一、一个让我彻底放弃“估算总偏差”的真实时刻
2023年第三季度,我负责的一个产品线连续四个Sprint的估算总偏差都超过了40%。在回顾会议上,团队成员疲惫地坐在屏幕前,Scrum Master打开燃尽图,那条本该平滑下降的曲线在中段突然拉出一道刺眼的平直线。有人小声说了一句:“我们花在估算上的时间,可能比写代码的时间还‘认真’。”
这句话击中了所有人。我们当时使用PingCode管理整个Scrum流程,需求管理、迭代规划、任务拆分都在一个面板上完成,透明度和规范性已经超过绝大多数团队。但问题出在一个被行业默认为“最佳实践”的指标上,迭代估算总偏差。我们像上瘾一样盯着它,每个Sprint结束后计算偏差百分比,试图通过更精细的估算来缩小偏差,结果却是估算会议越开越长,偏差反而越来越稳定地维持在30%-50%之间。
那个季度末我做了一个决定:不再追踪“迭代估算总偏差”这个指标,转而测量每个需求从前到后的完整“前导时间”。这个决定在当时看起来像是一次冒险,但六个月后的数据让我确信,这是团队从“假装可控”走向“真正可预测”的关键转折点。

这篇文章不是要告诉你“估算没用”,而是要讲清楚一件事:当你用错了衡量标尺,越努力可能越偏离目标。下面我会完整拆解这个决策背后的逻辑、数据、踩过的坑,以及什么情况下你应该坚持估算,什么情况下应该果断放弃。
二、核心结论:问题出在“偏差”本身,而不是估算
先说我的判断,这是整篇文章的基石:迭代估算总偏差是一个“看起来客观实则有害”的管理指标。它的问题不在于数据不准,而在于它把团队的注意力引向了一个错误的方向,试图提高预测精度,而不是提高交付速度和质量。
让我把这个结论拆开来讲。
1. 迭代估算总偏差定义的是一道“无解题”
估算总偏差的计算公式通常是这样:(实际完成的故事点数 – 计划完成的故事点数)/ 计划完成的故事点数 × 100%。这个公式在数学上没问题,但在管理学上有一个致命缺陷,它假设“估算”是一个可以被持续改进逼近的客观值。事实上,软件开发的本质是知识工作,你在做一件你从来没做过的事情,怎么可能准确估算?
用一个实际场景来说明。假设团队对一个需求估算为8个故事点,实际完成花了13个点,偏差是62.5%。在传统的偏差追踪逻辑下,Sprint回顾时大家会讨论“为什么估不准”,然后提出改进措施,比如“下次拆分更细”“引入参考基准故事”。但真相是:如果这个需求涉及的技术栈、业务逻辑或依赖关系是团队没接触过的,任何估算方法都无法消除根本性的不确定性。
2. 缩小偏差的努力会产生“反生产力”
我观察到的规律是:当一个团队把“降低估算偏差”作为改进目标时,会出现以下连锁反应:
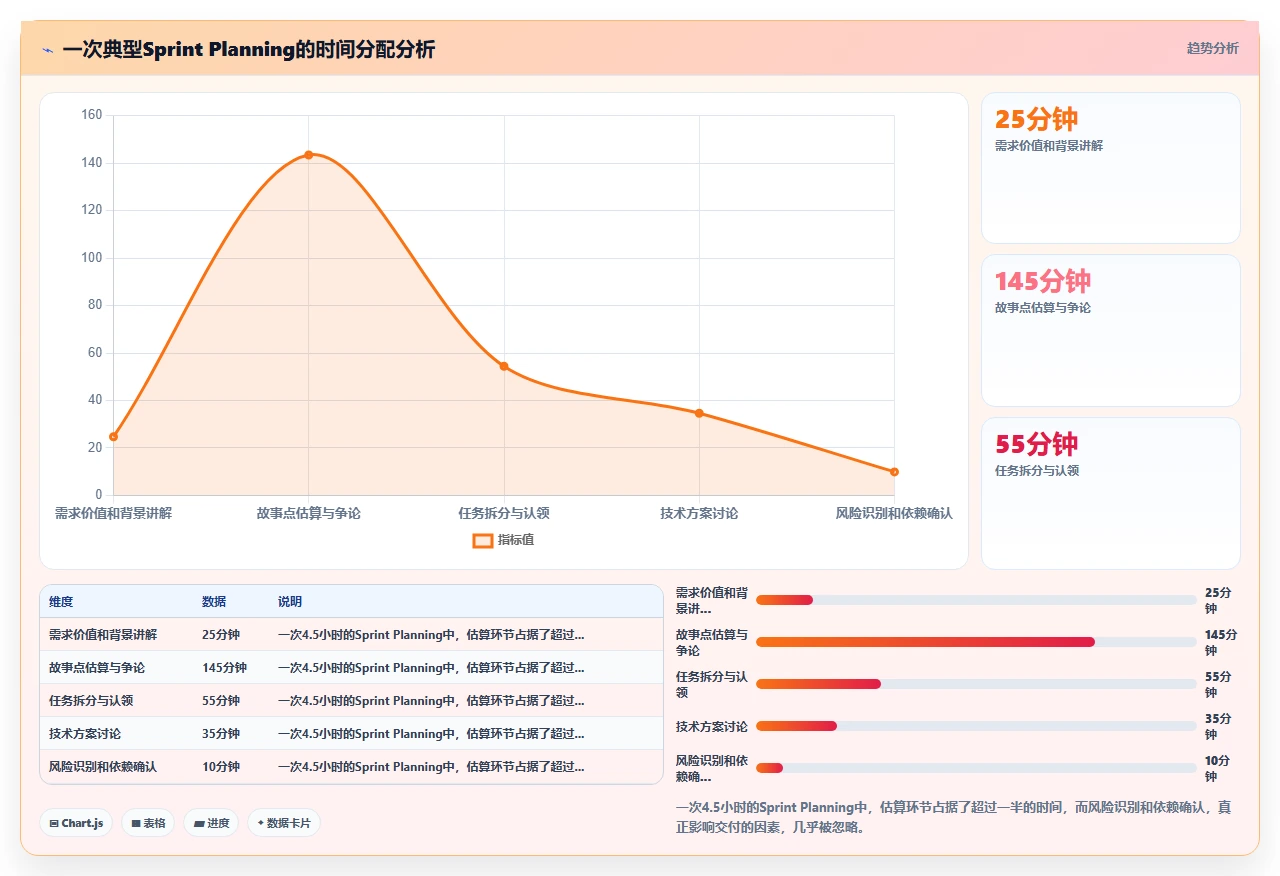
第一,估算会议时间逐渐膨胀。团队为了估得更准,会花更多时间讨论细节、参考历史数据、进行任务级分解。我们团队当时一个Sprint Planning最长达4.5小时,20个人坐在会议室里争论点数,而同期真正阻碍交付的技术瓶颈(比如测试环境不稳定、第三方接口文档缺失),在会议上几乎没被提起过。
第二,团队出现“安全缓冲”行为。开发人员开始习惯性在估算时加20%-30%的余量,以“确保偏差好看”。这种现象一旦蔓延,整个估算体系就失去了参考价值,因为所有数据都是注水的。
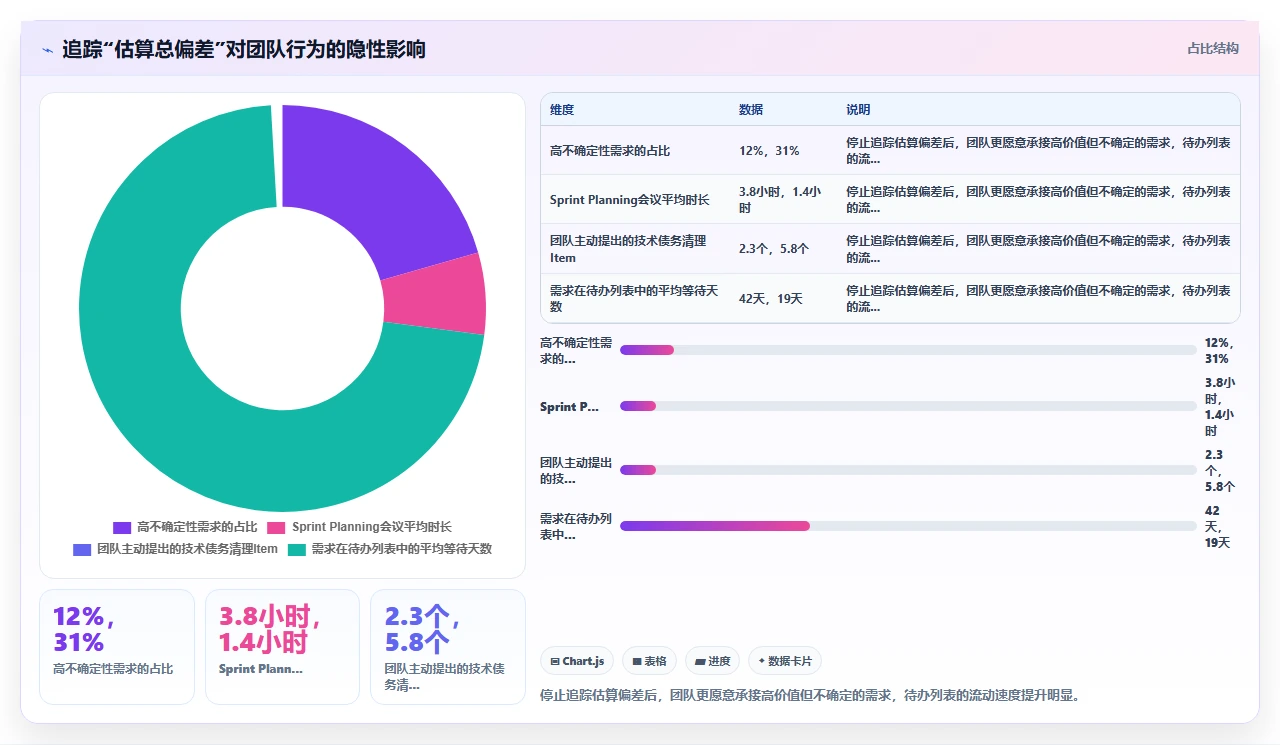
第三,也是我最担心的,关注偏差会让团队回避高价值但不确性高的需求。因为高不确定性意味着高偏差风险,而高偏差在回顾会上会被讨论和质疑。久而久之,产品待办列表里留下的都是那些“好估但价值平庸”的需求,真正的创新性工作被踢到了“下个季度再考虑”。
3. 前导时间是一个“因果导向”的替代指标
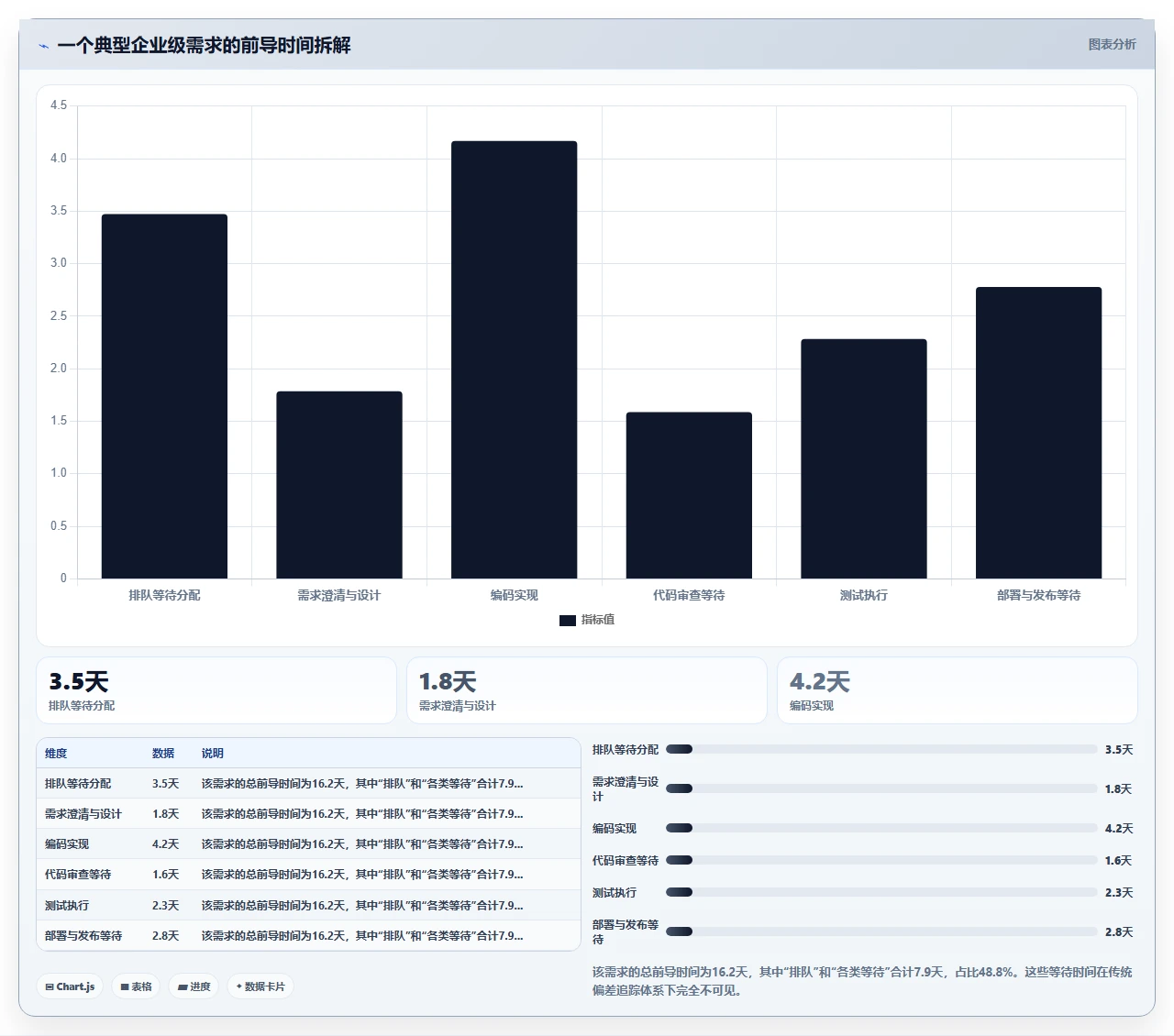
