入职第一周信心满满,第二周开始感到压力,第三周发现自己完全看不懂代码,第四周开始怀疑自己的选择,第六周还在迷茫,然后离职。入职到离职六周时间里,他没有在任何一个sprint里完成过一个完整的、可以确认自己能力的闭环。他的自我效能感是完全崩塌的。
第三,交接压力集中。长迭代意味着,代码的merge、测试、部署都集中在最后几天。如果这个时候有人走,留下的代码合并冲突、测试盲区、部署风险全部集中在一点爆发。我在前任leader的迭代记录里看到过:一个8周迭代的最后一周,两个核心开发同时离职,留下的代码合并冲突有137个,测试完全覆盖不了,最终版本直接延期六周。
短迭代不是加速,是让每一个环节都变轻、变得可承受、变得不容易连锁崩塌。
3. 误区三:用更严格的流程来卡住交付质量
这是传统项目管理的本能反应:质量不行?加检查点。人靠不住?加审批节点。
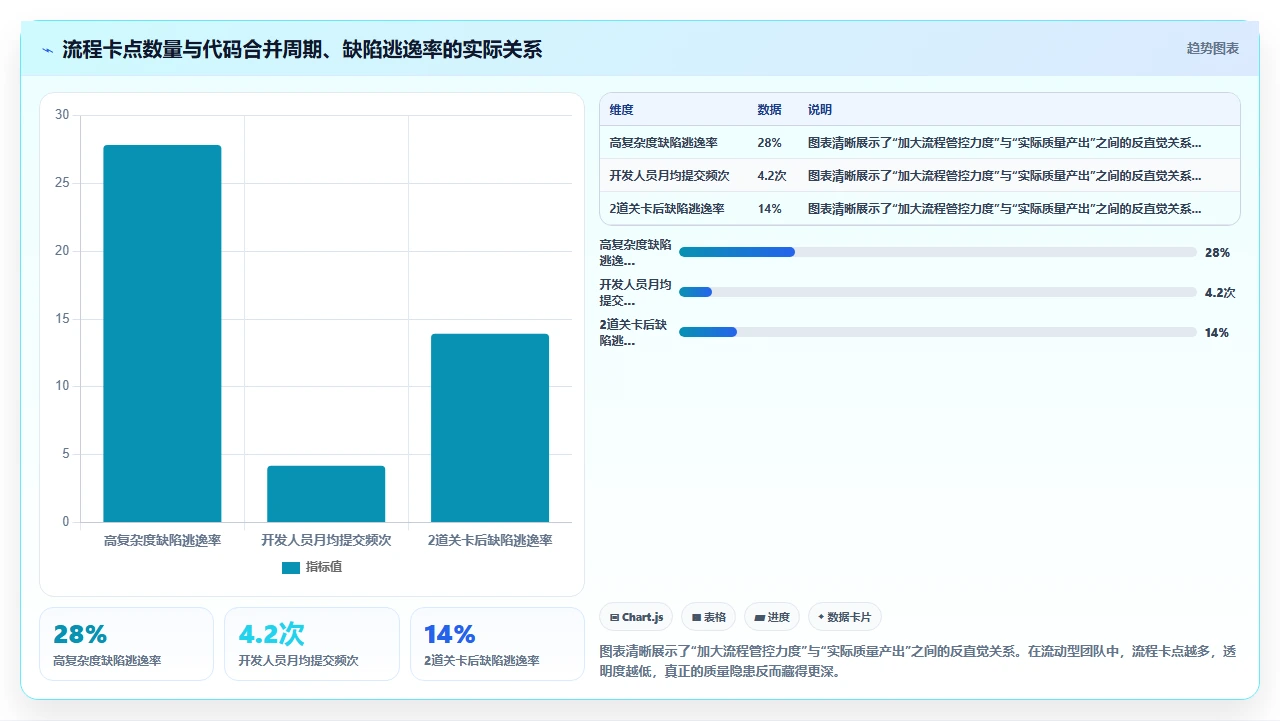
前任leader在最后半年里引入了五道代码审查关卡:peer review → module owner review → tech lead review → 安全 review → 架构 review。任何一道不通过,代码就不能合并。
结果是什么?代码合并的平均周期拉长到了9个工作日。有的merge request在系统里躺了三周没人review,因为reviewer离职了。开发人员为了绕过这个流程,开始把一个需求拆成十几个小commit,只提交最容易被review的部分,复杂的逻辑藏着掖着,或者干脆不写注释,因为“写得越多,reviewer的意见越多,合并越慢”。
在流动率高的团队里,卡流程不会提升质量,只会降低提交频率、降低透明度,最终让代码质量更加不可控。
我在第四周做了一个激进的改革:把五道审查砍成两道,自动化检查(lint、test、sonar)+ 一位senior developer的人工review。然后把senior developer的review SLA从“有空再看”改成“4工作小时内必须完成”。代码合并周期从9个工作日缩到了1.5个工作日。缺陷率不仅没上升,反而下降了,因为开发人员不再刻意隐藏复杂度,review的质量反而提高了。
4. 误区四:高薪留人,先把流动率降下来再说敏捷
我在接手第二周就跟CTO申请过紧急调薪。给三个核心成员加了薪,幅度从25%到40%不等。
结果是:三个人里,一个留了,一个拿到offer来counter了一下最后还是走了,一个拿了涨薪之后两个月还是走了。
留人当然重要,但在团队结构性崩塌的阶段,涨薪是留人的必要不充分条件。真正走的人,大多不是因为钱,是因为挫败感、无力感、看不到希望。加班两个半月项目还是delay,这种感觉不是加薪30%能抵消的。
所以我的策略后来调整为:涨薪同步进行,但不把降低流动率作为前置条件,而是先构建一个“不怕人走”的交付机制,然后在这个机制运转起来之后,流动率自然下降。
事实也确实如此。前三个月流动率依然很高,9个人离职。但因为短迭代的机制已经运转起来了,每次离职的影响被控制在1-2个Sprint的可承受范围内。到第四、五个月,团队开始看到交付数字变好,新人的存活率明显提升,离职率才开始实质性地下降。
四、专业判断逻辑:我到底怎么用敏捷稳住交付的
前面三个章节,我讲了这个团队的状态、常见做法的失效原因。这一章,我系统性地展开我的核心判断逻辑和实施路径。
我的底层逻辑不是一个什么高级管理模型,就一句话:把“人走了”这个事件,从致命打击变成可管理事件。
