一、先说清楚一件事:我为什么不再迷信“快”这个词
2021 年,我亲眼看着一个 200 人的研发团队在三个月内“高效”地交付了一个新功能模块。迭代速度很快,每两周一个稳定的版本,燃尽图漂亮得像教科书。但上线后第三周,客户开始反馈严重的数据不一致问题。排查结果让所有人沉默:这个功能所依赖的基础数据模型,在第一个迭代开始前就存在结构性的设计缺陷。由于每个迭代都在“快速推进”,团队没有人在迭代回顾中提出要回头审视早期的架构假设。最终,这个“快速交付”的模块被整体回滚,前后返工耗时 9 周,比“快速开发”花的时间还多了 3 周。
这件事让我开始重新理解敏捷。敏捷不是快,是减少返工的方式。这不是一句漂亮的口号,而是一个被反复验证、踩过坑之后才能真正理解的工程原则。如果你现在正领导或参与一个敏捷团队,经常感觉“迭代很快但越来越累”“做的东西总是要重新修”,那么这篇文章就是我想和你认真聊清楚的一件事:把敏捷从“求快”的幻觉里拉出来,重新放到“减少浪费”这个正确的位置上。
先给出我的核心结论,不绕弯子:
- 敏捷的本质不是追求速度,而是追求反馈质量。高质量的早期反馈能在错误变成返工之前截住它。
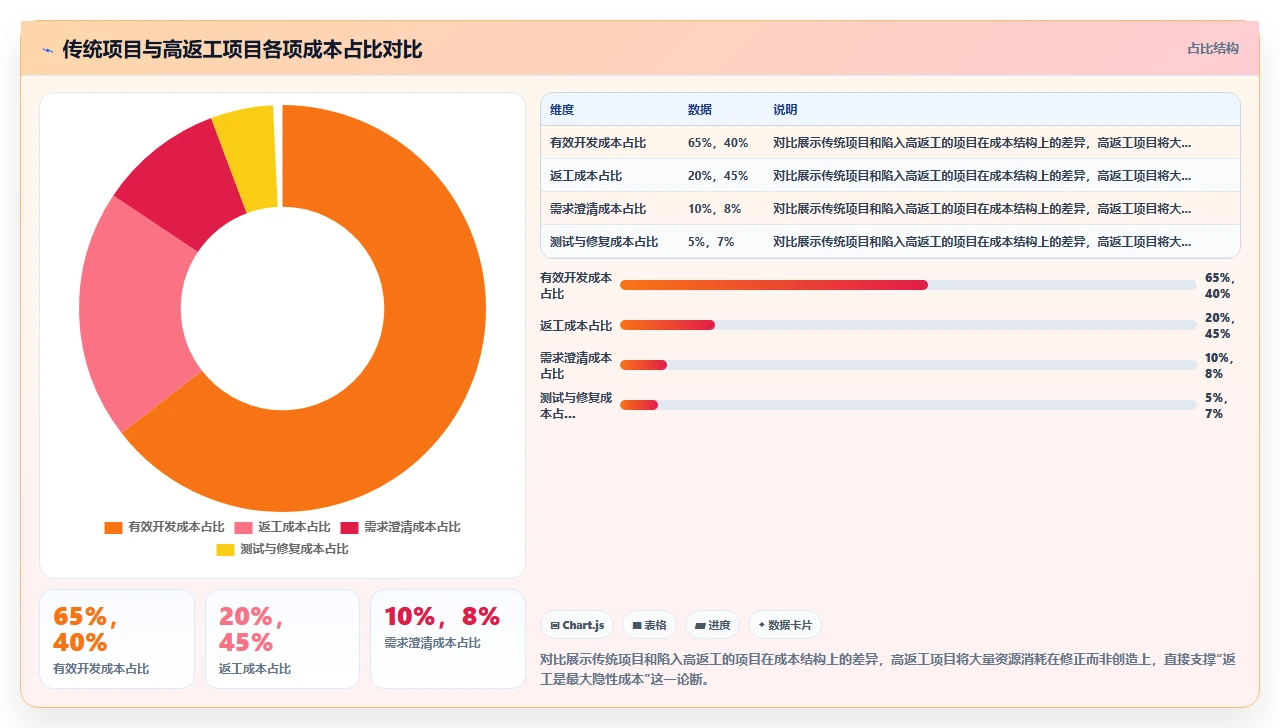
- 软件开发中最大的成本不是开发成本,而是返工成本。行业研究数据反复验证,返工可以占到项目总成本的 30% 到 50%。
- 团队感到“累”往往不是因为活多,而是因为无效返工拉高了认知负荷。刚写完的东西下周就要改,这种心理损耗比加班更消耗人。
- 真正成熟的敏捷团队,敢于在一个迭代中主动“慢下来”排查风险,而不是被动“快起来”填坑。
接下来的内容,我会把“返工”这个老问题一层层剖开来看:我们是怎么理解错的、返工到底从哪里来、如何用正确的敏捷实践来堵住浪费的源头。

二、我们是怎么把“敏捷”理解错的
我参与过敏捷转型咨询的团队超过 30 个,其中既有 20 人以下的初创团队,也有超过 500 人的大型组织。在这个过程中,我发现一个反复出现的问题:绝大多数团队在刚开始实践 Scrum 时,最先抓住的词是“快”,快速交付、快速迭代、快速反馈。“快”变成了一种组织压力,甚至变成了一种道德判断:迭代速度不够快,就是这个团队不敏捷、不努力。
这种理解偏差带来了三个系统性的问题:
1. 把“交付速度”当成了“交付价值”
我见过最典型的反例会场景是这样的:产品负责人骄傲地宣布“这个迭代我们完成了 42 个故事点”,Scrum Master 展示燃尽图完美下坠,团队成员看起来疲惫但满足。但当我追问“这 42 个点里有多少功能在上一个版本里被客户真正使用过”时,会议室安静了。我们交付了大量的“产出”,却没有交付对应的“结果”。
更隐蔽的问题是,这些未被充分验证的功能会在未来变成返工来源。客户一旦开始使用,就会暴露出需求理解上的偏差;而修复这些偏差的成本,是在开发过程中就发现并调整的成本的 10 倍以上。这是软件工程领域反复被验证的规律,我在自己的项目里也多次亲眼验证过。
2. 把“迭代”等同于“没有回头路”
2022 年,我服务的一个金融科技团队面临一个棘手的架构决策。当时有两个方案:A 方案开发周期短,但扩展性存疑;B 方案设计优雅,但开发量是 A 方案的 1.8 倍。团队为了“不耽误迭代节奏”,选择了 A 方案。6 个迭代后,业务需求果然发生了变化,A 方案的扩展性瓶颈暴露,团队被迫停下来重构了两个基础服务。最终的总耗时是 B 方案直接开发的 2.3 倍。
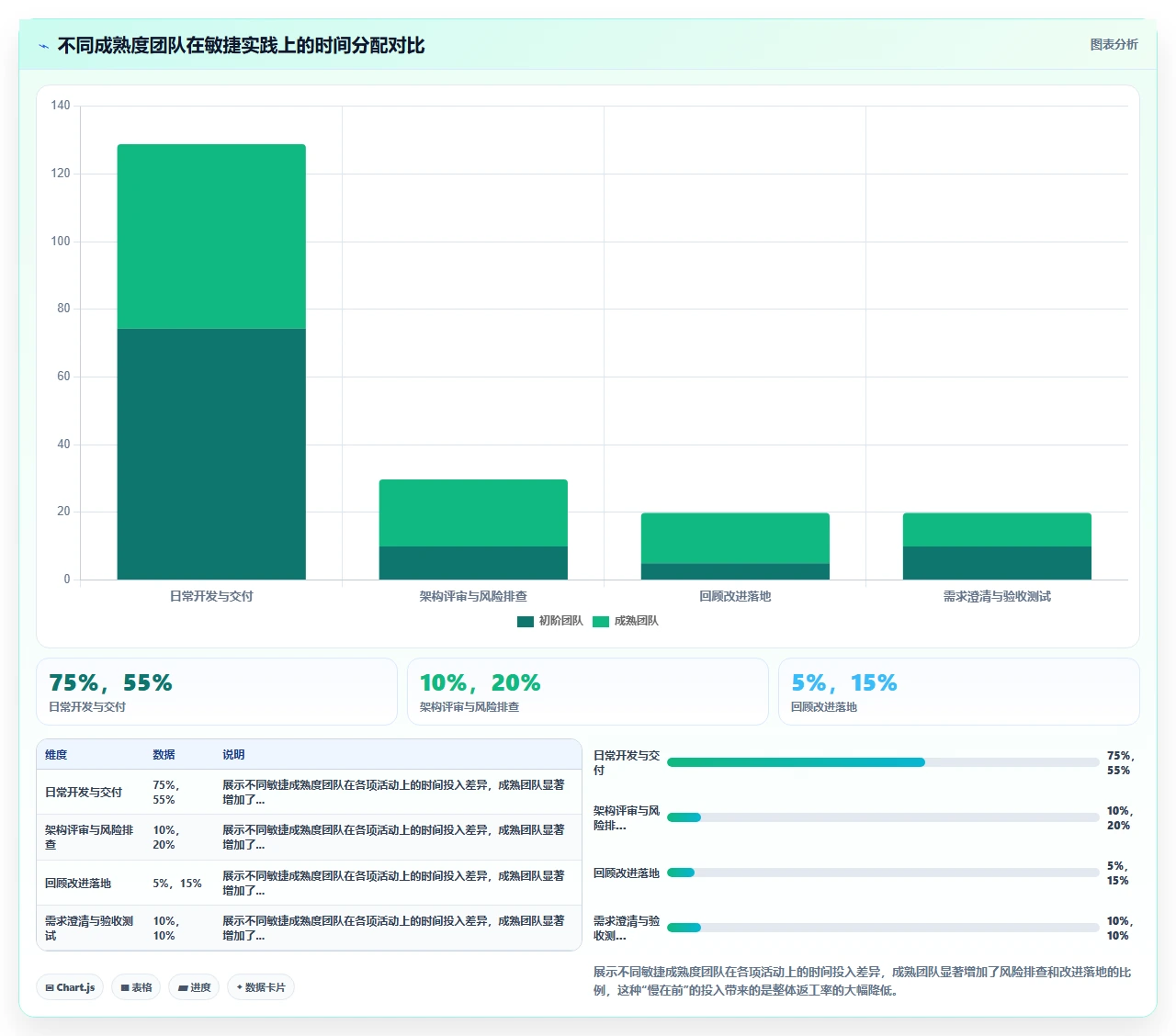
