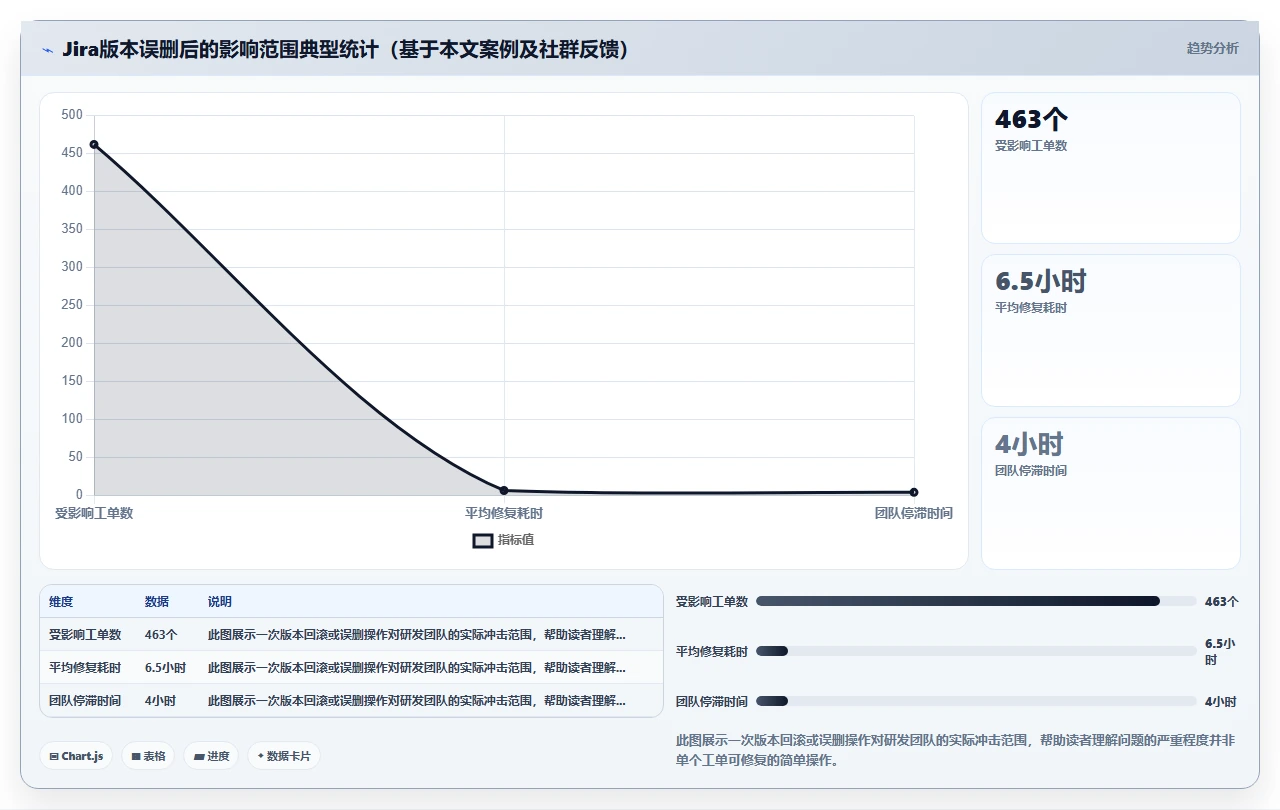
一、半夜两点,我亲手炸掉了 463 个工单的版本关联
那是 2023 年 11 月的一个深夜,我在给公司 Jira Server 做季度维护。原本计划很简单:清理一些废弃版本,给系统瘦身。我在版本管理页面勾选了十几个“看似没人用”的版本,点了删除。三十秒后,Scrum Master 的电话打进来:“你动了什么?整个 Sprint 的看板全乱了,工单上的修复版本显示‘关联已断开’,我们连哪些需求要上线都不知道了。”
我后背瞬间凉透。打开 Jira 一看,463 个工单的“修复版本”字段变成了灰色,后面跟着一串冰冷的 ID 数字:“关联已断开 [ID:10823]”。这不是一个工单的事,是整个项目团队的交付视图瘫痪了。
那天晚上我花了 4 个小时手动修复,第二天又拉着运维团队写脚本补了整整一天。事后复盘,我才意识到:Jira 的版本管理有一个巨大的暗坑,而市面上几乎所有教程都在回避它,版本不是字符串标签,它是一个实体对象。你删的不是名字,是一条数据库记录。关联到这条记录的所有工单字段,会瞬间变成“孤儿指针”。
这篇文章,是我用 463 个工单的代价换来的。我会把诊断过程、紧急恢复方案、常见误区,以及从根源上杜绝这个问题的预防策略,全部讲清楚。如果你正在管理 Jira 或者考虑迁移到国产替代方案(比如我们后来引入的 PingCode),这篇内容应该能帮你少踩一个足以让整个团队停摆的大坑。

二、核心结论先行:这不是 Bug,是 Jira 的数据模型设计使然
在深入展开之前,我先把这个问题的底层逻辑讲清楚。因为我发现,90% 的 Jira 管理员在第一次遇到这个问题时,第一反应是“系统出 Bug 了”。
