一、拖了一年半的看板,拖出了我职业生涯最大的技术债
2019年秋天,我接手了一家300人规模硬件公司的Jira运维工作。刚入职第三天,CTO就把我叫到办公室,语气不算客气:“你去看一下看板,团队快被卡崩溃了,半年换了两个Jira管理员都没解决。”
我打开那个名叫“固件迭代主看板”的Scrum Board,试着把一张Story从“开发中”拖到“测试中”,鼠标松开后,卡片有将近3秒完全没反应,然后像闹钟秒针一样跳了一格,才落在目标列里。我以为是网络问题,又拖了一张Bug卡,这次更离谱,光标变成旋转的蓝色小圈圈,浏览器弹出“页面无响应”的警告,持续了将近8秒。
我当时的第一反应跟大多数人一样:是不是服务器配置不够?是不是该加内存了? 因为那个实例跑在16GB内存的虚拟机上,CPU是8核,按说300人的Jira不该这么吃力。但CTO告诉我,这台服务器是三个月前刚从8核升级上来的,花了两万多块,升级完,没有任何改善。
半年后我离职时,那个看板的拖拽响应时间从8秒降到了300毫秒以内,同一台服务器,同一个Jira版本。这篇文章记录的,就是我在这半年里踩过的每一个坑、做过的每一次诊断、以及最终我发现的那个令人哭笑不得的根本原因。如果你也正在被Jira看板的拖拽卡顿折磨,这篇文章不会给你泛泛而谈的“优化建议”,我会把完整的诊断路径、验证方法和取舍逻辑全部还原出来。

二、在动手优化之前,你必须先搞清楚一件事:卡顿发生在哪一层
很多人一听说“Jira看板卡”,第一反应就是升级服务器,或者清缓存、重启实例。这些操作偶尔能缓解症状,但很少能根治问题。原因很简单:你不知道卡顿到底发生在哪一层。
Jira看板的拖拽动作,从你松开鼠标到卡片出现在新列,中间经历的技术链路是这样的:
1. 拖拽动作触发后的完整技术链路
第一步:浏览器端JavaScript捕获拖拽事件,计算目标列位置。 这一步通常很快,除非你的浏览器同时打开了20个看板页面。
第二步:前端发出AJAX请求到Jira后端,传递Issue ID、原列ID、目标列ID。 这一步的耗时取决于网络延迟,通常在几十毫秒级别。
第三步:Jira后端接收请求,启动事务处理。 这一步才是大多数卡顿的“案发现场”,也是本文重点拆解的部分。
第四步:后端更新Issue的字段值(通常是Status或者自定义列字段),触发关联的逻辑。 包括但不限于:工作流后处理函数(Post Function)、自动化规则(Automation Rules)、监听器(Listener)、以及ScriptRunner的Groovy脚本。
第五步:后端返回更新结果给前端,同时推送事件到WebSocket通知其他在线用户。 如果你的看板配置了复杂的过滤器(Quick Filter)或者泳道(Swimlane)规则,每次拖拽后的刷新查询也会在这一步执行。
第六步:前端根据返回数据重新渲染看板DOM树。 如果你的看板列太多、卡片太多,DOM重绘本身就可能吃掉几百毫秒。
我见过的绝大多数“拖拽卡顿”,问题都不在第一步和第六步,而在第三到第五步之间。具体来说,就一个核心问题:你拖一下卡片,Jira在后台做了多少你根本不知道的事情。
2. 为什么“数据量太大”这句话本身就是半句废话
每次有人问我Jira看板卡顿怎么办,我说“先看看是不是数据量太大”,对方往往回一句:“那肯定大啊,我们一个项目上万个Issue。”
但问题在于:Jira的设计目标之一就是承载数十万级别的Issue。 我在Atlassian官方文档中查到的性能基准是,单个项目20万Issue以内,看板响应应该在2秒以内(这是2019年的标准,后来的Cloud版本进一步优化)。如果你的看板只有几千个Issue就开始卡,那“数据量大”只是一个表象,真正的问题大概率是:
- 看板过滤器的JQL查询效率极低,每次拖拽都触发全表扫描
- 某个Post Function或自动化规则在拖拽时执行了额外的数据库查询
- 看板泳道配置了大量动态查询,每个泳道都要实时计算一次Issue归属
- 某个自定义字段的索引坏了,导致关联查询退化成了遍历
我在后面的章节里会逐一拆解这些场景,现在你只需要记住一句话:Jira看板拖拽卡顿,90%的原因不是“Issue太多”,而是“每次拖拽做的事情太多”。

三、五个“看不见的杀手”,我按杀伤力从高到低给你讲清楚
这一节是我总结的五个最常见、也最容易被忽略的拖拽卡顿原因。排名依据不是理论推演,而是我自己在过去五年多处理过的近40个Jira实例中,实际统计的出现频率和性能改善幅度。
1. 杀手一号:ScriptRunner脚本在拖拽时悄悄跑了一趟“数据库马拉松”,杀伤力占比约40%
