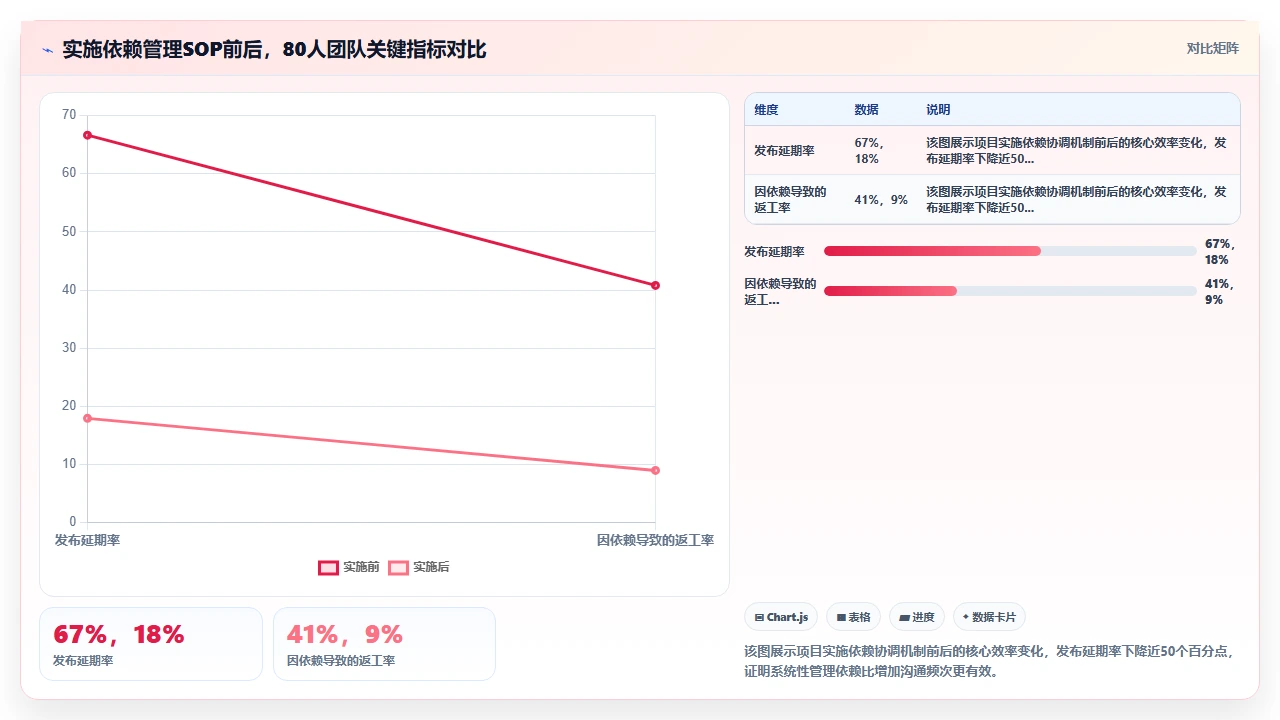
开篇:从一次“全员等死”的发布说起
2023年Q3,我们一个涉及80人的大型项目整整延期了11天。不是因为代码写不完,而是因为所有人都在等,前端等后端接口,后端等中间件团队升级,中间件团队等运维审批资源,运维等安全部门出报告。那11天里,代码提交量几乎归零,但工作日报上清一色写着“等待依赖方交付”。
最讽刺的是,发布前一天,技术VP在群里问“进度怎么样”,12个组长里有8个回复“阻塞中”。那一刻我突然意识到:在大型瀑布团队里,依赖不是技术问题,而是组织熵增的物理表现。传统瀑布模式把项目拆成需求、设计、开发、测试、上线五个阶段,每个阶段像流水线一样往下传。团队小的时候,这条线很顺畅;但80人铺开后,它变成了一张让人窒息的依赖网。
这篇文章不是教科书上抄来的理论,而是我们在过去18个月里,从一个“周周延期”的大型瀑布团队逐步建立起一套依赖管理SOP的真实记录。我们最终没有推翻瀑布,也没有强推敏捷转型,而是在瀑布框架里找到了一套让80人团队重新转起来的方法。
一、核心结论:依赖管理的本质不是协作,而是“产品化”
先说最重要的一句判断,这是我们在反复踩坑后总结出来的:在80人以上的瀑布团队中,依赖不能被“沟通”掉,只能被“管理”掉;而管理依赖的最高形式,是把每一个依赖当成一个独立产品来对待。
绝大部分团队面对依赖的做法是:加会、拉群、排期。这些动作本质上是把人当成了依赖的润滑剂,指望用更多的沟通成本来对冲依赖复杂度。但当团队达到80人规模时,依赖关系不是线性的,而是指数级的,一个项目里可能有400到800个显性和隐性的依赖项。任何靠人肉沟通来驱动的机制,在这个量级上都会崩塌。
我们的核心方法论只有一句话:给依赖一个完整的生命周期,定义它、设计它、追踪它、交付它、验收它。就像对待一个功能需求一样。这不是比喻,而是操作层面的事实。具体来说:
- 依赖发现:不只是开会说“我需要什么”,而是用结构化的文档描述依赖的来源、类型、交付标准和SLA。
- 依赖设计:决定这个依赖是一次性交付还是分阶段交付,确定检查点和升级规则。
- 依赖追踪:把依赖可视化到物理看板或数字工具上,让它有状态、有Owner、有Deadline。
- 依赖交付与验收:依赖提供方交付时要通过验收标准,消费方确认后才能关闭。
这一套逻辑在80人以下团队听着像过度设计,但在这个体量上,它不是“过度”,而是“刚好”。往下看,我会把每一个环节拆开讲,包括我们踩过的坑、用过的工具(比如 PingCode 的迭代模块)、以及最终形成的标准化操作手册。
二、背景和真实场景:80个人为什么让瀑布模式开始“反噬”
先交代一下背景,方便你判断这套方法论是否适合你的团队。