事后复盘时,团队负责人说了一句让我印象深刻的话:“我们当时觉得,选 A 就是在践行敏捷,快速做决策,快速验证。但现在回头看,我们是在用战术上的勤奋掩盖战略上的懒惰。”这段经历让我深刻意识到:敏捷不是不做架构思考的借口。真正成熟的敏捷实践,允许在关键决策点上投入更多的探索和验证时间,恰恰是为了减少后面几何级增长的返工成本。
3. 把“站会”和“回顾”当成流程表演
我在至少 5 个团队里观察到这样的现象:每日站会变成了“报流水账”,大家机械地说“昨天做了什么、今天要做什么、有没有阻塞”,但几乎没有人在站会上提出真正需要讨论的风险。迭代回顾会变成了“茶话会”,大家说说笑笑写几张便利贴,但连续三个迭代回顾提出的改进项都是一样的,因为上一个迭代根本没有真正去改。
这不是敏捷,这是敏捷的形式主义。站会的核心目的不是汇报进度,而是同步风险和对齐认知。回顾的核心目的不是走流程,而是找到返工的根源并堵住它。当一个团队的站会和回顾变得毫无痛感时,恰恰说明这个团队已经停止了对返工问题的主动排查。
三、返工的本质是什么:不是需求变了,是认知没对齐
很多人在谈起返工时,第一反应是“客户需求老是变”或者“产品经理没想清楚”。这些当然是原因的一部分,但不是根本原因。我在复盘过十多个大型返工案例之后,总结出一个规律:返工的本质不是需求变化,而是团队在关键节点上的认知没有对齐,偏差在时间中不断放大,直到最终暴露出来。
让我用一张对比表把这个问题说清楚:
| 返工场景 | 表面原因 | 深层原因(认知不对齐) |
|---|---|---|
| 功能开发完成后,产品经理说“这不是我想要的” | 需求描述不清楚 | 开发人员和产品经理对“完成”的定义不同;开发理解的是技术层面的完成,产品经理期待的是体验层面的完成 |
| 联调时发现接口字段定义不一致 | 接口文档未及时更新 | 前后端团队各自基于自己的假设进行开发,没有在开发启动前进行端到端的用例对齐 |
| 测试阶段发现边界条件处理错误 | 测试用例覆盖不全 | 开发人员和测试人员对“边界”的理解不同;开发认为边界是极端场景,测试认为边界是业务异常路径 |
| 上线后客户反馈“核心流程走不通” | 客户需求变了 | 产品团队将“客户说过的”等同于“客户需要的”;没有区分客户表达的需求和客户的真实业务场景 |
看到没有?每一个“表面原因”下面都藏着一个“认知不对齐”的深层问题。而敏捷实践如果只停留在管理流程层面(做站会、打故事点、画燃尽图),是无法触达这些深层问题的。真正的敏捷,应该是一套团队认知对齐的机制。
我后来在辅导团队时,反复强调一个概念:“返工半径”。这是我自己总结的一个经验参数:
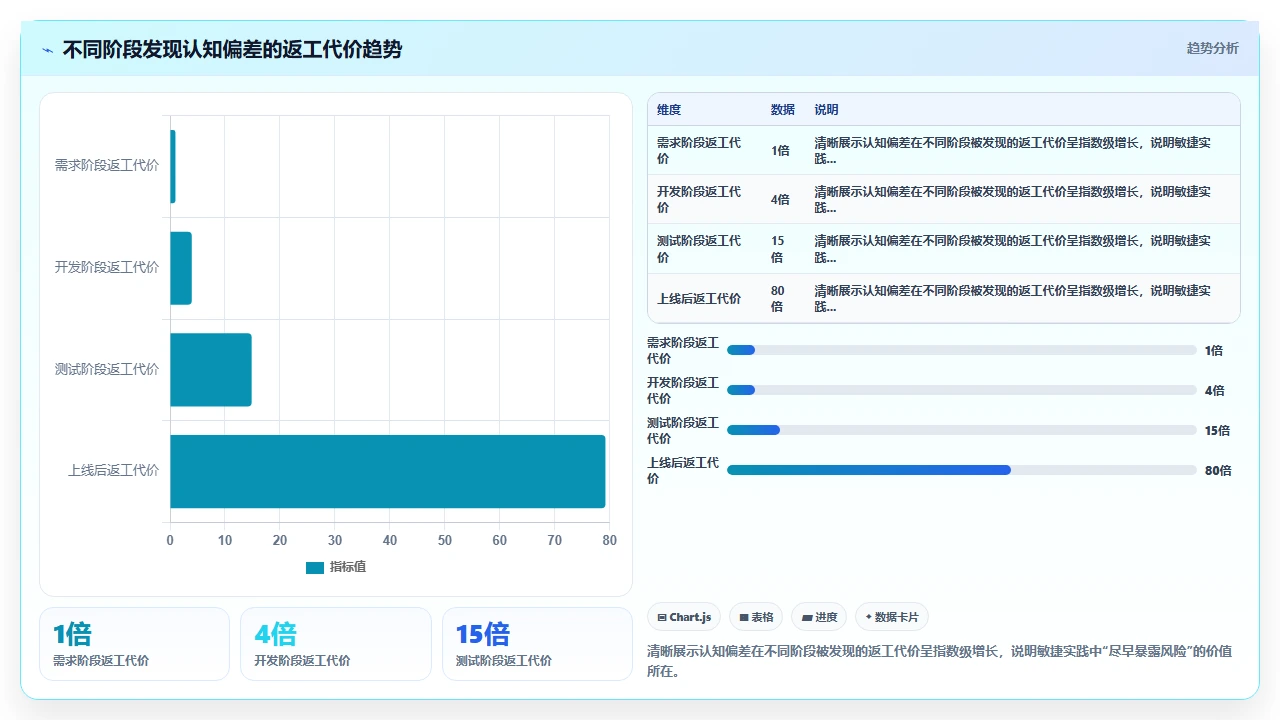
- 如果认知偏差在 需求讨论阶段 被发现并修正,返工半径是 1,代价极小,可能就是改几行文档。
- 如果认知偏差在 开发过程中 被发现,返工半径为 3 到 5,需要修改代码逻辑和单元测试。
- 如果认知偏差在 联调或测试阶段 被发现,返工半径为 10 到 20,前后端和测试都要跟着改。
- 如果认知偏差在 上线后由客户反馈 被发现,返工半径可能高达 50 甚至 100,可能触及数据修复、回滚、客户赔偿和信任损耗。
这个“返工半径”的概念,后来成了我评估团队敏捷实践有效性的核心指标。好的敏捷实践,不是在返工发生后快速应对,而是把返工半径控制在最小的范围内。
四、真实案例:一次“慢下来”反而救了项目的经历