不是的。这是 Jira 版本管理机制的必然行为。Jira 中的“版本”(Version)不是一个简单的文本标签,而是项目下的一个独立实体,拥有唯一的数据库 ID。当你在工单的“修复版本”或“影响版本”字段中选择某个版本时,工单存储的不是版本名称(如“v2.3.1”),而是版本实体的 ID。
这意味着两件事:
- 如果你删除了版本实体,所有引用该 ID 的工单字段立即失效,数据库层面留下的是指向不存在记录的外键,Jira 前端只能显示“关联已断开”。
- 如果你执行了数据库回滚(比如恢复到某个备份节点),版本实体可能被回退到一个更早的状态,但工单可能已经在回滚节点之后被修改过,新的工单引用的版本 ID 在回滚后的数据库中不存在,同样会造成关联断裂。
举个例子:你在 11 月 1 日创建了版本“Sprint 24”,Jira 给它的内部 ID 是 10823。Sprint 期间,团队把 50 个工单的修复版本都设成了 10823。11 月 5 日,你不小心删掉了这个版本,或者做了一次数据库回滚到 10 月 30 日的状态,10823 这条记录没了。那 50 个工单就会立刻变成断联状态,即使你重新手动创建一个同名版本“Sprint 24”,它的 ID 也变成了 10899,和原有工单的关联无法自动恢复。
所以,核心结论是:Jira 的版本关联问题本质上是实体引用断裂问题,不是界面显示问题。修复它的难度取决于你有多快发现问题、多早停止其他操作、以及你是否有备份或 API 脚本能力。
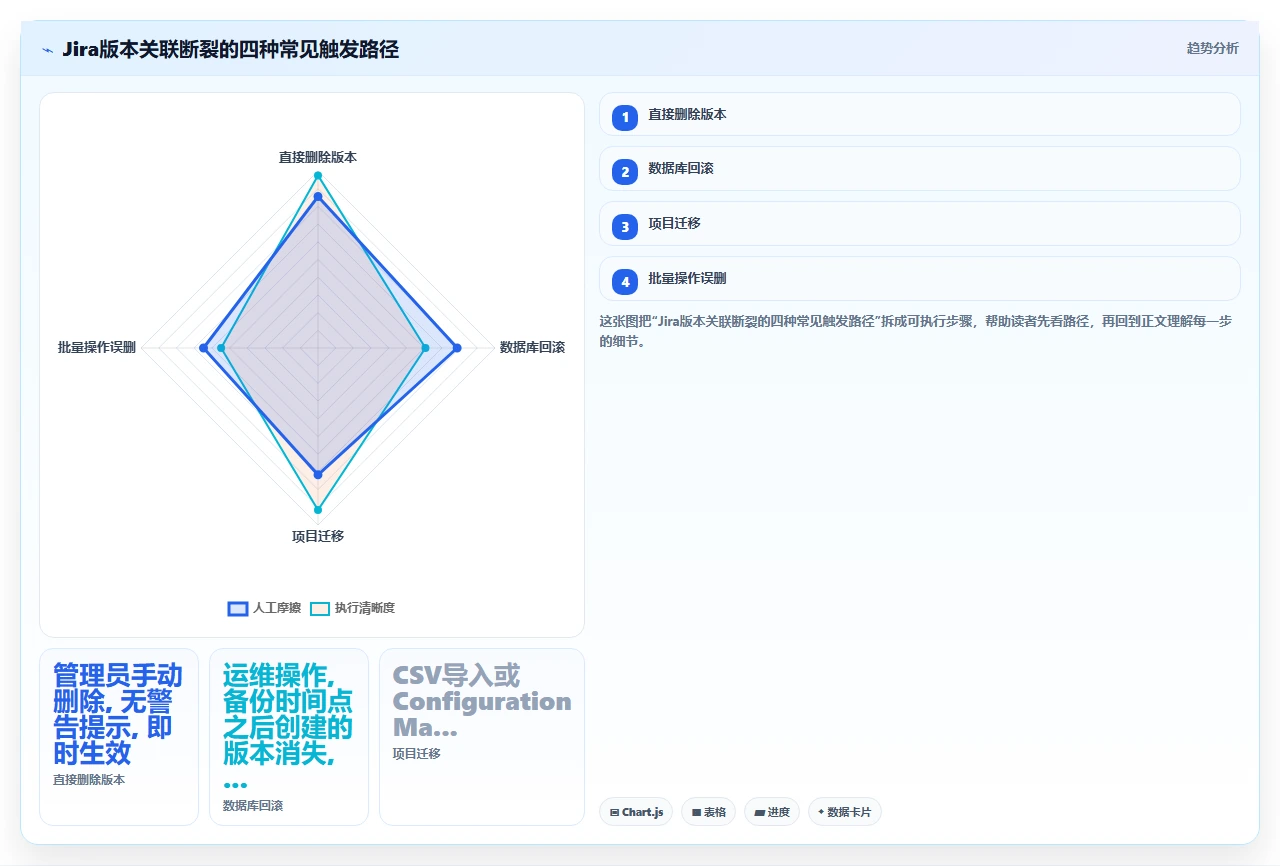
三、真实场景还原:哪些操作会触发这个灾难
我把过去三年在 Jira 运维中实际遇到和从社区收集到的触发场景做了归纳。这些场景有一个共同特点:操作者在执行的时候,Jira 不会给出任何警告。 你会觉得只是做了一件“常规管理操作”,直到用户反馈工单页面异常。
1. 直接删除版本