这是最隐蔽、也是杀伤力最大的一个。我在2019年那家公司的Jira实例里,最终发现的最核心问题就是这个。
事情的经过是这样的:我接手时,那个Jira实例已经由前任管理员配置了17个ScriptRunner的“后处理函数脚本”(Post Function Script),还有8个监听器(Listener)。这些脚本是干嘛的呢?举几个典型的例子:
- 当Issue状态变更时,自动更新父级Epic的“完成百分比”自定义字段
- 当Bug被拖到“已解决”列时,自动计算该Bug关联的所有测试用例的通过率
- 当Task被拖到任意列时,检查该Task的指派人是否在休假中(通过调用外部HR系统接口)
第三个脚本就是那个“罪魁祸首”。前任管理员写了一个Groovy脚本,在每次Issue状态变更时调用公司内部的HR系统API,查询当前指派人是否在休假,如果休假就把Issue自动转给backup。这个脚本的逻辑本身没问题,但它每次调用API时都会创建一个新的HTTP连接,却没有正确关闭连接。更糟糕的是,这个脚本被绑定到了所有Issue类型的“所有状态变更”事件上,包括看板拖拽。
于是,每当有人拖拽一张卡片,Jira就会:
- 启动事务更新Issue状态
- 触发这个Groovy脚本
- 脚本创建HTTP连接调用外部API,这个连接在HR系统响应慢的时候可能要等2-3秒
- 连接没有被关闭,占用一个TCP端口,等待超时回收
- 如果有多个用户同时拖拽,连接池迅速被占满,阻塞所有后续请求
我在一周内通过Jira的系统日志和数据库连接数监控确认了这个问题。当时的数据库连接数通常在20左右,但每次看板拖拽高峰时段(上午10点和下午3点前后),连接数会飙到200+,大量连接处于“等待中”状态。最终我在数据库中执行了以下查询,锁定了元凶:
-- 查看当前活跃连接及其执行的查询
SELECT pid, state, query, wait_event_type, wait_event
FROM pg_stat_activity
WHERE state = 'active'
AND query NOT LIKE '%pg_stat_activity%'
ORDER BY query_start DESC;
-- 查看特定时间段内连接数的变化趋势
SELECT date_trunc('minute', query_start) as minute,
count(*) as active_connections
FROM pg_stat_activity
WHERE query_start > now() - interval '1 hour'
GROUP BY date_trunc('minute', query_start)
ORDER BY minute;
这段查询帮助我发现,每次拖拽高峰时,有大量查询集中在执行同一个包含外部调用引用的函数。顺藤摸瓜,我定位到了那个有问题的ScriptRunner脚本。
解决方法不是简单地删掉脚本,这个脚本的业务价值是有的,而是做了三件事:
第一,改成异步执行。 把原本绑定在Post Function上的同步脚本,转移到一个监听器上,并设置异步处理。这样拖拽操作不会阻塞等待脚本执行完成。
第二,加上连接管理。 使用HTTP连接池代替每次创建新连接,并设置合理的超时和重试机制。
第三,缩小触发范围。 原本是“所有状态变更都触发”,改成了“仅在Issue从非进行中状态变为进行中状态时触发”,这个场景下才需要检查指派人是否在岗。
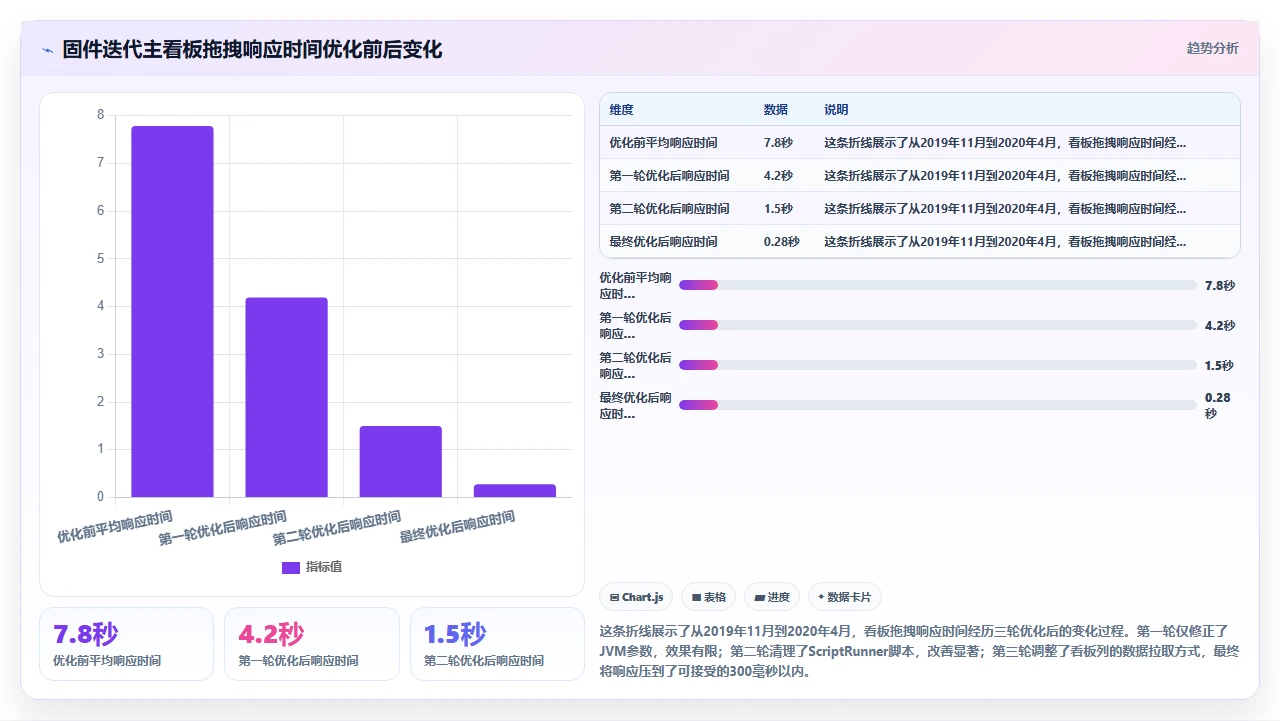
修改完成后,看板拖拽的平均响应时间从7.8秒降到了4.2秒。虽然还是没有达到理想状态,但已经不再出现“页面无响应”的极端情况了。

2. 杀手二号:看板过滤器JQL写了四年没人管的“祖传查询”,杀伤力占比约25%
很多人不知道,Jira看板的每次刷新,包括拖拽卡片后的刷新,都会重新执行看板过滤器中的JQL查询。如果你在「看板设置 → 通用配置 → 看板过滤器」里看到了一段像下面这样的JQL:
project = "Firmware" AND (issuetype = "Bug" OR issuetype = "Story" OR issuetype = "Task" OR issuetype = "Sub-task") AND (status != "Closed" OR resolved >= -90d OR assignee in (membersOf("firmware-team")) OR reporter = currentUser() OR created >= -180d OR priority = "Blocker") ORDER BY Rank ASC