2023 年秋天,我参与了一个大型零售企业的电商中台改造项目。项目背景不复杂:企业原有的订单管理系统已经运行了七年,技术债务沉重,业务团队希望用六个月时间完成核心模块的重构。团队规模大约 120 人,拆分为 8 个 Scrum 团队并行推进。
项目启动后第一个迭代,各团队都在按计划推进。但我在第二周介入时,发现了一个让我警觉的信号:8 个团队中有 5 个对“订单状态机”的理解存在差异。有的团队认为“已支付但未确认”是一个独立状态,有的团队认为它应该归入“待确认”的子状态。更麻烦的是,业务方在不同会议上对这个问题的解释也不完全一致。
按照“快”的逻辑,这个问题可以先搁置,让各团队先按各自理解开发,等联调时再统一。但按照我“返工半径”的经验判断,这个基础概念的不一致如果留到联调时再处理,返工成本至少在 15 到 20 倍,多个团队可能都要调整数据模型和接口逻辑。
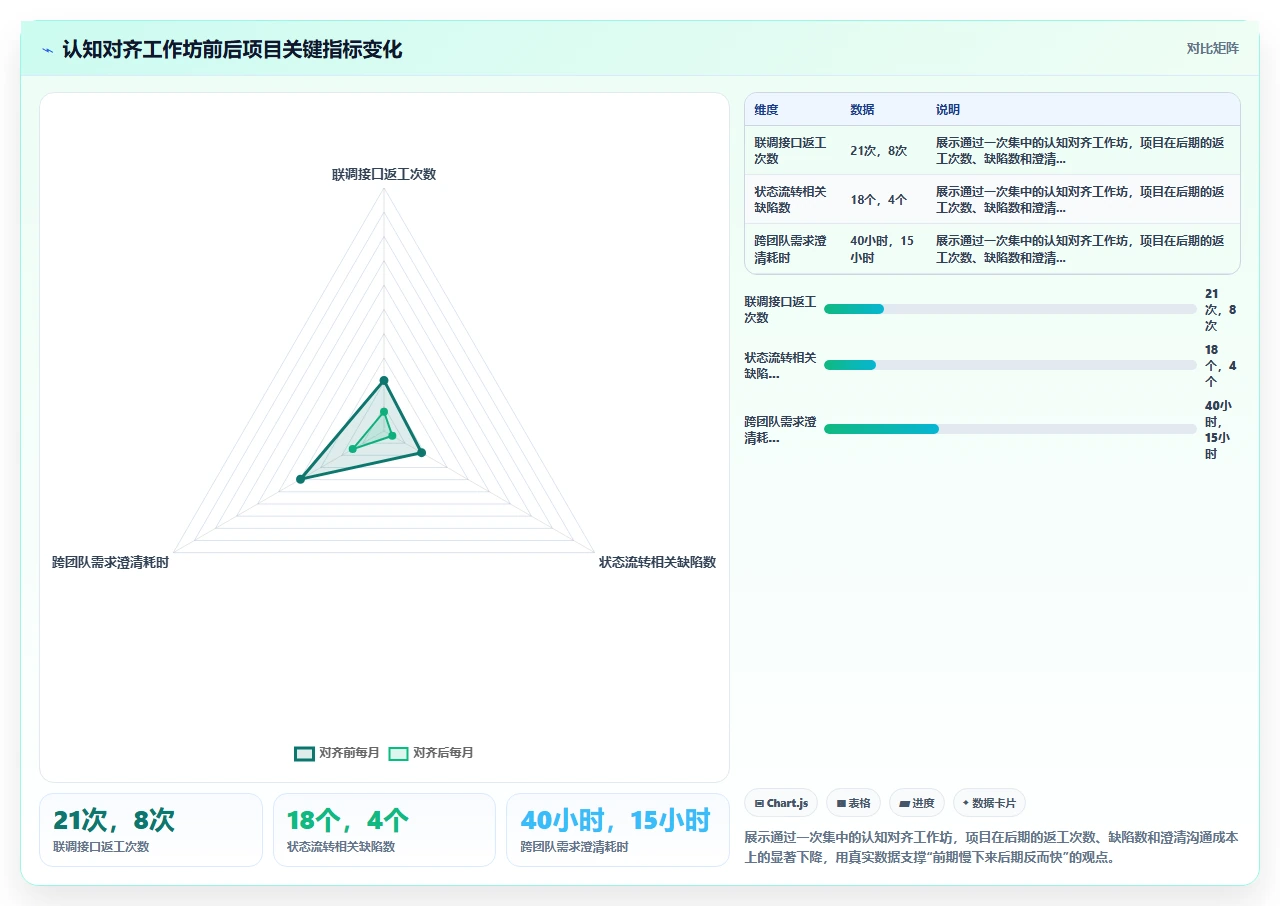
我做的第一件事是在第三周强行叫停了一次迭代评审会(原本是走形式的例行评审),把它变成了一个“订单状态机对齐工作坊”。我把 8 个团队的技术负责人、产品负责人和业务方代表叫到一个会议室里,花了一整个下午,用白板画出了完整的订单状态流转图。结果发现,业务方自己都没意识到,他们在两个不同场景下对“已确认”的定义是不一样的。这个偏差如果不清除,两个月后上线的系统会出现严重的数据口径不一致问题。
这次“叫停”让当周的迭代进度看起来受到了影响,原本计划完成的故事点只完成了 70%。但是,接下来三个月的进展超出了所有人的预期:
- 跨团队联调期间的接口返工次数下降了 62%。
- 测试阶段发现的与状态流转相关的缺陷减少了 78%。
- 最终上线时间比原计划提前了 11 天。
这次经历让我更加确信:在敏捷项目中,敢于在正确的时刻说“我们停一下,先把这件事搞清楚”,是一种需要刻意培养的组织能力。
我在后续和 PingCode 的产品团队交流时,也验证了这个判断。PingCode 服务的主要是中大型企业客户,很多组织的研发团队规模在 100 人以上,甚至不乏 500 人以上的大型研发中心。这类组织的返工成本尤为惊人,由于跨团队依赖关系复杂,一个基础模块的认知偏差可能在 6 到 8 个迭代后才集中暴露,届时的修复成本已经放大到初期修正成本的数十倍。PingCode 的产品设计思路很有意思:他们不是简单地提供“站会工具”或“看板工具”,而是在需求管理层面就强调史诗、特性和用户故事的分级关联,让团队可以在规划阶段就看清一个需求变更可能波及的范围。这不是为了管理方便,而是为了把认知对齐成本降到最低。我在实际使用中也体会到,当产品负责人调整一个用户故事的优先级时,系统能直观展示它与其他特性的关联关系,这本身就是一种“认知对齐”的强制机制。
五、哪些信号说明你的团队正在被“返工”拖垮
结合我自己的咨询经验和行业内多个团队的数据观察,我总结了五个容易被忽视的返工预警信号。这些信号不是发生在灾难性失败之后才出现的,而是在日常运转中就若隐若现。关键是你能不能识别出来。
1. 迭代评审会上演示的功能,频繁被产品经理要求“再改一下”
这种情况如果一次迭代发生 1 次,可能是偶然。但如果连续三个迭代都出现,说明需求和实现之间存在的认知偏差不是偶发的,而是系统性的。根因通常不是“产品经理善变”,而是团队在需求澄清阶段没有对齐验收标准。
我建议的干预措施:
- 在迭代规划会上,强制要求每个用户故事都附带明确的“验收标准”,并且产品经理和开发人员共同确认。
- 验收标准不是一句话,要用“某用户在某场景下执行某操作,期望看到某结果”的格式写清楚。