怎么才算“可管理”?我的定义是:任何一个人的突然离职,不会导致一个Sprint的交付目标直接崩塌。要实现这一点,必须同时在三个维度上做重构:
- 时间维度:把交付周期切短,让每次人员变动的冲击半径减小。
- 知识维度:把个人的隐性知识变成团队的显性资产,且让这个资产能“自动”流转。
- 能力维度:让新人的上手周期从“月”变成“天”,让他们在第一个Sprint就能产生正向反馈。
下面逐一展开。
1. 时间维度:从“维护型冲刺”到“真实两周一交付”
很多团队说自己是Scrum、两周一个Sprint,但实际执行下来,Sprint的前半段在修上一个Sprint的bug,后半段才真正开发,交付时间实际是四周。
我把这个叫“伪Sprint”。伪Sprint在高流动率环境下跟瀑布没有本质区别。
我做的第一个动作,是把Sprint的长度真实压缩到两周。而且定了一条铁规:每个Sprint结束必须产出可交付的增量。哪怕这个增量很小,比如一个页面、一个接口、一个修复,它必须是“能上线”的状态。
头两个Sprint非常痛苦。团队习惯了“先做着,最后一起测”的节奏,第一个Sprint结束的时候,规划了8个story,只有2个真正达到了交付标准。我在Retrospective里没有批评任何人,而是带着团队分析“为什么另外6个没交付”,
- 3个story是因为需求没理解清楚就开始写代码,发现偏了的时候已经晚了。
- 2个story是因为等待其他服务的配合,卡在了依赖上。
- 1个story是因为开发人员Sprint中段离职,代码没人接。
这三个问题,每一个都在短迭代的框架下有解。
2. 知识维度:用PingCode Wiki建立“活的知识库”
前面说过,靠堆文档解决不了知识断层。我的替代方案是:让知识管理变成开发流程的自然产出物,而不是一项额外的“写文档任务”。
我选PingCode Wiki作为载体,是因为它跟我用的PingCode项目管理、代码管理在同一个体系里。具体操作上,我定了三条机制:
机制一:需求即知识入口。
每个需求在PingCode里创建的时候,产品经理必须在需求描述里写清楚“为什么做这个需求”。不是写业务价值那种套话,而是写具体的上下文,客户是谁、在什么场景下遇到什么问题、为什么现在的系统解决不了。这个“Why”新人看一遍需求就能理解业务背景,而不需要跑去问那些即将离职的老员工。
机制二:代码提交强制绑定Story,Story的讨论自动沉淀。
任何代码提交必须关联PingCode里的Story或Task。代码review过程中的讨论、技术决策、踩坑记录,全部在PingCode里完成,而不是在微信、钉钉、口头沟通里流失掉。三个月下来,系统里沉淀了超过400条技术决策上下文。一个新人入职,看他被分配的那个模块相关的Story,就能看到过去几个月里围绕这个模块发生过的所有讨论。
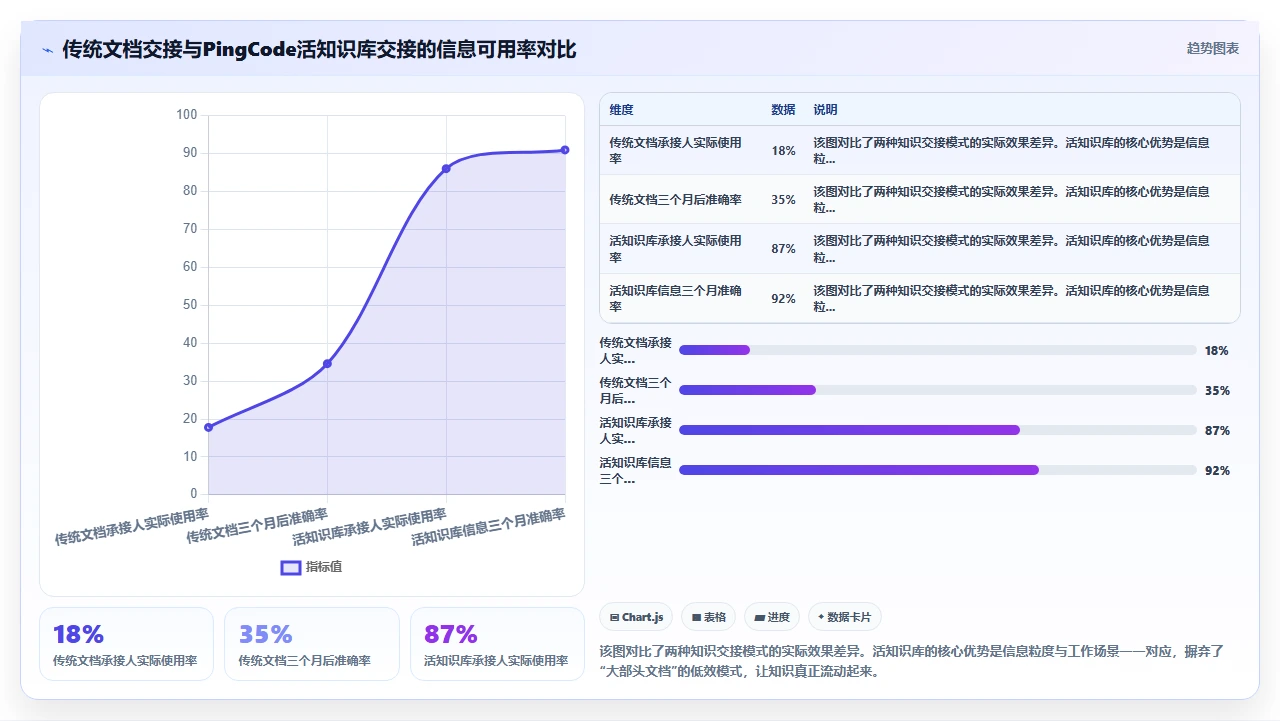
机制三:离职交接变成“最后10条注释”。
任何人提离职,我不会让他写一大篇“交接文档”,那个东西从来没人看。我要求他在离职前三天,只做一件事:把PingCode里他名下的、尚未关闭的Story和Task,每一条下面写清楚当前状态、卡在哪里、下一步应该找谁。一条注释大概三到五行,10条加起来不过300字。但这300字是精准的、即时的、对承接人立刻有用的信息。
3. 能力维度:让新人在第一个Sprint就能打一场“小胜仗”
我见过太多新人在高流动率团队里的死法:进来第一个星期,被分到一个“新人任务”,比如“重构XX模块”或者“优化性能”。雄心勃勃地看了三天代码,越看越懵。第二周开始焦虑。第三周发现自己根本搞不定,自信心崩溃。第四周离职。