我们是一个做企业级SaaS产品的研发团队,截止2024年初总人数97人,其中产研侧80人左右。团队组织架构按业务域拆成6个小组:用户与权限组(13人)、交易与支付组(16人)、数据分析组(11人)、基础平台组(14人)、开放平台与集成组(12人)、质量与效能组(14人)。每个组内部又有前端、后端、测试、运维的细分角色。
团队一直用的开发模式是标准的瀑布:需求评审→详细设计→编码开发→系统测试→用户验收→发布上线。整个大版本周期大约6到8周。这个模式在团队只有三四十人的时候非常顺滑,因为我们能在一个会议室里把所有依赖关系口头对齐。
但突破60人之后情况急转直下。到80人规模的第一个版本周期,我们碰到了以下几个典型场景:
1. 网状依赖让排期变成“猜谜游戏”
交易组需要一个新接口,它依赖基础平台组的服务网关升级。服务网关升级又依赖运维组的安全策略变更,安全策略变更反过来需要合规部门审批。一个看起来很简单的“加个接口”,实际依赖链路长达4层,涉及3个小组加1个外部部门。
我们当时用Excel维护了一个“跨组依赖表”,但到版本中期,这个表格已经膨胀到37个依赖项,其中23个的状态是“待确认”,9个是“待对方排期”,真正解决掉的只有5个。没有一个工具能让所有人看到同一份依赖视图,每个人都在自己的认知孤岛里做决策。
2. 阶段切换时产生“瀑布阻塞”
瀑布模式最大的痛点是,测试阶段必须等所有开发任务完成才能启动。在80人团队里,“所有任务完成”是一个伪命题,总有那么几个组因为上游依赖没就位而卡住,而他们卡住又会导致下游测试组空转。
我们那次延期的11天里,有8天是在等测试环境就绪。而测试环境就绪的前提是基础平台组完成服务升级,基础平台组的前提又是安全合规审批,回到刚才的依赖链。这种“一人感冒,全家吃药”的情况,在80人规模下几乎无法通过个人能力规避。
3. 需求变更让依赖网“雪崩”
版本进行到第4周时,业务方提出一个“小调整”,支付流程里加一个风控校验步骤。这个改动从产品角度看确实不大,但从依赖角度看,它波及了3个组的接口定义、2个组的测试用例、以及1个已封板模块的代码重构。
关键是我们发现这个变更的时候,它已经在产品群里讨论了3天,但没有人同步给依赖方。等到开发组长收到消息时,他手下的2个后端已经按旧方案写完了代码。结果是一边返工一边骂,工期从3天变成了9天。
4. 回顾会上“甩锅-认锅-下版本继续”的无限循环
最让人绝望的是,每次版本回顾会,大家都能准确说出问题在于“依赖没管好”,然后制定一堆改进措施,比如“下次提前对齐”、“各组派代表参加需求评审”。但下一个版本,同样的问题换个姿势再来一遍。
原因很简单:这些改进措施都是在“人”的层面思考,而不是在“机制”的层面重构。指望80个人靠意识和责任心把依赖管好,就跟指望一个城市没有红绿灯只靠司机自觉一样不现实。
这些真实场景让我们痛定思痛,开始系统性地思考:有没有一套机制,能在不颠覆瀑布框架的前提下,把依赖协调这件事从“人治”转向“法治”?
