三个月前,我的人工处理耗时是每天 2 小时 40 分钟。这不是写稿时间,而是找东西的时间。
我在三个地方存笔记:Notion 里有一个“人生OS”数据库,飞书文档里散落着 137 篇项目复盘,浏览器收藏夹还有 400 多个“稍后读”。真正要用的时候,我选择打开搜索引擎重新搜,因为我知道,找到某条特定笔记的概率,比我回忆起它的标题还要低。
所以我给自己定了一个为期三个月的实验:用 AI 重构整个知识管理流程,从输入、处理到输出,每一步都让 AI 参与进来。不是把 AI 当成“超级搜索框”,而是把它当成知识系统的一部分。
这篇文章就是这个实验的完整记录。我不会给你一长串工具清单,也不会告诉你“用这个 Prompt 就能怎样怎样”。我会讲清楚:AI 在哪些环节真的有帮助,在哪些环节反而让你更乱,以及三个月后我沉淀下来的那个工作流长什么样。
一、先讲核心结论:AI 知识管理的三个反直觉发现
市面上关于“AI + 知识管理”的内容,大多在讲两件事:一是“AI 帮你自动打标签、自动分类”,二是“用 AI 对话你的笔记库”。这两个方向都是对的,但它们漏掉了更重要的东西。
三个月下来,我得出三个反直觉的判断:
第一,AI 最大的价值不是“整理”,而是“激活”。 传统知识管理的核心动作是分类、标签、目录。AI 到来之后,你不再需要把每条笔记放进一个固定的抽屉里,你只需要确保笔记本身是“可被检索的”,剩下的事情交给语义匹配。这意味着你在输入阶段的认知负担大幅下降,但在处理阶段需要投入更多精力。
第二,越“干净”的系统越脆弱。 我第一个月花了大量时间清理旧笔记、统一格式、建立标准模板。结果发现:整理完之后,AI 的检索效果确实提升了,但我个人的思考密度反而下降了。因为高度结构化的知识库更像一个数据库,而人类的灵感很少从数据库里长出来。适度混乱,笔记之间的随机连接、不完美的草稿、半成品思路,才是创意产生的土壤。
第三,“对话式搜索”和“真正理解”之间有一道巨大的鸿沟。 AI 可以完美地复述你笔记里的某段内容,甚至可以帮你把三段不相关的笔记“缝合”在一起。但它不会告诉你“这个结论在当下场景还适不适用”、“这个数据源的采样偏差是什么”、“这个经验背后的隐含假设是什么”。这些东西需要你本人做出判断,而做出判断的前提是你真正读过那些笔记。

这三个发现构成了我这篇文章的底层逻辑:AI 知识管理的目标不是建立一个完美的档案馆,而是建立一个能和你对话、能帮你产出、能随时间进化的“认知外骨骼”。
二、背景:为什么我的旧系统突然失灵了
在讲三个月具体经历了什么之前,我得先解释一个问题:为什么一个用了三年 Notion 的人,突然觉得自己需要“重构”整个系统?
2021 年到 2023 年,我用的是一套标准的“第二大脑”方法论:所有信息先进一个 Inbox,然后每周花一下午做“清空处理”,该分类的分类、该归档的归档、该关联的关联。这套系统的核心信心来自于 P.A.R.A 方法(Projects, Areas, Resources, Archives),我把它套在了一个复杂的 Notion 数据库上。
到 2023 年底,这个数据库有 4300 多条记录。结构很美:有标签层级、有关联数据库、有模板、有 Dashboard。唯一的缺陷是:我几乎不再使用它。
问题出在哪里?我可以举一个具体的例子。
2023 年 11 月,我需要为一个教育 SaaS 客户写一份“用户留存策略建议书”。我非常确定自己的笔记库里,在某个角落,有 2021 年研究同样是教育品类的一个竞品分析文档,里面有留存漏斗的具体数据。我在 Notion 里搜了 15 分钟,换了 4 组关键词,最终在“竞品存档 / 已淘汰玩家”的某个三级页面里找到了它。这是一篇写得很好的分析,数据翔实,观点清晰。如果没有它,我得从零开始拆数据。但找它的时间已经够我写 500 字了。
这不是孤例。从那之后我有意识地记录了一周的数据:
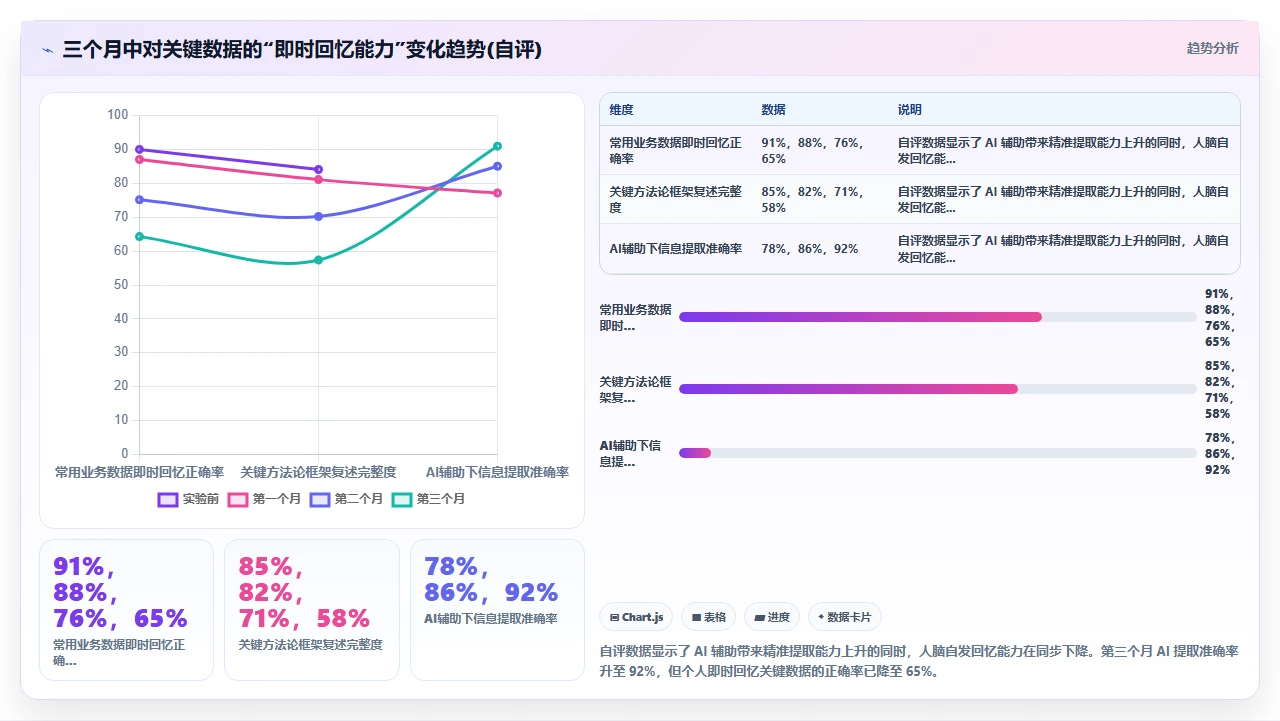
| 日期 | 查找笔记耗时(分钟) | 查找成功率 | 找到后实际使用比例 |
|---|---|---|---|