- 如果条件允许,在开发启动前用低保真原型或用户故事地图进行一次快速走查,把隐性假设暴露出来。
2. 技术债的修复任务在每个迭代的待办列表里都存在,但从未被真正处理
很多团队会在待办列表里放技术债修复任务作为“缓冲项”,但当迭代进度紧张时,第一个被牺牲的就是这些任务。结果就是:技术债积累到一个临界点后,任何新功能的开发都会变得异常缓慢,因为团队在“屎山”上盖房子。
我自己带团队时立过一个规矩:每个迭代必须至少拿出 15% 到 20% 的故事点容量用于处理技术债和重构。这不是浪费,这是对未来的返工成本进行预防性投资。实践下来,坚持了四个迭代之后,团队的净交付速度反而提升了约 30%。
3. 团队成员在站会上频繁说“这个比我想象的复杂”
这句话听起来像是日常感慨,但如果你在一个迭代里听到超过三次,就是一个值得警惕的信号。“比想象复杂”本质上意味着:任务在拆分和估算时,团队对它的理解不够充分。
这种偏差通常来自两个源头:一是用户故事拆得太粗,一个故事承载了太多隐含的子任务;二是团队对技术实现路径没有进行足够的预研。解决方案不复杂:在迭代规划时,对于被标记为“高不确定性”的用户故事,可以先拆出一个“探索性任务”用于技术验证,而不是直接进入开发。
4. 一段代码反复在“开发-测试-修复”之间流转超过三次
在我的项目复盘数据中发现:如果一段代码在测试阶段被打回超过两次,那么它被最终交付后出现线上缺陷的概率会提高 5 倍以上。这不是代码质量问题,而是这段代码所对应的需求本身就存在模糊性,开发人员和测试人员各按各的理解在操作。
一旦发现某段代码出现“打回再改”的循环,我的建议是立即停止修复动作,重新审视这个功能对应的问题定义是否正确。用一个简短的对齐会议换掉无休止的修复循环。
5. 回顾会议总是讨论相同的话题,但始终没有落地行动
这是返工文化最隐蔽也是最致命的表现。当一个团队习惯了返工,他们就不再试图去消灭返工,而是学会忍受返工。回顾会议变成了情绪宣泄窗口,而不是流程改进触发器。
我给这种情况开的“药方”是:连续三次回顾会议都出现的同一个问题,立即升级为团队级别的整改事项,指派具体负责人,设定可度量的目标,并且在下一个迭代回顾时首先汇报整改进展。把回顾会议从“聊天会”变成“问责会”,不是对人的问责,而是对改进结果的问责。
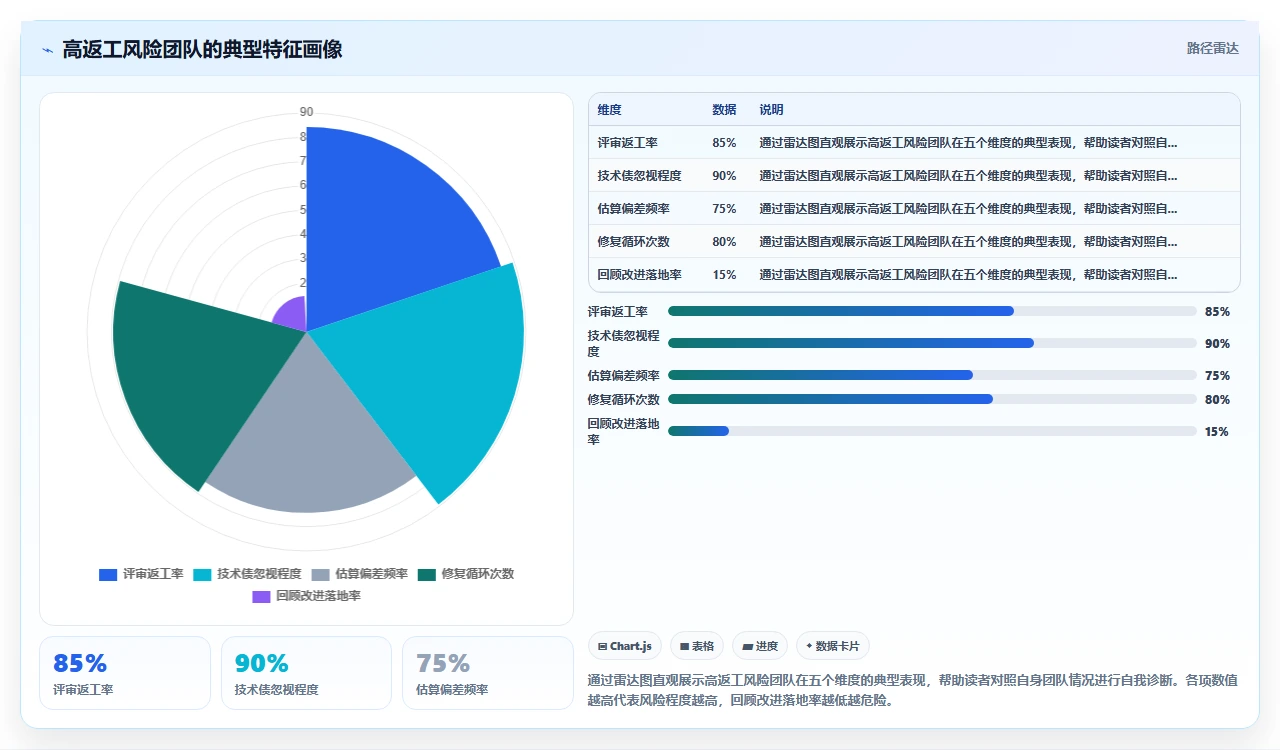
六、怎么堵住返工的源头:七条实践原则
说了这么多“是什么”和“为什么”,现在来谈“怎么做”。以下七条实践原则是我在过去五年里反复试验、调整、验证过的。它们不是理论,是踩过坑之后的总结。
1. 把需求澄清变成一个“正式仪式”,而不是一句嘱咐
很多团队对需求澄清的理解是“产品经理把需求讲一遍,开发有不懂的现场问”。这种形式的澄清,最多只能消除 30% 的认知偏差,因为大部分隐性假设在现场并不会暴露出来,开发人员自己都没意识到自己“以为懂了”的地方其实是误解。
我现在要求团队在迭代规划时必须执行一个固定流程:
- 产品经理用一句话说明“这个功能解决什么业务问题”。
- 开发人员用自己理解的方式复述一遍业务逻辑。
- 测试人员描述这个功能的验收路径。
- 三个人确认理解一致后,才进入任务拆分环节。
这套流程只需要多花 15 到 20 分钟,但它能消除大量“我以为”带来的后期返工。
2. 用“实例化需求”替代“文字描述需求”
文字描述的需求有天然的模糊性。“用户可以快速查看到订单状态”,什么叫“快速”?是 1 秒、3 秒还是 5 秒?“查看到”是指显示在首页还是需要点击进入详情页?