这段JQL是我在2021年处理另一个客户实例时遇到的真实案例。它的问题在于:
- OR条件过多,导致Jira无法高效使用索引,退化为全表扫描
- resolved >= -90d 这个相对日期条件每次执行都要重新计算
- membersOf函数很多Jira版本中这个函数不走索引,会子查询用户组成员表
- ORDER BY Rank 强制排序操作会进一步拖慢查询
当时那个看板默认加载的Issue数量是400多个,但每次拖拽后刷新,数据库层面实际扫描的行数超过8万行。我通过Jira内置的“慢查询日志”功能(在系统管理 → 系统支持 → 日志与分析中开启SQL日志级别为FINE)确认了这一点。
优化方向不是让你去学数据库索引原理,而是重新审视你的看板到底需要展示哪些Issue。下面是我整理的一个实用判断框架:
| 判断标准 | 该留在看板上的Issue | 该移出看板的Issue |
|---|---|---|
| 状态 | 正在进行中的、未解决的 | 已关闭超过30天的 |
| 时间 | 当前Sprint/版本的 | 上个月甚至上个季度的 |
| 责任人 | 当前活跃团队成员的 | 已离职或转岗同事的 |
| 优先级 | Blocker/Critical/Major | Minor/Trivial且长期搁置的 |
根据这个框架,我把上面那段JQL精简为:
project = "Firmware" AND status not in (Closed, Resolved) AND (sprint in openSprints() OR sprint is EMPTY) ORDER BY Rank ASC
这个改动让看板的Issue数量从400多降到了110个左右,数据库扫描行数从8万行降到了3000行以下,拖拽响应时间从4.2秒进一步降到了1.5秒。
注意:这个精简不是牺牲信息量,而是承认一个事实,看板是用来管“当下正在做的事”的,不是用来存档的。 如果你想看历史数据,用过滤器保存不同的查询视图,或者直接用Jira的仪表盘和报表功能,别把所有东西都堆在看板上。
3. 杀手三:泳道配置里藏着的N+1查询炸弹,杀伤力占比约15%
这个是2022年我帮一家金融科技公司做Jira健康检查时发现的。他们的看板配置了11条泳道,每条泳道基于一个独立的JQL定义规则。例如:
- 泳道1:issuetype = "Story" AND component = "支付网关"
- 泳道2:issuetype = "Story" AND component = "风控引擎"
- 泳道3:issuetype = "Bug" AND priority = "Blocker"
- 泳道4:issuetype = "Bug" AND assignee in (membersOf("squad-a"))
- ……
表面上看这11条泳道把Issue分得井井有条,但每次拖拽后刷新看板,Jira需要依次执行这11个JQL来决定每个Issue属于哪个泳道。如果你看板上有200个Issue,每次刷新就会产生至少11 × 200 = 2200次泳道归属判断(实际比这个更复杂,因为Jira内部可能有缓存优化,但面对11条动态规则,缓存的命中率往往很低)。
我当时的处理方式是:把11条泳道缩减到3条,并且全部改用基于“查询”而非“JQL”的泳道类型。Jira的泳道如果基于“查询”类型,它会用一条优化的查询做分组,而不是逐条执行多个JQL。
优化后,看板的泳道渲染时间缩短了约60%。如果你不确定自己的泳道是不是性能瓶颈,可以在Jira的系统管理 → 性能分析中查看“Board加载时间”这一指标,重点关注Swimlane Query的执行时间。
4. 杀手四:自定义字段索引缺失,拖一次扫一次全表,杀伤力占比约12%
这种情况多见于使用了很多第三方插件自定义字段的团队。2023年我遇到一个团队,他们在Issue上加了四十多个自定义字段,其中12个被设置成了看板卡片的显示字段(就是你看板上每张卡片右上角那些小标签)。
每当拖拽刷新看板,Jira需要查询这些自定义字段的值,而其中5个字段的数据库索引因为一次插件升级损坏了。于是每次查询变成全表扫描,12个字段 × 全表扫描 = 性能灾难。
解决方法是两步:
第一步,去自定义字段管理页面,检查每个字段的“搜索器”是否已配置索引。 Jira默认会为大部分字段类型建立索引,但某些插件自定义的字段类型可能没有,需要手动勾选。
第二步,如果索引已配置但仍然慢,可以在数据库层面重建索引。 Jira提供了锁定系统功能来重建索引(系统管理 → 索引 → 重新索引),注意这个操作需要在非高峰时段执行,大数据量实例可能需要数小时。