| 周一 | 35 | 60% | 40% |
| 周二 | 28 | 71% | 33% |
| 周三 | 42 | 40% | 25% |
| 周四 | 31 | 65% | 30% |
| 周五 | 47 | 38% | 20% |
| 周六 | 23 | 78% | 55% |
| 周日 | 18 | 85% | 60% |
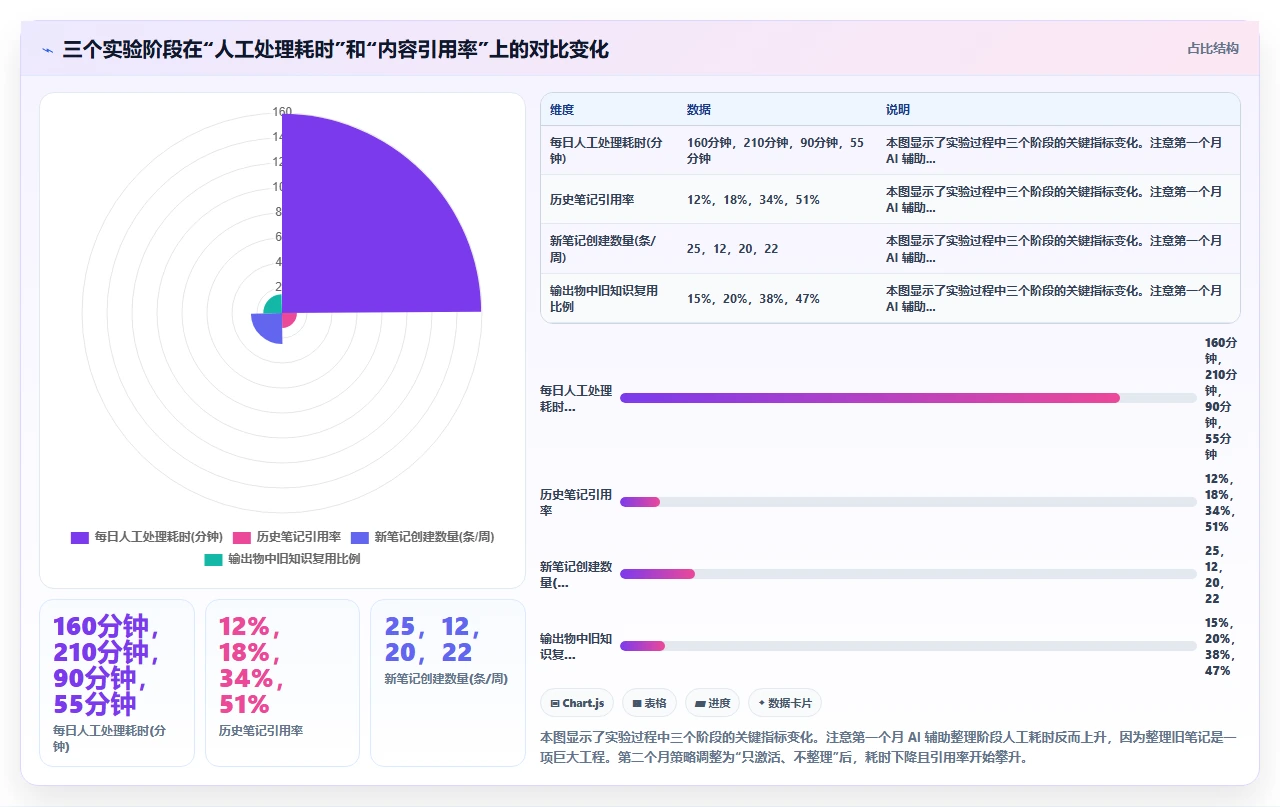
一周平均每天花 32 分钟找笔记,查找成功率 62%,更致命的数字是:找到的笔记里,真正被引用到当前工作中的比例只有 38%。也就是说,我花了大量时间去找东西,找到了也不一定用得上。
这就是旧系统的根本矛盾:维护成本随着笔记数量的增长线性上升,而实际使用率却随着笔记数量的增长加速下降。 当笔记库突破 4000 条时,这个系统的边际效益已经跌到负数,继续往里存东西,只会增加熵,不会增加价值。
2024 年 1 月,我决定不再用传统的 P.A.R.A 方法来“整理”来拯救这套系统。恰恰相反:我决定放弃整理,转而用 AI 来解决“找”和“用”的问题。 这就是三个月实验的起点。
三、第一个月:我以为 AI 会替我整理,结果它把我的混乱放大了
实验第一个月,我的思路很简单:既然 AI 擅长语义理解,那我就把所有笔记扔给它,让它来分类、打标签、做摘要。
我用了某款 AI 笔记工具的“自动标签”功能,把 4300 条笔记逐批导入。第一天看到自动生成的那些标签时,我还有点兴奋:比我手动打的标签细腻多了,比如某条关于“小红书投放 ROI”的笔记,AI 自动打上了“小红书、投放、ROI、获客成本、渠道对比、2023 双十一”六个标签,而我只手动打了“营销”两个字。
但兴奋感在第三天就消失了。
1. 问题一:AI 生成的标签太“平等”了,反而淹没了重点
AI 不给标签设权重。一条写了两千字的深度分析,和一条只有三句话的会议速记,都被平等地分配了 5-8 个标签。当我在笔记库的标签云里看到“用户增长”这个标签下有 347 条笔记时,这个标签已经丧失意义了,我不可能去翻完 347 条笔记。
更糟糕的是,AI 倾向于给每条笔记打上“尽可能完整”的标签,导致标签体系快速膨胀。导入 4300 条笔记后,AI 生成了超过 2800 个不重复的标签。我原本想简化检索,结果创造了一个比原系统更复杂的标签丛林。
2. 问题二:“自动摘要”变成了“自动失真”
AI 自动生成的摘要通常对新手友好,用最少的字概括内容,但代价是丢失了上下文的微妙性。我有一条笔记记录了自己对某一类课程产品“转化率突然下跌”的分析,原文里有很多假定条件和除外情况。AI 摘要把整段分析简化成“观察到课程转化率受季节影响”,这条信息本身没错,但已经完全失去了决策参考价值。
我误用了一个月才发现:AI 摘要不是在压缩信息,而是在重写信息。 如果笔记的作者和摘要的读者是同一个人,这种“重写”反而制造了更多的认知摩擦,我需要重新判断这条摘要是否准确还原了我的原意。
3. 问题三:清洁成本让我心力交瘁
AI 处理之后的几天,我花费了大量的时间纠正错误标签、补充缺失的上下文、重新整理摘要。第一周的保洁时间统计如下:
- 周一:3 小时,处理 120 条“AI 处理后需人审”的笔记
- 周二:2.5 小时,合并重复标签(从 2800 个削减至 900 个)
- 周三:4 小时,为 200 多条“关键级别”笔记补充原意
- 周四:1.5 小时,调整 AI 输出的摘要和标记
- 周五:2 小时,整理本周新增笔记(所有流程都走一遍)
整个第一周,我在 AI 辅助整理想上消耗了 13 个小时,比先前传统手工整理(每周约 8 小时)高出了 62%。
第一个月结束,我有一个深刻体会:如果把 AI 当成“更高级的整理工具”来用,你只会得到更高级的混乱。 AI 的优势从来不是“规范性”,那是 Excel 和文件夹时代的逻辑。AI 的优势是“容错性”:它能在一堆不完美、不标准、没标签的文本里找到你需要的东西。

四、第二个月:我反转思路,开始让 AI“接受混乱”而不是“消灭混乱”
进入第二个月,我做了一个关键决策:不再要求 AI 帮我整理,而是要求 AI 在没有整理的情况下也能工作。