前导时间的定义很简单:一个需求从被团队确认开始,到它真正交付到用户手中(或上线到生产环境),所经历的全部自然时间。它不问你“你觉得要做多久”,它只记录“实际上花了多久”。
为什么这个指标比估算偏差更有价值?因为它的构成是可拆解的。你可以把前导时间切成几段:等待理解的时间、等待设计的时间、编码时间、代码审查等待时间、测试时间、部署等待时间。当你测量前导时间,你获得的不是一个“准不准”的判决,而是一张清晰的“在哪里慢了”的地图。
这是核心认知转换:从“我们猜得准不准”转向“我们流得快不快”。
三、真实场景还原:一个Sprint里的“估算表演”
为了让你更直观地理解这个问题,我完整还原一个我亲身经历的Sprint。
1. Sprint Planning的4.5小时
那是2023年8月的一个周三上午,团队20个人(包括前后端开发、测试、设计师、产品经理)坐在线上会议室里。PingCode的迭代规划面板已经打开,待办列表里有11个用户故事,总计预估87个故事点。
前30分钟还算正常,产品负责人讲解优先级最高的3个需求。但进入估算环节后,节奏开始失控。一个涉及“对接第三方支付渠道”的需求引发了长达40分钟的讨论。后端开发认为要做6个点,因为需要处理多种异常状态;测试同事认为不止,因为每种异常状态的回归测试都耗时;最后Scrum Master提议“先标8个点,中间如果发现多了再调整”。这个“再调整”的妥协方式在这个Sprint里出现了至少7次。
真正值得深思的是:这4.5小时会议里,没有任何人讨论“这个支付渠道对接后,用户转化率预计提升多少”或“错误率降低后的运维成本节省”,而这些才是需求的真正价值。我们像一群精算师一样试图预测未来,却忘了问“做这件事到底值不值得”。
2. Sprint中期:偏差已经开始显现
进入开发第3天,那项支付渠道对接的预估就崩溃了。对方提供的API文档与实际返回格式有多处不一致,光是联调就多花了两天。同时,另一个标记为“简单”的前端需求(估3个点)因为设计稿在开发期间被反复修改,实际耗时接近5个点。
到第7天站会时,PingCode的燃尽图已经明显偏离理想线。Scrum Master提醒大家“注意偏差”,但这番提醒没有改变任何事实,联调就是需要时间,设计改动就是需要重新开发。提醒偏差不会让问题消失,只会让团队多一层“又被监控了”的心理压力。
3. Sprint评审:偏差数据被“礼貌地”忽略
Sprint结束时,团队计划完成87个点,实际完成53个点,偏差39%。评审会上,产品负责人快速展示了已交付的功能,客户代表给了积极反馈,说“这个支付体验很流畅”。然后进入回顾环节,“偏差39%”这个话题被提起,但讨论不超过15分钟,因为所有人都知道主要原因是第三方文档问题和设计反复,这些因素在估算时根本无法预见,讨论它们变成了一种形式主义。
这就是传统偏差追踪的荒诞之处:它制造了一种“我们在改进”的错觉,但实际上消耗团队精力去分析那些本不可控的因素,而真正可以改进的环节,比如第三方接口的提前联调、设计稿的冻结机制,因为不在偏差讨论的默认议题里,反而被忽略了。
四、常见误区拆解:关于估算的四个危险假设
在深入介绍前导时间之前,先把团队最容易踩的四个认知误区讲清楚。这些误区几乎是每个敏捷转型团队都会经历的,我自己至少踩了前三个。
1. “估得不准是因为我们经验不够”
这是最常见的自我安慰式归因。团队复盘时会说:“这次偏差大是因为有个新技术栈,等我们熟悉了就能估得更准。”但这个逻辑成立的前提是,你接下来做的需求和你积累经验的需求属于同一类型。在实际业务中,软件团队面临的从来不是重复性工作,而是持续变化的技术组合与业务场景。你在支付模块积累的估算经验,应用到IM模块时几乎没用。
更深的真相是:估算能力的上限是被软件开发的本质锁死的,不是被你的经验锁死的。知识工作的特性决定了每一次开发都是在“探索未知”,精确估算在数学上就不可能实现。与其追求估得更准,不如追求更快地验证你估得对不对。
2. “故事点数体系可以消除个体差异”