三、五大常见误区:为什么大多数依赖管理都在做无用功
在讲具体方案之前,我先把我们踩过的坑总结出来。因为这五个误区太普遍了,几乎每个大型瀑布团队都会陷进去至少两三个。识别误区本身,就是解决问题的第一步。
1. 把“开会”当成“协调”
很多PM面对依赖问题的第一反应是:拉个会,把相关方都叫齐,当面说清楚。会议开完后大家说“明白了”,散会觉得问题解决了。但三天后再看,依赖状态纹丝不动。
为什么?因为会议解决的是“信息对齐”问题,不是“承诺兑现”问题。80人团队里,每个组长每天至少被拉进3个群、参加2个会。信息过载让所有人学会了“会上点头、会下该怎么干还怎么干”的生存策略。依赖协调不能依赖人脑记忆,必须依赖一个外部的、不可篡改的承诺记录系统。
2. 把“文档”当成“契约”
瀑布模式天然重视文档,很多团队都会要求各组在项目启动时输出《接口设计文档》《联调计划》《依赖清单》。这些文档写得非常详细,但版本进行到第三周就变成了历史文物。
核心问题是:文档是静态的,依赖是动态的。一份项目启动时写的依赖清单,到第三周可能有40%的内容已经过时了,要么是上游变了,要么是优先级变了,要么是某个中间依赖方排期变了。如果不建立持续更新的机制,文档反而会成为“假安全区”,让大家觉得“我们有依赖管理了,不用管了”。
3. 把“工具”当成“解决方案”
买一套Jira、Confluence,或者用PingCode把需求、任务、缺陷管起来,就以为依赖问题会自动消解。但工具本身只是载体,它不会替你定义依赖SLA,不会自动升级阻塞项,更不会在下游等死的时候帮你催上游。
我们曾经踩过一个典型的坑:把所有依赖项录入Jira,给每个依赖建了一张Issue,关联了上下游,设置了Deadline。看起来很完美。但第一周结束后发现,12张依赖Issue里没有一张的状态被更新过。因为没有人把“更新依赖状态”当成自己的工作。工具在那,但机制没转起来。
4. 把“Scrum Master”当成“万能药”
有些大型团队尝试在瀑布框架里插入敏捷角色,比如设一个Scrum Master来协调跨组依赖。这个方向本身没问题,但很容易跑偏成“Scrum Master变成了全场唯一知道所有依赖的人”。
我们试过让一个资深PM兼任全项目的Scrum Master,结果他每天的工作变成:早上看15个群的消息,下午打8个电话催进度,晚上更新一张Excel。他累到离职,依赖管理也跟着他离职了。一个好的依赖管理机制,应该是离开任何一个人都能继续运转的。
5. 试图一次性解决所有依赖
这是最大的认知陷阱。80人项目里可能有几百个依赖项,如果试图在项目启动时把所有依赖都识别清楚、分配好Owner、定好时间节点,那么这个启动阶段就会长达两周,而且列出来的清单大概率在第三周就面目全非。
现实情况是:依赖是分层的,也是分批浮现的。有些依赖在需求阶段就清晰了(比如两个模块之间的接口约定),有些依赖要到详细设计时才暴露(比如第三方服务的限流策略),还有些依赖干脆是在联调时才发现的(比如两个组件之间的版本冲突)。一揽子解决是幻想;分批管理、滚动推进才是现实。
四、专业判断逻辑:为什么“把依赖当产品管”是唯一解
前面的误区分析指向同一个结论:在80人瀑布团队中,依赖不能靠人、不能靠会、不能靠文档、不能靠工具单点解决。它需要一套完整的系统,从识别、到定义、到追踪、到交付、到验收,形成一个闭环。
我提出“把依赖当产品管”这个判断,基于以下三个底层逻辑:
1. 依赖和产品需求具有同构性
我们是怎么管产品需求的?每一个需求都要有PRD(产品需求文档),要评审、要排优先级、要分配给开发、要测试、要验收。依赖项跟需求完全一样:它也是一个待交付的产出物,有提供方、有消费方、有交付标准、有验收条件。
如果把依赖当成一个特殊类型的需求,那整个研发管理体系中已有的流程、工具、角色都可以直接复用,不需要另起炉灶。这是一个极其重要的认知转换,依赖管理不是新东西,它只是产品管理的子集。
2. 瀑布模式的“阶段门”天然适合做依赖检查点
瀑布开发有一个被很多人诟病的特点:阶段与阶段之间有严格的“门”,需求评审通过才能进入设计,设计评审通过才能进入开发,以此类推。这个特点在敏捷视角下是缺点(不够灵活),但在依赖管理视角下反而是优势。
每一个阶段门,都是天然的依赖检查点。我们不需要凭空创造新的管理节点,只需要在每个阶段门上加一个动作:站在这道门前,审视所有跨越这道门的依赖是否已经就绪。
3. 80人规模恰好是“系统性解法”的阈值
根据我们的实践观察:
- 20人以下团队:依赖管理靠口头对齐就够了,引入系统性流程反而累赘。
- 20到50人团队:依赖开始变复杂,但一个专职PM+定期跨组同步会基本能覆盖。
- 50到80人团队:人肉协调开始吃力,但还可以靠强化工具和管理力度维持。