最直接也最“蠢”的场景,就是我踩过的坑。在项目设置 → 版本页面,选中版本然后点删除。Jira 只会弹出一个确认框问“你确定要删除吗?”,但它不会告诉你:“此操作将导致 463 个工单丢失版本关联,且不可通过界面撤销。”
2. 数据库级别的回滚或还原
这是中大型团队更容易遇到的情况。运维团队在做数据库维护时,可能会用 mysqldump 或 pg_dump 的备份文件恢复 Jira 数据库。如果备份文件的时间点早于某些版本的创建时间,恢复后这些版本就“凭空消失”了。更隐蔽的是:
- 工单数据是持续更新的,回滚后工单可能还在(因为工单的创建时间早于备份点),但版本记录是新的(晚于备份点),回滚后版本记录丢失。
- 所有在备份点之后关联到新版本的工单,都会在回滚后断开关联。
3. 合并或迁移项目时版本数据丢失
有团队在做 Jira 项目迁移(比如用 Configuration Manager 插件或 CSV 导入)时,如果版本映射配置不当,新项目中创建的版本会拥有不同的 ID。所有通过导入进来的工单,其版本字段可能因为无法匹配而变成空值或断联状态。
4. 误操作:在版本列表中“合并”或“移动”工单
某些批量操作插件允许你在版本视图中“将所有工单从版本 A 移动到版本 B”,然后删除版本 A。如果不小心勾选了错误的源版本和目标版本,批量操作完成后,源版本被删除,但目标版本关联也可能因为插件实现方式的问题部分丢失。
四、常见误区拆解:你以为是“修复”的操作,可能让事情更糟
在工单关联断裂之后,我和很多踩过同样坑的同行交流,发现大家的第一反应往往走向几个方向,而其中有相当一部分是无效甚至有害的。我把最常见的四个误区拆解清楚。
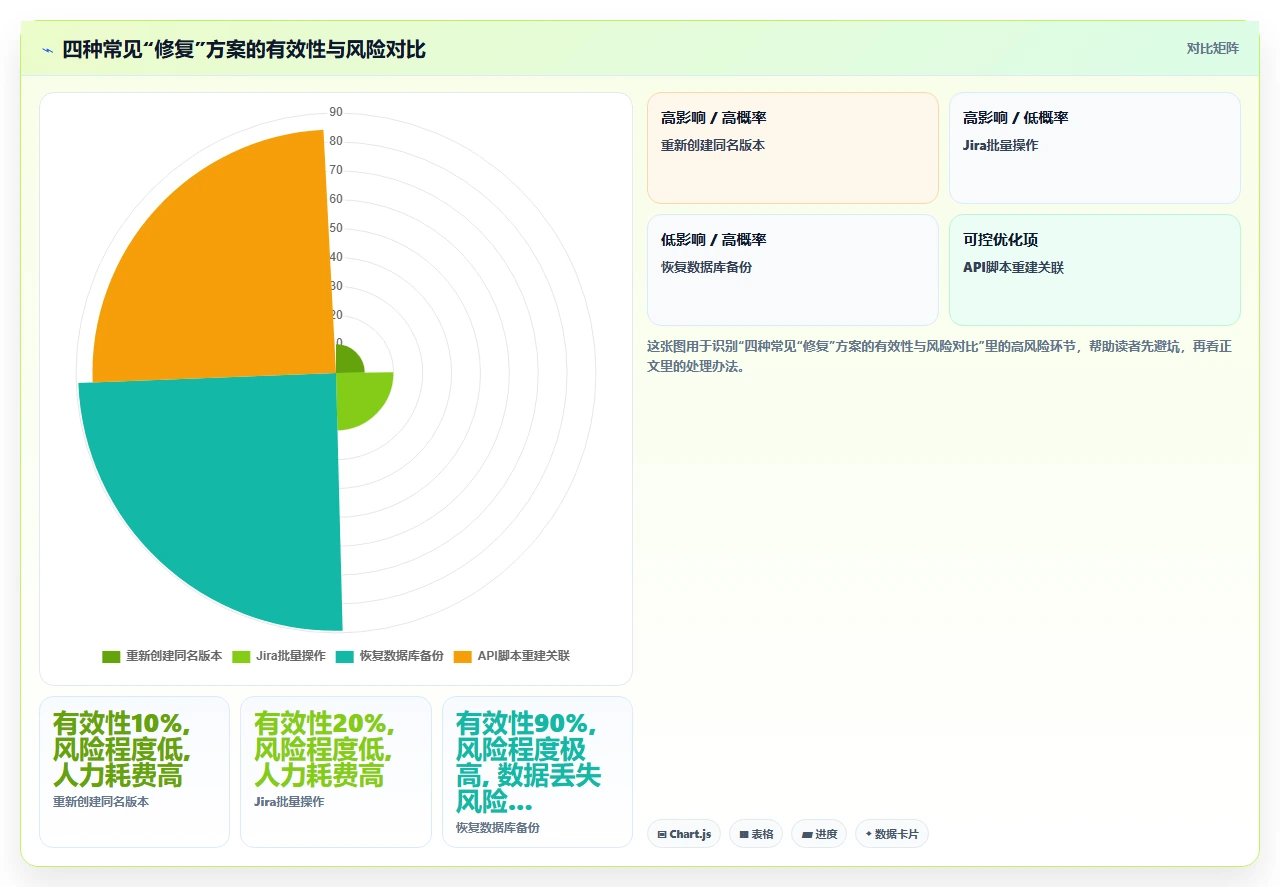
1. 误区:“我重新创建一个同名版本不就行了?”