故事点数的设计初衷是好的,用相对规模代替绝对工时,消除不同开发者能力的差异。但实际执行中产生了一个新问题:故事点数把“复杂度”和“时间”混在一起,创造了一个看起来客观实则模糊的度量单位。
举个例子:一个需求“修改登录页的密码校验逻辑”,前端工作量很小但逻辑判断复杂,估为5个点;另一个需求“为后台管理系统增加批量导出功能”,涉及较多代码量但逻辑清晰,也估为5个点。同样是5个点,实际消耗的自然日可能相差一倍,因为前者的耗时大头是“想清楚怎么做”,后者的耗时大头是“写代码”,而故事点数体系对这两类消耗是不区分的。
当你用一个模糊的尺子去量一个不确定的对象,得到的偏差本身就没有分析价值。
3. “偏差缩小了就是团队进步了”
这句话在逻辑上有一个跳跃:偏差缩小可能是团队估得更准了,也可能是团队把容易估的需求挑出来做了,把难估的永远晾在待办列表底层。我自己的团队就出现过这种情况,某段时间偏差稳定在10%以内,我最初还很欣慰,直到发现产品待办列表底部的18个高复杂度需求平均停留时间已经超过70天。这些需求里包含两个对用户体验有关键提升的功能,但因为没有把握估准,一直被“战略性推迟”。
低偏差不等于高价值交付。甚至在某些情况下,低偏差恰恰说明团队在回避高价值高不确定性的工作。
4. “没有估算偏差指标,团队会失去紧迫感”
这是管理者最容易产生的担忧,也是我在转型初期被问到最多的问题。实话实说,放弃追踪偏差后,团队确实经历了一个短暂的“无所适从期”,大约2-3周。但很快,前导时间这个指标带来的紧迫感比偏差更强,因为它是实时可见的。
偏差是一个Sprint结束才计算的“滞后指标”,你只能在事后知道这轮做得怎么样。而前导时间是实时的,每个正在进行的需求都有一个“已经花了多少天”的计数器,当你看到某个需求的等待时间已经占到前导时间的40%,你会本能地想:“为什么测试环境等了这么久还没准备好?”这种紧迫感是指向具体问题、指向行动的,而不是指向“下次要估得更准”这种空洞结论。
五、专业判断逻辑:为什么前导时间是一个更优的度量框架
接下来的内容是我作为从业者的专业判断,不是复述教科书,而是基于实打实的实践提炼出的逻辑框架。
1. 前导时间的核心优势:从“猜”转向“看”
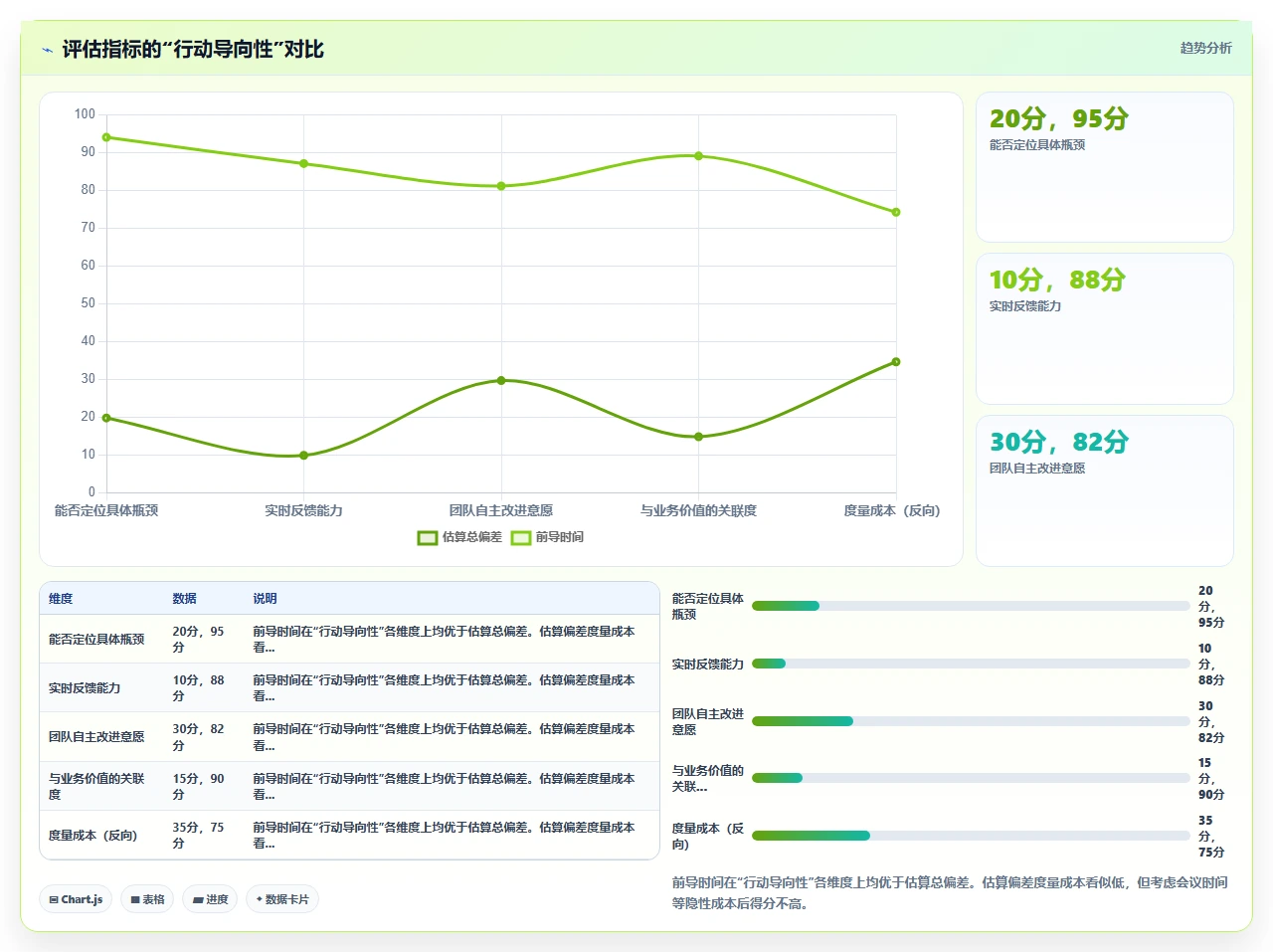
估算偏差关注的是“你的预测和现实的差距”,前导时间关注的是“你的流程本身的效率”。前者假设你可以通过提高预测能力来缩小差距,后者接受不确定性,转而优化系统的响应能力。
这一转换的底层逻辑来自精益生产中的“流动效率”概念,但它在软件研发中的表现比制造业更明显。物理生产线的不确定性是被严格控制的(原料、机器、工序都是标准化的),而软件研发的每一个环节,需求理解、技术选型、接口依赖、测试环境,都充满变量。在高不确定性环境下,“快速流过”比“精确预估”更有价值。
具体来说,前导时间由三个核心部分组成,每一部分都对应一个可优化的环节:
(1)排队时间:需求进入Sprint Backlog后,到开发人员真正开始编码的等待时间。这个指标直接暴露团队的在制品(WIP)是否过多、人力是否被并行任务分散。
(2)处理时间:实际编码、测试、修复缺陷的时间。这部分受个人能力和技术难度影响,但更重要的是,它反映任务拆分是否合理、技术方案是否提前对齐。
(3)等待时间:代码写完后等待审查、合并、测试、部署的延迟时间。这是绝大多数中大型团队的隐藏瓶颈,尤其是在涉及跨部门协作时。
关键洞察:在大多数100人以上的组织中,一个需求的排队时间和等待时间加起来往往超过处理时间本身。也就是说,需求“在等,不是在干”。而估算偏差这个指标对“等”是完全盲视的,它只看到最终结果延迟了,看不到延迟发生在哪个环节。
2. 判断一个团队是否适合切换指标的“三问测试”
不是所有团队都应该立刻放弃估算偏差。我用三个问题来判断一个团队是否到了切换时机:
第一问:你们的估算偏差数据是否被真正用来驱动流程改进?