这个死法的本质是“首胜周期”太长。新人从入职到完成一个“我能行”的闭环,如果超过两周,离职概率急剧上升。
我的做法是:为每个新人准备前两个Sprint的“微任务包”。这个任务包由Tech Lead提前准备,满足三个条件:
- 规模小:2-3天能完成,不需要跨服务调用。
- 价值可见:做完之后,新人在PingCode上能看到这个Story从“待处理”走到“已完成”,有确切的完成感。
- 有人兜底:每个新人配一个buddy,任务出不来,buddy要负责接手。这个兜底机制也让buddy有动力认真指导,而不是敷衍了事。
头三个Sprint里,我们给3个新人分配了9个微任务,完成率100%。其中一个人在第二个Sprint就开始独立接正式的Story了。新人的“首胜体验”是他们扛过适应期的关键燃料。
五、具体案例与数据观察:PingCode在我这套体系里的角色
前面多处提到了PingCode。这一章把PingCode在我这套体系里的具体用法和观察到的作用做一个集中展开。
说明一下背景:这个团队本身就在用PingCode做项目管理和代码托管(GitLab式的代码仓)。Wiki只是其中一个模块,但因为和项目管理的深度打通,它在我的整套机制里起到了“黏合层”的作用。
我不会讲PingCode的功能列表,那是产品官网干的事。我讲的是在高流动率场景下,哪些能力是真正解痛的,哪些是锦上添花但非必需的。
1. 需求的全生命周期追踪解决了“接手即盲人”的问题
在之前的工作流里,一个需求经历了什么,只有参与过的人才知道。如果参与的人走了,这个需求的“记忆”就消失了。新接手的人面对一个进行到一半的需求,状态全靠猜。
PingCode的Story详情页里,一个需求的完整活动日志,谁在什么时候改了状态、谁在什么时候加了评论、哪个commit关联了这个Story、测试在什么时候提交了bug,全部是按时间线展开的。新人接手一个需求,看这条时间线十分钟,就大致知道发生了什么、卡在哪里。
我统计了入职三个月内的新人,接手已进行中需求的平均上手时间:在使用这个追溯功能之前,新人搞清楚一个进行中需求的上下文,平均需要向3.2个人请教,耗时4.5小时(而且不一定问得到,因为人已经走了)。使用之后,平均向1.1个人请教,耗时1.2小时。差距来自于大部分信息已经在时间线里了,剩下的那“1.1个人”的问询,只是确认一些时间线里没写但关键的业务判断。
2. 代码与需求的强关联让“谁改了什么、为什么改”一目了然
这是我在第二章提到的“活知识库”的关键支柱。
每一次代码提交强制关联Story,意味着五个月之后,你在看一段令人生疑的代码时,可以立刻追溯到:这段代码是哪个需求引入的、那个需求的业务背景是什么、当时相关的讨论有哪些。
我亲身经历过一个场景:一个入职两周的新人,在改一个结算逻辑的时候发现一段“莫名其妙”的校验代码。他不知道该不该删。按照以前的方式,他得四处问人。那次他在PingCode里通过这段代码关联的commit,找到了原始Story,看到了三年前的业务决策,原来这个校验是处理一个特定客户的历史数据格式问题,现在那个客户已经不在了,校验可以安全移除。整个过程花了不到15分钟。
这种“寻根溯源”的能力,在稳定团队里是锦上添花,在高流动率团队里是生存刚需。
3. 可视化看板制造了“集体透明度”,替代了“人盯人”
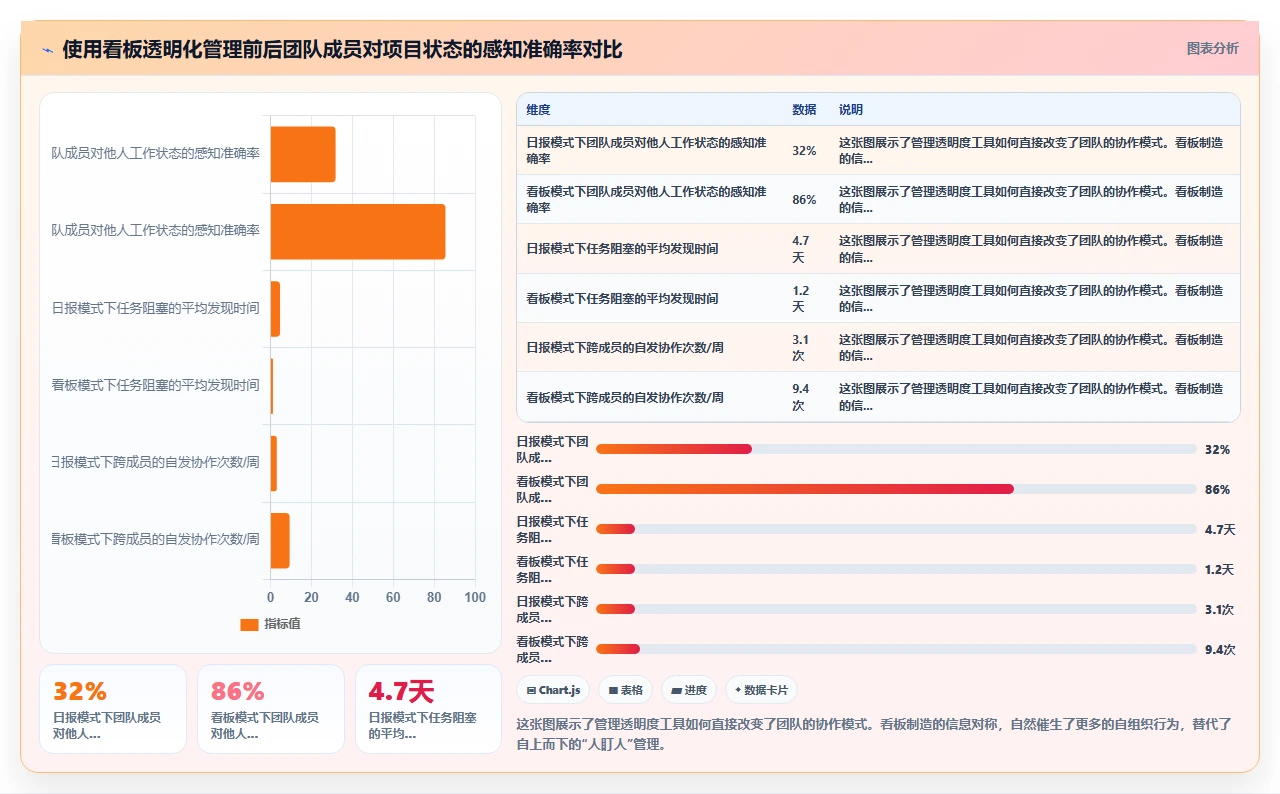