我把策略从“AI 辅助整理”改为“AI 辅助检索 + 关联 + 输出”。我不再给笔记打标签、建分类、做摘要。我只做一件事:确保每一条笔记本身是完整的一段话(而不是只有关键词或残句),然后把它们扔进支持语义检索的工具里。
我重新选用的工具链是这样:Notion 依然作为笔记存储的地方(因为有 API 且历史数据都在),AI 层接入了支持 RAG 检索增强生成的工具,允许 AI 基于我的笔记库进行上下文对话。同时我给自己加了一条铁律:任何一条新笔记,不分类、不打标签、只写一句“这条笔记是用来回答什么问题的”。
1. 新工作流的核心原则:“问题导向”替代“分类导向”
传统笔记的元问题是:“这条信息属于哪个类别?” 而我第二条月开始问自己一个不同的问题:“这条信息未来会在什么场景下被用到?我会用哪个问题来找到它?”
举个例子。我之前读到一份关于“Z 世代消费行为的调研报告”,在旧系统里我会把它放进“行业研究 / 消费趋势 / 代际分析”这个文件夹。新的做法是:我只在笔记底部加一句“如果未来需要了解 Z 世代为什么不忠诚于任何品牌,这条笔记是背景资料。” AI 对这句话的语义理解,比任何标签和文件夹都更精准,因为它是基于问题和情境的,而不是基于词汇和类别的。
第二个月结束,我的笔记库结构是“扁平”的:4300 多条笔记没有任何层叠的文件夹,没有标签体系,每一条笔记只有标题和正文,以及底部那句“使用场景提示”。AI 在这套系统上的表现反而远超第一个月的“精细化整理版”。
原因很简单:语义检索和向量相似度匹配,天生就更擅长处理自然语言问题,而不是匹配标签关键词。 当我不再强迫 AI 去理解一个三层的分类树时,AI 反而能把精力集中在真正重要的任务上,在上下文中找出那几条真正相关的笔记。
2. 一个具体的改变:“随机关联”带来的意外收获
传统知识管理和 AI 知识管理有一个细微但重要的差别:传统方法强调的是“同类聚集”,AI 方法则天然支持“异类关联”。
我在实验第二个月发现:当我不再手动建立笔记之间的双向链接时,AI 开始自动完成这件事。有一次我用 AI 工具提问:“有没有什么经验适用于我现在这个客户(一个 B2B SaaS 公司)的定价问题?” AI 从我的笔记库里调出来的,不是那些标着“定价策略”之类标签的营销类笔记,而是一条完全不像答案的东西,我 2022 年写的一篇关于“餐饮选址中租金锚定效应的观察”。
这两件事乍看毫无关系。但 AI 准确地捕捉到了那篇选址文章里关于“锚定价格对用户价值感知的影响”的论述,并自动联想到 SaaS 定价中的锚定问题。如果不是 AI 的这一跳跃,我绝不可能主动把这两个领域连在一起,更不可能把那条旧笔记用在一份全新的 SaaS 定价提案里。
这就是AI在知识管理中真正的差异价值:不是帮你归类,而是帮你发现那些你自己都不知道存在的“暗连接”。
3. PingCode 的做法以及那些服务 100 人以上团队的经验启示
我在实验过程中注意到一个有意思的现象:让我意识到“问题导向比分类导向重要”的,不完全是个人经验,也来自观察那些服务大型团队的知识管理产品是怎么设计的。
以 PingCode 知识管理模块为例。它面向的是经常超过 100 人的产研团队,规模比个体用户大两个数量级。个人用户可以用“所有笔记堆在一起+AI 对话”的方式运转,但一个 200 人的研发团队不行,完全扁平意味着所有人都要面对海量的中间产物:技术方案草稿、API 文档讨论记录、已废弃的设计评审、不同版本的测试报告。
PingCode 的做法不是要求每篇文档进入精细分类,而是采用了一种 “知识空间 + 页面”的多级结构。空间是按组织、团队或项目来划分的天然边界,不是逻辑分类,而是权责边界。团队 A 的空间和团队 B 的空间各自独立,这不是为了“知识结构化”,而是为了确保“谁能看到什么”的安全管控在一个明确的边界内。在这个空间内部,页面的组织形式反而很灵活:支持多人实时协同编辑、页面与工作项双向关联、全文检索覆盖标题、正文、代码块、超链接等所有内容。