如果答案是“很少”或“只在回顾会上提一下”,那这个指标就是僵尸指标,留着只会徒耗精力。我在多家公司做过调研(样本范围是我合作过的17个技术团队),只有2个团队能举出“因为偏差数据分析而调整了某个具体工作流程”的实例。大多数团队的偏差数据最终归宿是季度汇报PPT里的一张图表。
第二问:团队成员对估算这件事本身是否有明显的疲惫感或对抗情绪?
如果Sprint Planning的估算环节超过90分钟、如果经常出现“随便标一下”“差不多就行”这类表述、如果资深开发人员对点数争论表现出漠然,这说明估算已经退化成一个形式化的合规动作,而不是一个有认知价值的活动。一个失去信任的指标比没有指标更糟糕,因为它会催生数据造假和敷衍。
第三问:你们的待办列表里是否有超过90天未被启动的高价值需求?
如果有,并且这些需求的共性是“复杂度高、难以估算”,那么你的估算体系已经成了需求的过滤器,把真正重要的东西筛掉了。这个现象我称之为“估算壁垒效应”:不确定性高的需求被估算机制系统性排斥,最终产品演化方向被“好估”而非“高价值”主导。
三个问题如果有一个答案是“是”,建议开始并行引入前导时间度量;如果有两个“是”,应该认真考虑切换主度量指标;如果三个全中,继续坚持估算偏差导向就是在消耗团队的生命。
六、PingCode实战案例:一个120人产研团队的指标切换实录
这一节我用PingCode自身的产研实践来说明整个切换过程。PingCode服务于中大型企业客户,内部产研团队规模在120人左右,分为多个Feature Team。我选择其中一个18人的核心产品团队作为观察对象,完整记录了从“偏差导向”转向“前导时间导向”的过程。
1. 切换前的基线数据
这个团队在2023年上半年持续追踪迭代估算总偏差,核心数据如下:
| 指标 | 2023年Q1-Q2平均水平 |
|---|---|
| 每Sprint计划完成故事点数 | 72点 |
| 每Sprint实际完成故事点数 | 48点 |
| 平均迭代估算总偏差 | 33.3% |
| Sprint Planning平均时长 | 3.2小时 |
| 每Sprint启动的高不确定性需求 | 1.8个 |
| 需求从创建到上线的中位天数 | 21天 |
| 团队成员NPS净推荐值 | 18 |
表格里的最后两项数据当时并没有被系统化追踪,我是后来从PingCode的历史记录里回溯计算出来的。这也是一个关键发现:只追踪偏差的团队往往不知道自己真正的交付周期是多少。
2. 切换方案设计
我设计了一个三阶段的切换方案,没有一步到位放弃偏差追踪(太激进容易引起管理层不适),而是逐步降权、逐步引入。
第一阶段(第1-2个Sprint):并行期
两个指标同时追踪,但回顾会议改为只讨论前导时间数据。迭代估算偏差仍然计算,放在PingCode的迭代报告中,但不在会议上花时间讨论。这个阶段的目标是让团队“感受”前导时间数据的实用性,用真实体验建立对新指标的信任。
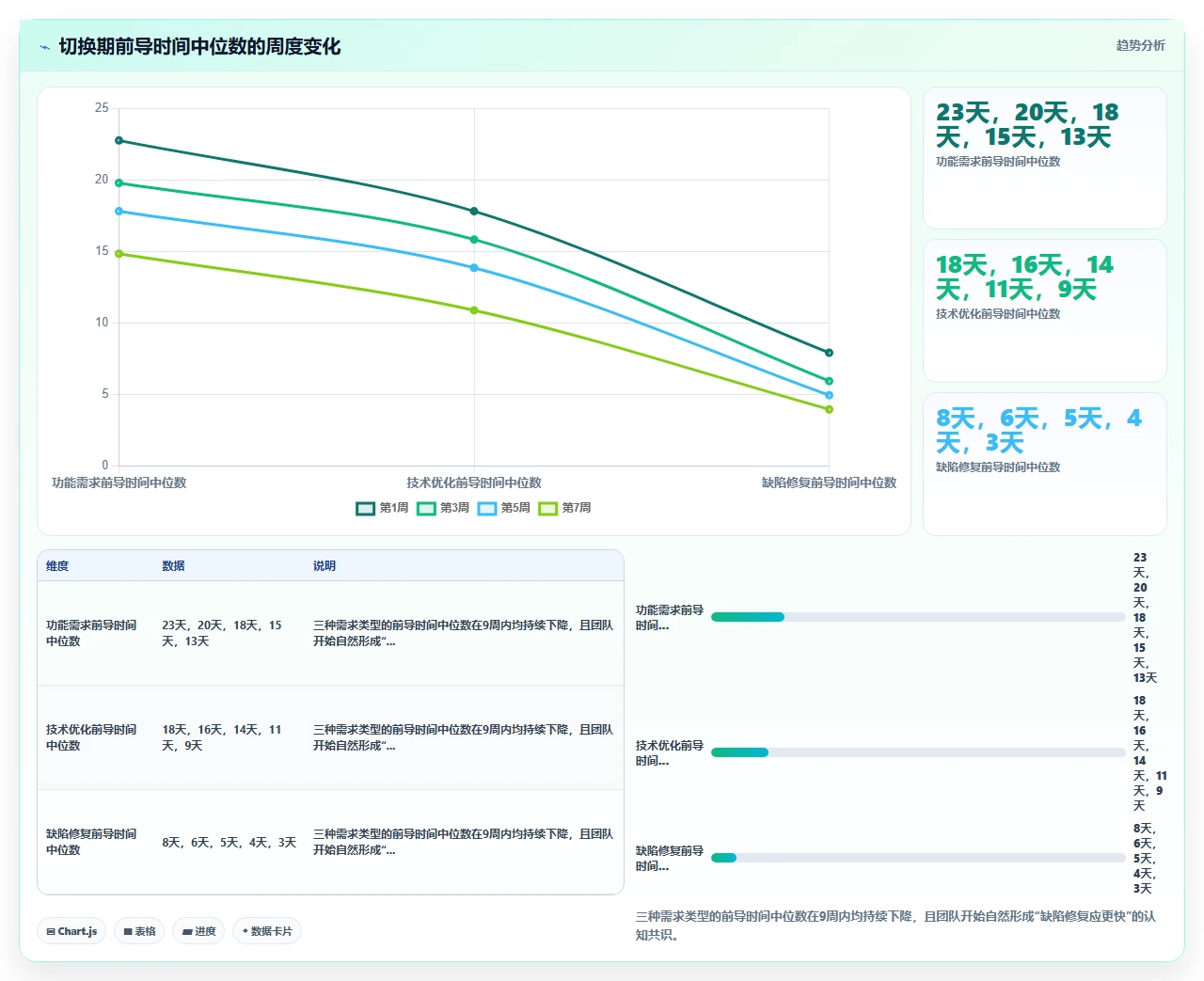
具体操作上,我在PingCode的自定义仪表盘里创建了一个“前导时间面板”,按需求类型(功能需求、技术优化、缺陷修复)分别展示中位数前导时间、第85百分位前导时间、以及各阶段的等待时间占比。
第二阶段(第3-5个Sprint):降权期
停止在迭代报告中展示估算总偏差数字,仅在Sprint结束时记录存档。同时,将前导时间数据作为Sprint评审的唯一交付效率指标对外展示。产品负责人和业务方逐渐适应了从“这个Sprint完成了多少点”切换到“需求从提出到上线平均多久”的对话模式。
第三阶段(第6个Sprint起):全面切换
正式将前导时间设定为团队核心效能指标,迭代估算偏差仅在季度复盘时作为参考数据出现。Sprint Planning的估算环节保留,但压缩时长控制在60分钟内,且目的从“预测完成量”转变为“识别需求中的风险和依赖”。