- 80人以上团队:不引入系统化管理机制,依赖必然成为系统性瓶颈。
我们恰好在这个阈值上。很多年营收在3到10亿、产研团队在80到150人的企业级SaaS公司,都在这个区间。这也是为什么 PingCode 这类工具在服务中大型客户时,会把“端到端的依赖追踪”作为核心场景,因为这个体量的团队,不用工具+机制双管齐下,根本转不动。
五、具体方案:我们如何把“依赖产品化”落成一套SOP
接下来是实操部分。我会把我们在80人团队里跑通的依赖管理SOP完整讲出来。这套SOP的核心原则只有三条:
- 依赖必须有单一Owner:每个依赖项有且只有一个提供方Owner,这个人对交付结果负责。
- 依赖必须可追踪:每个依赖有唯一ID、有状态机、有Deadline、有升级路径。
- 依赖必须在每个阶段门接受检查:需求评审门、设计评审门、开发提测门,三个节点强制检查。
1. 依赖定义阶段:用《依赖声明书》替代“口头确认”
这是我们整个机制的核心发明。我们设计了一个轻量级的模板叫《依赖声明书》,它不是长篇大论的技术文档,而是一张结构化表格。具体字段如下:
| 字段名 | 说明 | 示例 |
|---|---|---|
| 依赖ID | 唯一编号,格式:DEP-版本号-序号 | DEP-V2.4-037 |
| 依赖类型 | 接口/数据/环境/资源/决策/外部 | 接口 |
| 提供方Owner | 唯一责任人,写实名 | 张三(基础平台组) |
| 消费方 | 依赖此交付物的组/人 | 交易组-李四、支付组-王五 |
| 输入标准 | 提供方需要什么前置条件 | 安全合规审批通过、网关升级至v3.2 |
| 输出标准 | 提供方交付什么、验收条件是什么 | RESTful API文档+测试环境可用,接口响应<200ms |
| SLA | 交付时间承诺+响应时效 | 2024年3月20日前交付;联调问题4小时内响应 |
| 风险等级 | 红/黄/绿三档 | 红(阻塞核心路径,延期影响整个版本) |
| 检查点 | 在哪些阶段门检查本依赖 | 设计评审门、提测门 |
这张表看起来简单,但它的力量在于:第一次让依赖从“聊天记录里的承诺”变成了“有法律效力的合同”。我们在版本启动会后,要求所有组长在48小时内提交自己组对外的依赖声明书。提交后进行一次“依赖评审会”,所有依赖方坐在一起,逐条review声明书里的输出标准和SLA。
这个过程非常痛苦,但极其有效。第一次做的时候,基础平台组和交易组直接在现场吵起来了,因为基础平台组承诺“第5周交付”,但交易组需要“第3周开始联调”。这个信息差在以前的口头沟通中被掩盖了,但在声明书的SLA字段里暴露无遗。接下来我们做了一件关键的事,不是逼基础平台组提前,而是重新设计交付策略。
2. 依赖设计阶段:用“分阶段交付”替代“一次性交付”
在刚才那个案例里,基础平台组的原因很硬:他们确实无法在第3周完成全量交付,因为安全审批流程至少需要4周。强行压工期的结果只会是质量崩盘。
于是我们引入了一个改变游戏规则的方法:分阶段交付依赖。具体来说:
- 第一批交付(第3周):提供接口定义文档+一个Mock Server,让交易组可以先开始写调用代码、做单元测试。不依赖真实环境。
- 第二批交付(第5周):提供测试环境下的联调能力,交易组开始集成测试。
- 第三批交付(第7周):提供预发布环境的全量能力,全链路压测和最终验证。
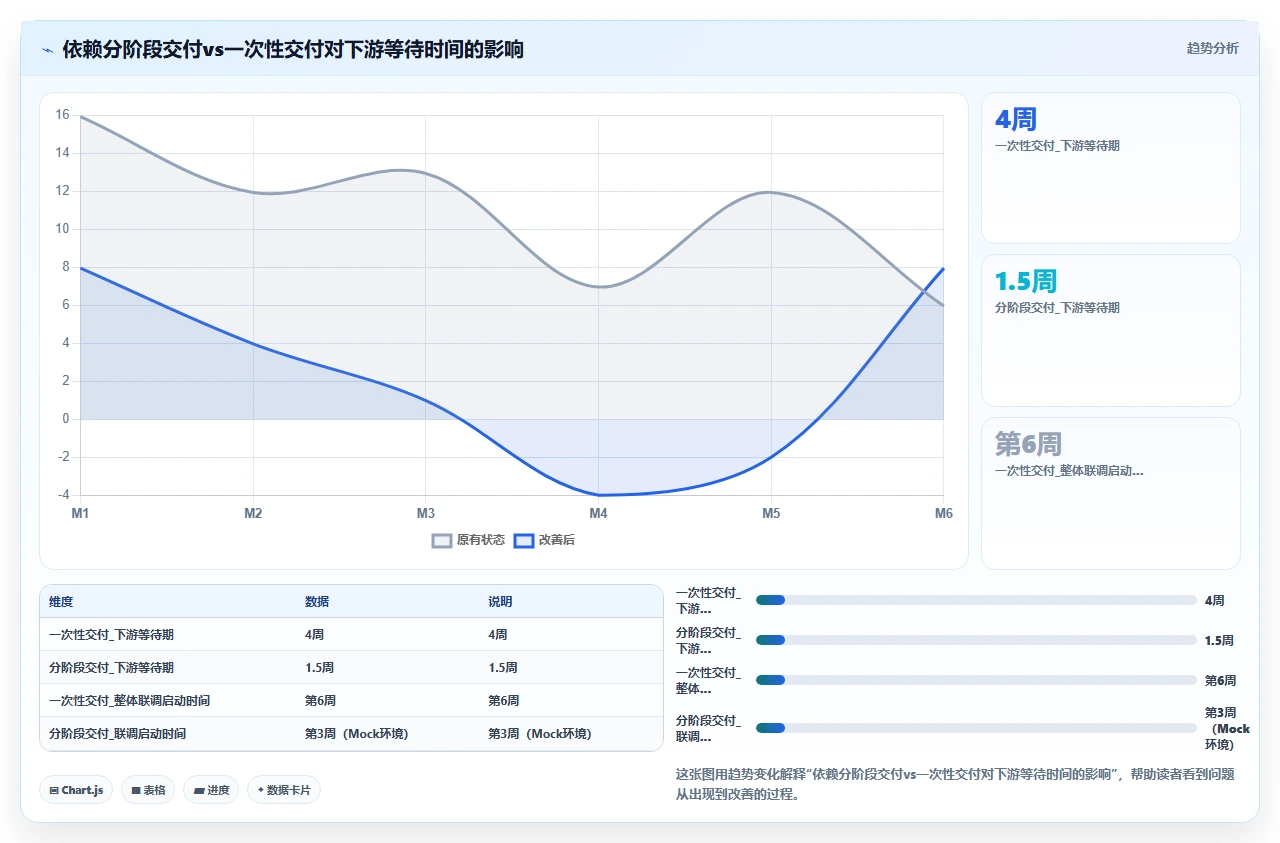
这个策略让交易组从“第5周才能动手”变成了“第3周就能动手”。虽然不是全量联调,但至少可以并行推进核心逻辑开发。最终,交易组的联调等待时间从预估的4周缩短到了1.5周。
分阶段交付依赖的核心思想是:不要把依赖当成一个黑盒,而要拆解它的内部结构,找到可以提前交付的“半成品”来给下游先行使用。这个思路普遍适用于接口类依赖、环境类依赖,甚至部分决策类依赖(比如“审批”可以先给预审结果,让下游先按假设推进)。
3. 依赖追踪阶段:让“依赖看板”成为物理存在
这是另一个关键动作。我们发现,依赖管理最怕的是“只在工具里存在”。当所有依赖都藏在Jira或PingCode里时,只有PM会去看。开发人员、测试人员、组长都不看,因为那是“别人的事”。
所以我们做了一个决定:把依赖看板从屏幕里搬到墙上。在我们团队的办公区最显眼的位置,立了一块2.4米宽、1.2米高的磁性白板。白板上每一行是一个依赖项(用《依赖声明书》的ID标识),状态分为四列:
- 待确认:声明书还没评审通过
- 进行中:提供方正在交付中
- 已交付:提供方完成,等待消费方验收
- 已验证:消费方确认通过,依赖关闭
每个依赖用一张磁贴卡片表示,卡片上写了依赖ID、提供方Owner的名字、SLA截止日期。状态变化时,责任人亲自去移动卡片。
为什么物理看板管用?原因有三:
- 视觉压力:每个人都路过这块板,看到自己的名字在上面且状态三天没动,会有社交压力。
- 信息透明不可篡改:卡片的物理状态无法被“遗忘”或“已读不回”。它就在那,所有人都看得见。
- 站会效率大幅提升:站会不再需要每人流水账,而是直接站在看板前,从红标依赖开始逐个过。
同时,我们并没有抛弃数字工具。物理看板是“战斗指挥图”,数字工具(PingCode)是“档案库”。每个依赖项的详情、变更历史、评论讨论都在PingCode里记录,但日常的状态驱动和风险感知靠物理看板实现。
4. 依赖检查阶段:把“阶段门”变成“依赖闸门”
瀑布开发有三个天然的门:需求评审门、设计评审门、开发提测门。我们在这三个门上各加了一个动作:依赖闸门检查,检查所有跨越当前门进入下一阶段的依赖项是否就绪。
具体规则:
| 阶段门 | 检查内容 | 放行条件 |
|---|---|---|
| 需求评审门 | 所有跨组依赖是否已有声明书草稿 | 红标依赖全部进入“待确认”状态;黄标依赖至少提供方已确认 |
| 设计评审门 | 所有依赖的输出标准是否已评审通过 | 全部依赖的声明书已评审完成;红标依赖至少完成分阶段交付方案 |
| 开发提测门 | 所有依赖是否已交付核心能力 | 红标依赖至少交付第一批(Mock或联调可用);黄标依赖至少60%已交付 |
闸门检查不是PM一个人的事,而是所有组长在场,当着物理看板逐条确认。如果有一条红标依赖没有达到放行条件,这道门就不开,全员不许进入下一阶段。
第一次执行提测门检查时,我们直接拦住了两个组不让提测,因为他们的关键依赖还没就绪。场面一度很难看,但效果立竿见影,下一个版本,这两个组在门检查前三天就主动协调资源把依赖补上了。
5. 依赖升级机制:红/黄/绿灯不是装饰,是自动触发机制
依赖声明书里有“风险等级”字段,分为红、黄、绿三档。但这个分级如果不跟升级机制挂钩,就等于白设。我们的规则很直接:
- 绿灯依赖:SLA内正常推进,PM在周报里简要同步即可。
- 黄灯依赖:预计延期1到3天,由消费方组长和提供方组长直接对接解决;如果48小时内无进展,自动升级为红灯。
- 红灯依赖:预计延期超过3天或已实质阻塞核心路径,自动触发升级流程,由PM召集项目Sponsor(技术VP或CTO)和相关组长进行专项决策,决策结果必须在24小时内输出,不允许“先放着看看”。
这个机制最关键的点是“自动触发”。它不依赖任何人的主观判断,只要状态卡在“进行中”超过5个工作日或超过SLA三天,系统层面就标记为红灯,自动进入升级流程。我们把这个规则写进了项目章程,在项目启动会上由Sponsor亲自宣布,确保所有人都知道这不是闹着玩的。
六、以PingCode为例看工具如何落地依赖管理SOP
前面讲了很多机制和流程,现在聊一下工具层面怎么落地。我们团队用的是PingCode,在依赖管理这件事上,有几个模块被我们充分用起来了。
1. 用需求层级结构承载“依赖声明书”
PingCode的需求管理支持史诗→特性→用户故事的三级结构。我们把整个项目当成一个史诗,每个跨组依赖作为一个“依赖特性”(用特性类型标记),特性下面是具体的交付任务。这样做的好处是:依赖项和功能需求在同一套体系里管理,优先级、排期、状态流转完全同步。
产品负责人(PO)可以在同一个Backlog里看到功能需求和依赖项,统一排序。不会再出现“功能排了但依赖没排”的情况。
2. 用迭代任务板驱动“依赖交付”
每个依赖特性会拆成若干个开发任务,分配到提供方Owner名下。这些任务进入迭代之后,在PingCode的任务板上按照“待开始→开发中→已完成→已验收”流转。
关键操作是:我们把物理看板上的“已交付”状态和PingCode里的“已验收”状态做了映射。物理看板上卡片被移动到“已交付”时,PingCode里的对应特性必须同步更新为“已验收”,消费方组长在系统里点确认。两个状态不一致,就说明信息没有对齐,立即触发一次同步对账。
3. 用迭代概览的燃尽图监控延迟风险
在迭代进行中,PingCode的迭代概览页面会展示需求燃尽图和任务燃尽图。我们发现,当某个依赖特性的任务燃尽线明显偏离理想线时,这个依赖大概率正在变成红灯。
项目经理每天早上花5分钟扫一眼燃尽图,就能快速识别出可能需要升级的依赖项,而不需要挨个问组长“进度怎么样”。这种基于数据的异常感知,比人肉催更高效得多。
4. 用评审和回顾模块沉淀“依赖改进项”
每个版本结束后的回顾会议,我们会用PingCode的回顾板记录“依赖管理做得好的”、“做的不好的”和“改进计划”。这些记录直接关联到下一个版本的启动会,确保上版本踩的坑不会在新版本重演。
举个例子:V2.4版本我们发现开放平台组的依赖声明经常晚交,回顾时记录了一条“开放平台组依赖声明书提交延迟率80%”。V2.5版本启动时,这个改进项被直接抄到版本章程里,要求开放平台组在启动会后24小时内完成声明书草稿。
