信息收集(Information Gathering),信息收集是指通过各种方式获取所需要的信息。信息收集是信息得以利用的名列前茅步,也是关键的一步。信息收集工作的好坏,直接关系到整个信息管理工作的质量。
在实战中,前期的信息收集的完整性,很大一部分决定了在对网站进行的测试的成功几率,能够收集的越多,对我们的帮助也是极其重要的。
一、CMS识别
在网站搭建的时候,很多网站往往为了方便会通过各类网站搭建平台,直接利用其中的源码直接进行搭建,但往往可能因为源码的开源而导致漏洞的产生,网上也有各类CMS的漏洞的披露,可以通过这些漏洞的利用,从而成功实现攻击。
CMS识别在线网站:(1)https://scan.较好15.cn/web/ (2)http://whatweb.bugscaner.com/look/
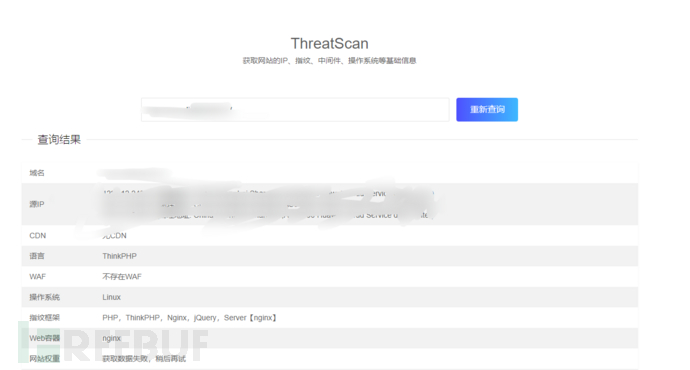
识别为thinkphp我们就通过搜索,对已披露的漏洞进行测试
但网上已披露的网站可能都已经被修复了,我们怎么去获取源码呢
可以通过网站源码平台进行源码的载或者通过github看是否有无进行源码的开放
网站源码平台:http://down.chinaz.com/ 当然还有很多可以自行搜索查找
github平台:https://www.githubs.cn/ 对thinkphp查询是否有没有源码的公开
架构信息获取
站点搭建分析
二、对网站搭建进行收集
在网站搭建的时候,往往不会只有一个页面,在不同的页面,可能存在不同的CMS或者可能相对于主页面有着较脆弱的防护,我们可以利用对其他页面的渗透从而拿下主站的权限,简单来说就是获取多个目标,而不是单单利用一个站点进行测试。
1.子域名收集
子域名指二级域名,二级域名是拔尖域名的下一级。
例如:http://xxx.com是个拔尖域名,http://xxx.xxx.com就是它的子域名
对子域名的收集我们可以通过在线平台或者工具进行爬取获取
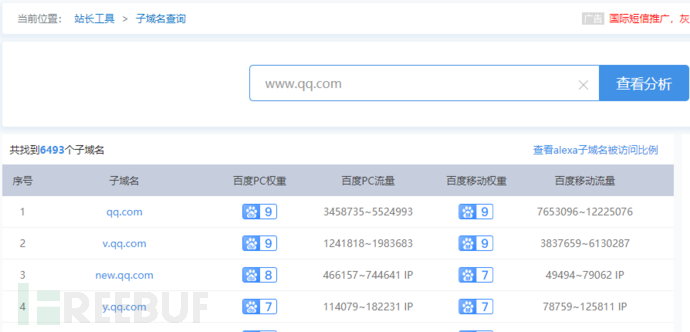
利用Layer子域名挖掘机进行爬取
2.端口扫描
在一个网站中可能存在同个网址,但是通过端口的不同,所显示的页面也不同。
例如:www.xxx.com:80和www.xxx.com:8080 虽然网站的网址相同,但所呈现出来的界面完全不同。

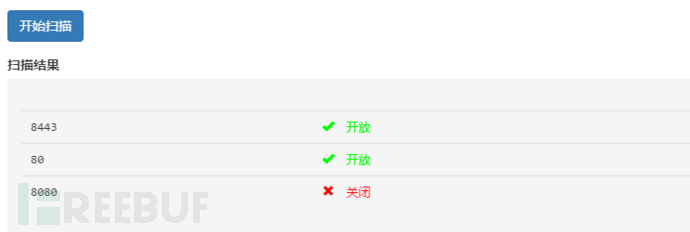
扫描出端口开放的同时,我们也可以利用相对应的端口进行攻击
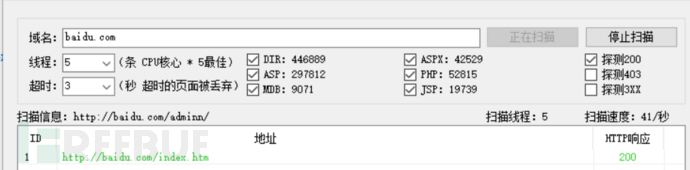