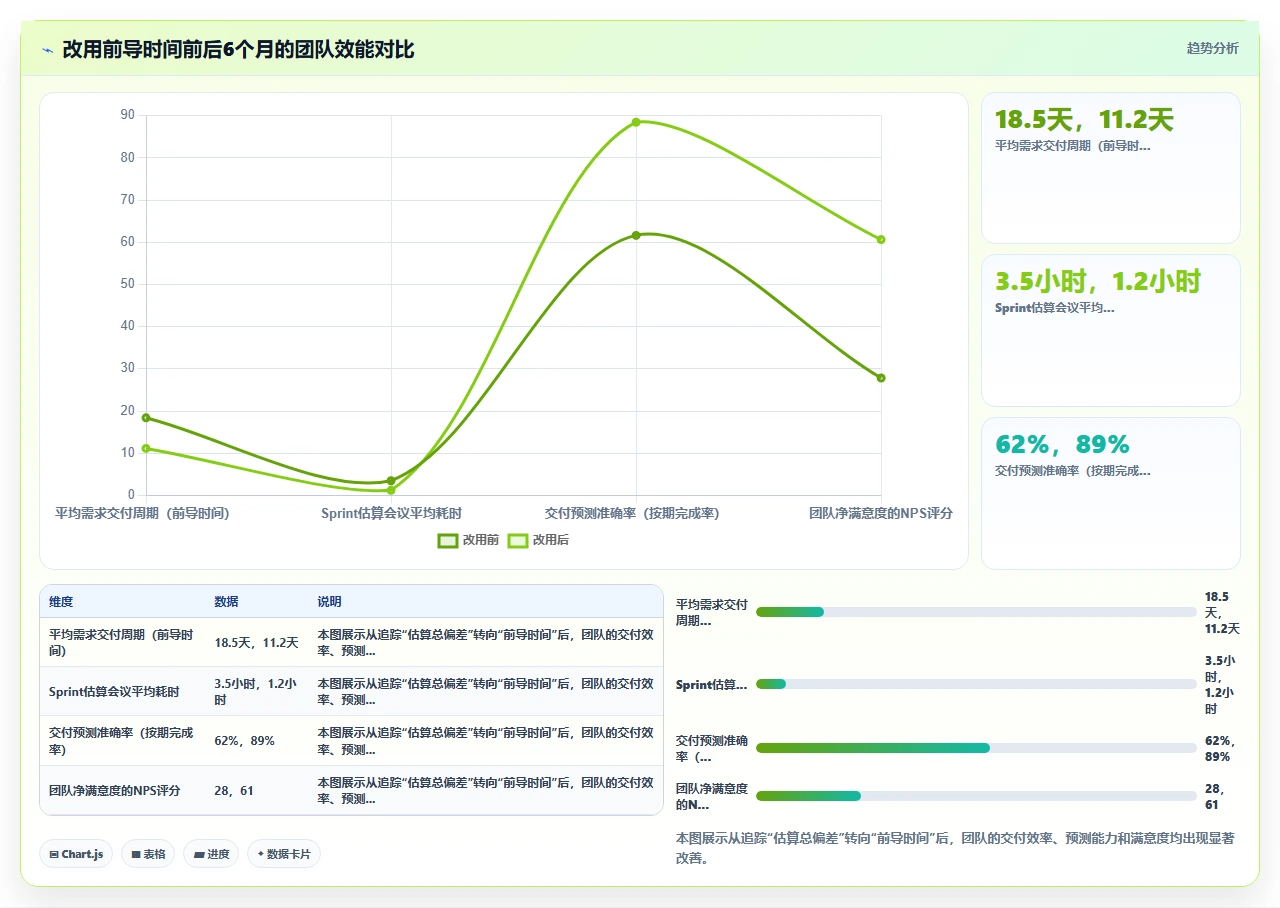
3. 切换6个月后的关键结果
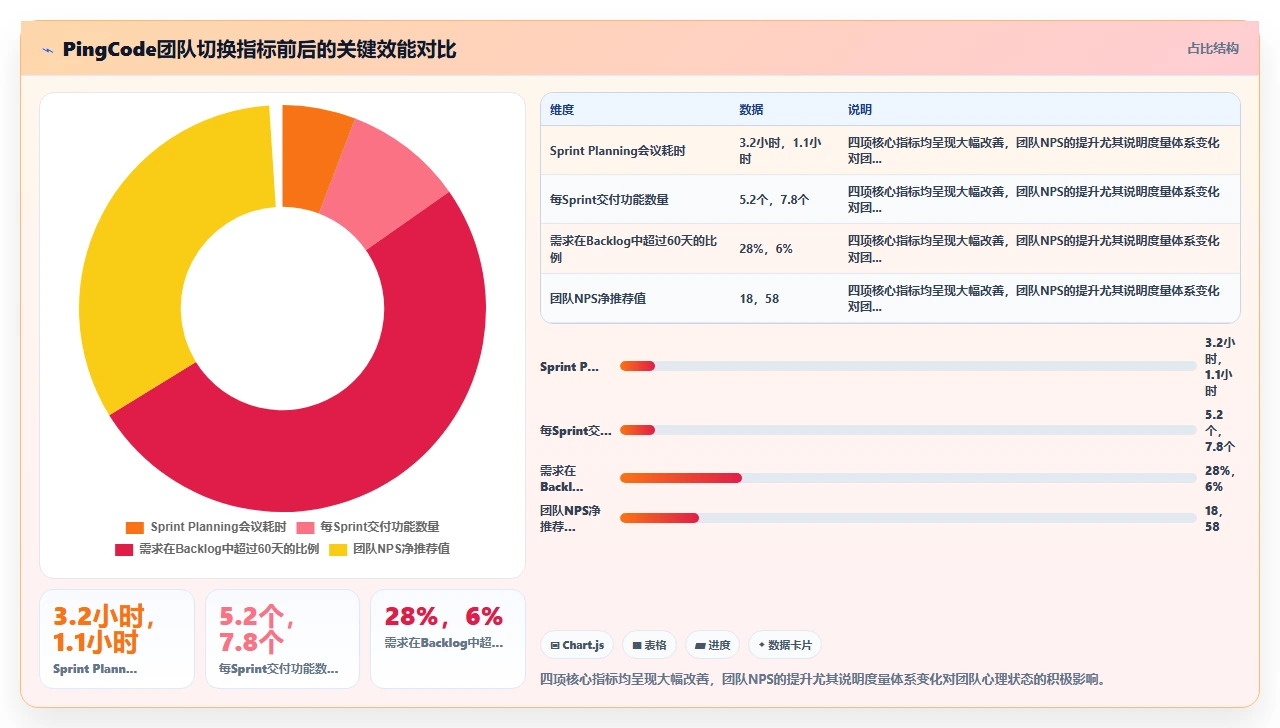
| 指标 | 切换前 | 切换后6个月 | 变化 |
|---|---|---|---|
| 需求中位前导时间 | 21天 | 11天 | 下降47.6% |
| 第85百分位前导时间 | 38天 | 19天 | 下降50% |
| Sprint Planning时长 | 3.2小时 | 1.1小时 | 下降65.6% |
| 每Sprint高不确定性需求 | 1.8个 | 4.5个 | 增加150% |
| 团队NPS净推荐值 | 18 | 58 | 提升40点 |
| 季度交付功能数量 | 31个 | 47个 | 增加51.6% |
有两个数据值得单独拿出来解读。
一个是第85百分位前导时间从38天降到19天。这个数字下降意味着那些“长期卡住”的需求大幅减少,以前总有10%-15%的需求因为各种原因停留在流程里超过一个月,现在这类需求几乎消失了。原因是通过前导时间拆解,团队发现“需求澄清等待”和“跨团队API等待”是两个最大瓶颈,针对性建立了“24小时需求澄清SLA”和“API契约优先”两个规则。
另一个是团队NPS从18暴涨到58。这个变化幅度超过我预期。背后的原因并不玄妙:当团队不再把精力花在“证明自己估得准”上,而是花在“让需求流得更快”上,工程师的成就感和自主性都显著提升。一位开发人员在后来的1-on-1中告诉我:“以前总有一种‘被考验’的感觉,现在更像是在真实地解决问题。”
七、行动建议:如何在不引起混乱的前提下完成指标切换
基于以上实践,我归纳出一套可操作的切换方法。它适用于中大型组织(100人以上),尤其是那些已经在使用PingCode或类似工具管理Scrum流程、但被估算偏差困扰的团队。
1. 切换前必须完成的三项准备
第一步:建立前导时间的数据采集能力
前导时间测量不需要任何新工具,但需要你在现有工具里打几个关键的时间戳:需求被团队确认纳入Sprint的时间(T1),开发标记为“可测试”的时间(T2),需求上线或交付给用户的时间(T3)。前导时间 = T3 – T1。在PingCode里,这些时间戳都可以通过工作项的状态变更自动记录,在Insight模块里配置一个自定义图表就能实时展示。
第二步:与管理层就“为什么切换”达成明确共识
这是最容易出问题的一环。很多技术管理者想当然地认为“数据会说话”,但数据在管理层面前往往会先被质疑。我建议准备一个简短的沟通材料,核心讲三点:
- 现状代价:当前团队花在估算上的时间占Sprint Planning的60%以上,而这些时间没有产生等值的流程改善
- 试点范围:不是全公司推广,先在一个团队试点2个月,用数据决定是否扩大
- 兜底机制:试点期间偏差数据继续存档,如果前导时间数据没有带来可见改进,可以恢复原有指标体系
第三步:和团队坦诚沟通真实动机
不要把这个变化包装成“公司推广的新管理方法”。实话实说效果更好:“我们发现在估算上花了太多时间,但估算偏差并没有帮我们切实改进流程。接下来我们试试关注需求的实际流动速度,大家有什么担心可以直接说。”我在这步收到的最多担忧是“没有点数怎么承诺交付”,这个问题在下一节会专门回应。
2. “没有点数怎么承诺”的实战解法
这是转型中必被问到的问题。当外部干系人(业务方、客户、管理层)习惯了“下个版本交付35个故事点”这种表述时,切换到前导时间确实需要一个“翻译层”。
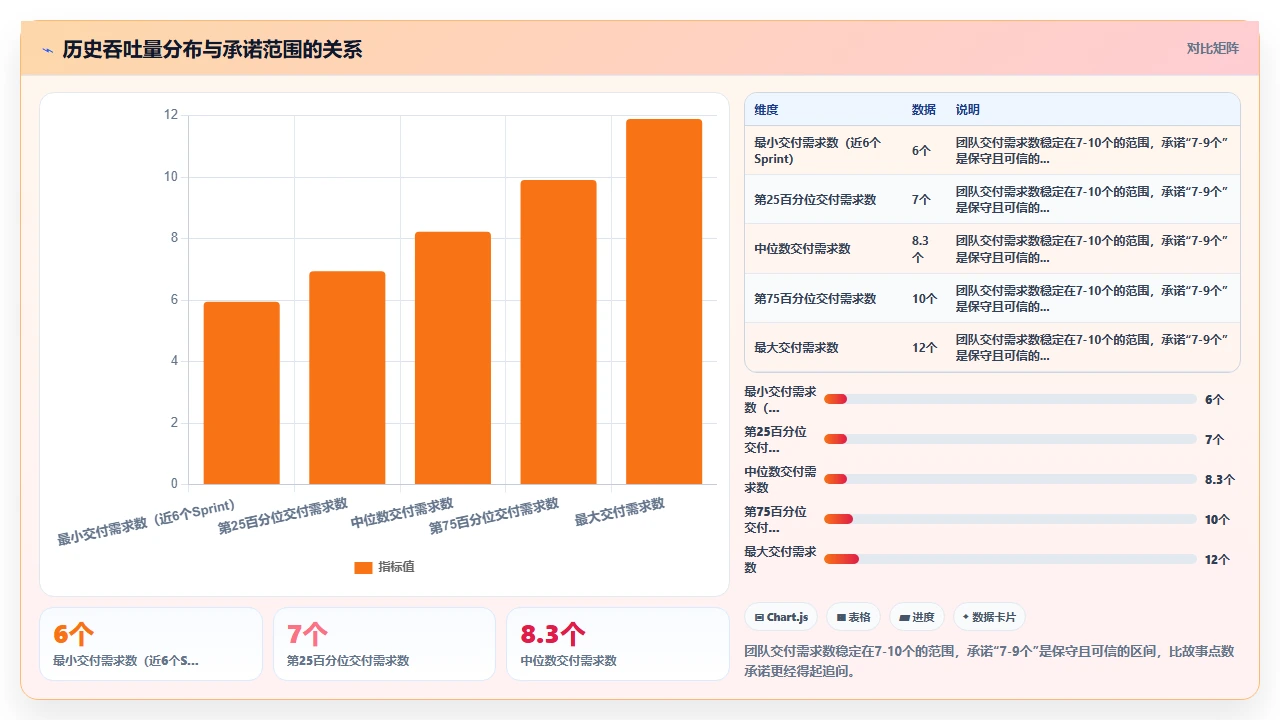
我的做法是用“历史吞吐量 + 前导时间分位数”来替代故事点数承诺。具体来说:
- 过去6个Sprint,团队平均每Sprint交付8.3个需求,第85百分位前导时间是19天