不行。严格来说,这是最浪费时间也最具误导性的操作。 同名版本创建后,Jira 分配的是新的内部 ID。你的工单字段指向的仍然是旧的已删除 ID,所以不会自动恢复。你需要手动打开每一个断联工单,在修复版本字段中重新选择这个新版本,几百个工单的话,这可能需要几个人天。
更糟的是,如果你在操作过程中没有记录哪些工单原本关联了哪个版本,你甚至无法确认“之前是哪些工单受影响”。
2. 误区:“我可以用 Jira 批量操作恢复”
理论上,Jira 的“批量修改”功能可以批量修改工单的版本字段。但这里有一个致命的限制:如果原来的版本实体已经被删除,工单的版本字段显示的只是“关联已断开”,而不是一个可被批量操作选中的目标。 也就是说,你无法在批量操作界面中“找到”那些断联工单并按版本重新设置,因为 Jira 无法识别它们“之前”关联了哪个版本。
只有当版本实体仍然存在(比如你只是误删了部分关联,而版本本身还在),批量操作才能有效。可一旦发生“关联已断开”的显示,说明版本实体已经不存在了。
3. 误区:“从备份恢复 Jira 就行了”
这是最危险的误区。如果你用 XML 备份或数据库备份恢复整个 Jira 实例,确实可以恢复到删除版本之前的状态。但代价是:备份时间点之后产生的所有数据都会丢失。 包括新创建的工单、评论、附件、工作日志、代码提交关联,全没了。
现实中,很少有团队能承受这种损失。所以数据库回滚不是一个“修复方案”,而是一个“时间窗口置换方案”,你用一种破坏换另一种破坏。除非你属于以下情况:
- 发现得很早(操作后几分钟内),并且期间没有任何重要数据写入。
- 你有一个接近实时的数据库备份,并且可以接受少量数据丢失。
大多数情况,恢复备份是最坏的选择之一。
4. 误区:“一定是 Jira 的 Bug,等 Atlassian 修复”
正如我在第二部分解释的,这是 Jira 数据模型设计的固有行为,Atlassian 不会把它当成 Bug 修复。在 Jira 官方的文档中,版本删除是一个“破坏性操作”,他们只会建议你在删除前手动检查关联工单,但这个提示只存在于文档的角落,不体现在操作界面上。
五、专业判断逻辑:如何诊断断裂范围与修复可行性
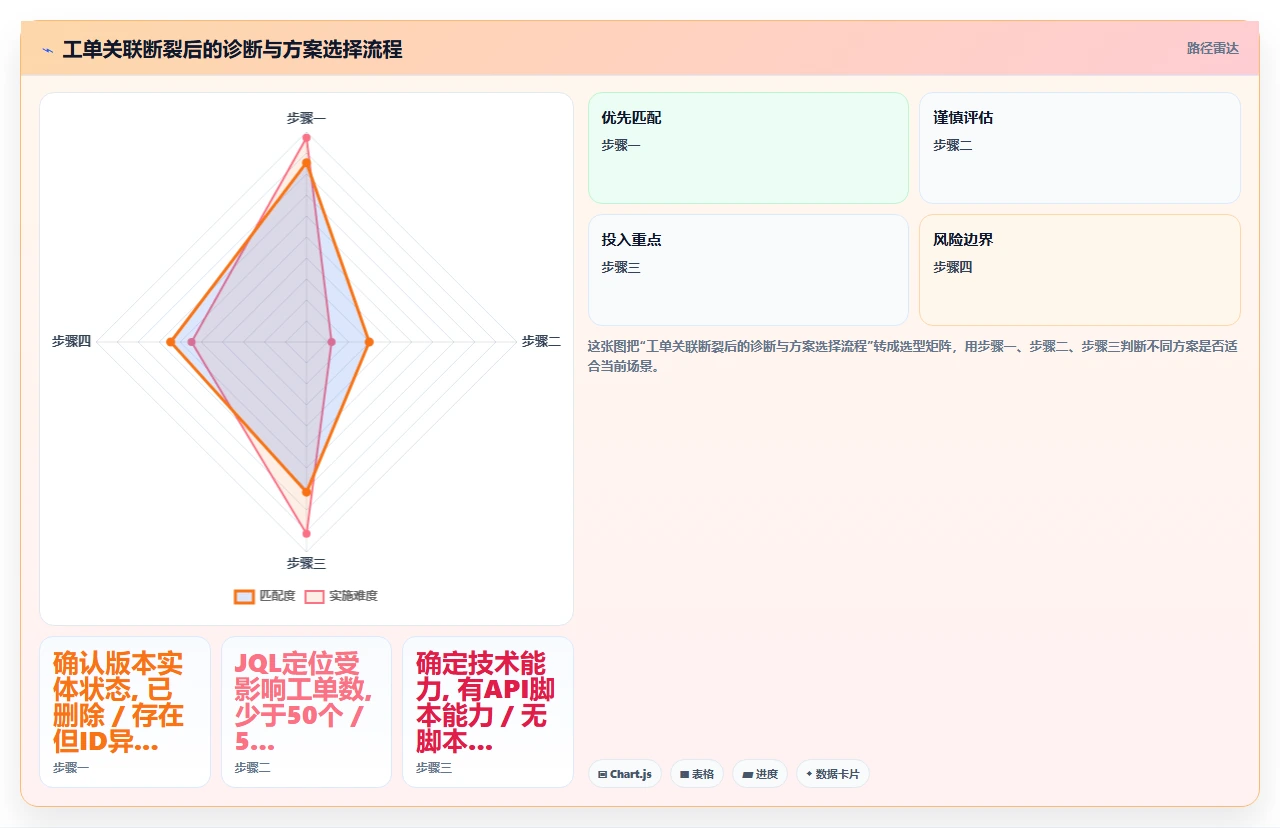
当工单关联断裂已经发生时,你的第一步不是动手修,而是快速诊断。我总结了一套在半小时内完成影响评估的判断流程。
1. 确定版本实体的状态:是“被删除”还是“ID 漂移”?