3.网站目录收集
在不同目录的网页,可能存在后台登陆页面或者有与数据库交互的地方,我们也可以利用这些页面进行测试。
我们可以利用工具直接进行扫描目录
工具御剑后台扫描,webpathbrute对目标网站进行目录爬取
4.旁站查询
旁站简单来说就是同服务器上的不同站点,在一个服务器上可能搭建了多个网站,我们可以选择利用其中一个安全防护较薄弱的网站进行渗透。
在线旁站查询:http://stool.chinaz.com/same
5.C段查询
C段简单来说就是不同服务器上的不同站点,网站搭建用不同的服务器搭建不同的站点,但都属于同一个站点,我们可以攻击其中一个网站,通过内网渗透从而获取其他网站的权限。
在线C段查询:https://chapangzhan.com/
6.类似站点
在网站使用中,可能或进行网站的迁移或者可能有一些违法网站为了不被抓到,会多个或更换网址,但都只是细微上的区别
比如:www.xxx.com可以就会变成www.xxx.cn或者www.xxx01.com等等之类
这类我不太清楚有没有什么平台或者工具可以实现,但可以作为日常信息收集的一种手段。
类似域名站点 .org .com .cn .net
7.搭建软件特征站点
在网站搭建为了方便,使用集成搭建平台比如phpstudy,宝塔等进行搭建,通常会有特征化的信息,可以对其判断是否利用了搭建软件进行搭建,一旦知道了搭建软件,我们就可以通过搜索搭建软件的漏洞,对其测试,从而拿下权限。
如我利用本地phpstudy搭建一个网站 通过审查元素的network进行抓包查看数据包的信息
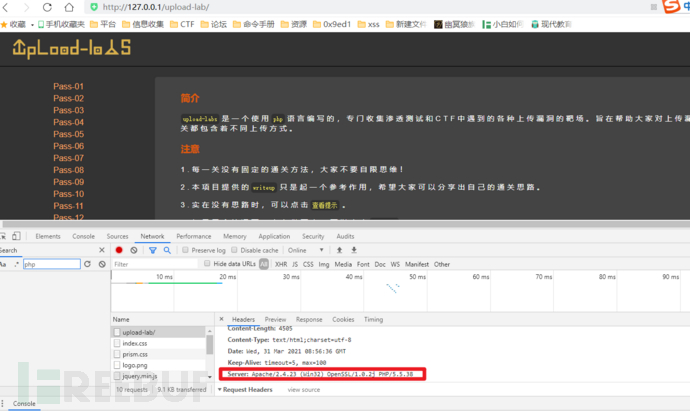
我们可以发现含有
Server:Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.5.38 这就是明显的利用了集成搭建 如果是没有使用的话 通常不会有完整的信息 比如就Server:Apache
具体的server的样式需要自己搭建才能知道。
一旦确定了我们就可以直接利用网上披露的漏洞直接进行利用
8.判断操作系统
最简单的判断方法就是大写 windows对大小写不敏感,而linux对大小写敏感
比如:网址为www.xxx.com/1.php 我们修改为www.xxx.com/1.PHp 能够访问为windows系统 不能够访问为linux系统
三、CDN绕过寻找真实IP
首先认识CDN是什么,CDN的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
1.如何判断CDN是否存在