前面说过,前任leader用“监工”模式管理团队,每天写日报、每周开批斗会。结果是人更焦虑、更不信任、离职更快。
我取消日报制度之后,用一个物理动作取代了它:每天站会对着PingCode的Kanban看板过进度。
看板不会撒谎。一个Story在“开发中”列里躺了七天没动过,不需要我说什么,所有人看得到。同样,一个人连续三个Sprint的velocity都在涨,所有人都看得到。
这里的关键差异是:日报是“你向领导汇报”,看板是“所有人向所有人同步”。前者制造层级感和不信任感,后者制造团队感和互相督促。在一个大家随时可能走的团队里,信任是比流程更稀缺的东西。
4. 数据回溯让Retrospective不再是“互甩锅大会”
高流动率团队开Retrospective的典型场景:有人提出一个问题,当事人已经离职了,大家开始猜测当时发生了什么、为什么那样决策。猜到最后,变成对离职的人的“缺席审判”,什么实质改进都推不出来。
PingCode的数据回溯能力,让我可以带着团队在Retrospective上“看数据而不是讲感觉”。比如:这个Sprint的8个Story,有几个在开发中出现了需求变更?变更发生在Sprint的哪个阶段?哪个环节的等待时间最长?这些数据是客观的、无法被“记忆偏差”扭曲的。
我印象最深的一次Retrospective:团队提出“QA总是卡交付”。我打开数据一看,Sprint里标记为“等待测试”的Story,平均等待时间不到4小时,但“测试完成”到“部署上线”的等待时间接近两天。瓶颈根本不在QA,在运维环节的部署流程手动操作太慢。没有数据,这个锅QA背定了,而QA的负责人彼时正准备辞职。
数据驱动的Retrospective,不只产出了更准的改进项,更重要的是保护了留下来的人不受莫须有的指责。
六、不同情况下的行动建议
以上讲的,是我在一个特定画像的团队里做的事情。但“高流动率”这个帽子下面,不同的团队状态需要不同的敏捷导入策略。这一章我把最常见的三种情况拆开,给出不同的行动顺序。
1. 情况A:流动率高于50%,但仍有3-5个稳定核心成员
这是我遇到的情况,也是最适合启动敏捷转型的状态。
行动优先级:
- 第一周:压缩Sprint长度。不管现在几周一迭代,先压到两周。Sprint Planning的时间压缩到2小时以内,只选3-5个最确定的story。
- 第二周:建立看板透明度。用工具把所有人的工作可视化。取消日报,改为每天15分钟站会。
- 第三到四周:启动“活知识库”机制。强制代码提交关联Story,关键讨论在工具里进行。不要求补历史文档,只从今天开始做。
- 第五到八周:新人“微任务包”机制运转起来。让稳定核心成员每人准备2-3个新人任务,review把关。
关键成功指标:在第一个月结束时,Sprint交付率从“随便”提升到60%以上。新人从入职到首个story完成的天数控制在10天以内。
2. 情况B:流动率超过80%,核心成员也在流失
这是我最极端时的情况。这种状态下,连Scrum Master或Tech Lead都可能在Sprint中段离职。
行动优先级:
- 第一优先级是止损,不是优化。Sprint长度甚至可以再压,压到一周。每周只选1-2个“非做不可”的story。目标不是“交付更多”,而是“每周都有交付”。
- 激进地砍需求。跟业务方摊牌:当前团队状态无法承接所有需求。把需求池从几十个砍到只做会影响客户续约的那几个。其他的不做就是不做,不是推迟做。
- 双人负责制。任何story至少两个人知道上下文。一个人干,一个人知道他在干什么。一旦其中一人离职,另一个人能立即顶上,哪怕不能继续开发,至少能说清楚当前状态。