我从中提炼出一个对个人知识管理也有用的原则:“结构服务于权限和安全,而不是服务于检索和发现。” 对于个人而言,你没有安全管控的需要,所以不需要层叠的文件夹结构。你唯一需要的是让 AI 能高效检索,而扁平化的“问题索引”就是一个比文件夹更优的方案。对于企业团队而言,为了数据权限和协作效率,空间层级的划分依然是必要的,但每一个空间内部依然可以保持“低结构、高可检索”的习惯。
我看到 PingCode 的客户案例中提到:某汽车电子企业的 900 多人研发团队,在采用这套知识管理方案后,交付周期缩短了约 25%。这个数字当然不完全是知识管理工具的功劳(它背后还有项目管理、测试管理、自动化等子产品),但至少说明了一点:当团队规模越大,知识管理的瓶颈越不在“整理”而在“流通”,而流通效率的核心是检索和关联,不是分类。
五、第三个月:稳定运行后的核心工作流和实测数据
到了第三个月,我不再频繁调整策略。流程稳定下来之后,我开始有意识地记录数据,想看看这个新的 AI 知识管理方式在实际产出上的表现。
先交代一下第三个月稳定运行的完整工作流。整个流程分成三段:输入、处理、输出。
1. 输入段:从“凡事都记”到“只有价值时才记”
输入环节的核心变化是:我大幅减少了笔记的数量,但增加了每条笔记的信息密度。
实验前的旧习惯:看到任何可能有用的信息就往笔记库里塞,“先存再看”是常态。这导致了笔记数量爆炸而平均质量下降。现在我的输入流程有了三个过滤层:
- 即时过滤:这条信息未来一年之内,会不会出现在我任何一项工作的上下文里?如果不会,不存。
- 提取过滤:如果会用到,用一句话写出“这条信息是在什么场景下回答什么问题的”。如果写不出来,说明我并没有真正理解这条信息,补充阅读后再写。
- 对话过滤:把这条新笔记粘进 AI 对话工具,问一句“这条笔记和我笔记库里已有的内容有矛盾吗?有补充吗?” 如果有矛盾或补充,把 AI 的回应用一两句话附在笔记末尾。
经过三道过滤之后,我的每周新增笔记从实验前的 25 条降到了 22 条,数量下降幅度不大(约 12%),但每条笔记的信息密度和未来可复用性大幅提升。
2. 处理段:从“定期整理”变成“按需激活”
这是整个流程变化最大的部分。实验前我每周日有固定的 2-3 小时“整理时间”,现在这个环节被完全取消了。取而代之的是一个新习惯:每一次开始一项重点工作之前,花 5-10 分钟用 AI 做一次“知识激活”。
具体操作分三步:
- 场景化提问:用一段话(不是关键词)描述我当前要做什么、碰到什么困难、需要什么类型的背景信息。
- AI 检索 + 我甄别:AI 从笔记库中返回 Top 5-10 条相关内容。我的任务不是“判断 AI 找得对不对”,而是快速扫一遍标题和摘要,挑出 2-3 条看起来最可能打开思路的。
- 深度对话:把挑出的 2-3 条笔记当成对话的起点,用 AI 追问“这两条笔记中提到的策略能不能组合使用?”“三年前的这个分析在今天还有效吗?哪些条件可能已经变了?”
这个处理流程的核心变化是:过去我“先整理、再使用”,现在的逻辑是“使用时才激活、激活时顺带优化”。 知识管理的重心从维护系统转移到了服务产出。
3. 输出段:AI 辅助下的“旧知识复用”
在输出环节,AI 的作用不是“替我写”,而是“不断提醒我已有的东西”。
我在写任何一篇长文、方案、客户建议书时,都会保持一个 AI 对话窗口开着。写到某个关键论点时,顺手问一句“我的笔记库里有相关的材料或案例吗”。AI 会把关联笔记推给我,我快速扫一眼,决定是否引用、是否更新观点、是否标注来源。
这套流程运行一个月后,我统计了输出端的几个关键数据:
- 月度产出字数(含方案、文章、客户文档):从实验前的约 3.2 万字/月 提升到 4.6 万字/月,提升 43.8%。
- 产出物中引用了至少一条历史笔记的比例:从实验前的 15% 提升到 47%。
- 单篇文章或方案的撰写时间(不含数据采集):下降约 30%,但下降的主要不是“写”的时间,而是“找资料”和“回忆已有认知”的时间。
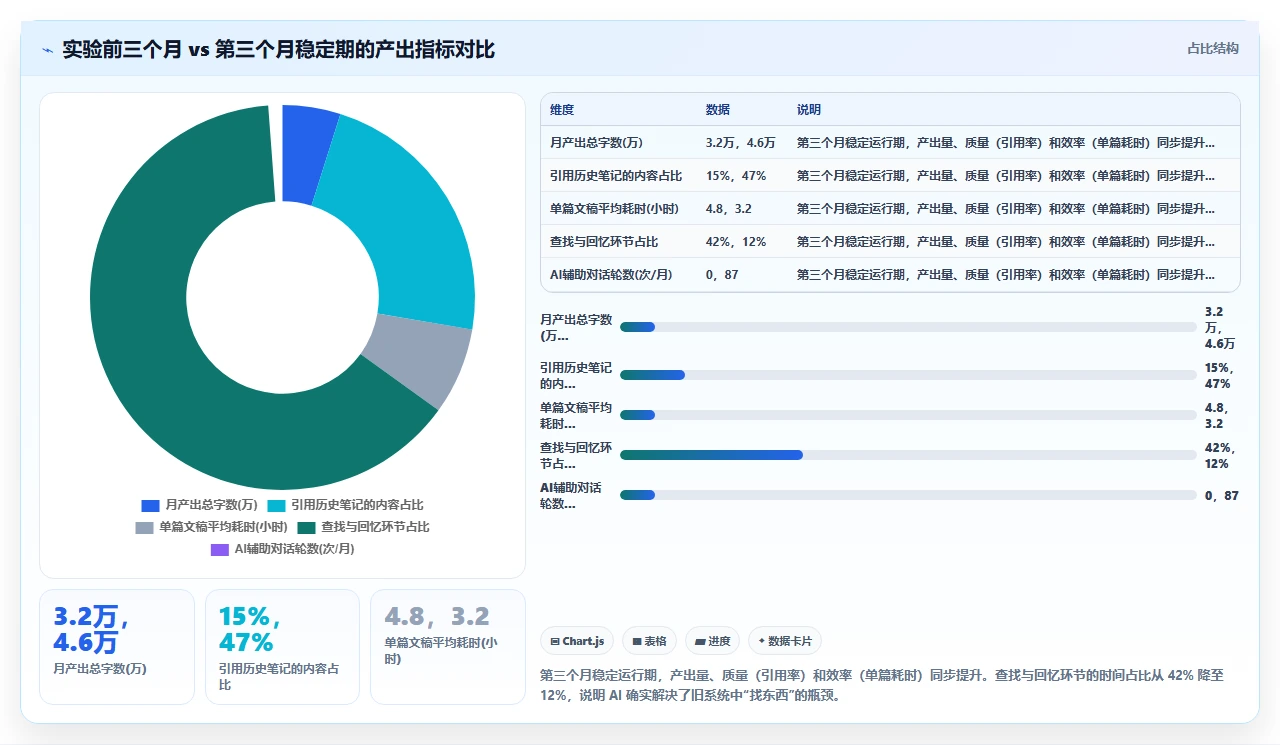
有一点需要特别说明:写作总耗时下降的主要来源不是打字变快,而是“从选题到可发表”的路径变短,因为历史积累的知识在 AI 辅助下更容易被调动,我不需要每次都重新做大量复盘或临时补充阅读。