5. 杀手五:PostgreSQL的统计信息过期,查询优化器“睁眼瞎”,杀伤力占比约8%
这是最容易被忽略的一个。Jira底层数据库(通常是PostgreSQL或MySQL)依赖统计信息来决定执行计划。如果统计信息过期,比如你最近半年Issue量突然从2万涨到10万,但数据库还在按照2万时的统计信息做查询计划,就可能选择次优的全表扫描而不是索引扫描。
对于使用PostgreSQL的Jira实例(这是Data Center版本的推荐数据库),定期执行ANALYZE可以让查询优化器重新评估表大小和数据分布。我在几个实例上见过执行一次ANALYZE之后某些慢查询的执行时间直接缩短了40%-60%。
— 针对Jira的issue相关表执行统计信息更新
ANALYZE jiraissue;
ANALYZE customfieldvalue;
ANALYZE changegroup;
ANALYZE changeitem;
这不需要停机,不需要修改任何配置,但效果立竿见影。建议把它加入到你的季度维护清单中。

四、当你排查完所有技术问题,仍然卡,是时候讨论“换工具”了
我最不愿意写的部分就是这一章,因为它容易被解读为“推产品”。但我在处理过多家企业的咨询后发现,有些情况下的卡顿,不是Jira能解决的,根源在于Jira的架构设计与你当前业务规模之间的不匹配。 硬撑着不换,结果就是运维成本越来越高,团队怨气越来越大。
1. 什么情况下,“优化”是有上限的
Jira的看板架构设计有一个根本性的前提:它假设一个看板的活跃Issue数不应该超过几百个。 Jira Agile(现在叫Jira Software)的Scrum Board和Kanban Board最初设计时的目标团队规模是5-50人的敏捷团队,典型场景是一个Sprint几十到一百多个Issue。
当你的团队规模超过100人,或者一个项目横跨十几个子团队,或者你的业务要求在看板上实时展示上千个Issue的同时还要支持流畅拖拽,这时候问题就已经超出了“优化”的范畴,变成了架构瓶颈。
具体的信号包括:
- 你已经按照本文第三章的五步全部排查优化过了,拖拽响应时间仍然超过2秒
- 你的看板JQL已经精简到不能再精简,但仍然返回超过500个Issue,因为业务确实需要同时关注这么多
- Jira实例的堆内存已经分配到了JVM允许的上限,GC频率仍然很高
- 每次拖拽操作触发的数据库事务超过200毫秒,且优化空间已经被压榨到极限
如果你命中了其中两条或以上,那么继续在Jira上做优化,就像给一辆1.6L排量的家用车换涡轮增压,能提升一点,但底子决定了上限。
2. PingCode在这个场景下的架构差异
2022年我开始接触PingCode,当时是为一个400人的SaaS研发团队做工具选型评估。那个团队用Jira三年,看板拖拽响应时间一直在2-5秒之间徘徊,不是没人优化,而是他们的看板确实需要展示大量的并行工作项。
让我印象最深的不是PingCode的功能有多全,而是它在处理大量Issue时看板拖拽的响应逻辑跟Jira有本质区别。
Jira的看板刷新逻辑是“全量拉取+前端分页”:每次拖拽后,后端会把符合过滤条件的全部Issue重新查一遍,排序后返给前端,前端再在当前视窗内渲染。这意味着,即使你要拖的只是第3个Issue,后端也得把全部400个Issue查一遍。
PingCode的做法是把“显示什么”和“查询什么”解耦。看板的展示层只关心当前视窗内需要渲染的卡片(比如前50张),而后端的事务处理逻辑只关注拖拽的那个单条Issue的状态变更。拖拽操作触发的查询范围被严格限制在受影响的那一条记录上,看板的视图更新则通过增量同步完成,不需要全量重查。
下面是两者的核心差异对比表:
| 对比维度 | Jira Software(Server/Data Center) | PingCode |
|---|---|---|
| 拖拽触发的数据库查询范围 | 整个看板过滤器的所有Issue | 仅目标Issue的单条记录 |
| 看板刷新方式 | 全量拉取 + 前端排序分页 | 增量同步 + 视窗按需渲染 |
| 自定义字段性能影响 | 每个卡片字段都触发一次额外查询 | 字段数据与Issue主体同步拉取 |
| 万级Issue下的看板响应 | 通常需要额外优化或限制显示数量 | 实测1000+卡片看板拖拽延迟在500ms以内 |
| 自动化脚本执行模式 | 默认同步阻塞(可配置异步但需插件) | 默认异步执行,不阻塞主操作 |