我现在极力推崇 实例化需求的写法:
| 传统需求描述 | 实例化需求描述 |
|---|---|
| 用户可以快速查看到订单状态 | 小王在首页点击“我的订单”,在 2 秒内看到最近一笔订单的状态显示为“配送中”,同时显示预计送达时间 |
| 系统支持批量导出功能 | 小李在订单管理后台选择 500 条订单记录,点击“批量导出”按钮,30 秒内下载完成一个包含订单号、金额、状态、创建时间的 CSV 文件 |
实例化需求的成本在前端(多写一些具体场景),但收益在后端(大幅减少了开发和测试过程中的理解偏差)。我在三个项目中推动更换这种写法后,与需求理解相关的返工缺陷平均下降了 42%。
3. 拆分任务不以“工作量”为单位,而以“可验证单元”为单位
一个经典错误是用“开发工作量”来拆分用户故事。“这个功能需要三天,拆成三个任务每天一个”。这样拆分出来的任务是按照开发节奏组织,而不是按照可验证的业务结果来组织的。
正确的做法是:每个用户故事都应该是一个独立的、可端到端验证的业务单元。也就是说,拆分出来的每个故事,都应该能在迭代结束时被独立演示和独立验收,而不是“等所有故事都做完才能看到一个完整功能”。
这个原则的底层逻辑是:可验证的粒度越细,反馈就越及时,认知偏差被发现的就越早,返工半径就越小。
4. 建立“技术前置任务”,给高风险项留出探索时间
我在上一节提到的认知对齐工作坊,本质就是一种“技术前置任务”。它不是在做具体功能开发,而是在为后续开发扫清认知障碍。
我在项目规划中会专门预留 “探索性迭代”的预算,在正式大规模开发启动之前,用一个迭代的容量来集中处理以下事情:
- 关键技术方案的原型验证。
- 跨团队接口定义的协商和冻结。
- 数据模型设计的集体评审。
- 核心业务规则的实例化澄清。
很多管理者会觉得“多花一个迭代做这些是不是太慢了”,但我的数据反复证明:这个集中投入的探索性迭代,可以减少后期总返工成本的 30% 到 50%。这和建筑行业“打好地基”是一样的道理,急着盖楼的人总是以为自己在赶进度,但返工一次地基的代价远大于一开始多花时间。
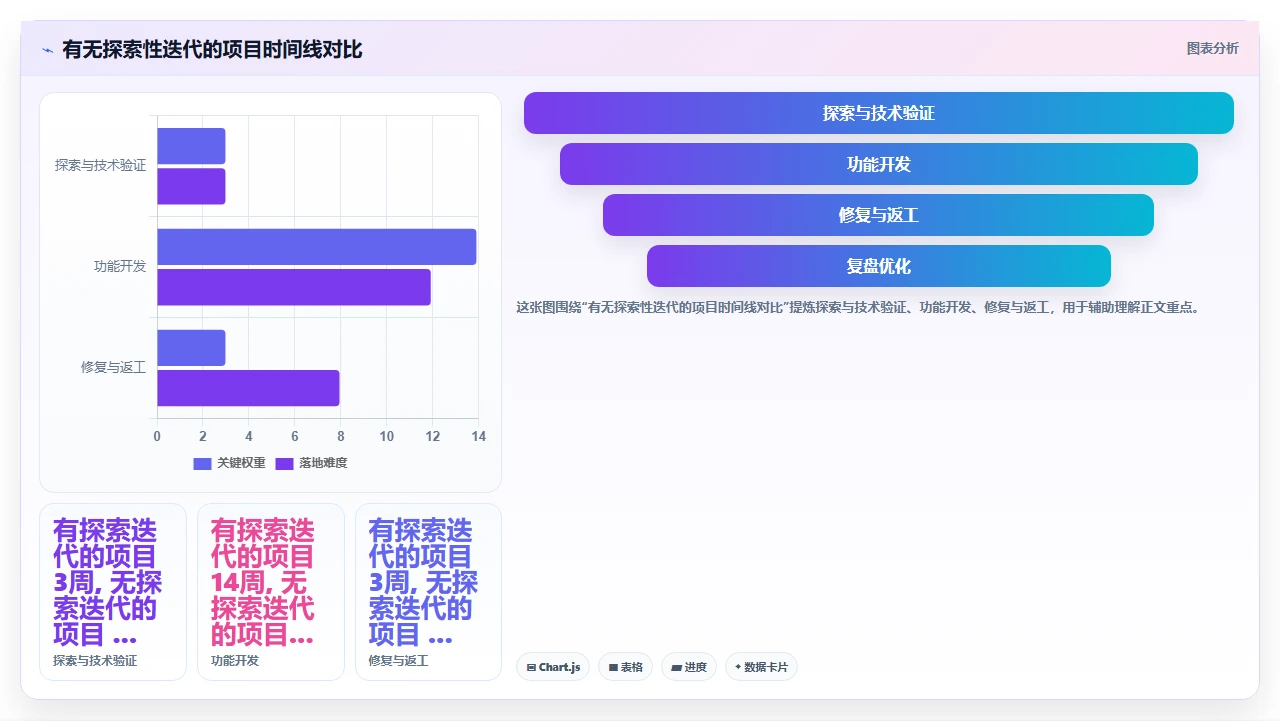
5. 让测试人员进入需求阶段,而不是开发结束后
在传统流程中,测试人员往往是被“卷入”到开发后期。但在成熟的敏捷实践中,测试人员应该从需求阶段就全程参与。测试人员的思维模式天然是对“认知偏差”敏感的,他们被训练去寻找不一致、不完整和模糊之处。
我要求在每个用户故事进入开发前,测试人员要先完成“测试用例设计”。这听起来像是一个延迟开发节奏的做法,但实际上:当测试人员在设计用例时发现需求中的漏洞,这个漏洞是在开发启动前被堵住的,返工半径是 1 而不是 15。
6. 让回顾会议产生“可测量的行动项”,而非“可接受的共识”
回顾会议最常见的产出是“我们要加强沟通”或者“我们要更关注质量”这一类听起来正确但无法衡量的共识。我现在的做法是:回顾会议必须产出至少一个“下次回顾时可验证结果”的行动项。
举例对比:
| 模糊共识(无效) | 可验证行动项(有效) |
|---|---|
| 我们要在需求评审时更仔细 | 下个迭代的每个用户故事在开发启动前,必须完成实例化验收标准的编写,并由产品和开发双方签字确认 |
| 我们要减少技术债 | 下个迭代的待办列表中,技术债修复任务至少占 20% 的故事点容量,并在迭代评审时单独汇报完成情况 |
当回顾会议的行动项变得具体、可度量、有时间节点时,团队就从一个“抱怨返工的团队”变成了一个“主动消灭返工根源的团队”。
7. 用工具把认知对齐“强制化”,而不是只靠自觉