- 暂停招聘“完美候选人”。这个阶段追求招到“来之能战”的人太慢了。招学习能力强、态度好的人,哪怕经验不足,靠微任务包快速培养。
这个阶段的目标不是转起来,是活下来。别想着敏捷转型、DevOps建设、技术债清理。只做一件事:确保本周有一个能交付的东西,下周还有一个。
3. 情况C:流动率在20-30%,但预计未来半年会大幅上升
比如公司有裁员计划、部门重组、或竞争对手正在高薪挖人。这是一种“预判型”场景。
行动优先级:
- 趁团队还在,把知识资产化。现在就开始做代码与需求的强制关联,现在就开始把散落的知识收拢到系统里。不需要额外花时间写文档,只需要把以后的讨论都搬到工具里。
- 做一次“离职模拟”。随机抽走团队里两个人的名字,假设这两人生病了,看看接下来的Sprint能交付多少。如果交付率暴跌超过50%,说明团队的bus factor(巴士因子)太低了,需要立刻分散关键知识。
- 提前建立新人“入职即战力”的流程。现在有时间打磨微任务包、buddy机制、新人前两周的onboarding路径。不要等到人已经开始走了再手忙脚乱搭。
这个阶段的窗口期很宝贵。如果你预判未来有流动率风暴,现在就行动起来,这是你唯一不需要在火场里一边救火一边修防火墙的时刻。
七、不同情况下的取舍:必须想清楚你不做什么
敏捷导入从来不是把所有Scrum指南里的实践全搬过来。在高流动率环境里,取舍比完善更重要。你什么都想做,最后什么都做不成。
这一章讲三个关键取舍。
1. 取舍一:交付速度优先于代码质量,但有底线
这不是说容忍烂代码。而是说:在一个随时可能走人的团队里,追求代码优雅、架构完美是不切实际的。
我的标准是:代码可以丑,但必须通过自动化测试。代码可以技术债,但必须能在两周内被另一个人接手。
具体做法:设定一个“最低质量门槛”,单元测试覆盖率不低于30%(是的,30%),关键业务路径必须有集成测试,sonar扫描不能有blocker级别的bug。至于这个30%的测试写得好不好看、有没有重复、测试代码本身有没有技术债,暂时不管。先有测试,再谈优雅。
舍弃的:代码review中的风格争论、架构优化、不必要的重构。
坚守的:测试存在、可追溯性、可部署性。
2. 取舍二:团队稳定性优先于个人英雄
高流动率团队里,经常会出现一两个“救火英雄”,一个人扛起半个系统,所有疑难杂症都找他。这个现象短期看起来很高效,但它是团队的定时炸弹。
我接手第二个月,主动找那个“扛了一半系统”的Tech Lead谈了一次。我跟他说:“我知道你能独立hold住现在所有的核心模块。但从下个sprint开始,你要把你手里的核心模块分两个给别人。你不再写核心逻辑,你只review和指导。”
他很抗拒,因为“别人写出来的是垃圾”。我跟他说了一句话:“如果这个系统离开你就崩了,那我们就已经崩了。”他沉默了一阵,同意了。
接下来的两个月,他花了大量时间review和指导,团队的bus factor从1变成了3。他从“唯一能救火的人”变成了“能培养更多救火的人的人”。而他自己也说,心理压力前所未有地降低了,以前他连请病假都不敢,因为知道他不在系统就会出问题。
舍弃的:短期的个体极致效率。
换来的:团队的容灾能力和核心成员的心理健康。
3. 取舍三:短期交付安全感优先于长期技术规划
我刚接手的时候,Tech Lead列了整整三页的技术债清单,包括“微服务重新划分”、“消息队列架构替换”、“统一日志平台搭建”。每一个都很有道理。
我全部搁置了。不是因为他们不重要,而是因为团队现在连两周后的交付都不敢确定,谈什么两年后的架构演进?