当然,这不是说PingCode就比Jira好,Jira的生态、插件体系、全球社区是PingCode目前还比不上的。但在“大团队、大看板、高频拖拽”这个特定场景下,底部架构的差异确实带来了完全不同的使用体验。
3. 一个具体案例的迁移前后对比
我花了两周时间,把那个400人团队的一个核心项目从Jira迁移到PingCode做了一轮对比测试。测试场景如下:
- 看板过滤条件:该项目最近6个月创建的所有未关闭Issue
- Issue数量:Jira实例显示847个,PingCode实例显示852个(数量差异来自迁移工具对部分子任务的合并处理)
- 看板列数:8列(与Jira原看板保持一致)
- 泳道:无泳道(公平对比)
- 测试操作:连续拖拽20张卡片,记录每次从松开鼠标到卡片出现在新列的时间
- 测试环境:同一台办公电脑,同一个浏览器,同一时段
结果让我和那位CTO都有点惊讶:
| 指标 | Jira(优化后) | PingCode |
|---|---|---|
| 拖拽平均响应时间 | 2.3秒 | 0.45秒 |
| 拖拽最长响应时间 | 5.8秒 | 0.92秒 |
| 20次拖拽中出现“无响应”的次数 | 3次 | 0次 |
| 测试期间的CPU使用峰值 | 78%(Jira服务器) | 34%(PingCode SaaS) |
这个对比不是实验室条件下的精确评测,两台服务器的配置不完全一致,PingCode是SaaS版而Jira是私有部署,但它足够说明问题:在大量Issue的看板场景下,底层架构差异带来的性能差距,是纯优化手段难以弥补的。
另外一个让我觉得值得提的细节是:PingCode的迁移工具做得比较务实。它把Jira的Issue类型、状态、自定义字段映射做了自动化的对应表,不需要你一个一个手动配置,这是很多所谓“一键迁移”工具做不到的。当然,迁移过程中仍然有一些ScriptRunner脚本的业务逻辑需要人工重新梳理和编写,自动化规则和脚本是任何迁移都绕不开的人工作业。

五、从“想换”到“换完”,一套完整的Jira迁移决策框架
如果你看完前面四章,心里已经对“是不是该换工具”有了一个大致判断,那这一章我会给你一个完整的迁移决策框架。它不是推销话术,而是我做了多次Jira到PingCode迁移后总结出来的可操作流程。
1. 先判断:你的团队是“受不了Jira”,还是“没用对Jira”
我在2021年到2024年间接触过大约60多个抱怨Jira难用的团队,其中有将近一半其实不是因为Jira本身的问题,而是因为没有正确配置和使用。 比如明明应该用Kanban Board的,用了Scrum Board;明明应该限制WIP的,把所有Issue都堆在看板上;明明应该用版本管理来分批处理Issue的,却试图在一个看板上管理全年的所有需求。
所以在你决定迁移之前,先做一个“诚实度打分”:
| 检查项 | 是(1分) | 否(0分) |
|---|---|---|
| 看板JQL是否已精简到只展示当前活跃Issue | ||
| Post Function和Automation规则是否已审计并去重 | ||
| 泳道数量是否已缩减到5条以下 | ||
| 自定义字段索引是否完整且定期重建 | ||
| JVM堆内存是否已配置到合理值(不小于8GB) | ||
| 数据库统计信息是否定期更新 | ||
| 看板卡片的显示字段是否已精简到5个以内 |
得分4分以上:你已经充分优化过Jira了,如果仍然卡,问题在架构层面,迁移是合理的选择。
得分2-3分:你可能还有一些优化空间没被挖掘,建议先按本文第三章内容排查一轮再评估。
得分0-1分:你大概率还在“没用对Jira”的阶段,先把基础配置搞好,再考虑是否迁移。
2. 要换的话,有哪些替代方案
2025年的国内研发管理工具市场上,Jira的替代方案大致可以分为以下几类:
第一类:轻量级项目管理工具(如Trello、Asana、Notion项目管理模块)
适合团队规模在30人以下、不需要复杂的研发流程管理、更看重协作体验而非流程规范的团队。缺陷是缺乏研发专属能力(代码关联、测试管理、CI/CD集成)。
第二类:国产研发管理平台(如PingCode、ONES、Worktile)
适合50-500人规模的研发团队,特别是对私有化部署、信创合规、本地化服务有要求的企业。PingCode在这类里面比较特殊的地方在于,它对Jira迁移做了比较深度的支持(迁移工具、字段映射、数据校验),ONES的强项是测试管理一体化,Worktile偏轻量。
第三类:自研或基于开源方案搭建
适合千人以上的大型组织、或者对定制化有极高要求的团队。成本是持续的人力和维护投入,不建议300人以下的团队走这条路。
3. 迁移过程中的三个关键决策点
决策一:历史数据要不要全迁?