登录 Jira,进入管理后台 → 项目 → 版本。对照之前版本的名称列表,确认:
- 版本实体彻底消失:说明被删除或数据库回滚导致丢失。
- 版本实体存在但名称/描述变了:可能发生了 ID 漂移(比如迁移或手动修改导致新旧版本混淆)。
- 版本实体存在但部分工单关联丢失:可能是部分工单的数据在迁移中被截断。
不同的状态决定后续修复策略。实体消失是最难处理的,只能用 API 脚本按历史记录重建。实体存在但关联丢失,可以在有备份数据的情况下用批量操作修复。
2. 用 JQL 精准锁定受影响工单
即使工单的版本字段显示“关联已断开”,Jira 的 JQL 仍然有一些间接方式帮你定位:
方法一:查询修复版本为空的工单
project = "YOUR_PROJECT" AND fixVersion IS EMPTY AND created >= "2023-10-01"
加上创建时间限制,可以过滤掉那些真正没有分配修复版本的老工单,聚焦在最近可能受影响的范围内。
方法二:结合 Sprint 范围缩小
project = "YOUR_PROJECT" AND fixVersion IS EMPTY AND sprint in openSprints()
或者用 Sprint 名称:
project = "YOUR_PROJECT" AND fixVersion IS EMPTY AND sprint = "Sprint 24"
方法三:利用 Jira 的变更历史(Changelog)
这是最准确但需要额外工具的方法。通过 Jira REST API 查询工单的变更历史,可以找到版本字段的变化记录:
GET /rest/api/2/issue/{issueKey}?expand=changelog
在 changelog 中搜索 field 为 “Fix Version” 的条目,可以看到该工单历史关联过的版本名称。遍历所有可疑工单后,汇总出受影响工单和它们理应关联的版本名称。
3. 评估团队可承受的恢复方案
做完诊断之后,根据以下矩阵做决策:
| 受影响工单数量 | 版本实体状态 | 推荐方案 | 预计恢复时间 |
|---|---|---|---|
| < 50 | 已删除 | 手动逐个修复 | 1-2 小时 |
| < 50 | 存在但关联丢失 | 批量操作修复 | 30 分钟 |
| 50-300 | 已删除 | API 脚本修复 | 3-6 小时(含脚本编写和测试) |
| > 300 | 已删除 | API 脚本 + 团队成员验证 | 1-2 天 |
| 任意 | 不确定 | 先做完整诊断,不要动手 | 诊断耗时 1-2 小时 |
六、我的具体案例:PingCode 如何帮我们避开了这个系统性风险
在上面那起事故之后,我们的运维流程确实做了大幅改进:增加了版本删除的审批流程,写好了 API 预案脚本,甚至在大版本发布前强制备份。但老实说,这件事暴露出的是 Jira 数据模型的根本性设计问题,它把“版本”这个高频使用的业务实体和底层数据库 ID 做了硬绑定,而这种绑定在界面层完全不可见。
2024 年初,我们公司(约 200 人的研发团队)开始评估 Jira 的国产替代方案。其中一个重要的评估维度就是:版本管理会不会再出现类似的“孤儿数据”问题。
最终我们选择了 PingCode。下面以我们的实际迁移和使用经历来说明 PingCode 在这个问题上是如何从机制层面规避的。
1. 版本关联的本质差异:标签 vs 实体
PingCode 的工作项管理中,版本被设计为标签式属性而非独立实体。这意味着:
- 工作项存储的是版本名称字符串(如“v2.3.1”),而不是一个隐藏的数据库 ID。
- 如果你删除了一个版本标签,工作项上只是该字段被清空,不会出现“关联已断开”这种无法追溯的状态。
- 你可以随时重新创建一个同名版本标签,通过批量编辑功能一键恢复关联,因为匹配逻辑是字符串相等,而非 ID 映射。
这个设计差异在实际操作中的感受非常明显。我在 PingCode 中做过测试:创建版本“Sprint 25”,给 100 个工作项打上标签,然后删掉版本标签,再重新创建一个同名标签。通过批量编辑,100 个工作项的关联在 5 分钟内全部恢复,且不需要任何脚本。
2. 迁移过程中的版本数据保护
我们从 Jira 迁移到 PingCode 时,最担心的就是版本数据在迁移过程中丢失。PingCode 的迁移工具提供了以下保护:
- 版本字段映射:支持将 Jira 的修复版本、影响版本字段直接映射为 PingCode 的自定义标签字段,迁移过程中名称保持不变。
- 迁移日志可视化:在迁移过程中,可以看到每个工作项的版本字段映射结果,如果某个版本未能正确映射,会在日志中清晰标注,而不是静默丢失。
- 迁移后验证:提供迁移完成后的数据一致性检查报告,我们 12,000 多个工作项中只有 3 个出现版本字段为空的情况,原因都是 Jira 端原数据已损坏,而非迁移工具导致。
3. 对于 100 人以上团队的额外收益
除了规避版本断裂问题,PingCode 在我们这种规模团队下还带来了几个额外的管理收益:
- 不需要插件就能实现 Jira 需要插件才能做的版本报表:PingCode 内置了版本燃尽图、版本进度看板,不需要像 Jira 那样依赖 EazyBI 或其他报表插件。
- 与国内办公平台的集成降低了版本通知成本:版本发布时,PingCode 可以直接通过企业微信/飞书/钉钉推送版本发布说明,研发和产品团队能实时收到通知,而不需要登录 Jira 查看。
- 版本权限的审批流机制:PingCode 支持版本删除操作的审批流程配置,关键版本需要项目负责人审批后才能删除,从流程上杜绝了误删风险。我们在 Jira 上是用第三方插件做的审批,但那个插件在我们踩坑的时候刚好没生效。
七、不同场景下的行动建议:你现在该做什么
根据你所在团队的具体情况,我把行动建议分为三个场景给出。
1. 场景 A:你的 Jira 还没有出过事,但你想预防
立即执行以下操作(30 分钟内完成):
- 检查版本列表: 进入每个项目的版本管理页面,确认是否有“僵尸版本”,创建后从未被任何工单引用的版本。这类版本是误删的高风险操作对象,因为管理员会误判它们“没用”。