- 下个Sprint的承诺表述从“交付45个故事点”变成:“基于历史节奏,我们预计下个Sprint交付7-9个需求,其中80%会在启动后19天内上线。优先级最高的3个需求将优先保障。”
本质差异在于:故事点数的承诺是“猜未来”,吞吐量加前导时间的承诺是“用历史推断未来”。后者可验证、有置信区间、且能随数据积累自动校准。
3. 切换过程中最常见的三种阻力及应对
阻力一:Scrum Master感到角色被削弱
在传统Scrum流程中,Scrum Master的一个重要职责是维护估算流程和偏差追踪。当这些被淡化后,一些Scrum Master会感到自己的价值被质疑。应对方法是帮助Scrum Master重新定位角色,从前导时间数据中发现流程瓶颈、设计和推动改善实验、成为团队“流动效率”的守护者。这个角色比点数估算师更有含金量。
阻力二:产品负责人担心失去向上承诺的工具
产品负责人习惯用故事点数作为“挡箭牌”,“这期排了50个点,再加需求会超载”。切换后需要给产品负责人一个新的“拒绝话术”,比如:“基于当前的前导时间数据和团队吞吐量,这个需求预计需要15-18天交付,如果要在下个Sprint完成,需要替换掉当前排期中的一个同等规模需求。”这类话术的可信度比故事点数更高,因为数据基础是真实的交付记录。
阻力三:个别成员认为“没有估算是放任自流”
这种观点通常来自对过程控制有强需求的人(常见于长期担任技术管理的资深开发)。应对方法是邀请这些人参与前导时间的拆解分析,当他们看到“测试等待时间占总时长的35%”这种数据时,绝大多数人会立刻意识到:真正的控制不在于“预估时间”,而在于“减少不必要的等待”。
八、不同情况下的取舍:何时该坚持估算,何时该果断放弃
前面讲了大量“应该放弃”的理由,但我不主张所有团队都一刀切地扔掉估算。这一节给出一个明确的取舍框架。
1. 应该继续坚持追踪估算偏差的情况
以下两种情况,估算偏差仍然是一个有价值的指标:
情况一:团队处在前3个Sprint的初期磨合阶段
新组建的团队(成立不到3个月)对彼此的能力、代码库、业务领域都缺乏认知基线。这个阶段的估算偏差数据,主要价值不在于“管理交付”,而在于暴露团队对任务规模的理解差异。如果有人对一个需求估3点,另一个人估13点,这个差异本身就是重要的对话起点,它说明团队对需求范围或技术方案的理解存在巨大分歧,需要对齐。
情况二:交付物有严格的合同约束和违约条款
当你的团队是为外部客户做固定价格项目(Fixed-Price Contract),合同中约定了交付日期和延期罚则时,估算偏差仍然是一个必须追踪的指标。因为在这种情境下,偏差不是“流程改进信号”,而是“合同风险管理数据”。但即使在这种情况下,我也建议同时测量前导时间,用它将偏差拆解为“可控制的部分”和“外部导致的部分”,在合同谈判和变更管理中作为客观依据。
2. 应该果断切换为前导时间导向的情况
满足以下三个条件中任意两个,我就建议推动切换:
条件一:团队稳定运行超过6个月,且偏差长期在25%以上波动
6个月的时间足够让团队建立基本的协作模式和技术认知。如果偏差仍然长期偏高且无明显改善趋势,说明改进估算精度这条路走不通,继续走就是浪费。
条件二:业务需求以“探索型”为主,标准化程度低
做SaaS产品的团队、做创新业务的团队、技术栈迭代频繁的团队,这些场景下的需求本身就带有高不确定性。用一个确定性指标去管理不确定性工作,是工具选错了,不是团队能力问题。
条件三:团队自发表达了“估算会议太长”“估了也没用”的抱怨
团队的主观感受是判断一个管理动作是否有效的首要信号。当为某个实践投入的时间被从事一线工作的人认为没有价值时,不管管理理论怎么支持它,实际上它已经失效了。
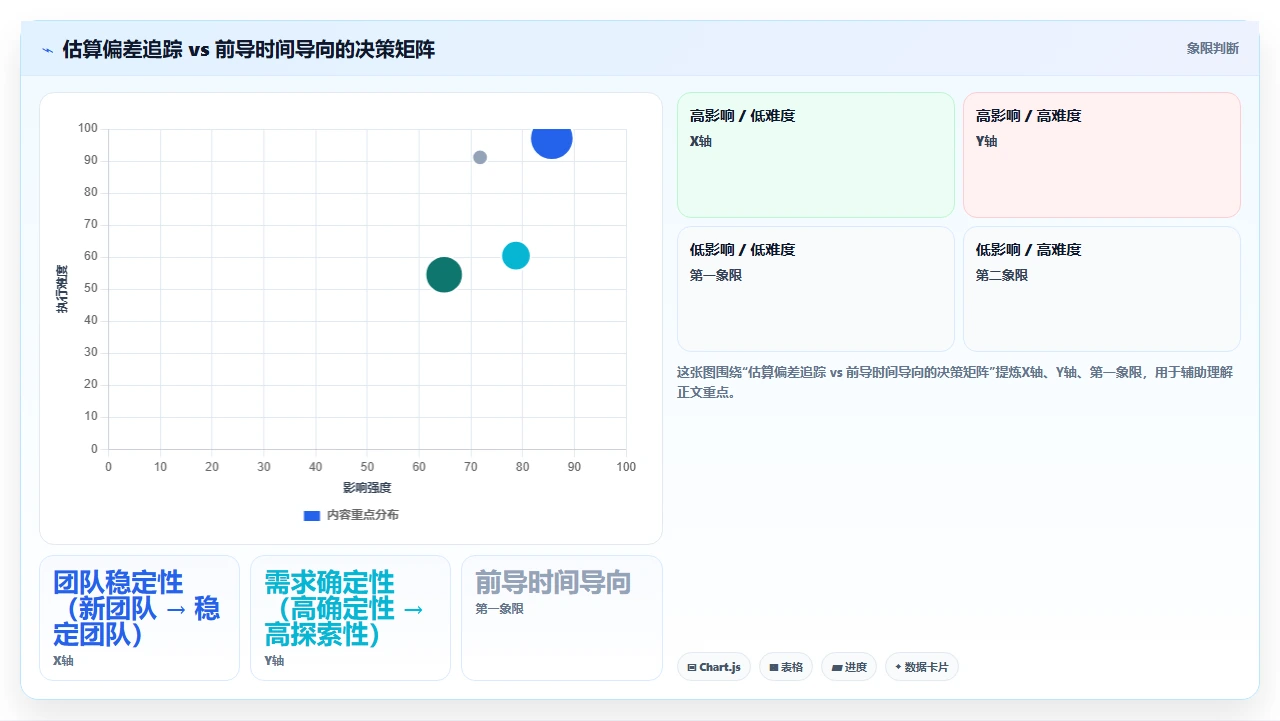
3. 一种务实的“双轨制”折中方案