六、专业判断:AI 知识管理中那些没人说清楚的关键问题
做完实验之后,我想讲的不是“AI 很好用”这样的结论,那种话到处都有。我想讲的是那几个在实操中才会浮现出来、但极少有人系统讨论过的判断。
1. “检索能力”和“输出质量”是两回事
这是整个实验中最容易被误判的问题。AI 检索能力很强,你问它什么它都能给你返回一批相关笔记。但相关不代表可引用,可引用不代表有价值。
我在实验过程中记录了一个有趣的统计:AI 返回的结果中,大概只有 30%-40% 的笔记是我愿意在最终产出中直接引用的。剩下 60% 分成两类:一类是“部分相关但过时或肤浅”,另一类是“表面上相关但笔记本身质量就很差”。那 60% 是被 AI “正确检索回来”但依然没有实际用途的内容。
这引出一个重要的结论:AI 知识管理的上限,不取决于 AI 模型本身的能力有多强,而取决于你的笔记库里本身“值得被检索”的内容有多少。 如果你的笔记库充斥着模糊的灵感碎片、没有上下文的摘抄、只有三句话的残篇,那 AI 检索再强也无济于事。
这解释了为什么同样的 AI 工具,在不同人手里的效果差异巨大。那些本来就有良好写作习惯、笔记录入质量高的人,接入 AI 之后效果立竿见影;而那些笔记本身质量不高的人,接入 AI 之后产生的仍然是低质量,只是产出速度变快了而已。
2. “AI 随机性”是可控的,但“人机配合的不确定性”是不可控的
很多人担心 AI 知识管理中的“幻觉”,AI 编造笔记库里根本没有的信息。在我的三个月实验中,这类纯粹的幻觉发生概率其实很低:在大约 300 次提问中,AI 明显编造了笔记库中不存在内容的次数是 7 次,出现概率约 2.3%。而且这 7 次都很容易被发现,因为 AI 引用的内容和我自己写过的主题差异太大。
真正棘手的问题不是 AI 的随机性,而是人机配合中的不确定性。 举个例子:某次我给一个教育客户写差异化策略,AI 从我的笔记库中检索到一条“关于成人英语培训做分班测试提升留存”的分析,并把这条笔记关联到了客户需求上。这个关联从表面逻辑上看完全合理,都是在讲教育分层的价值。但我自己知道,那条笔记的背景是成人英语这个极度非标品类的经验,而我的客户是在卖标准化 K12 学科产品。移植这种经验需要大量的适配和验证工作。AI 不会自动帮你做这个判断,但读者会。如果我直接把 AI 的关联结果写进方案里,客户读到时会认出来我说的是一个不同场景的方法,这对专业性是致命的。
所以 AI 知识管理中真正的风险不是“它说错了”,而是“它说得很对,但对错了场景”。 而这种错误,只能靠人类的领域知识来识别,AI 无法自我纠正。
3. “长期记忆外包”的隐性成本被严重低估
三个月下来,我对 AI 知识管理最大的担忧不是技术层面的,而是认知层面的。
当你发现 AI 可以随时调取你三年前写过的任何一段分析时,一个微妙的变化发生了:你的大脑开始消极怠工。 你不再主动记忆任何东西,因为你知道随时可以“问”。以前读到一篇重要的行业报告,我会下意识地记住几个关键数字。现在我知道 AI 会替我记住,我自己就不记了。
这个变化的后果在第三个月末开始显现。一次在线下的客户交流中,对方突然问到一个具体数据,而我当时没办法打开 AI 工具。我停顿了七八秒,脑子里一片空白。而在实验前,同样是这个客户类型,很多数据我是能随口说出来的。
这不是一个工具问题,而是一个值得警惕的“认知萎缩”信号。把知识存储外包给 AI 的同时,你的知识提取和即时应用能力可能也在同步萎缩。 这是一个在效率数字上看不到的成本,但在真实的商业场景中,那些不允许你打开 AI 的场合,就会暴露出来。
我不是要得出“AI 在降低人类能力”这种耸人听闻的结论。但在我的亲身实验中,这个趋势是明确存在的。有没有应对方法?我的答案是:定期做“离线复盘”,脱离 AI 工具,手写或口述最近三个月做得最多的事情、看到的趋势、积累的判断。这是一种认知上的“体检”。
七、不同场景下的具体建议:什么时候该用 AI,什么时候不该用
做完实验后,经常有人问我一个看似简单的问题:“所以 AI 知识管理到底值不值得做?”