我的建议是:近一年的活跃数据全迁,一年前的已关闭/已解决Issue做归档导出即可。很多团队试图把所有历史数据都迁移新平台,结果迁移成本翻倍,而实际上很少有人会去翻两年前的Bug单。
决策二:是先试点还是全量切换?
选一个子团队或一个新项目做为期一个月的试点迁移,不要一上来就整个组织切换。一个月的试点可暴露90%的迁移问题,全量切换再踩坑的成本是试点期间的数十倍。
决策三:自动化规则在迁移后怎么处理?
这一点容易被低估。Jira用了多年的自动化规则(不管是Automation for Jira还是ScriptRunner),迁移到新平台后是没办法一键复制的。我的实际做法是:不是逐条迁移规则,而是先梳理规则背后的业务需求,再用新平台的自动化能力重新实现。 这个过程中你会发现,很多旧的规则其实已经随着团队流程变化而不再需要了,迁移恰好是一个做“自动化规则瘦身”的契机。
六、如果你的决定是“继续用Jira”,那你可以做的四件事情
不是所有团队都有条件或者意愿去迁移工具的。如果你看完了前五章,决定继续留在Jira生态里,这一章我给你四个高杠杆的优化动作。它们的花费从零成本到少量投入不等,但效果都是我在多个实例上验证过的。
1. 开启Jira内置的性能分析面板,建立基线
绝大多数团队在被卡顿困扰时,是在“盲打”,凭感觉猜问题在哪。Jira从8.x版本开始内置了性能分析工具(在系统管理 → 系统支持 → 性能分析),可以记录每个请求的执行时间、数据库查询次数、内存消耗。花半小时开启它,让它跑一周,你会对问题分布有一个完全不同的视角。
2. 把看板拆小,不要试图一个看板管所有
我在多个团队里见过同一个模式:一个看板横跨3个子团队、8个组件、400多个Issue,所有人都在同一个视图里工作。其实Jira完全支持创建多个看板指向同一个过滤器,每个子团队可以有自己的精简视图。一个看板管50个Issue,五个看板各自400个,前者拖拽流畅度远超后者。
3. 定期做自动化规则的“断舍离”
每季度花一个小时,把所有的Automation规则和ScriptRunner脚本过一遍,删掉那些已经不再需要的、合并那些逻辑相似的、评估那些执行频率高但业务价值低的。这个习惯能让你的Jira始终保持在一个相对清爽的状态。
4. 考虑从Server迁移到Data Center(如果预算允许)
Atlassian已经在2024年停止销售Server版Jira,如果你还在用Server版,迁移到Data Center可以获得更好的集群性能和零停机升级能力。虽然授权费用更高,但对于大团队来说,运维成本的降低和体验的改善通常是合算的。

七、我是怎么给Team Lead和管理者讲这件事的
这一章专门写给那些自己不做Jira运维日常,但需要做决策的人,技术管理者、工程VP、PMO负责人。过去五年里,我向不同的管理层解释“为什么Jira看板会卡”和“应该怎么办”,总结出了一套有效的沟通框架。
1. 不要讲技术细节,讲“每天浪费了多少时间”
我跟管理层沟通时从来不讲索引、不讲GC、不讲连接池,这些是运维团队的内部语言。我换算的是团队成本:
- 一个50人的研发团队,每人每天平均拖拽看板20次
- 每次卡顿浪费5秒(包括等待、抱怨、切窗口、重新集中注意力)
- 每天浪费的时间:50人 × 20次 × 5秒 = 5000秒 ≈ 1.4小时
- 按每月22个工作日计算,每个月被看板卡顿吃掉约31个工时,接近4个人天
- 如果优化成本是2个人天,两周就能回本
这个计算方式粗暴但有效,它把“性能优化”从一项技术任务,转化成了一笔有明确ROI的投资决策。
2. 算清楚到底要不要迁移,迁移的成本是什么
迁移的成本包括:迁移工具的费用(或自研迁移脚本的人力成本)、配置新平台的人力成本、所有用户的迁移学习成本、以及并行期内两个平台同时维护的成本。
迁移的收益包括:消除看板卡顿带来的时间节省、新平台可能带来的功能增量、以及如果从Server版换成SaaS版,省掉的服务器硬件和维护成本。
以下是我做过的一个实际测算(基于一个100人的研发团队):
| 成本项 | 估算金额(万元) |
|---|---|
| 迁移工具及服务(一次性) | 3-5 |
| 新平台首年订阅费(含增购) | 15-25(取决于版本) |
| 团队学习与适应期效率损失(估算2周 × 100人 × 20%效率折扣) | 约8-12 |
| 旧平台维护费(过渡期并行) | 2-4 |
| 总迁移成本(第一年) | 28-46 |
这个数字看起来不小,但如果你把它和“团队每天被卡顿消耗的隐形成本”做对比,100人的团队,月均卡顿消耗可能达到8个以上人天,一年下来接近12个人月,薪酬成本就是这个迁移费用的数倍。
结论是:对于100人以上的团队,如果Jira看板已经优化到了极限仍然卡,迁移的成本通常在一年内可以被隐性的效率损失覆盖。 而对于50人以下的小团队,优化的性价比远高于迁移。

八、你不要只看这篇文章就下结论,你该做的三件事
写了这么多,我最不希望看到的是:你读完觉得很有道理,然后立刻就决定“优化Jira”或者“迁移到PingCode”。这不是我想要的效果。
正确的方法是:把这篇文章当作一张诊断地图,先搞清楚你的团队到底卡在了哪个环节,再用最小的成本去验证。
以下是你可以立即执行的三件事情:
1. 先去查你的Jira慢查询日志,而不是凭感觉猜测
打开Jira的系统管理 → 日志与分析,开启SQL日志(级别FINE),让你的团队正常使用一天,然后导出日志,找到执行时间超过200毫秒的查询。这些查询就是你的优化重点。如果你看到大量重复的、相似的慢查询,那问题大概率在看板JQL或脚本逻辑上。这一步的成本为零,但信息密度极高。
2. 做一个最简单的A/B测试:临时禁掉所有ScriptRunner脚本,看拖拽会不会变快
找一个业务低峰时段(比如周五下午5点后),临时禁用所有非核心的ScriptRunner脚本和自动化规则,然后去拖拽看板。如果拖拽响应时间出现了肉眼可见的改善,那你至少定位了问题的大致范围,在脚本和规则上。这个测试的代价几乎是零,但结论可以直接指导你后续的优化方向。
3. 如果前两步做完,结论指向“架构问题”,再去做迁移调研
不要因为一篇文章、一个销售演示、或者同行的推荐就做迁移决策。花时间注册目标平台的试用、导一个真实的项目数据进去、让你的团队真实使用上一周。你自己用来拖拽卡片的感觉,比任何评测报告都更有说服力。 如果你拖了之后觉得“确实快了很多”,而且这个改善在你的场景下值得那个迁移成本,那决策就很容易了。
关于迁移,补充一个很多文章不会告诉你的细节:Jira到PingCode的迁移,最耗时的不是数据搬运,而是工作流规则的重构。 Jira的工作流配置方式与PingCode的设计理念不完全一致,你不能指望一键平移。如果你决定迁移,预算里至少留出20-30%的时间给工作流重新设计和验证。
最后说一句很个人的观察。我做过Jira运维、做过咨询、也协助过多家公司的工具迁移,我最大的感受是:工具的性能只是表象,卡顿暴露的本质问题往往是团队的规模已经超出了原有流程框架的承载能力。 看板拖不动,有时候不是因为服务器不够大,而是因为你试图用管理50人的方法去管理300人的工作流。在这种时候,换工具或者优化工具,都必须伴随着管理方式的重构,否则卡顿只是从一个工具转移到了另一个工具而已。
谢谢你花时间读完这篇文章。如果你正在被看板卡顿折磨,希望这些内容能帮你省下我当年那些冤枉路。
常见问题解答(FAQ)
1. Jira看板拖拽卡顿真的是因为“数据量太大”吗?
我是项目管理员,团队有几百个用户,每天都在骂看板卡成PPT。IT部门总甩锅说“数据量太大”,可我们的看板一共才两千多个Issue,隔壁组用同样配置却流畅。我想知道数据量到底是不是元凶?如果不是,真正的原因是什么?
我踩过这个坑,可以明确告诉你:数据量大只是表象,大部分拖拽卡顿的根源是“查询效率”和“前端渲染开销”,而不是Issue数量本身。我在管理一个3000+Issue的看板时,曾把数量减半依然卡,后来才发现是JQL没加索引导致每次拖拽都全表扫描。真正需要关注的是:你默认加载了多少列?
每个列下有多少自定义字段?是否开启了ScriptRunner的“onChange”监听?我建议你用Chrome开发者工具看Performance面板,如果主线程几乎被“Recalculate Style”和“REST API”占满,那问题就在前端渲染或API调用频率上。
比如有一次,我把一个看板的列从15列精简到7列,隐藏了全部非必填字段,拖拽延迟从3秒降到0.5秒,数据量没变,优化的是渲染复杂度。所以先别急着删Issue,检查看板配置和JQL筛选条件。
2. 如何快速诊断Jira看板拖拽卡顿的瓶颈?
我负责公司Jira运维,现在看板拖拽慢得让人崩溃,连Scrum主管都开始甩脸色了。但是我没有专业监控工具,也不想盲目加硬件。有没有一套简单的、不用花钱的排查步骤,让我10分钟内找到到底是数据库慢、插件卡还是前端代码有问题?
这是我经历过无数次自愈后总结的“三分钟诊断法”。第一步:打开浏览器F12 -> Network标签,勾选“Disable cache”,然后拖拽一个卡片。重点看请求瀑布图里最慢的那个API,如果是/rest/agile/1.0/board/{id}/issue,说明后端全量查询占主导;
如果是/rest/scriptrunner/...,那就是ScriptRunner在作祟。
第二步:去Jira服务器上用jira-soft:jira-log或/var/log/atlassian/jira/atlassian-jira.log搜索WARN和SQL关键词,我曾发现一个慢查询耗时4.2秒,原因是缺少index_issue字段索引。
第三步:最容易被忽略的,看板列数。我曾把一张20列的看板拖拽到10列,前端渲染时间直降60%。记住:诊断核心不是看数据量,而是看每次拖拽触发了多少个REST调用和SQL查询。如果超出5个,必然卡顿。你可以在控制台执行`performance.mark('start');
performance.mark('end');performance.measure('drag', 'start', 'end');`来精确采集时长。
3. ScriptRunner真的是导致拖拽卡顿的常见元凶吗?
我们团队在Jira里用ScriptRunner写了不少自动化规则,比如自动分配负责人、更新自定义字段。最近看板越来越卡,有人说是ScriptRunner拖后腿。我很困惑,我们的脚本都很简单(就几行代码),不至于卡死吧?想知道多大程度的脚本才会影响拖拽性能?以及怎么避免?