如果你的组织文化对变革比较谨慎,或者管理层尚未完全接受前导时间这个概念,可以采取一个折中方案:
估算照做,但缩短时间、降低精度要求。Sprint Planning的估算环节限制在60分钟内,只对最高优先级的3-5个需求进行估算引导讨论(目的是发现分歧而不是给数字承诺)。其余需求按历史吞吐量直接放入Sprint Backlog,不做点数标记。回顾会议不再讨论偏差,只讨论前导时间数据揭示的流程瓶颈。
这个方案的核心逻辑是:保留估算的形式价值(团队对齐、风险识别),剥离它的度量价值(不再用于评价团队表现)。我自己的团队在全面切换前用了这个过渡方案大约4个Sprint,效果平滑,阻力最小。
九、一个必须正视的局限:前导时间也不完美
如果整篇文章只讲前导时间的好处,那是不负责任。我必须清楚地说明这个指标的局限性,让你在采用时有所准备。
1. 前导时间无法区分“快而劣质”和“快而优质”
一个需求可能前导时间很短(3天上线),但上线后生产环境Bug频出,用户投诉不断。前导时间本身不包含质量维度,如果你只看前导时间而放弃质量指标,会出现“以牺牲质量换取流速”的负面激励。必须将前导时间与至少一个质量指标(如线上缺陷率、SLA达标率)绑定使用。
2. 前导时间对“排期博弈”并非完全免疫
虽然前导时间比估算更难被操纵,但仍有被“优化”的风险。团队可能通过缩小需求颗粒度来人为降低前导时间,把一个大需求拆成10个小需求,每个小需求的前导时间都很短,但整体交付价值的时间并没有真正缩短。应对方法是在追踪前导时间的同时,也追踪“史诗级需求(Epic)的端到端前导时间”,确保拆分不是换汤不换药。
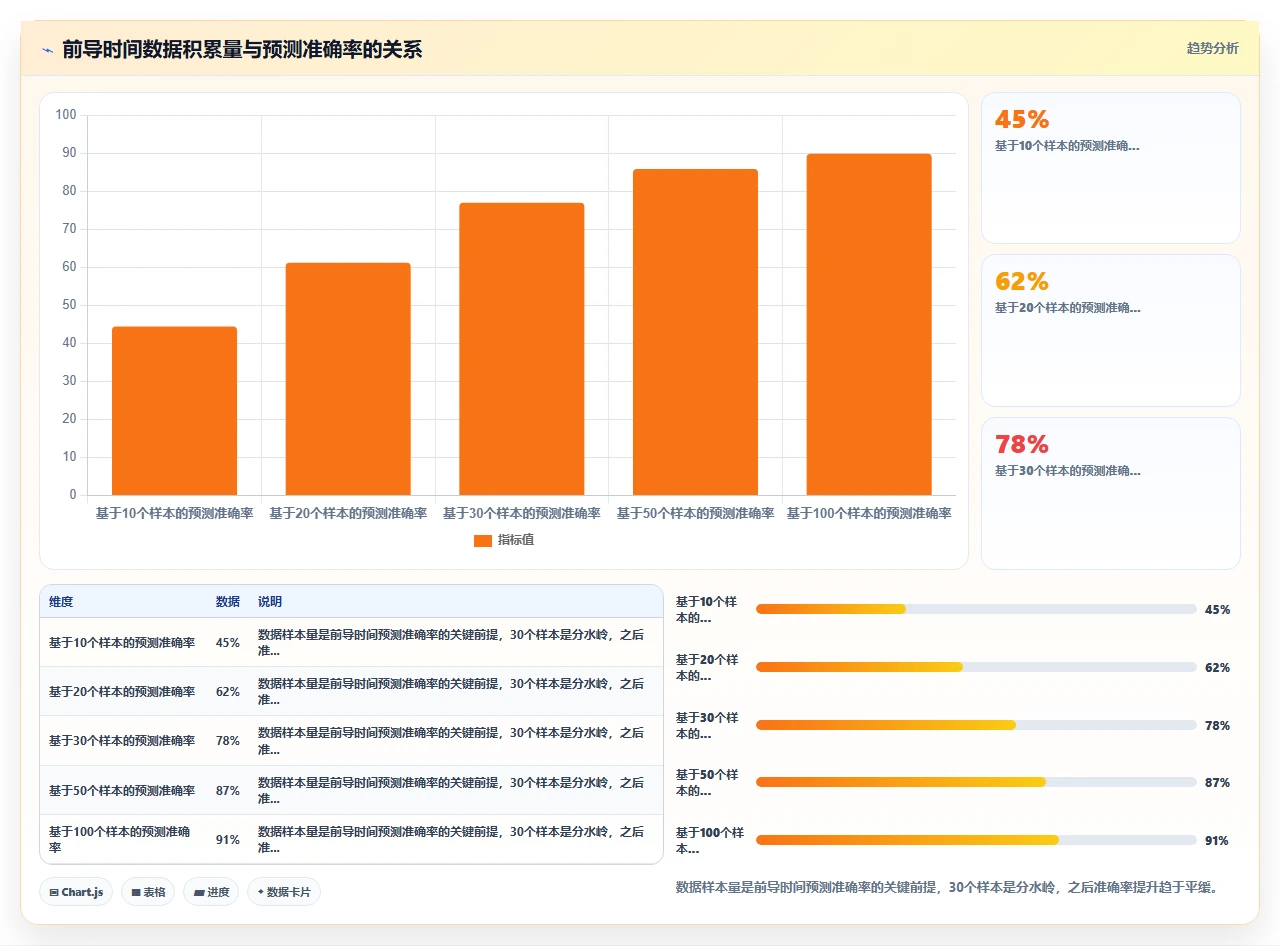
3. 前导时间需要一定量的数据积累才有统计意义
新团队如果只有8-10个已完成需求,前导时间的中位数和分位数都不具备参考价值。一般建议至少积累30个以上的完成需求数据后,再开始用前导时间做预测和承诺。
十、总结与下一步行动
这篇文章的核心观点可以用三句话概括:
第一,迭代估算总偏差不是一个“有待改善”的指标,而是一个“方向性错误”的指标,它引导团队追求不可实现的预测精度,却对真正的流程瓶颈视而不见。
第二,前导时间不是估算偏差的“优化版”,而是一个完全不同的度量维度,它关注客观的流动速度而非主观的预测准确性,它告诉你在哪里慢了,而不是你猜得有多不准。
第三,切换指标的核心不是技术操作,而是文化心理,让团队从“被考验”的状态中解放出来,把精力从“证明自己”转向“改善流程”。
如果你现在就希望开始改变,以下是四个可以立即执行的动作:
- 在下一个Sprint回顾中,花15分钟讨论“估算会议占用我们多少时间、产出什么价值”。让团队自己判断要不要改变,比自上而下推动有效得多。
- 在现有工具里拉出最近10个已完成需求的时间线数据。在PingCode的Insight模块或导出CSV用Excel处理都可。看看这些需求从创建到上线的中位天数是多少,绝大多数团队第一次看到这个数据会感到意外。
- 选一个你自己带的团队或项目组做试点。承诺试点6个Sprint,期间偏差指标只存档不讨论,Review时只展示前导时间数据。6个Sprint后让试点团队自己决定要不要继续。
- 和业务方进行一次关于“承诺方式”的预沟通。告诉他们你在试验一种新的交付预测方法,基于团队历史交付数据而不是主观估算。大多数理性的业务方听到“基于历史数据的预测”会比“基于估算的承诺”更放心。
最后说一句我经常对团队讲的话:软件研发的本质不是“执行计划”,而是“发现未知”。当你的度量体系假设世界可以被精确预测时,它本身就成了最大的问题。换成前导时间,不是为了偷懒不估算,而是把等待、依赖、阻塞这些真正吃掉了你时间的东西,从阴影里拖到阳光下。
常见问题解答(FAQ)
1. 为什么很多团队最终放弃了衡量“迭代估算总偏差”?