- 设置版本删除权限: 在 Jira 的权限方案中,将“删除版本”权限仅授予项目管理员,普通团队成员不应拥有此权限。如果团队需要定期清理版本,设定审批流程。
- 建立版本命名规范: 永远不要用临时名称创建版本(如“test”、“临时版本”),因为这类版本容易在清理中被误删。建议使用标准化命名如“Sprint-2024-Q1-01”或“Release-v2.3.1”。
- 每周执行一次版本关联巡检: 使用以下 JQL 脚本,查找所有修复版本为空的近期工单并推送报告:
project = "YOUR_PROJECT" AND fixVersion IS EMPTY AND created >= -14d ORDER BY created DESC
2. 场景 B:你正在经历工单关联断裂,需要紧急修复
请严格按照以下步骤操作:
- 立即通知所有团队成员停止在 Jira 上操作工单,特别是修改版本字段。如果有人在不知道的情况下手动调整了版本,会增加事后批量修复的复杂度。
- 按照本文第四部分的诊断逻辑,确认版本实体状态和受影响工单范围。
- 如果你有 Jira 的 Changelog 数据(默认 Jira 会保留变更历史),可以通过 REST API 拉取受影响工单的历史版本信息。脚本思路如下(Python 示例):
import requests
from requests.auth import HTTPBasicAuth
假设你已通过 JQL 拿到了受影响工单列表
issue_keys = ["PROJ-1001", "PROJ-1002", "PROJ-1003"]
jira_url = "https://your-domain.atlassian.net"
for key in issue_keys:
response = requests.get(
f"{jira_url}/rest/api/2/issue/{key}?expand=changelog",
auth=HTTPBasicAuth("email", "api_token")
)
changelog = response.json()["changelog"]["histories"]
for history in changelog:
for item in history["items"]:
if item["field"] == "Fix Version":
print(f"{key}: {item['fromString']} -> {item['toString']}")
- 根据 Changelog 数据重建映射表(工单 Key → 应关联的版本名称),然后用 REST API 批量更新:
PUT /rest/api/2/issue/{issueKey}
{
"update": {
"fixVersions": [{"name": "Sprint-24"}]
}
}
注意: API 更新会触发 Jira 的通知邮件,如果工单量很大,提前和团队沟通好。建议先在测试环境或一个工单上验证脚本正确性。
3. 场景 C:你正在评估离开 Jira,考虑国产替代方案
如果你像我们一样,已经受够了 Jira 的这类暗坑,可以重点考察以下几个方面:
- 数据模型的健壮性:版本、模块、标签等常用属性是实体关联还是标签关联?删除操作的影响范围是什么?操作界面是否有明确的警告?
- 迁移工具的数据保护能力:是否能保证版本字段在迁移过程中不丢失?是否有迁移日志可以审核?
- 权限和审批流:关键操作(删版本、删项目、改工作流)是否有审批流机制,还是仅仅依赖管理员的自觉?
- 中大型团队的适配程度:对于我们这种 100 人以上的组织,工具是否能支撑多项目并行的版本管理,而不是让人在项目间来回切换?
我们选择 PingCode 的核心原因,除了上文提到的版本机制差异外,还因为它对 100 人以上中大型组织的支持做得相对成熟:多项目版本视图、跨项目的版本依赖关系图、以及与研发流水线的深度集成,这些在 Jira 中需要用多个插件拼凑的功能,PingCode 是一体化的。
八、不同情况下的取舍:修复、忍受、还是迁移
不是所有团队在经历了版本断裂之后都应该立刻迁移工具。根据我们的实际经验和与同行交流的数据,这里给出一个更务实的取舍框架。
1. 选择留在 Jira 并加强流程管控(适合以下情况)
- 团队规模在 50 人以下,版本数量可控,不存在多项目交叉依赖。
- 公司已有完善的 Jira 运维体系(专职管理员、备份策略、审批流程),偶发的版本断裂可以在 1-2 小时内手动修复。
- 团队对 Jira 的使用深度不高,基本停留在“一个项目一个看板”的层面,版本只是用于标记发布号。
留在 Jira 的代价: 你需要持续投入运维人力维护防错机制。我们团队在事故之后,每个月大约要花 2-4 小时做版本巡检和权限审计。对于一个小团队来说,这可能是一个专职管理员半小时的工作量,还能承受。
2. 选择部分迁移到更安全的工具(适合以下情况)
- 团队规模在 50-150 人,多项目并行,版本管理复杂度上升,但核心研发流程依赖 Jira 的某些独特功能(如高级 JQL、特定插件)。
- 你可以先在新项目中使用替代工具(如 PingCode),老项目继续跑在 Jira 上,通过 API 或 Webhook 做数据同步。等新工具验证稳定后,再逐步迁移历史项目。
部分迁移的代价: 一段时间内需要维护两套工具,团队有上下文切换成本。但相比一次性全量迁移的风险,这种渐进式过渡更容易被技术和业务团队接受。
3. 选择全面迁移到国产研发管理平台(适合以下情况)
- 团队规模在 100 人以上,已经多次被 Jira 的维护问题(插件兼容性、版本断裂、权限失控、Server 停售等)拖累。
- 公司有明确的国产化或信创合规要求,或者需要工具能部署在本地服务器、适配国产操作系统。
- 你希望用一个工具覆盖产品管理、项目管理、测试管理、知识管理,而不是用 Jira + Confluence + Zephyr + EazyBI 拼凑。
全面迁移的代价: 迁移项目本身需要 2-6 周(取决于数据量和流程复杂度),并且需要 1-2 个 Sprint 的适应期。但这个成本是一次性的。以我们团队为例,迁移到 PingCode 后,版本管理的维护时间从每月 2-4 小时降到了基本为零,因为不需要做防错巡检,审批流已经帮我们挡住了所有的风险操作。