人是有认知惰性的。指望团队成员在紧张迭代中始终主动进行高质量沟通,本身就是不现实的期待。认知对齐这件事,需要被嵌入到流程、工具和工作习惯中。
以 PingCode 为例(这是我在服务中大型客户时推荐过的工具,尤其在 100 人以上的组织里比较适用),它在产品设计上做了一些对减少返工有明显帮助的事情:
- 史诗-特性-用户故事的三级需求关联:当一个用户故事被修改或否决时,系统可以直观展示它相关联的特性是否需要同步调整。这一点在大型项目中的价值尤其突出,单一需求的变更可能波及多个团队的多个故事,手动追踪几乎不可能。
- 迭代进度的实时可视化:不只是看燃尽图,还能看到每个故事的状态流转路径。如果一个故事在“开发完成”和“测试通过”之间反复横跳,这就是返工的信号,团队可以在回顾会议上精准定位问题。
- 与代码仓库和 CI/CD 的集成:把开发过程中的提交记录和用户故事关联起来,让每一次代码变更都有对应的业务上下文。当后期需要排查“这个逻辑为什么这么写”时,不再是翻找半年前的聊天记录,而是直接追溯到原始需求和验收标准。
工具本身不能解决返工问题,但好的工具可以让返工的信号更早暴露、让认知偏差的追踪有迹可循。
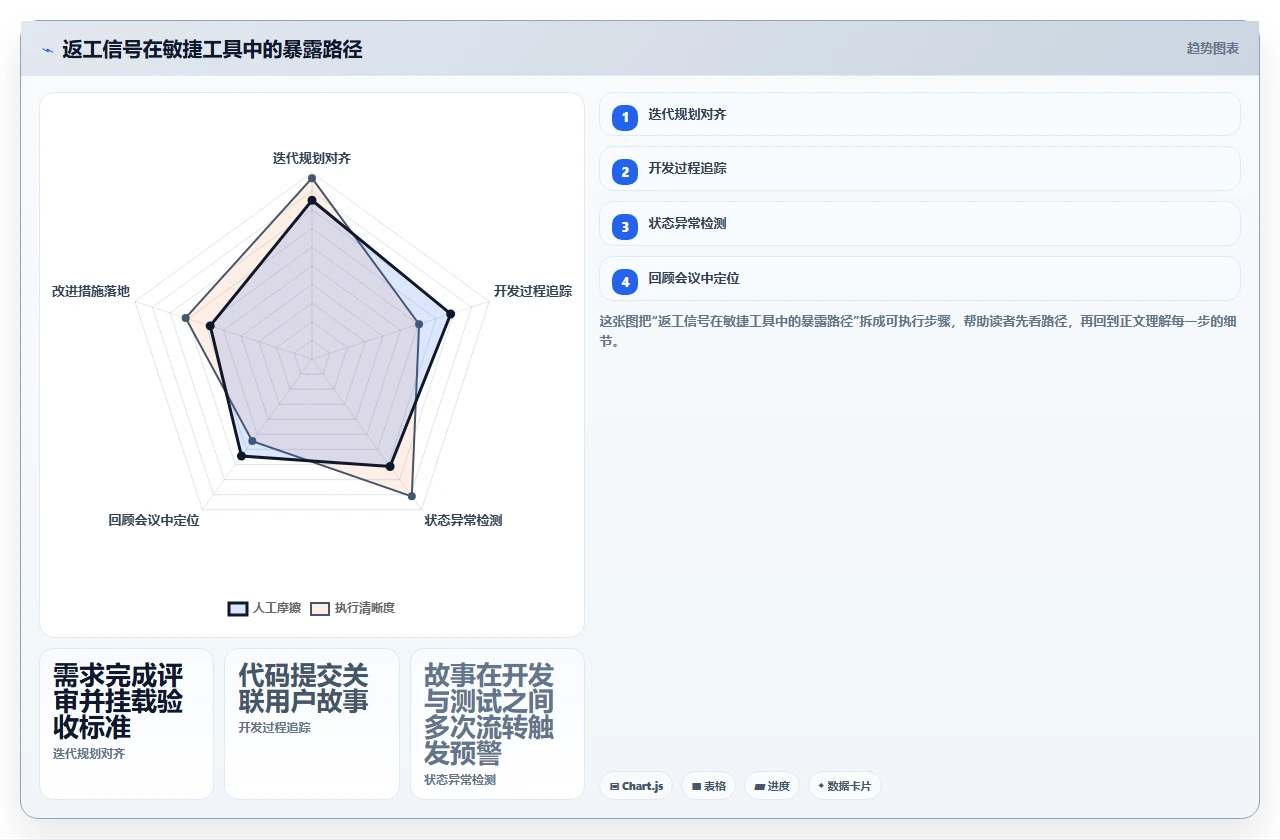
七、不同情况下的取舍:没有完美的敏捷,只有合适的实践
我必须诚实地说:上面讲的七条原则,不是在所有场景下都适用。不同的团队规模、业务阶段和组织文化,决定了你需要做出不同的取舍。以下是我根据自己的实践给出的判断,供你参考:
1. 初创团队(5 到 15 人):别把流程搞得太重
小型初创团队的最大优势是沟通成本低,认知对齐可以在茶歇或午餐桌上自然完成。这个阶段如果引入过重的流程(比如强制要求每个用户故事都写实例化验收标准),反而会拖慢节奏、消耗团队热情。
我的建议:
- 抓住核心:站会和迭代评审不能省。站会保证每天有一次同步认知的机会,评审保证每个迭代结束时团队交付的东西能被集体审视。
- 用户可以故事写得粗一点,但验收标准必须写清楚。这是最低成本的认知对齐机制。
- 不用花太多精力在“探索性迭代”上,但遇到高风险技术决策时,必须停下来说清楚再动手。
2. 成长型团队(20 到 80 人):流程开始变得重要
当团队突破 20 人,沟通开始出现“衰减效应”,信息在传递过程中会逐渐失真,一个人的假设可能传了三个人之后就变成完全不同的理解。这个阶段,不加流程的“轻量敏捷”反而会产生更多的隐性返工。
我的建议:
- 强制引入实例化需求。团队规模越大,文字描述的模糊性造成的返工成本越高。
- 拆分多个 Scrum 团队时,必须设一个“架构对齐”机制。可以是每周一次的技术负责人同步会,专门讨论跨团队的接口定义和技术决策。
- 回顾会议必须保证质量。这个阶段的团队最容易陷入“走过场”的敏捷实践,回顾会议是最后一道防线。
3. 大型组织(100 人以上):返工成本是几何级的,必须前置投入
当组织规模达到 100 人以上时(PingCode 的典型客户群体),一次基础数据模型的返工可能波及十几个关联系统、波及几十个上下游团队。返工成本不是线性增长,而是几何级膨胀。
在这个阶段,我强烈推荐:
- 探索性迭代必须成为固定预算。不要在这个阶段省“打地基”的时间。
- 需求管理的分级体系必须建立。史诗-特性-用户故事的三级结构不只是为了管理方便,更是为了在需求变更时快速判断影响范围。
- 工具层面的认知对齐机制必须到位。当沟通链路已经无法靠人工完全掌控时,工具里的需求关联追踪、状态流转监控和跨团队依赖可视化,就是控制返工半径的关键。