利用多节点技术进行请求返回判断:超级ping 借助各地进行ping检测 出现多个IP地址 可以判断存在CDN 出现单一IP地址 可以判断没有CDN 例:对www.baidu.com进行超级ping检测 发现有两个不同的ip的地址 可以判断出存在CDN防护
2.怎么绕过CDN
1.子域名查询
利用原理:网站为了节约只对访问量大的域名进行CDN防护,子域名没有设置CDN防护
(1)去除www
去除www之后进行ping检测 原理:当进入xxx.com之后会自动跳转www.xxx.com没有对xxx.com进行CDN防护 例如 通过www.xxx.com进行ping检测 发现出现多个IP地址
但通过 xxx.com进行ping检测 发现IP地址少数
(2)通过子域名扫描 对子域名进行ping检测

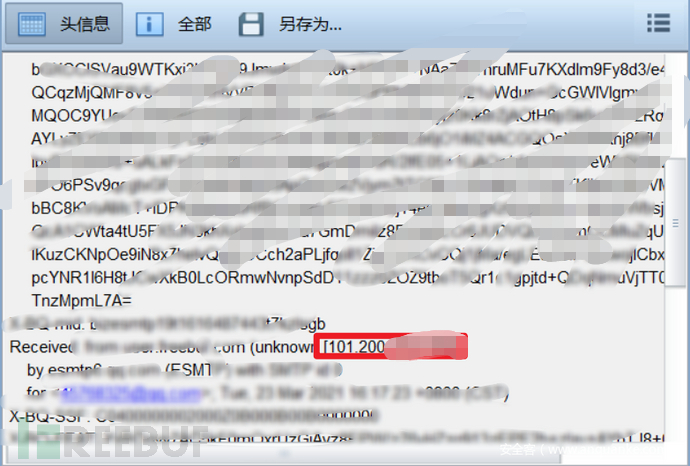
2.邮件服务查询
利用原理:邮件服务器 大部分不会做CDN 利用注册,找回密码等网站发送邮件进行验证,获取验证码,查看邮件代码获取IP地址
3.国外地址请求
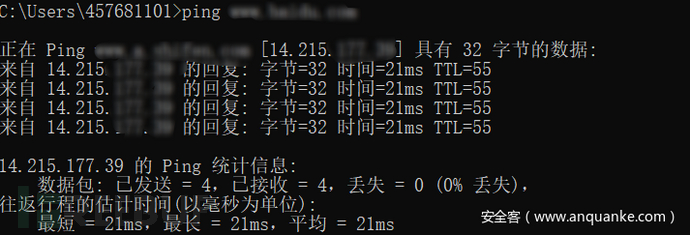
利用原理:只针对于中国地区进行cdn防护,没有部署国外访问的CDN的访问节点
(1)利用国外ping对目标进行ping检测(尽量使用少见国家)

(2)利用VPN全局代理利用CMD进行PING检测
4.遗留文件
利用原理:网站搭建时,遗留文件中含有真实的IP地址 例如:phpinfo() 上面可能会有ip
5.黑暗引擎
(1)利用黑暗引擎google shodan zoomeye等进行搜索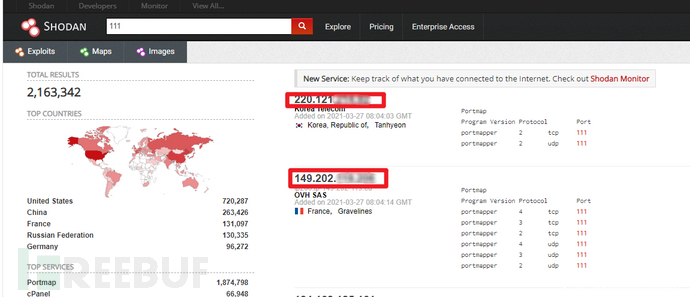 (2)搜索特定ico图标 很多缓存节点对这个不会进行cdn防护 哈希值
(2)搜索特定ico图标 很多缓存节点对这个不会进行cdn防护 哈希值
6.dns历史记录
查看网站的dns 利用原理:可能之前未使用DNS 之后使用了CDN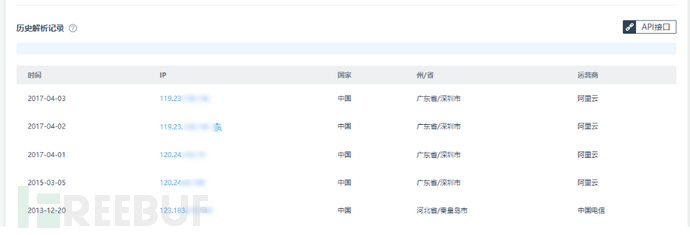
7.第三方接口查询
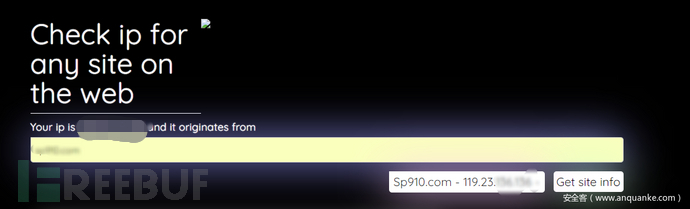
3.可能出现问题
1.为什么使用方法的不同发现的IP地址不同
(1)可以利用备案号或者公司地址的查询
判断IP所在的地址 然后手动判断IP地址的真实性 例:通过不同方式发现两个IP地址位于两个不同的城市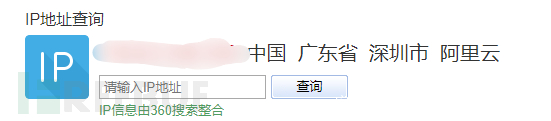