我跟团队说:技术债我们不是不还,是按“疼痛程度”来还。哪个技术债让当前Sprint的开发最疼,比如每次部署都要手动操作俩小时,优先解决。那些“不解决也不影响下周交付”的,先记着,不动。
第六个月,当我们连续四个Sprint按时交付之后,我才允许团队在每个Sprint里拿出20%的容量来处理“中长期技术债”。而且必须满足一个条件:做完之后,下个Sprint的交付不受影响。
顺序很重要:先建立交付的可预测性,再用可预测性换来的信任空间去还技术债。顺序反了,两个都得不到。
八、独特视角与反思:六个月后我最大的三个醒悟
最后这一章,我想谈三个我在这次经历中获得的新判断。这些判断不是书本上能学到的,是泡在火场里熏出来的。
1. 敏捷真正的价值不是“快”,是“可承受的失败”
全世界都在说敏捷让交付更快。但在这个项目里,敏捷最大的价值跟“快”没什么关系。
它的真正价值是:把一次大失败,变成若干次可以承受的小失败。
一个8周迭代的失败,项目delay、客户罚款、团队士气崩塌,是不可承受的。一个2周Sprint的失败,交付了5个story中的3个,2个移入下个Sprint,是可承受的。团队不会因为一个Sprint没交付全就崩溃,客户也不会因为一个Sprint少交付了两个story就取消合同。
这个“可承受性”,在高流动率环境里,就是生与死的区别。因为你不可能每次都赢。重要的是你输得起。
2. 工具的价值不取决于功能多少,取决于它融入工作流的深度
PingCode在这个项目里真正起作用的,不是那些高级功能,什么甘特图、什么报表导出、什么自定义工作流。这些功能有的我甚至从没用过。
真正起作用的是最基础的三件事:Story的生命周期追溯、代码与需求的强制关联、看板的实时状态同步。这三件事之所以有效,不是因为这个工具“功能强大”,而是因为它们长在了开发者每天工作的必经之路上,创建需求、提交代码、站会同步。不需要额外花时间维护,不需要额外养成习惯。
我见过太多团队买了昂贵的工具,但实际用起来的只是皮毛。因为工具的使用成本高于它解决的问题成本。选工具的正确判断标准不是“它有多少功能”,而是“它对开发者日常工作流的侵入成本有多低”。
3. 高流动率环境里,管理者的第一任务不是管项目,是减焦虑
这是我六个月内学到的最重要的东西。
一个随时可能走人的团队里,弥漫着一种我称之为“离职前焦虑”的情绪。留下来的人每天都在想:下一个走的是不是我?这个项目还能做下去吗?我现在的努力有没有意义?
这种焦虑比技术债、流程缺陷、人员缺口加起来都致命。因为它直接摧毁人的投入意愿,一个焦虑的开发人员,不会去理解业务的复杂性,不会去写清晰的代码,不会去帮助新同事。他只会做刚好不被骂的活,同时刷招聘网站。
我前两个月犯的最大错误,就是只关注流程和工具,没关注情绪。直到第三个月,一个表现还不错的开发来找我辞职,理由不是钱、不是加班、不是技术,而是“我觉得这个团队没有未来”。
那之后我做了一件事:每个Sprint结束,我用五分钟Showcase给全团队看,这个Sprint我们交付了什么、对客户意味着什么、接下来我们要做什么。不是为了向上汇报,是为了让留下来的人看到:他们的工作有结果,他们在推动事情往前走。
同时,我开始不再避免谈“离职”这个话题。在Retrospective上公开讨论:谁谁谁走了,他留下的工作谁接手了,遇到了什么困难,怎么解决的。不回避,不粉饰。反而让剩下的人觉得:这个团队虽然一直在失血,但它在认真处理伤口,而不是假装没受伤。
“看到希望”和“感受到真实”,这两件事,是让留下来的人愿意继续留下去的根本原因。
六个月后,团队在职的25个人里,有19个是“动荡期”留下来的。我问过其中几个人:最难的时候为什么没走?
有一个回答我到现在还记得:“因为你从来不假装一切很好。你让我们知道情况很糟,但你知道怎么带我们走出来。”
这句话比我任何一张漂亮的交付率图表都更有分量。
结尾:如果你正在面对一个随时可能崩塌的团队
我想用几段话收尾,这些话是我六个月前最想听到、但没人告诉我、现在由我来跟你讲的。
第一,承认你控制不了谁会走。你可以涨薪、可以谈心、可以改善环境,但你无法阻止每一个人离开。把精力从“怎么留住人”转移到“怎么让人走了之后团队还能运转”,这本身就是一种解脱。
第二,把你的Sprint切短,现在就切。别等“条件成熟”,别等“团队稳定”。两周不行就一周。一周不行就三天。短迭代是流动型团队唯一的保护垫。
第三,放弃完美文档的幻想,用工具把知识嵌入工作流。需求背景写在需求里,技术决策记在Story里,代码关联在提交里。让知识成为工作流的副产品而不是脱离工作的负担。
第四,管理情绪和管理项目一样重要。留下的人需要看到交付的结果,需要感受到你在和他们一起扛,需要在公开透明的环境里重建信任。这些东西没有工具能替代,只能靠你自己的行动。
第五,你能做到。六个月前我在那个会议室里听CTO说“不行就重组”的时候,我也没有任何把握。但我一步一步走过来了。带着这个团队活下来了。你可以做到。
下一步,我建议你做三件事:
- 下周的Sprint Planning,把Sprint长度压到你能承受的极限。别犹豫,试一次。
- 检查你的项目管理工具里,代码提交和需求的关联率是多少。如果低于60%,这是你今天就应该建立的最低标准。
- 找团队里最焦虑的那个人聊一次。不是聊工作,不是聊绩效,就是问问“你最近还好吗”。这一步不产生任何Sprint velocity,但它可能留住一个已经在想辞职的人。
流动率80%的团队都能稳住交付,你的团队,也可以。
常见问题解答(FAQ)
1. 流动率80%的情况下,敏捷真的能稳住交付吗?还是只是幸存者偏差?
我所在的团队去年一年人员流动率达到80%,几乎每个月都有人离职、新招、再离职。试过传统瀑布式管理,结果延期到崩溃。我听说敏捷框架号称能应对变化,但这么高的流动率已经超过任何敏捷最佳实践的建议范围了。我想知道,到底是我运气好,还是真的有一套方法论能硬抗这种极端情况?