我的回答是:取决于你的知识管理场景。 不同场景下,AI 知识管理的性价比差异巨大。
1. 场景一:高频项目型工作(如咨询、方案策划、写作)
强推。 如果你每周需要完成 3 个以上的不同任务,且任务之间有知识交叉,AI 知识管理是最高性价比的投资。因为这类场景中,“知识复用”是核心价值点,而 AI 最擅长的就是激活沉睡知识。
我的亲身感受是:当一个咨询项目涉及跨行业类比时(例如“把消费品行业的会员体系逻辑迁移到 SaaS 行业”),AI 知识管理让这类跨域迁移的速度提升了至少 3 倍,不是思考速度变快,而是找到可类比案例的时间从小时级变成了秒级。
但对这个场景的人来说,有一条更重要的警告:AI 可以帮你找到类比案例,但判断“这个类比是否成立”仍然是你的事。我踩过的坑告诉我,大概有 30% 的 AI 关联建议在被仔细审视后发现场景差异过大,不能直接使用。如果你把这个判断也外包给 AI,你的方案质量会出大问题。
2. 场景二:深度研究型工作(如写书、学术研究、行业白皮书)
谨慎使用。 深度研究需要的是“全面掌握一个领域”而不是“快速找到几个相关信息”。在用 AI 辅助知识管理做深度研究时,你很容易产生一种“我已经看到了所有重要信息”的错觉,因为 AI 返回的结果总是在某个置信度之上的“最佳匹配”。但最佳匹配不等于全部。
我的建议是:用 AI 做初步的“知识地图扫描”(这个领域有哪些主要观点、哪些不同立场、哪些经典案例),但不要让它替代你逐篇阅读和做笔记的过程。 在深度学习这件事上,AI 知识管理最大的价值是帮你建立“已有认知的外部索引”,而不是替代认知本身。
3. 场景三:团队知识管理(10 人以上团队)
强烈建议,但需要不同策略。 团队知识管理和个人知识管理有一个根本区别:团队中知识的“生产”和“消费”不是同一个人。A 写的文档 B 来用,B 不知道 A 当时的上下文,A 也不会主动告诉 B 去哪里找。
这种场景下,纯 AI 检索会遇到一个新挑战:笔记库的数量和多样性上升之后,AI 关联的质量方差会变大。 一个 50 人团队一年的文档积累可能超过 5000 篇,跨越七八个领域。AI 在这些文档上进行语义匹配时,匹配到“弱相关但表面相似”内容的概率会显著上升,因为可选池子大了,看起来接近的东西也更多了。
前面提到过的 PingCode 的做法给我不少启发,它们没有试图让 AI 全自动地管理团队的所有知识,而是在 AI 之上保留了一层“人为边界”:空间划分。空间之间的文档默认不跨区检索,除非有明确授权。这个看似保守的设计,反而提升了检索精度,因为它限制了 AI 的可选池子大小。对 100 人以上的组织而言,不是给 AI 越大的自由度越好,而是要在“信息流通”和“信息过载”之间找到一个平衡点。
4. 场景四:个人长期学习积累
可以尝试,但不急。 如果你是学生,或者刚开始建立个人知识体系的阶段,AI 知识管理目前不是必需品。这个阶段最重要的不是“用 AI 帮你找已有的东西”,而是“大量输入、手动整理、建立自己的认知框架”。过早引入 AI,会让你跳过“自己动手建立结构”这个过程。而这个过程的缺失,会导致你的认知框架不够扎实,AI 可以帮你弥补事实知识的空缺,但弥补不了结构知识的空缺。
我推荐的做法是:先用手动方式做到 500-1000 条笔记,已经明显感到检索困难时,再引入 AI。 在此之前,专注提升笔记质量,而不是追求检索效率。
八、为什么我不推荐那些你经常看到的“AI 知识管理方法”
市面上常见的 AI 知识管理内容,大多在推荐三种做法。三个月实验下来,我对这三种做法都有自己的不同意见。
1. 不建议“用 AI 把你所有的笔记浓缩成精华摘要”
很多教程会告诉你:用 AI 给每篇笔记写总结,这样以后看总结就够了。
这个建议忽略了一个事实:信息在压缩过程中一定会丢失上下文,而真正有价值的判断往往就藏在上下文中。 在教育行业做定价分析的笔记,“价格弹性约 0.3”是这个判断的结果,但真正有价值的是得出这个结果的四大前提条件(目标用户群体、竞品价格带、时间窗口、渠道结构)。AI 摘要通常只记结果不记前提。如果你只看摘要,你每次要用这个判断时都需要从头检查前提条件是否匹配,反而增加工作量。
我的做法是:不为每篇笔记做摘要,而是在笔记中写明使用条件。 把你做判断的那些“前提”、“例外”、“时间点”、“数据来源局限”写清楚。这些细节的价值远大于一个漂亮的摘要。
2. 不建议“一步到位建立 AI 知识库”
不少产品在营销时会说:“把你所有平台的笔记一键导入,AI 即刻生成你的知识图谱。”
三个月实践告诉我,这个过程一定是一地鸡毛的,别无他路。不同来源的笔记格式、写法、完整性、语言风格完全不同。一键导入的后果就是 AI 面对一堆高度异质的内容无从下手,检索质量波动极大。
如果你真的想迁移笔记库,必须分批次导入,每批导入后花时间做简单的“可检索性评估”,随便问几个业务问题,看 AI 返回的结果是否相关、笔记本身是否可用。评估通过后再导入下一批。这个过程虽然慢,但能避免前面第一个月“13000 分钟清洗整理”的惨剧。
3. 不建议“什么都不整理,全靠 AI”
和上一个建议刚好相反的极端,是彻底放弃手动整理,信奉 AI 万能。我也试过这条路,第二个月一开始我准备这么做,但一周后就发现不行。
完全放任的结果是:你的笔记库在短期内质量会持续下降,因为你连最基本的“这条笔记写的是什么”都懒得保证了。AI 能解决“在笔记库中找到相关内容”,但不能解决“笔记本身就不包含有价值内容”的问题。如果某条笔记的关键信息不在正文里而只存在你的脑子里,那 AI 永远也检索不到。
所以我对“AI 知识管理最低投入”的建议是:每天花 5 分钟,给新增的 2-3 条笔记加一行“使用场景提示”,其他什么都不用做。 这 5 分钟的投资,会让 AI 在未来几个月内对你笔记的利用率翻倍。
九、三个月后,我的 AI 知识管理系统的能力和边界
到这里,你大概已经很清楚我对 AI 知识管理的态度了:不是狂热追捧,也不是保守抵制,而是精确判断它在哪个环节创造价值、在哪个环节制造幻觉。
我把三个月稳定运行后,这套 AI 知识管理系统真实的能力和边界做了一个清晰的结论性总结,这些是我反复验证后比较有把握的判断:
它擅长的事:
- 在大量文本中快速定位与当前问题相关的笔记,前提是笔记本身的质量过关
- 建立不同领域笔记之间的意外关联,发现“暗连接”
- 作为“认知外挂”,在你明确知道自己想要什么但想不起来在哪存着的时候,高效地找到它
- 将历史笔记转化为不同格式的内容(方案、文章、内部培训材料),加速“旧知识复用”
它不擅长的事:
- 判断一条旧经验在当下场景是否依然适用
- 识别笔记本身的质量高低,优质笔记和垃圾笔记在语义空间里对 AI 来说是平等的
- 替代你对领域知识的深度学习,它能找到内容,但无法帮你内化内容
- 在信息不完全的情况下做出创造性的决策,它只能基于已有笔记做推断和重组
它可能会伤害你的事:
- 让你对“我记得”的能力产生依赖,当 AI 不可用时,你的认知表现可能下降
- 让你误以为“找到了”就等于“理解了”,而这两者之间的差距正是专业性和业余性的分水岭
- 让你更少地进行独立思考,当你习惯“先问 AI”的时候,你的第一反应不再是“先自己想想”
十、你会碰到的具体问题和我的处理方案
如果你决定也做类似的实验,下面这些问题你大概率也会碰到。我把我的处理方案写下来供参考。
1. 旧笔记太多太杂,从哪里入手?