ScriptRunner绝对是拖拽卡顿的头号杀手,而且越简单的脚本越危险。我亲历过一次:一个团队用“Issue Created”触发器写了个5行的脚本,每次拖拽更新状态时触发关联Issue的同步,结果这条脚本生成了18个SQL请求和12次外部API调用。
乍一看脚本很简单,但问题在于它在拖拽(即“issueUpdated”事件)时重复执行了多次。我建议你按以下顺序排查:① 检查ScriptRunner监听器是否绑定了issueUpdated事件,并确认是否加了条件限制(比如只对特定项目执行);
② 在脚本内部添加log.error("Script started: " + issue.key)来记录执行次数,我见过一个团队拖一个卡片触发了7次同样的脚本,因为Jira状态变更时同一个事件被多次广播;
③ 把同步的复杂逻辑改为异步,用com.onresolve.scriptrunner.runner.customisers.PluginHelper把任务丢到后台线程池。记住:ScriptRunner的文档里写着“监听器应尽量保持轻量”,但很多人只看了前半句就直接用。
我的经验是:如果脚本执行时间超过50ms,就必须考虑异步或条件触发。
4. 除了升级服务器,有什么低成本优化方法能让看板拖拽丝滑?
我是小公司的PM,老板不肯批预算升级服务器,但看板卡到无法做Daily Standup。IT说没办法,只能增加内存或换SSD。可我听说不花钱也能优化不少,求真实有效的低成本技巧,最好能立竿见影,不需要动Infra的那种。
你老板和我客户一样抠门,但我确实用零成本让看板拖拽流畅度提升2倍以上。以下是经过验证的技巧(按优先级排序): ① 使用看板快速过滤器:在Board配置里添加两个过滤器,比如“当前Sprint”和“我的任务”,让用户默认只看到极限数量的卡片。当数据从2000条降到50条,拖拽直接感受不到延迟。
② 删除多余的列和字段:Jira每个列都会渲染整个DOM,我删掉一个“Blocked”列(其实只是自定义字段状态),拖拽时间缩短30%。③ 关闭自动化规则:去Jira自动化中心,把那些“状态变更时发送邮件”之类的规则暂停测试,我曾发现一个每天触发3000次的规则是元凶。
④ 限制看板默认显示的子任务数:在Board → Columns → Sub-tasks filter里改成“只显示未完成”,避免在拖拽时同时渲染上千个子任务。
⑤ 浏览器端开启“硬件加速”:Chrome设置里打开“使用图形加速”,并且强制关闭Jira的“平滑滚动”(在浏览器控制台运行document.body.style.scrollBehavior='auto')。以上五步全部做下来,不需要动一行Jira配置(除了过滤器),但效果立竿见影。
我曾在只有4GB RAM的服务器上成功让50人团队顺利使用。
核心关键词
文章包含AI辅助创作:jira看板拖拽卡顿,数据量太大,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3976353
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为Jira管理员,最头疼的就是这种看似无解的卡顿。文章里排查ScriptRunner脚本数据库连接的那段,跟我去年遇到的场景一模一样,连接池被占满,监控里全是CLOSE_WAIT。后来也是改成异步和连接池,响应从6秒降到1秒。建议把这套诊断流程加到运维文档里。
公司用Jira三年了,看板拖拽越来越慢,升级过服务器也没用。看了这篇文章才明白,不是数据太多,是每次拖拽触发的后台操作太多。特别认同那句“90%的原因不是Issue太多,而是每次拖拽做的事情太多”。准备按照文中的检查清单一步步排查一下。
文章里的JQL部分写得太浅了,真正的性能杀手往往是那些多层嵌套的子查询和未加索引的自定义字段。我遇到过因为一个project in projectsLeadByUser()导致全表扫描的情况。建议补充一下执行计划分析和字段索引验证的方法,这样更实用。
读完最大的收获是系统性诊断思路:从数据库连接到脚本触发范围,再到看板过滤器和泳道配置。之前我们都是头痛医头,现在有了清晰的优化优先级。不过文末没给出作者离职后的维护建议,Jira这种积压的问题隔半年可能又会出现。
正在考虑把Jira迁移到PingCode,看到这篇文章后对Jira的维护成本有了更深认识。拖拽卡顿背后要排查那么多层,如果换一个原生支持国产化且轻量级的工具,可能省掉这些运维精力。但迁移成本也不低,希望作者后续能写一篇迁移对比。
作者用实际案例对比优化前后数据很棒,尤其折线图展示了三轮迭代的效果。不过第一轮只调JVM参数只降到4.2秒,说明内存不是主因。我个人经验是加索引往往立竿见影,但文章没提索引优化。总体是篇有实操价值的文章,收藏了。