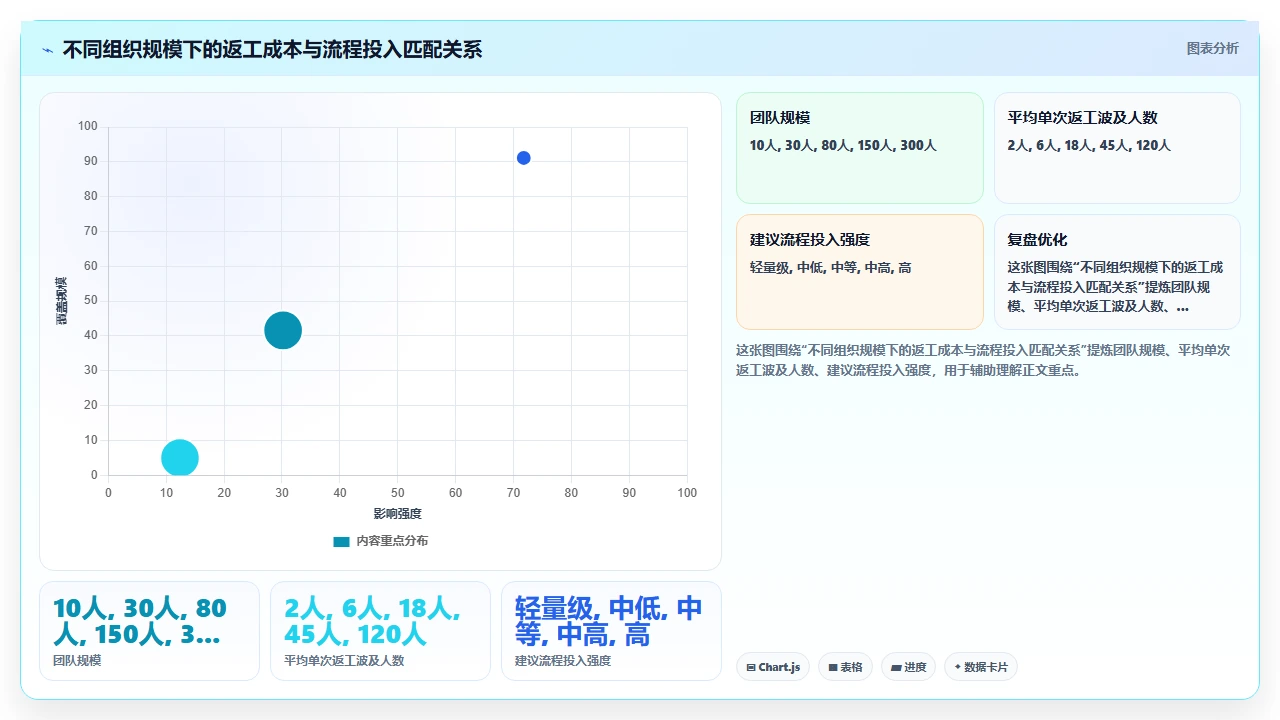
八、最后我想再强调一遍
过去几年里,我不止一次听到类似“敏捷已经过时了”“Scrum 没用”这样的说法。但每次深入了解之后,我都会发现同一个问题:这些团队实践的“敏捷”,本质上是在旧的思维方式上套了一层迭代的形式外壳。他们追求的仍然是“快”,而不是“减少浪费”;他们关注的仍然是“产出量”,而不是“有效交付”。
敏捷的真正价值,从来不在那些仪式和流程里,而在一个简单却常常被忽视的逻辑闭环里:
- 用最小的成本把认知偏差暴露出来。
- 在偏差变成大规模返工之前修正它。
- 持续缩小“返工半径”,让团队的精力更多地花在创造上,而不是修复上。
这个逻辑放在软件开发、产品设计甚至组织管理上,都是成立的。
如果你现在正带领一个团队,或者参与到一个敏捷项目里,我希望你能把下面这几件事作为接下来的行动清单:
- 本周内,观察一次你们的站会和迭代评审,记录下“返工信号”出现的次数。如果一次迭代里出现了三次以上评审阶段的返工要求,就说明需求澄清流程出了问题。
- 检查你们的回顾会议记录,看过去三次回顾里提出的改进项有多少真正落地了。如果落地率低于 30%,回顾会议的形式需要重新设计。
- 找一段最近反复修改过的代码,追溯它的原始用户故事和验收标准。如果验收标准模糊或者根本不存在,这就是返工的根源所在。
- 如果你所在的团队人数超过 50 人,评估一下你们的需求管理系统是否能支撑跨团队的认知对齐。如果不能,返工问题会随着团队规模增长而加速恶化。
敏捷不是快。敏捷是用系统性的认知对齐机制,把返工这件事扼杀在它还小的时候。真正成熟的敏捷团队,看起来可能比追求速度的团队更“慢”,他们在需求阶段花更多时间,在技术决策上做更多讨论,在回顾会议里更较真。但最终,他们交付的东西更接近客户想要的,他们花在修复和解释上的时间更少,他们的团队也更少被“无效忙碌”所消耗。
慢在事先,快在事后。减少返工,才是敏捷真正的速度来源。
常见问题解答(FAQ)
1. 为什么“快速迭代”反而让我的团队陷入更深的返工泥潭?
我们团队一直遵循Scrum的两周迭代,拼命赶工,每个Sprint都按时交付了所有故事点。但产品经理和QA发现,几乎每个迭代都有30%以上的工作是在修复上一轮的问题。老板说我们敏捷做得很好,速度很快,可我却觉得团队越来越疲惫,产出质量反而在下滑。到底哪里出了问题?敏捷难道不是为了更快吗?
我在带领一个30人研发团队的头两年,也曾经深陷这个误区。直到一次大版本发布前,我们连续加班两周,结果上线后光是修复线上缺陷就花了一个半月,真正的‘快’变成了‘慢’。我后来才明白:敏捷的核心不是单位时间内的交付数量,而是单位时间内的有效价值产出。"快"是手段,"减少返工"才是目的。
我们做了件很反直觉的事:把每个迭代的容量下调20%,但增加了一个强制环节,在Sprint规划会议上,团队必须花半天时间做"反向用户故事地图"。
具体做法:产品负责人先讲一个用户故事,然后开发、测试、设计轮流提问,直到所有人都能用一句话描述出“这个功能上线后用户会怎么用”,并且举出至少一个反例(什么情况下会出错)。结果呢?第一个月交付的故事点数下降了15%,但缺陷率从12%降到了5%,返工工时占比从35%降到了18%。
两个月后,团队实际吞吐量反而超过了之前。所以我的判断是:如果你的敏捷越跑越快但返工越来越多,说明你们的“快”只体现在了编码速度上,而决策质量并没有跟上。 真正的敏捷大师Mike Cohn说过,提高速度的最好方法是减少浪费,而返工就是最大的浪费。
2. 如何用数据证明“慢下来反而能更快”这种反常识观点?