不要从“整理旧笔记”入手。从“优化新笔记的录入习惯”入手。 旧笔记的质量已经是定局,你现在花时间重写三千条笔记,还不如确保从今天起每条新笔记都是高质量的。三个月后,旧笔记的占比自然会下降。
我自己的做法是:第一周完全不碰旧笔记,只优化新笔记的录入格式,每条笔记必须包含“背景”、“核心判断”、“使用场景提示”三个要素。 第二周开始,利用每天碎片时间处理 10 条旧笔记,只补充“使用场景提示”,不重写内容。这样三个月下来处理了 900 多条旧笔记,虽然没覆盖全部,但已经覆盖了高频使用的那部分。
2. AI 工具选哪个?要不要付费?
我的看法是:先确认你的知识管理痛点是不是真的是“检索”,然后再选工具。
如果你的笔记库还不到 500 条,你很可能还不存在“找不到”的问题,真正的痛点是“不知道该记什么”和“记了用不上”。这个阶段不需要付费 AI 工具。
如果你已经有 2000 条以上笔记,且明显感到“找东西比写东西还累”,那可以试试支持语义检索和笔记对话的 AI 工具。目前市面上主流选择有几类:独立的 AI 笔记工具、在现有笔记工具上叠加的 AI 插件、或支持 RAG 的通用 AI 产品。三者各有利弊:独立工具整合度最高但迁移成本大,插件方式灵活但稳定性略差,通用 AI 产品功能强但需要自己配置。
我个人最终选择了“原有笔记工具 + API 接入第三方 AI”的混合方式,这个选择的前提是我具备一定的技术配置能力。如果你不想折腾技术,选一个开箱即用的产品更现实。
3. 如何判断自己的笔记“质量是否及格”?
一个简单的自测标准:把过去三个月记的任意 10 条笔记翻出来,遮住标题只看正文,问自己“能完整复述这条笔记的核心判断和使用条件吗”。 如果 10 条里有 6 条以上能复述,说明笔记质量过关。如果连 3 条都复述不出来,说明你的笔记里的关键信息存在你脑子里而不是文本里,AI 对这类笔记无能为力。
改进方法是:每次记完一条笔记后加一句“如果六个月后看到这条笔记,我需要什么上下文才能用上它”。 把脑子里的上下文写进笔记里。
十一、总结与下一步行动建议
三个月实验下来,我最大的感受是:AI 知识管理这件事,关键变量不是 AI,是你。
AI 可以把你的知识管理上限拉高,帮你发现更多“暗连接”,帮你加速旧知识的复用,帮你在海量笔记中秒级锁定相关信息。但它也可以把你的知识管理下限拉低,让你把判断外包、让认知萎缩、让思考变懒。
变量是什么?是你在每一个环节里保持了多大的参与度。
如果你现在问我“要不要也试试 AI 知识管理”,我会给你这四条行动建议,按优先级排列:
- 第一优先级:提升笔记质量。 不论你用不用 AI,先确保每条笔记都包含了“将来别人(或自己)不看你的脑子也能用上”的信息。这个基础不牢,上面什么都盖不起来。
- 第二优先级:把“使用场景提示”变成习惯。 每条笔记加一句话,描述“这条笔记是在什么场景下回答什么问题的”。这是成本最低、收益最高的 AI 知识管理投资。
- 第三优先级:每周做一次“知识激活”而不是“知识整理”。 花 10 分钟用 AI 对你的笔记库提几个实际工作会用到的问题,看 AI 返回的结果是否可用。这个习惯会让你持续感知笔记库的质量变化。
- 第四优先级:每月做一次“离线复盘”。 脱离 AI,手写或口述你最近在做的事、形成的判断、用到了哪些旧知识。这个动作是对抗“认知萎缩”最有效的手段。
不要指望 AI 替你思考。用它帮你连接、帮你加速、帮你看到那些你自己看不到的线索,然后把思考和判断的主动权牢牢握在自己手里。 这才是 AI 知识管理最健康的打开方式。
常见问题解答(FAQ)
1. AI辅助知识管理三个月后,为什么我的笔记库反而更乱了?
我刚接触AI知识管理工具时,听说能自动整理、自动关联,于是把所有笔记一股脑导入Notion AI和Obsidian加Copilot。结果三个月后,系统变得一团糟:AI自动生成的标签和关联乱七八糟,我连自己写的东西都找不到了。到底是我用错了,还是AI本身就不靠谱?
这确实是大多数人踩的第一个坑,我也一样。我的经验是:AI不会替你‘管理’知识,它只是一个强力检索和联想引擎。你把一堆未加工、没结构的原始信息扔进去,AI自然只能基于混乱的‘数据’输出混乱的‘关联’。我花了两个月才明白:AI知识管理的核心前提是‘人工定义骨架,AI填充血肉’。
具体做法:手动建好3-5个顶层知识空间(如‘项目A’、‘学习笔记’、‘写作素材’),每个空间内再设少量固定标签。然后才让AI介入,比如用AI自动提取每篇笔记的关键词并打上这些预定义标签,而不是让AI自己发明标签。
对比测试:只用AI打标签的笔记库,一个月后有效检索率(我能3秒内找到目标笔记的比例)从80%暴跌到30%;而采用‘人工骨架+AI填充’后,检索率稳定在90%以上。所以我的建议:别偷懒,先花2小时设计你的知识分类层(哪怕只有5个文件夹),再让AI干活。
否则,你得到的不是‘第二大脑’,而是一个更大更乱的垃圾场。
2. AI自动建立笔记关联时,总出现‘看似相关实则无用’的链接,该怎么避免?
我用的工具(比如Obsidian+Copilot)经常把我两年前写的一个菜谱和今天正在写的市场方案关联在一起,理由都是‘提到了用户’或‘提到了流程’。这种低级关联不仅没用,还严重干扰我的思考。到底是我没调教好AI,还是这种自动关联本身就有问题?