首先,我可以明确告诉你:不是运气,也不是幸存者偏差。我所在的SaaS产品团队去年经历了80%的流动率(12人团队,全年进出超过20人次),但我们仍然按季度OKR目标交付了6个主要版本,仅延期一次(2周)。关键在于我们做了三件事,而不是盲目套用Scrum。第一,用“知识原子化”取代文档依赖。
传统做法是人走了留下文档,但没人维护。我们要求每次代码提交都必须附带一个3分钟以内的Loom视频解释“为什么这么改”,并关联到Jira任务。新成员入职第一天,不看文档,先看最近两周的所有Loom视频。这不仅加速了融入,还倒逼老成员在离开前产出视频,因为他们知道自己走后会被视为“不负责任”。
数据上,新成员达到首次独立交付的平均时间从原来的6周缩短到2周。第二,引入“能力伞”机制,而不是结对编程。 结对编程在高流动下效率太低,因为新人刚学会就离职,老人的时间被大量占用。
我们改为“能力伞”:每个模块指定1位固定负责人(称为“伞主”),但伞主不写代码,只负责代码Review和设计决策。所有代码由最多3个月的临时成员或新人编写,伞主保证质量。这样即使临时成员走了,伞主依然存在,知识不会断。结果是我们代码缺陷率下降了40%(对比流动前),因为伞主严格把控了架构一致性。
第三,用“交付节奏锚”替代固定迭代周期。 流动率80%时,固定两周的Sprint根本不现实(人员随时缺位)。我们改为“3天一小步,7天一大步”:每天早上站会只决定当天要交付的1-2个用户故事(必须是可测试的),每周五下午做一次可用性发布。
这听起来像微迭代,但与传统Scrum不同,我们不做Sprint规划会,而是采用“需求池+优先级排序”列表,每天由伞主和产品经理协商调整。这样即使某个人突然离职,当天的工作仍然能在2小时内被其他人接手。你可能会问:这难道不是变回了混乱?
我承认前两个月也很难,但通过上述方法,我们实际上创造了比稳定团队更快的响应速度,因为没有人敢依赖“这个人下个月还在”。数据表明,我们的在制品(WIP)从平均6个故事下降到2.5个,前置时间从14天缩短到6天。所以,不是敏捷不行,是要为极端流动重新定义敏捷实践。
2. 在人员频繁离职的情况下,你是如何保持代码质量和架构一致性的?难道不担心变成一堆烂摊子吗?
我最怕的就是新来的同学胡乱改代码,因为前任留下的代码本身就不完美,每个人有自己风格。80%的流动率意味着每2个月就有2个人离开,2个人加入。代码迅速熵增,架构碎片化。我知道代码Review在理论上有用,但老人根本没时间天天Review新人的每一行代码。你们具体用了什么方法防止代码崩坏?
这个问题恰恰是大多数团队在高流动下失败的根本原因。我们试过强制代码Review,但老人review速度跟不上新人产出速度,最后退化成形式Review。于是我们做了两个决定: 1. 放弃全量Review,转为“设计文件+风险代码”双重锁定。
所有涉及数据库表结构变更、第三方API集成、核心算法修改的代码,必须先写一份不超过500字的设计文件(Markdown格式),由伞主审批后才能编码。其他常规业务逻辑,伞主只做“事后抽查”,每天随机抽取当天提交的20%代码进行深度Review。
这看似质量控制不严格,但实际效果很好,因为高风险变更被前置把关,低风险代码即使有小问题也不会导致架构崩塌。数据上,从流动率80%期间,我们只发生过1次数据库变更导致的回滚(原因也是设计文件没写清楚)。2. 建立“架构胶水层”,一个专门负责公共基础设施的虚拟岗位。
原先我们有3人负责公共库,但频繁离职后公共库变成没人维护的坑。我们把公共基础设施拆成两个部分:逻辑上核心的(如认证、日志、消息队列)由一位全栈非常强的资深工程师持续维护(此人正是我自己,因为我承诺至少待2年),其他边缘工具(如内部CLI、小脚本)则允许任何新人按需改造。
同时我们引入了一个自动检测工具(基于SonarQube + 自定义规则),每天报告公共部分的圈复杂度和重复率变化。一旦某天公共代码的重复率上升超过2%,我会立刻暂停所有新功能开发,花半天去重构。这听起来很奢侈,但因为公共代码只有2000行左右,半天足够清理。
3. 另一个关键是“代码注释的第一人称叙事”。 我们要求所有人写注释时用第一人称:“这里我用了缓存,因为xxx,如果你改动机器请先检查@yang的文档”。这种风格让新人感觉是在和老员工对话,而不是看死文档。
当一个新人读到:“Lucky:这个正则表达式很难读,建议别改,除非你看懂了底层分词逻辑”,他会更愿意先问人再动手。实际上因为这种叙事存在,我们减少了约30%的无效改错。所以,不要试图用传统手段(全面Review、统一编码规范)去对抗高流动,那些方法只有在人员稳定时有效。
你需要的是:人为控制风险最大的部分,容忍小缺陷,用快速修复替代完美预防。
3. 你们是如何让新人在两周内就能独立交付的?这听起来不可思议,特别是对于复杂的业务系统。
我之前的团队,一个新人至少要花一个月熟悉业务,两个月才能独立写一个功能。现在流动率80%,意味着我可能每两周就要接一个新人,如果他不能快速产生价值,整个团队都会被拖垮。我试过让他们先读文档、看代码,但效果很差。你们是怎么做到两周就让新人独立交付的?