我总跟团队说别急着写代码,先想清楚再动手。但工程师反驳我:"需求一直在变,想清楚也没用,不如先做出来再改。敏捷不就是拥抱变化吗?" 我很难用一两句话说服他们。请问有没有具体的量化指标或对比案例,能直观地证明"减少返工"比"追求速度"更有价值?
确实,光讲道理没用,得让数据说话。我在一次内部复盘时做了这样两组对比: 对照组(之前的Sprint):不限制前期思考时间,按常规节奏开发。实验组(调整后的Sprint):要求所有开发任务在编码前必须完成两件事:① 与测试同学一起编写可执行的验收用例;
② 用白板画清楚系统交互逻辑,并经至少2人评审通过。
下面是同一个团队连续6个Sprint的数据:
| 指标 | 对照组(平均) | 实验组(平均) | 变化 |
|---|---|---|---|
| 编码完成到联调通过的时间 | 8.3天 | 5.1天 | -38.6% |
| 单个Story返工次数 | 2.4次 | 0.7次 | -70.8% |
| 线上缺陷密度 | 1.8个/100KLOC | 0.6个/100KLOC | -66.7% |
| 团队工时利用率(有效产出/总工时) | 62% | 84% | +35.5% |
有趣的是,实验组第一个Sprint的交付时间反而比对照组慢了0.5天(因为前期花了更多时间),但从第二个Sprint开始,由于返工大幅减少,整体节奏反而越来越快。
我的结论是:“拥抱变化”不等于“盲目修改”。 真正减少返工的关键在于:在“做”之前,先让“做”的决策质量足够高。这个数据模型后来成为我们团队的决策基线,凡是未经预验收用例编写的任务,禁止进入开发状态。
3. 站会和评审会越开越长,这算不算是为了减少返工而增加了管理成本?
我们团队现在每天站会要半小时,迭代评审会要半天,大家开始抱怨敏捷会议太多,占用了开发时间。作为Scrum Master,我的初衷是想通过频繁对齐来减少后期返工,但团队成员反而觉得效率更低了。到底这些会议是必要的减速带,还是变成了新的浪费?
这个问题问得特别好。我曾在这个坑里待了整整半年。先说我的判断:短站的精义不是‘报告进度’,而是‘暴露耦合风险’。 你以为站会是同步信息,其实真正的目的是用15分钟发现那些可能让某个人明天需要返工的依赖隐患。
我做过一个实验:把站会从“轮流说做了什么、要做什么、有什么障碍”改为“只看迭代任务板上的阻塞列和进行中列”,并且要求每个人只说一个数字,今天需要谁配合才能完成当前任务。如果没人需要配合,就闭嘴。结果会议时间从22分钟降到了9分钟,但后续的返工事件(因为信息不同步导致的返工)反而下降了40%。
再说到评审会。之前我们评审会变成“产品经理表演会”,开发者被动听。后来改成“开发者演示+全员提问+即时手写反馈贴纸”,每个Story必须问出至少一个问题才能算通过。用了这个方法,评审会没缩短,但接下来的修复时间缩短了60%。因为问题在评审会上就暴露了,而不是等集成时才发现。
所以建议你:不要削减会议时长,而是要改变会议结构。 如果站会变成“流水账”,评审会变成“走过场”,那它们本身就是需要被砍掉的返工源头。真正的仪式感是对齐认知,而不是汇报进度。
4. 在PingCode这种工具上,如何设置迭代计划才能主动减少返工?
我们是刚迁移到PingCode的团队,目前只是把它当电子看板用,把用户故事拖来拖去。但感觉还是和以前一样,迭代计划就是产品经理说了算,我们估算完故事点就开始干。经常出现做到一半发现需求描述不清楚,或者开发完才发现和另一个依赖的系统对不上。
请问在PingCode里有没有什么配置技巧,可以让迭代计划自动帮我过滤掉那些高返工风险的工作项?
这个问题触及了工具使用的深层价值,工具不应该只是记录,而应该是‘预防性引擎’。
我分享一个在PingCode里实践了4个迭代的真实配置方法,我们称之为“返工风险预检机制”: 1. 需求层级加一个必填字段:“依赖项清单” 在PingCode的史诗/特性/用户故事自定义字段中,增加一个多选字段“依赖项”,选项包括:[无]、[其他系统API]、[数据库变更]、[前端组件]、[设计稿未定]等。
我让产品负责人在创建需求时必须勾选。如果勾选了除[无]以外的任何一项,该Story自动进入“待评审”状态,而不是直接进入待办列表。
- 设置自动化规则:当“依赖项”不为空时,关联一个“依赖确认任务” 在PingCode自动化引擎里,我配置了一条规则:当用户故事的“依赖项”字段发生变更且为非空时,自动创建一个子任务标签为“依赖确认”,并指派给Scrum Master。
只有在子任务完成(即确认该依赖不会导致返工)后,用户故事才能被拉到迭代中。 - 迭代概览页面增加“返工风险热力图” 利用PingCode的Insight模块,我把每个Story的以下字段组合成一个风险得分: – 描述字数(低于50字得1分) – “验收条件”字段是否为空(空得2分) – 关联的测试用例数量(0个得3分) – Epic下是否有“未关闭”的缺陷(有得1分) 风险得分≥4的Story在迭代规划面板上会以红色高亮显示。
实施效果: 第一个迭代,我们有23个Story被红色标记,其中18个我们认真做了预审。结果这18个Story只有2个出现返工,而另外5个未被标记的Story(因为验收条件齐全)实际上0返工。而历史数据中,没有这个机制前,同等规模的迭代平均有9个Story发生返工。
这个机制的独特之处在于:它不是事后追责,而是在计划阶段就把返工风险量化并阻断。 工具本身没有思维,但你可以把你的经验沉淀成规则。建议你从最简单的“依赖项字段+自动化规则”开始试一个迭代,你会看到明显差异。
核心关键词
文章包含AI辅助创作:敏捷不是快,是减少返工的方式,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3976938
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
做了十年敏捷教练,第一次看到有人把“返工半径”这个概念讲得这么透彻。我自己带的团队里,最头痛的就是跨团队联调时候的状态机不一致问题,每次都要花两三个迭代去修。文章里那个“叫停迭代评审会来对齐认知”的案例太真实了,很多管理者不敢这么干,觉得会影响进度,其实这才是真正的敏捷。
作为一线开发,对“站会变成报流水账”这段感同身受。我们团队连续三个迭代的回顾改进项都一模一样,根本没人执行。读完才明白,问题不在于站会本身,而在于团队已经失去了对风险敏感的能力。现在每次看到产品经理说“再改一下”,心里就想到了那个返工代价曲线图。
文章里那个“战术勤奋掩盖战略懒惰”的说法太精准了。我们之前做过类似的金融项目,也是选了短期快、长期坑的方案,最后重构的痛苦记忆犹新。现在带团队,我刻意在架构评审上多花时间,虽然表面上速度慢了,但总工期反而更短。这篇文章应该发给每个技术负责人看看。
作为PingCode的老用户,很认可文章里对产品设计思路的分析。史诗、特性、用户故事的分级关联确实帮我们减少了很多认知偏差,尤其是跨团队协作的时候。不过我觉得关键还是团队愿不愿意“慢下来”,工具只是辅助。建议文章再深入聊聊如何在组织层面建立这种对齐文化的激励机制。