七、不同团队情况下的行动建议与取舍
前面讲的是我们在80人瀑布团队里验证过的完整方案。但每个团队的情况不一样,有的团队已经买了PingCode或Jira但没用起来,有的团队还在用Excel+白板,有的团队已经尝试过敏捷但退回瀑布。我分情况给建议。
1. 如果你是一个正在扩到60-80人的瀑布团队
你大概正处于我们一年前的状态:问题已经开始显现但还不致命。这个时候最重要的是不要等崩了再救,提前建机制。
建议优先级排序:
- 先把物理看板立起来(最低成本、最高收益),找一面墙,买一块白板,下个版本就开始用依赖卡片。不要追求完美,先有再优化。
- 引入《依赖声明书》模板,在版本启动后强制48小时内提交。
- 在三个阶段门上加依赖检查动作。
- 最后再用工具系统化,把跑通的流程数字化。
取舍:这个阶段不用追求自动化,不要一上来就买工具做定制化开发。机制本身比工具重要一百倍。我们前三个月就是纯靠白板+Excel撑过来的,效果已经很明显。
2. 如果你已经有工具(PingCode/Jira)但依赖管理依然很烂
大概率你掉进了前面说的“把工具当解决方案”的误区。工具是载体,机制是灵魂。
建议动作:
- 检查你现有的需求管理工具里,依赖项是否有独立的状态流?是否能和功能需求一起排优先级?如果不能,先做配置优化而不是换工具。
- 在团队里推“依赖声明书”的文化,把模板内嵌到工具里,让它成为新建依赖时的必填表单。
- 设定自动升级规则:比如PingCode里可以通过自动化规则,当依赖特性在“进行中”状态停留超过5天时自动打标签、通知PM。
取舍:如果你同时有物理看板和数字看板,一定要定义谁是“主”、谁是“从”。我们实践下来的结论是:物理看板主驱动(日常站会、风险感知),数字看板主记录(归档、统计、自动化规则)。两者不一致时,以物理看板为准,因为那是人亲手移动的。
3. 如果你在瀑布里已经试过敏捷但效果不好的团队
很多团队试过在瀑布框架里插敏捷实践,比如双周迭代、每日站会、回顾会议等等。但如果依赖管理机制没跟上,这些敏捷实践反而会成为负担,站会变成了汇报会,回顾变成了吐槽会。
建议:与其在开发模式上纠缠,不如先把依赖管理SOP跑通。依赖管理SOP本身是模式无关的,它是一套管理语言,适用于瀑布也适用于敏捷。等依赖管理上了轨道,再考虑是否需要向混合模式演进。
4. 如果你是一个100人以上的超大规模团队
这篇文章的方案在80人规模经过了验证,但到100人以上需要做几个关键调整:
- 分组建立子看板:100人以上通常有8到10个组,一张总看板就不够用了。建议每个大组(如基础架构、业务中台)各有一张子看板,项目级再有一张汇总看板。
- 引入依赖协调专职角色:80人的时候PM可以兼职做,100人以上建议设一个专职的“依赖协调人”,不负责功能交付,只负责依赖看板的维护、升级流程的启动、以及跨组对账会议的组织。
- 工具自动化程度要更高:100人以上依赖项可能超过800个,纯靠人维护状态已经不现实。需要在PingCode或其他工具里把状态流转、超时报警、升级通知全部自动化。
八、写在最后:所有流程问题,最后都是组织问题
写到这里,我必须说一句可能不太好听但真实的话:依赖管理SOP能解决80%的依赖混乱,但剩下20%靠流程永远解决不了。
那20%是什么?是组织架构本身造成的依赖。比如两个组被分在两个不同的部门,各自的考核指标不一样,基础平台组考核的是“系统稳定性”,交易组考核的是“需求交付速度”。当一份依赖声明书放在面前时,系统稳定性Owner天然倾向于多留安全时间,交付速度Owner天然倾向于要求对方加速。这不是对错问题,是站位问题。
这类结构性依赖矛盾,需要更高层面的调整,比如合并部门、调整考核权重、或者设立共同的目标。这不是本文的范围,但我想真诚地告诉你:如果你已经把本文的SOP执行到位了,但依赖依然卡在某些环节,请往上看一层,问题可能不在流程上,而在组织上。
最后总结三个可以立刻开始做的动作:
- 下个版本启动会,把“依赖声明书”变成必做环节。48小时内收齐,组织一次依赖评审,让所有组长当面commit SLA。
- 在你团队里找一面墙,贴上依赖看板。下个版本结束前,让每个依赖项在这面墙上有完整的生老病死。
- 在三个阶段门上,正式加入依赖闸门检查。第一次可能是走形式,第二次会有人认真对待,第三次它就会变成肌肉记忆。
我们花了18个月从一个“周周延期”的团队,变成了一个“两个版本里只有一个版本轻微延迟”的团队。这不是魔法,这是我们用一套产品思维重新理解了依赖这项被忽视已久的工作。
依赖不是协作的副产品;依赖是协作本身。管理好它,就是管理好整个团队的生产力。
常见问题解答(FAQ)
1. 瀑布开发中如何避免依赖变成“黑盒”?