九、一个更根本的反思:工具应该是护栏,而不是陷阱
回过头看那次半夜的事故,我反思的不仅仅是“为什么没做备份”或者“为什么没设审批流”。更深层的问题是:一个好的研发管理工具,应该用系统机制来防止灾难性误操作,而不是依赖管理员的警觉和记忆力。
Jira 给管理员的“自由度”非常大,你可以删版本、删工作流、改权限方案、甚至删项目,很多时候只需要点几下鼠标。这种自由度在小团队里是灵活性,在百人以上的组织里就是定时炸弹。因为任何一个人的一次手滑,都可能波及整个团队的交付节奏。
在这次评估替代方案的过程中,我观察到一个趋势:新一代的研发管理工具正在把“防错设计”作为产品的基本要求,而不是加分项。 PingCode 的版本管理之所以不容易出现断裂问题,不是因为它有什么魔法,而是因为它的数据模型从设计上就避免了实体断裂的场景。加上审批流和操作日志的配合,误删版本这件事在 PingCode 上要想造成同样的破坏,需要同时突破三重保护,而在 Jira 上,只需要一次确认点击。
当然,我也不是说 PingCode 就完美无缺。它在插件生态的丰富度上目前还比不上 Jira(毕竟 Jira 有十几年的 Marketplace 积累),如果你对某个特定插件有强依赖,迁移前需要仔细评估替代方案。但就核心的研发管理流程,需求、版本、迭代、缺陷、代码关联,PingCode 的一体化程度足够处理我们 200 人团队的需求。
十、总结:三件事你可以现在就做
这篇文章写了近六千字,如果你只能记住三件事,我希望是以下:
第一,Jira 的版本不是标签,是实体。删除版本就是删除数据库记录,关联会永久断裂。 每次在版本管理页面上操作前,问自己一句:“我知道这个操作会影响哪些工单吗?”如果不知道,停下来,先跑 JQL。
第二,预防比修复便宜一百倍。 设置权限、建立命名规范、定期巡检,这三件事加起来用不了你一小时,但可以帮你避免一个需要整个团队停摆半天来修复的事故。
第三,如果你的团队规模已经超过 100 人,认真考虑工具的“防错能力”应该是选型的重要维度。 一个能让管理员睡安稳觉的工具,比一个功能强大但处处是暗坑的工具,对组织来说更有价值。我们在 PingCode 上的迁移经历验证了这一点:不是因为它“功能更多”,而是因为它“不会让你在半夜接到电话说工单全断了”。
最后,如果你正在管理 Jira,现在就去跑一遍这个 JQL,看看你们项目里有多少工单的版本字段是空的:
project = "YOUR_PROJECT" AND fixVersion IS EMPTY AND created >= -30d
如果结果让你不安,说明你的版本管理已经在积累风险了。希望这篇文章能让你在它爆炸之前,有足够的时间拆掉引信。
常见问题解答(FAQ)
1. 如何确认 Jira 回滚版本后工单关联是否真的断了?
我昨天手贱回滚了一个项目版本,结果发现很多工单的‘修复版本’字段变成了空白,但不太确定是系统卡了还是真的断了?有没有办法快速验证一下?
我来帮你明确诊断。我自己就踩过这个坑,回滚了 Jira 的数据后,工单详情页的‘修复版本’字段要么完全空白,要么显示‘关联已断开 [ID:1234]’这样的字样。更隐蔽的情况是,字段看起来有值,但点进去发现版本名变成了‘未知版本’或者版本ID已经不匹配了。
我的验证方法是两步走: 第一步,用 JQL 直接扫描。在高级搜索框输入 fixVersion is EMPTY AND project = '你的项目Key',这会找出所有修复版本字段为空的工单。但这还不够,因为有些工单字段可能残留了旧ID但实际版本已被删除。
所以我还会用 fixVersion not in (versionNames()),其中 versionNames() 是你当前项目所有版本名称的列表,返回不在当前版本列表中的工单。
注意,Jira 原生没有直接函数,你可以通过脚本或手动列出当前版本名,然后用 fixVersion not in ("v1.0", "v2.0") 的方式。第二步,随机抽取几个显示正常的工单,查看版本字段,点开版本链接,如果跳转到404或者版本名与实际不符,那就确认关联断了。
我建议你先把这些查询结果导出成 CSV,作为后续修复的基线。
2. 回滚后工单关联全断了,有没有办法用 API 批量恢复?
我有几百个工单的版本关联都丢了,手动一个一个改会死人的。听说 Jira REST API 能批量修改,但我不懂代码,能不能直接给个脚本或者步骤?另外会不会有风险?
首先,API 确实是最高效的方案,但绝对不能直接在生产环境跑。我亲身经历过一次跑脚本把无关工单也改了,花了三个小时才回滚。这是我的标准流程: 前置准备(先在测试 Jira 实例上验证) 1. 获取受影响工单列表。使用我上一个答案提到的 JQL 查询,导出工单 issue key。
- 确定要重新关联的版本 ID。比如你回滚后,正确的版本是“v3.0”,它的 ID 可以通过 GET /rest/api/2/project/{projectKey}/versions 获取,找到 v3.0 对应的 id 值(是一个数字)。
- 准备脚本(我推荐用 Python 加 requests 库)。核心逻辑: – 读取工单列表。- 对每个工单,使用 PUT /rest/api/2/issue/{issueKey},在请求体里更新 fields.fixVersions 为 [{"id": "你的版本ID"}]。
- 注意:接口会替换整个
fixVersions列表,所以如果工单原本有多个版本,你需要先查出现有版本再决定保留哪些。更安全的做法是:先GET工单详情,拿到fixVersions数组,如果里面有失效的版本(ID 不存在了),就移除掉,再重新PUT。
风险点 – 批量操作必须加限速(比如每次间隔 200ms),否则会被 Jira 限流或造成死锁。- 一定要先备份工单数据(用 Jira 的企业备份功能或导出 CSV)。- 脚本跑完后,执行同样 JQL 查询检查是否还有空字段。如果发现新问题,立刻停止并恢复备份。
- 如果团队人多,最好在业务低峰期运行,并且通知所有人不要操作相关工单。
3. 如果我不懂 API 或者没权限用,有没有纯手工但高效的方法恢复关联?