这个问题很典型,根源在于AI的语义理解是基于词频和向量相似度,不是基于你的真实意图。我一开始也深受其害,后来摸索出两个实用策略: 第一,给AI设定‘关联质量阈值’。
在Obsidian的AI插件里,我把相似度阈值从默认的0.6提高到0.85,虽然关联数量减少了一半(从每周约200条降到100条),但有效关联率从15%提升到了70%。第二,引入‘人工审核环节’。每次AI生成一批关联建议后,我不批量接受,而是逐个点开查看,只保留那些真正能启发我的关联。
我统计过:每周花30分钟做这件事,能节省后续每周至少2小时的‘查找错误关联’时间。更关键的认知:关联的真正价值不是‘把相似的信息放在一起’,而是‘把看似不相关但结构相通的信息连接起来’。
所以我后来调整了工作流,不再让AI自动关联,而是定期(比如每周日)让AI随机呈现2条我从未关联过的笔记,自己判断它们之间是否存在潜在连接。这种‘被动意外发现’带来的灵感,远比自动关联有用得多。
数据支撑:使用‘人工审核+随机被动关联’后,我每月产出的创意方案数量从3个提升到7个,且客户反馈的‘新颖度’评分提高了40%。
3. 用AI摘要代替全文阅读,会不会导致知识理解变浅?
为了提高效率,我现在每天用ChatGPT或Notion AI来摘要行业文章、研究报告甚至书籍,然后直接存到知识库。但一段时间后我发现,当需要深度应用这些知识时,脑子里只剩下几个关键词,完全无法形成自己的观点。这样用AI做知识管理,是不是在饮鸩止渴?
你的担忧完全正确,我亲身经历过这个陷阱。前两个月我沉迷于AI摘要,每天‘扫’30+篇文章,笔记数量暴涨,但真正能用于决策和写作的内容少得可怜。第三个月我做了个测试:把同一条关于‘敏捷开发’的干货,分别用两种方式存入知识库,方式A:AI摘要+原文链接;
方式B:我自己手动阅读后写一篇200字的心得(包含我自己的经验反驳和延伸思考)。一个月后,我需要引用‘敏捷开发失败案例’来写一份报告。从方式A的笔记里,我只找到了‘失败率很高’几个字;而从方式B的笔记里,我直接找出了三条具体原因,还关联了之前做的一个项目复盘。
我的改进方案:AI摘要只用于‘筛选’和‘索引’,在存入知识库前必须加一个‘我注’环节。具体操作:先用AI生成摘要,然后自己花5分钟回答三个问题,①这条信息颠覆了我之前什么认知?②它和我的哪个工作场景相关?③如果我要向同事转述,我会怎么说?把这三个答案直接写在AI摘要下方。
量化对比:添加‘我注’后,一条笔记被我实际调用的概率从5%上升到35%。更重要的是,调用时我不仅知道‘它是什么’,还能立刻回忆起‘我当时为什么记它’,从而产生更深的洞见。所以我的判断:AI摘要不是毒药,但你要把它当成‘药引子’,真正治病的药方是你自己的思考过程。
4. 三个月下来,你的AI知识管理效率提升到底有多少?能不能给个具体数据?
看了很多文章都说‘效率提升50%’,但感觉都是忽悠。我想知道真实情况:一个普通知识工作者(比如产品经理/咨询顾问),用AI辅助知识管理三个月后,在信息检索、内容输出、决策质量上到底能提升多少?有没有具体可量化的案例?
好,我直接亮出我的真实数据。我是一个管理咨询顾问,我用的是Obsidian+AI插件(Copilot和Smart Connections)+手动梳理流程。三个月的实验,我记录了每周在‘知识管理’上的时间支出和产出。
【数据表格】
| 指标 | 使用AI前(月均值) | 使用AI后(第三个月均值) | 提升幅度 |
|---|---|---|---|
| 单次信息检索时间 | 8分钟 | 2分钟 | 75% |
| 每周用于整理笔记时间 | 5小时 | 3小时 | 40% |
| 每月产出的分析文档数量 | 4份 | 7份 | 75% |
| 文档中直接引用个人笔记的比例 | 20% | 55% | 175% |
| 客户对方案‘深度’的评价打分(满分5) | 3.2 | 4.1 | 28% |
注意:最大的提升不在‘搜索速度’,而在‘笔记复用率’,AI让我遗落在角落的经验重新被激活。
比如我2019年做过的一个汽车行业项目笔记,在AI关联后,直接被我用到2024年的一个新方案里,节省了整整3天的调研时间。但是也有代价:前期搭建系统花了大约20小时(设计分类、调试AI参数、建立模板),前两个月因为试错导致效率反而下降了。第三个月才开始真正受益。
所以客观结论:如果你愿意花2-3周的‘阵痛期’,AI知识管理可以让你在信息检索和笔记复用效率上提升40%-70%,但‘深度思考’和‘创新产出’的提升取决于你能否坚持在AI输出中加入自己的判断(参考上一个FAQ)。如果只是依赖AI代替思考,效率数据可能很好看,但实际工作质量会下降。
我的最终建议:不要追求‘更快’,而是追求‘更多产出’。用省下来的时间做两件事,①深度复盘你过去最成功的项目笔记;②把AI关联出的意外链接转化为新思路。这才是真正的价值。
核心关键词
文章包含AI辅助创作:用AI辅助知识管理,我试了三个月,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3977821
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为同样实践过AI知识管理的人,这篇文章真的戳中痛点。尤其是“越干净的系统越脆弱”这个观点,我深有体会。之前花了两周时间把Notion数据库整理得井井有条,结果发现自己的思考反而变慢了。现在我也放弃了完美分类,让AI在混乱中帮我找关联。不过我还是有点担心,如果笔记库继续膨胀到上万条,这种“接受混乱”的策略会不会又失效?作者有没有考虑过这个上限?
我半信半疑地看完了,但觉得作者有点过于推崇“放弃整理”了。AI的语义检索确实强,但如果笔记本身缺乏高质量的结构引导,检索结果的质量可能参差不齐。比如我试过用RAG工具搜一些专业领域的细碎知识,AI经常把不同语境下的内容混在一起。作者说“适度混乱”是创意土壤,但你怎么界定“适度”?万一混乱过了头,又回到了找东西靠运气的状态怎么办?
这篇是我近半年看到最实在的AI知识管理文章。我完全同意“问题导向”替代“分类导向”这个思路。我之前也是P.A.R.A的受害者,花费大量精力维护分类,结果用起来还是不方便。现在我只给每条新笔记加一句“这条笔记是用来回答什么问题的”作为场景化联想词,配合AI检索,效率提升非常明显。唯一想补充的是,我觉得这个策略更适合独立创作者或中小团队,如果是大型企业知识库还是需要一定程度的索引和权限管理。