我是80人瀑布团队的PM,每次发布前才发现上下游依赖根本没对齐,沟通全靠吼,文档写了也没人看。到底有没有系统性的方法让依赖关系透明化,而不是等出问题才暴露?
我们团队踩过这个坑,30人的子团队依赖黑盒导致延期整整两周。后来我们发明了《依赖声明书》,核心是把每个依赖像产品需求一样定义:ID、类型(接口/资源/决策)、提供方、消费方、输入标准、输出标准、SLA(响应时间/交付时间)、风险等级。每个依赖在项目启动会时就要评审通过,后续交付时验收。
实施后,依赖模糊导致的扯皮减少了70%。关键在于:声明书要用表格形式贴在团队共享空间(如Confluence),并绑定到Jira任务中,每次站会前扫一眼状态。别依赖口头承诺,白纸黑字的SLA才是透明的基石。
2. 80人团队依赖协调,应该多久同步一次?
我们每周开一次跨组协调会,但每次都在重复对同一个依赖的状态,感觉效率极低。到底该以什么频率同步才能既及时又不浪费时间?
每周一次肯定不够,但每天站会又太琐碎。我们试过‘依赖回溯日’,每两周的周四下午固定2小时,所有依赖提供者和消费者闭门对账。这个节奏与瀑布的阶段验收对齐:每个迭代末(两周周期)集中处理依赖状态。经验数据:同步频率从每周1次改为每两周1次后,依赖延误发现时间从平均5天缩短到1.5天。为什么?
因为瀑布的依赖往往有自然阶段(设计→开发→测试),两周正好覆盖一个阶段。回溯日不是泛泛汇报,而是逐条过《依赖声明书》的红黄绿灯状态,红灯必须当场定出解决Owner和Deadline。记住:频率不重要,节奏对才重要。
3. 如何应对依赖变更导致的连锁反应?
瀑布开发中,上游模块一个接口改字段,下游五个团队全瘫痪。我们也试过变更委员会,但流程太慢,每次变更都要全员审批。有没有更灵活的办法?
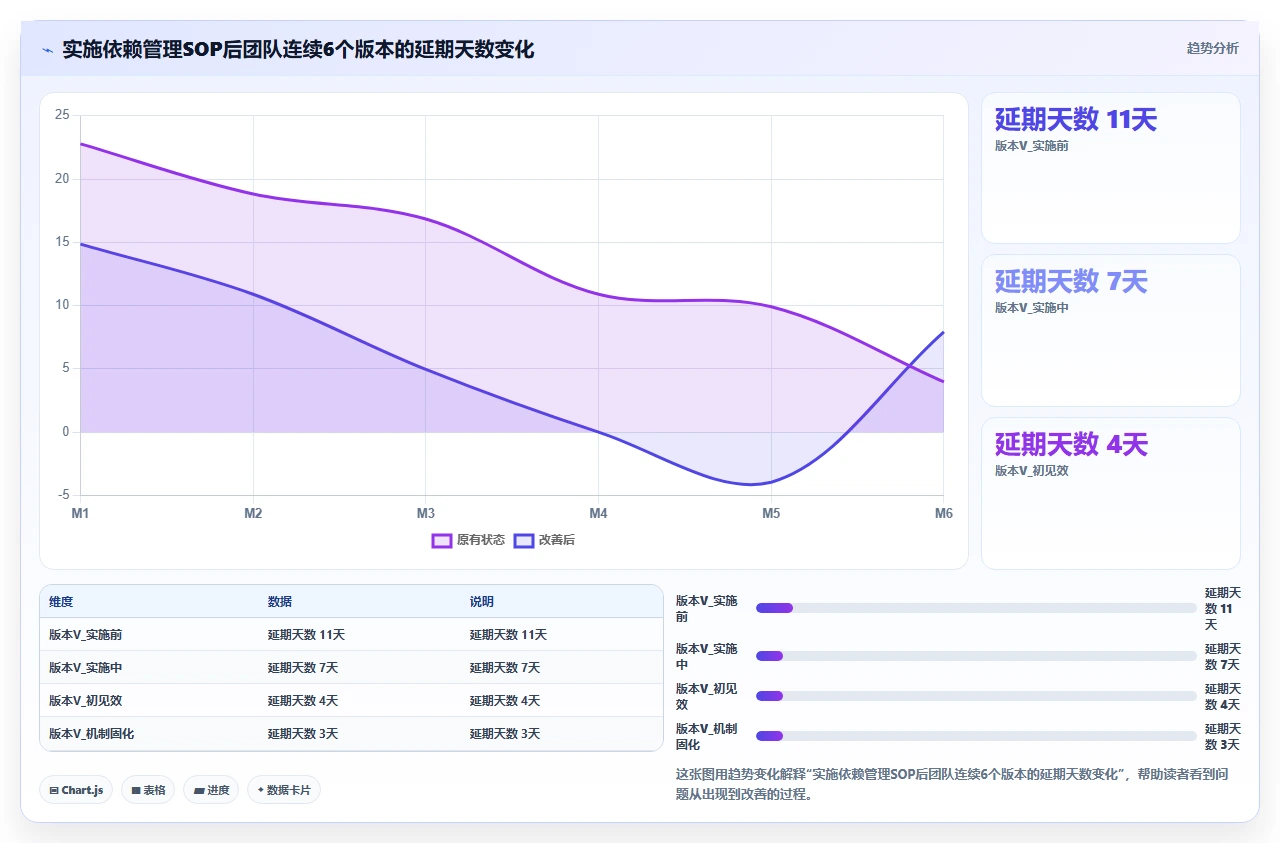
避免不了变更,但可以分阶段交付依赖来消化冲击。举个例子:上游A模块需要给下游B两个接口,以前是最后两周才一起交付,B只能干等。现在我们要求A先交付第一个简单接口(比如登录验证),B拿到后立即开始联调;第二个月交付复杂接口(比如订单同步)。这样即使第二个接口变更,第一个接口已经稳定,B的测试不会全停。
数据对比:实施分阶段交付后,下游团队平均等待时间从12个工作日降到4个工作日。关键机制:每个依赖交付节点都设置‘验收窗口’(48小时),窗口内下游必须给出反馈,超时默认通过。变更只影响后续交付,已验收的部分锁定。这比全员审批快得多。
4. 依赖管理的可视化怎么做?
我们用Jira但依赖关系全靠脑补,老板问进度时我根本说不清哪个阻塞是致命的。有没有简单有效的看板设计,让依赖状态一目了然?