公司 IT 不给开 API 权限,我只会用 Jira 界面操作。有没有办法在不写代码的情况下,一下子把几百个工单的版本字段补上?批量操作好像不行,因为版本选项里找不到原来那个版本了。
这是最折腾的情况,但我摸索出一套“半自动”手工大法。核心思路是:Jira 的批量编辑确实无法添加已被删除的版本(因为下拉框没选项),但你可以通过创建临时版本来绕开。步骤如下: 1. 在项目设置里重建一个同名版本。
注意:版本名可以一样,但底层 ID 会不同,工单字段会识别为新版本,但显示名称没变,用户感知不到差异。2. 使用 批量编辑(选中所有受影响工单,点“更多” -> “批量编辑”)。注意:批量编辑只支持添加或替换修复版本,因为你现在有了一个同名的选项,所以可以直接把新版本选上去。
如果工单原本绑定了多个版本(比如一个修复版本和一个影响版本),你需要分别对两个字段执行批量操作。注意:批量操作一次只能修改一个字段,所以要分两次跑。4. 执行完后,用 fixVersion in ("你重建的版本名") 验证。如果发现某些工单仍然有多个版本没补全,单独处理。
避坑点 – 如果原来的版本名被删除后你没记住名字,可以去审计日志或数据库备份里找。如果没备份,只能根据团队成员回忆。我建议你以后把版本命名规范写在 wiki 里,并保留所有历史版本列表(即使删掉了也要留一条记录)。- 这个方法只适用于版本名唯一的场景。
如果原来有多个同名版本(比如不同项目分支),那就不能简单重建,必须用 API 或者找回历史数据。- 重建版本后,旧的版本历史(比如关联的 Release 日期、描述)会丢失,但工单关联恢复是最紧要的。
4. 以后怎么避免 Jira 回滚导致工单关联断开?有没有预防措施?
我已经被这次事故吓怕了,每次回滚都提心吊胆。有没有什么规范或工具能提前预防?比如做版本管理时需要注意什么?另外回滚前有没有 checklist 可以参考?
我后来整理了一套 SOP,从此再没出过这种问题。核心原则是:永远不要删除版本,只归档。以下是具体预防措施: 1. 版本管理规范 – 在 Jira 中创建版本时,名称用 v2025.03.28 这种带日期的格式,避免歧义。
- 版本状态只使用“已发布”和“未发布”,严禁删除已关联任何工单的版本。如果必须废弃,把状态改为“已取消”,但保留实体。- 写一个自动化规则(Jira Automation):当有人尝试删除版本时,自动检查该版本是否被工单引用。如果引用数大于0,则拒绝删除并通知管理员。
2. 回滚前的检查清单 需要回滚 Jira 数据(比如恢复备份)前,执行以下步骤: – 记录当前所有版本列表(导出为 CSV)。- 记录所有关联工单的 fixVersion 和 affectedVersion 的快照(用我之前的 JQL 查询导出)。
- 通知所有团队成员:未来1小时内不要创建、编辑工单。- 恢复备份后,立刻运行对比脚本,检查版本 ID 是否一致。如果回滚后的版本 ID 变了,那么所有工单关联都会断。此时你需要决定:是手动重建版本名称(方法见第三个 FAQ)还是重新导入新数据?
3. 备份策略升级 不要把数据库备份当成万能药。我推荐采用“增量备份+版本快照”的方式:每次发布新版本前,单独导出该版本下的工单 CSV。回滚时,先恢复数据库,再导入 CSV 覆盖工单的版本字段(用 API 或手工)。这样即使版本 ID 变了,也能通过 CSV 里的版本名重新关联。
最后,定期(比如每季度)做一次数据完整性检查,跑一遍我之前给的 JQL 扫描,发现孤儿工单就立即处理。这套 SOP 下来,我团队两年没再出过关联断开的事故。
核心关键词
文章包含AI辅助创作:jira回滚版本,工单关联全断了,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3976246
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为Jira管理员,我第一次误删版本时也经历了同样的噩梦,看着几百个工单的关联瞬间断裂,那种无力感太真实了。手动逐个修复确实能解决,但代价太高。后来我养成了先导出关联列表再删除的习惯,但作者提到的实体ID机制才是根本。希望Atlassian能在删除时给出明确警告,甚至提供二次确认清单。
我们团队曾因为数据库回滚导致版本关联全断,当时运维直接恢复备份,结果丢失了两天的工单更新和评论,被开发吐槽了一周。看了文章才明白,版本ID漂移是比简单删除更隐蔽的陷阱。现在我的策略是:回滚前先用JQL扫描所有可能受影响的工单,单独导出CSV留底,双保险。
这篇文章简直说到了我的心坎上。我所在的团队上个月发生了一次版本误删,产品经理在Sprint中突然发现看板上的需求标签全乱了,导致当天上线决策直接推迟。虽然技术同学连夜用API恢复了大部分,但团队信任成本增加了。从管理层角度看,这类问题看似技术细节,实则直接影响交付效率。
我比较好奇的是,为什么Jira作为成熟的商业工具,在版本删除这样的高风险操作上,没有内置一个‘显示关联工单’的预览功能?让管理员清楚知道删除会影响到多少工单、哪些项目。这又不是什么高难度的开发需求。相比之下,PingCode在删除操作前会有明确的警示和阻断,体验好很多。
文章提到的PingCode迁移方案很有意思。我们公司也是因为Jira Server版本停售和安全合规问题在考虑替代品,最担心的就是数据迁移过程中版本关联断裂。如果PingCode有专业的Jira Importer工具和人工支持,能把版本ID映射做好,那确实比手工迁移靠谱。希望作者可以详细说说迁移实际踩过的坑。
非常实用的自救指南,尤其是JQL定位受影响工单的思路和API脚本重建关联的风险提示。我之前修复时就是盲目用批量操作,结果发现版本实体已删除后,批量界面根本选不了。现在我把作者的方法固化成了团队SOP,包括回滚前的版本快照检查和回滚后的自动化验证脚本,这套流程已经救了我们两次。