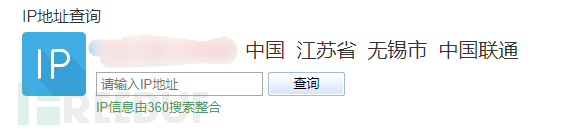 通过网站的备案号查询我们发现,备案号是粤开头的 我们就可以判断真实IP地址是位于广东省的
通过网站的备案号查询我们发现,备案号是粤开头的 我们就可以判断真实IP地址是位于广东省的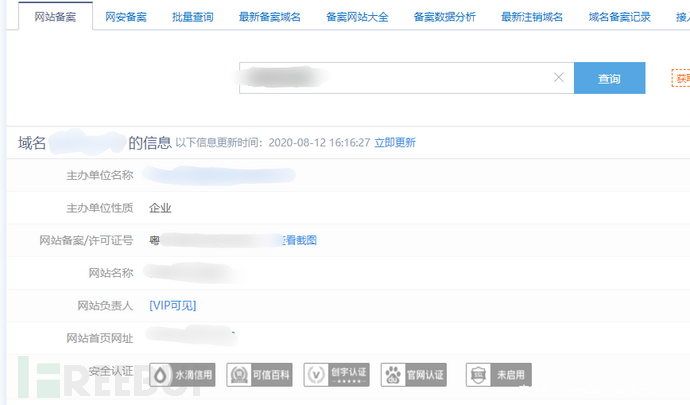
2)修改本地host
hosts文件位于:C:WindowsSystem32driversetc 然后用cmd进行ping检测 真实存在的IP地址就可以打开
4.判断是否有WAF
WAF是Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称: WAF)。利用国际上公认的一种说法:Web应用防火墙是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一款产品。
简单来说就是对网站进行防护,然后对访问进行限制,从而达到防护网站的目的。
在线判断是否有WAF:https://scan.较好15.cn/web/
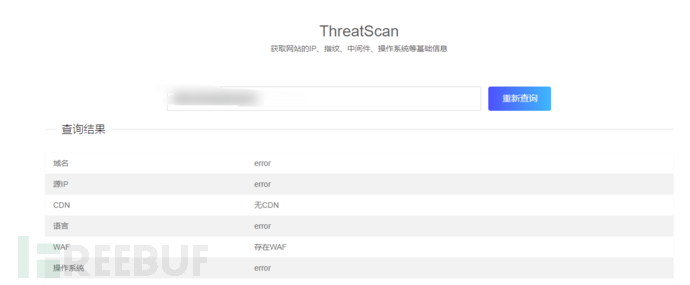
但无法判断waf类型 可以利用工具wafw00f进行判断
但并不是全部的waf都能够进行识别。
5.敏感文件泄露
常见的比如有phpinfo Rebot
6.爬取的时候遇到WAF的cc攻击防范怎么办
常见的waf都会对访问过快的ip地址进行封禁或者采取一定的措施,我们就难以对目标进行爬取获取我们所想要的信息。
这边我以webpathbrute的一些简单绕过进行说明
cc攻击防范是针对我们过快的访问或者非法访问进行限制
1.延时
通过修改访问间隔来使得我们访问速度变慢 从而实现绕过waf

2.白名单访问
利用工具进行爬取,如果使用工具扫描,在http头部中us中会有工具的特征,而waf会对这个检测,然后禁止访问,我们可以修改us信息从而绕过。
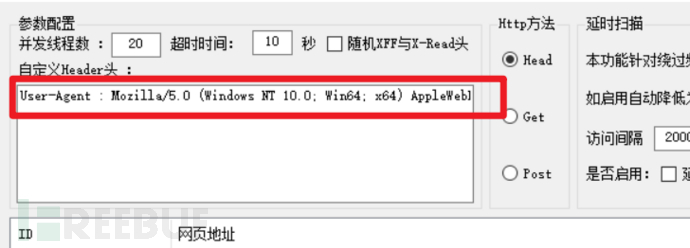
3.代理池绕过
简单来说就是用多个ip地址进行访问,封掉就换,实现目录的爬取。在后面我会单独写一篇文章对代理池的利用进行讲解
关于如何入门WEB信息收集就分享到这里啦,希望上述内容能够让大家有所提升。如果想要学习更多知识,请大家多多留意小编的更新。谢谢大家关注一下亿速云网站!
文章包含AI辅助创作:如何入门WEB信息收集,发布者:亿速云,转载请注明出处:https://worktile.com/kb/p/29157
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 