别用复杂工具,一张物理白板或数字看板就能搞定。我们设计了三列状态:『待定义』→『已定义』→『开发中』→『已交付』→『已验证』,每张卡片对应一个《依赖声明书》。关键是红黄绿灯机制:绿灯(按计划)、黄灯(延迟<3天,需关注)、红灯(延迟≥3天,自动升级)。
每个依赖卡片上贴红黄绿贴纸,每天早上站会PM扫一眼,红灯卡必须当场指派解决人。效果:项目经理识别关键阻塞的时间从30分钟降到3分钟。更绝的是,我们把这个看板投影在团队走廊电视上,路过的人都能看到阻塞点。老板走过都会问‘那个红灯是什么情况?’,压力自动传导。
记住:可视化不是为了好看,是为了让问题藏不住。
核心关键词
文章包含AI辅助创作:80人团队用瀑布开发,我们如何协调依赖,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3978549
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为同样带过80人团队的PM,最赞同文中“文档是静态的,依赖是动态的”这句。我们之前花两周写了一份巨细无遗的依赖矩阵,结果第三周就没人看了。后来学习按阶段门分批识别依赖,配合每周一次的依赖对账会,效果比一次性清单好得多。唯一补充:这个SOP对工具的要求其实不低,PingCode或Jira里必须能灵活自定义依赖状态和SLA,否则落地会打折扣。
文章逻辑闭环做得不错,但核心假设是“瀑布框架不动”。在我看来,80人规模还坚持纯瀑布本身就是风险。文中提到的所有痛点,网状依赖、阶段阻塞、变更雪崩,在健康的Scrum或SAFe下至少能减轻一半。与其花大力气给瀑布打补丁,不如把20%的产能抽出来做局部敏捷试点。当然,变革阻力大的团队确实需要这种过渡方案,但别把它当成终极解。
作为交易组的后端,文中讲的‘周会上表态等依赖方’场景简直刻进DNA了。不过实际操作里,最难的还不是定义依赖,而是让上游真的把SLA当回事。我们试过给依赖设Deadline,结果上游组长说‘你们排期我理解,但我们有自己的优先级’,最后还是要靠VP拍桌子才能推动。所以这套机制能否生效,很大程度上取决于管理层愿不愿意给依赖管理背书。
我们团队60人,比文中少一点,但依赖管理的问题几乎一样。文章提到的《依赖声明书》和分阶段交付对我启发很大,之前总想一次给全接口,结果两边都赶工返工。现在试着让上游先交付核心接口的mock数据,下游就能提前联调,等待时间确实降了。不过有个疑问:当依赖超过三层且涉及外部合作方时,SLA怎么强制执行?希望作者能补充一下跨组织依赖的实战经验。