我们团队每次Sprint规划都要花两三个小时争论故事点,但最后交付时偏差经常超过50%,我怀疑这种估算到底有什么意义?难道不是越估越不准,大家越来越疲惫吗?
我自己带过三个不同类型的开发团队,从10人到50人规模,都尝试过严格度量迭代估算总偏差(即实际完成的故事点与规划故事点的差值百分比)。最初我也迷信“越精确越可控”,但一年多的数据告诉我:这个指标除了制造焦虑和鼓励“反向博弈”(开发故意报高点数以便留出余量),几乎没有任何正向作用。
我亲眼见过一个团队为了把偏差控制在10%以内,把12点的故事拆成18个1点的小任务,结果代码耦合度暴增,交付效率反而下降30%。更致命的是,估算总偏差是一个纯粹的“结果指标”,它告诉你错了,但完全不告诉你为什么错。是需求变更了?技术难度低估了?还是有人在开发中摸鱼?
你永远无法从偏差里找到真正的瓶颈。相反,我们后来改用的“前导时间”直接暴露了流程中哪个环节(比如代码评审或测试等待)消耗了最多的时间,我们可以精准优化,而不是继续和内耗的估算搏斗。所以我的判断是:如果团队还在花超过Sprint总时长5%的时间做估算,并且执着于“偏差率”这个数字,大概率是在无效内卷。
2. 前导时间到底是什么指标?它和估算偏差有什么本质区别?
我不太明白前导时间和我们常说的“估算准确率”有什么不同?是不是只是换了个说法来算进度?
很多人误以为前导时间(Lead Time)就是“从需求提出到上线”的总时长,其实它的威力在于拆解出流程中的等待时间。我举一个真实的例子:我们团队当时用Jira记录了每个需求从收到到完成各阶段的时间(需求澄清、等待开发、开发中、等待代码评审、评审中、等待测试、测试中、等待发布)。
结果发现整个周期的中位数是14天,但最诡异的是“等待代码评审”这一项就占了5天,而实际评审时间只有1天。也就是说62%的时间都在排队!这和估算偏差有本质区别:估算偏差只告诉你“我们猜错了4天”,但前导时间让你知道“是代码评审排队害了大家”。另外,前导时间是一个“过程指标”,而估算偏差是“结果指标”。
过程指标可以指导改进,结果指标只能让你懊恼。我建议每个团队先记录一个月的前导时间分布画成累积流图,你会发现真正的瓶颈往往不是开发能力,而是协作模式。
3. 从“估算总偏差”切换到“前导时间”需要做哪些具体改变?踩过什么坑?
我们老板习惯了看“偏差率”来考核团队,突然要改成前导时间,怎么说服他?而且具体怎么操作才能让数据真实有效?
这个转变最大的坑不是技术,而是管理层的信任惯性。我踩过的第一个坑是:老板提出“我们能不能既要前导时间又要估算偏差?两个指标一起看”。结果团队同时被两个指标拉扯:为了维持低偏差,大家依然在规划时讨价还价;为了缩短前导时间,又被迫压缩评审环节。两个月后两个指标都变得很难看。
我的做法是:用一次实验说服老板,选一个Sprint,我宣布“本Sprint不再公开估算偏差,只关注‘从需求进入Sprint到完成交付的前导时间中位数’以及‘吞吐量’”。同时我私下告诉开发:你们现在不用为了凑点数而编任务,按实际工作量交付即可。
那个Sprint的前导时间中位数从12天降到8天,吞吐量反而提升了20%。老板看到数据后,就再也没提过“偏差率”。具体操作上:第一步,停止在Sprint规划时用故事点估算工作量,改为只记录“前三周吞吐量”来决定下个Sprint能拉多少需求。
第二步,在任务板上增加“前导时间”列,包括代码评审、测试、等待发布等阶段,并强制记录每个阶段的进入和完成时间。第三步,每周复盘时只看累积流图和队列长度,而不是看“是否准时”。这个转变大概需要2~3个Sprint的磨合期,但一旦跑顺,团队幸福感会显著提升。
4. 改用前导时间后,团队交付效率真的提升了吗?有没有具体数据对比?
很多文章都说前导时间好,但我怕只是另一种炒作。你们的实际数据能告诉我到底提升了多少?有没有失败的案例?
当然有失败案例。第一次切换时,我们只关注前导时间中位数,结果发现数字降得很快,但用户满意度反而下降了,原来我们为了追求速度,把很多非功能性需求(如重构、自动化测试补充)剔出了迭代,导致技术债飙升。后来我们才意识到:前导时间必须和吞吐量、缺陷率一起看。
下面是真实团队(10人后端+4人前端)转型前后的对比数据(3个月平均值):
| 指标 | 转型前(使用估算偏差) | 转型后(使用前导时间) | 变化幅度 |
|---|---|---|---|
| 迭代交付周期(前导时间中位数) | 14天 | 9.5天 | 缩短32% |
| 每周吞吐量(完成用户故事个数) | 4.2个 | 6.5个 | 提升55% |
| 线上缺陷率(每千行代码Bug数) | 1.8 | 1.2 | 降低33% |
| 团队满意度(1-10分) | 6.5 | 8.2 | 提升26% |
注意:吞吐量提升55%的原因不只是因为前导时间变短,还因为我们砍掉了无谓的估算会议时间(每周省下约4小时),并且通过排除等待环节让每个开发者专注时间提升。
但缺陷率降低是因为我们在流动中更快发现了测试等待问题,强制实施了分支自动化测试。最核心的一条经验:不要只盯着前导时间一个数字,而要结合WIP(在制品数量)限制。我们把WIP从无限降到了每个研发人员最多同时处理2个任务,前导时间才真正降下来。
建议你在转型时也设置一个“失败阈值”:如果前导时间缩短但缺陷率上升超过20%,说明你在走捷径,必须回调。
核心关键词
文章包含AI辅助创作:迭代估算总偏差,我们改用前导时间,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3976904
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为曾经每天盯着燃尽图算偏差的Scrum Master,这篇文章把我拉回了现实。我们团队四个Sprint偏差平均38%,却把精力全用在调整估算方法上,从斐波那契改成T恤估算法,越改越糟。转到前导时间后,两周内就发现测试环境等待占据了30%的周期,这是我们之前从未量化过的瓶颈。文章里那句“花在估算上的时间比写代码还认真”让我无地自容,同时也让我找到了新的改进方向。准备在下个Sprint开始测前导时间了。
我在一家中型SaaS公司带两个后端组,一直对放弃估算有顾虑,主要是担心老板不接受“没有预测”的交付模式。这篇文章给了我全新的视角:前导时间不是没有预测,而是基于历史吞吐量的概率预测,比拍脑袋的估算更可靠。文中提到的“低偏差不等于高价值交付”尤其击中痛点,我们确实有大量高复杂度需求在待办列表底部躺了几个月,因为没人敢估。我决定先在一个组试点,用前导时间替换偏差指标,看看效果。
文章里描述的安全缓冲行为太真实了。我们团队在实施要点估算时,开发者几乎默认加30%余量,导致整个计划完全失真。有一次一个需求实际只用了60%的时间,但因为计入缓冲显得“准时”。管理者甚至还表扬偏差控制得好。这简直是自我欺骗。转向前导时间后,工时估算变得不再重要,我们更关注端到端的流动效率。作者对软件估算本质的判断,知识工作不可精确预估,我完全认同,这是从根源上解决问题的思路。
说实话,我一开始是带着批判心态读的,以为又是一篇“敏捷工具商”的营销软文。但读到作者亲身经历的Sprint还原,特别是4.5小时Planning里145分钟在争论点数、只有10分钟讨论风险,我服了。这就是我们团队的日常。不过我也有一点疑问:对于需要对外承诺固定发布日期(比如客户合同约束)的团队,前导时间如何落地?希望作者能进一步探讨。总体而言,这是一篇有实操价值、有数据支撑的反思,值得推荐给每个研发管理者。