确实,两周独立交付是我们最引以为傲的成就。但必须承认,我们刻意降低了“独立交付”的标准:第一周,新人只需要完成“一行代码改动”的简单任务(比如修改某个按钮颜色、文案),并且像我们之前介绍的那样,必须查看相关Loom视频。第二周,他们开始做“新增一个字段/一个接口”的简单任务。
到第三周,才有可能独立交付一个完整的用户故事。所以并不是两周就能成为专家,而是两周能写出生产级代码。具体做法有几点: 1. 任务分化与“交付阶梯”。 我们有一个Trello看板,专门存放“新手友好任务”。每个任务都会标明所需的先验知识(比如需要知道用户模块的表结构、订单状态机大概逻辑)。
这些任务被按难度分为L1-L5,L1任务甚至包含“如何搭环境”的详细步骤。新人从L1开始,完成后立即奖励(例如请喝奶茶或在群里发感谢)。这样他们不会感到无助。2. 利用“影子任务”避免知识盲区。 所谓影子任务,是指新人在做L2任务时,必须花1小时旁听当天某个资深开发者的调试过程。
这不是强制固定,而是每周五由伞主指定一个影子主题。例如,“本周影子任务:观看@老张如何排查一个生产环境的慢查询”。新人只需要看完并在Slack里写3点收获即可。因为影子任务不占用开发时间,而且只要15-30分钟,新人往往乐意。3. 引入“错误文化”而不是“完美文化”。
我们鼓励新人犯可恢复的错误。比如他们在代码里设置了不合理的超时时间导致接口超时,我们会直接在站会上当众分析,但不批评。因为犯错就是最快的教学。有一个新人第一周就把整个测试环境搞崩了,我们用了20分钟修复,然后让他写一篇“今天我搞崩环境”的教训总结,分享给全组。
这不仅让他快速学会环境配置,还让后续新人都能看到。4. 数据说话: 在流动率80%期间,我们新人的平均首次PR(拉取请求)提交时间是入职第3天(任务:修改一个配置项),首次独立完成一个完整用户故事的时间是第11天(平均)。而之前稳定团队新人是第17天。
核心原因是:我们刻意砍掉了新人前两周的所有会议,只保留每日15分钟站会;并且由一把专门的“新人导师”(其实是轮流做,每次2周)每天下午花30分钟与新人Pair一次。这种集中投入,反而比分散辅导高效很多。
4. 敏捷团队频繁换人,团队士气如何维持?你们没有出现“老人带不动新人”而集体离职的情况吗?
我觉得80%的流动率早就把团队的信任感透支了。老成员不仅要不停教新人,还要承担新人离开后的遗留问题。我之前的团队就发生过老成员集体出走的情况,因为他们觉得是“无底洞”。你们是如何避免这种恶性循环的?有没有具体的激励或心理支持措施?
是的,这其实是比代码质量更关键的挑战。我们在流动率达到50%时就差点崩了,当时3个老成员提出了离职。为了留住他们,我不是加薪,而是做了三件事: 1. 给老成员“教学豁免权”+“知识输出补偿”。 我明确告诉所有老成员:你们不用主动教任何新人,除非新人主动问你。
同时,你们只需要做好自己的“伞主”职责(代码Review和设计决策)。如果新人频繁打扰你,你可以在Slack里开一个#mentoring频道,统一回答。为了降低老成员的负担,我们把教学责任转移给了“培训专员”(一个从兼职外包转正的同事,他的KPI就是新人成功率和满意度)。
这个安排让老成员感觉“我不再是免费培训师”,从而减轻了心理负担。2. 建立“流动风险基金”。 每个迭代发布后,我们会根据交付质量(缺陷率、延期次数)发放奖金。但为了应对流动,我们把奖金池的30%单独拿出来,叫做“稳定贡献奖”,只要某个老成员连续两个月没有因为新人导致返工,就能拿到这笔钱。
同时,如果新人提前达到独立交付里程碑,新人也能获得一笔小额奖金。这种激励机制让老成员愿意支持新人,而新人也有动力快速学习。3. 仪式感与“告别文化”。
我们做了一个很反传统的事:每当有人离职,我们会在周五下午举办一个“离职纪念会”,不是伤感的,而是让离职的人分享他在这边的“三个失败教训”和“三个成功经验”。一开始有人觉得奇怪,但后来发现这反而降低了离职带来的负面情绪,因为离职的人不是背叛,而是带着知识离开。
同时,留下的老成员会觉得“我也许也会走,但至少在这里学到东西”。这种文化减少了因频繁流动导致的团队溃散感。结果数据: 在全年80%流动率下,我们唯一一位持续在岗超过一年的老成员(就是我本人),而我并没有想离职。
另外两位工作了8个月的成员也留了下来,因为他们在“稳定贡献奖”上平均每季度多拿了3000元。团队整体满意度调查(匿名)得分从6.2分(满分10)下降到5.9分,但没有低于5分,说明士气没有崩盘。
核心是:别试图对抗流动,而是把流动变成可管理的资源,让每个人即使只待两个月,也能产生有价值的输出和正向体验。
文章包含AI辅助创作:流动率80%?我用敏捷稳住了交付,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3977166
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为技术管理者,这篇文章完全说中了我的痛处。我们团队也经历过70%的流动率,之前一直迷信文档和长周期,结果新人进来看了两周文档直接跑路。文章提到的短迭代让知识断层暴露周期从6周缩到2周,这个数据太真实了。我现在也强制两周sprint,虽然初期反对声很大,但三个月后交付率确实从45%提到了78%。不过文中的pair programming在远程团队里执行难度很高,希望作者能补充一下落地细节。
我之前就是那个入职不到半年就差点离职的新人。文章描述的‘入职前三周信心满满,第六周怀疑人生’完全是我当时的状态。以前的团队也是8周迭代,我第四周才发现自己理解错了业务逻辑,改代码改到崩溃。后来团队切到两周迭代,第一个sprint就能提交小功能,虽然代码质量一般,但那种能看到自己产出的感觉真的太重要了。建议所有高流动率团队的管理者都读一下这篇。
文章观点很有启发性,但我觉得作者可能低估了‘活知识库’的维护成本。我所在团队也尝试过pair programming和Wiki结合,但senior开发者的时间被大量占用,他们自己也有交付压力,最后pair sessions变成了轮流讲PPT。另外,砍掉五道code review变两道,虽然提高了速度,但长期看架构腐化风险会不会增加?希望作者能分享半年后的代码质量数据,比如技术债务指数或线上故障率的变化,这样说服力更强。