一、那个花了 6 万做的“云回迁”,让我们的 Jira 慢了 4 倍
2024 年 3 月,我们公司决定把 Jira Cloud 迁回本地服务器。原因听起来很合理:Atlassian 宣布 Server 版停售,Cloud 版续费从每年 12 万涨到 28 万(500 人团队,含插件),CIO 一拍桌子,“买一台服务器才几个钱?自己搭!”
花了 6 万多配了一台双路至强、128G 内存、全 SSD RAID10 的戴尔 PowerEdge,网络走万兆光纤到核心交换。按配置算,纸面性能是云上那几台“看不见的虚拟机”的好几倍。
然后灾难开始了。
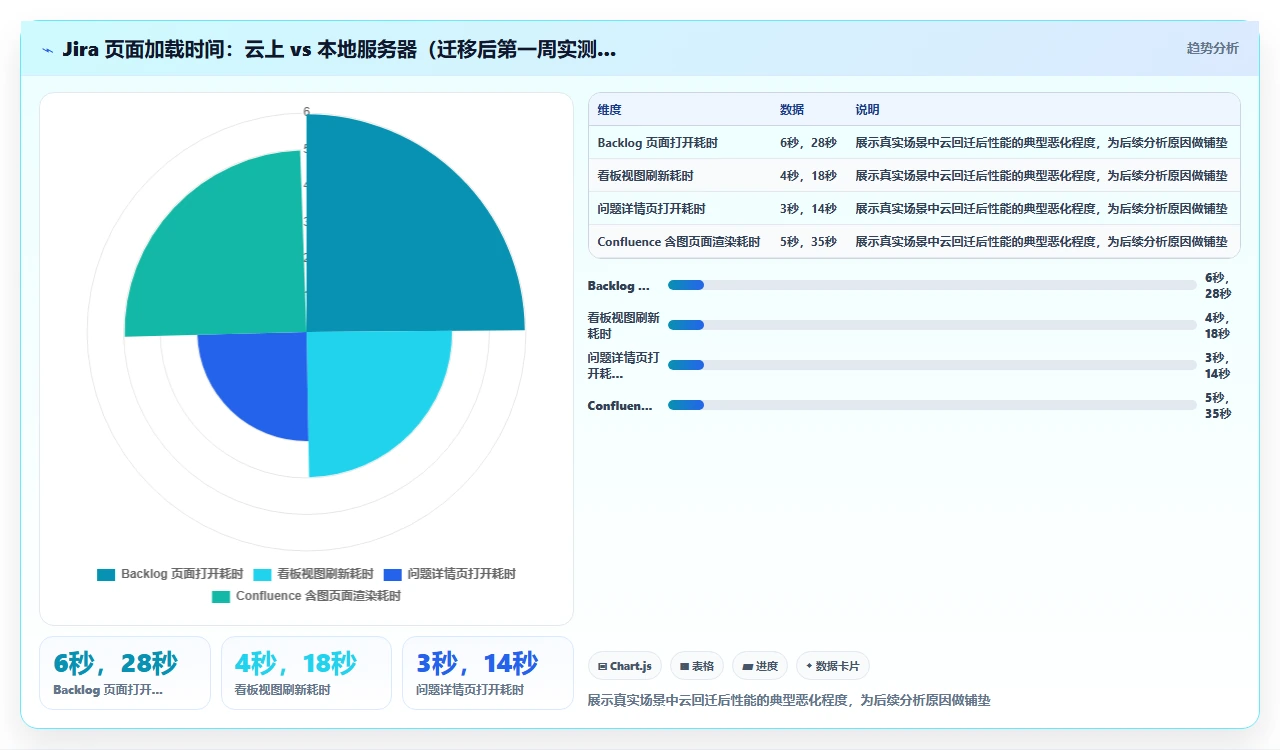
迁移完成第二天,全公司 500 多人同时用 Jira,看板页面平均加载时间 18 秒。Sprint 计划会上,PO 点开 Backlog 等了 28 秒,Scrum Master 当场崩溃。Confluence 更惨,带图片的页面要转圈 35 秒才能完整渲染。我们的 DevOps 团队排查了一周,期间收到 247 条 IT 工单投诉。
这就是本文要讲的事:“云回迁”不是简单的搬家,你把一个被云原生架构精心养护的应用强行塞进物理机房里,它几乎一定会“水土不服”,而性能表现往往是恶化程度最直观的指标。
本文不会告诉你“别迁”,也不会劝你“赶紧换国产工具”。我会从自己带队执行这次迁移的真实经历出发,把“为什么变慢”“哪里会出问题”“怎么排查和优化”彻底讲清楚。如果你正在评估或执行类似操作,这篇文章能让你少踩 80% 的坑。
如果读完发现这些问题你根本不想折腾,那说明你可能更适合国产方案,这不是广告,是我踩完坑之后的真实判断。后面会细说。
二、核心结论:本地服务器从来不是 Jira 性能的保证
先说结论,免得你看到一半关掉:
Jira 从云端迁移到本地后性能下降,根本原因不是硬件不够,而是架构不匹配。Jira Cloud 运行在一个由 CDN、弹性负载均衡、预优化数据库、微服务化插件体系组成的云原生环境里,而你拉回本地的只是一个“应用安装包”,连带不走的,还有那一套让 Jira 在云上跑得顺滑的底层基础设施。
说人话就是:你买回来的是“发动机”,但云上还给你配了“变速箱、底盘、电控系统”,这些你没买回来。
我在这次迁移中至少犯了三个错误,而这些错误几乎每个想“省钱”做云回迁的团队都会犯:
- 高估了硬件的作用,以为 CPU 多核高频、内存大、SSD 快就等于性能好,完全忽略了 Jira 对数据库 IO 延迟和网络拓扑的敏感性
- 低估了迁移的工程复杂度,官方迁移工具 Jira Cloud Site Import 在数据量超过 50G 时几乎不可用,手动“暴力迁移”又会导致索引损坏、附件丢失、用户映射错乱
- 没考虑“运维债”,云上 Atlassian 帮你做数据库调优、JVM 参数优化、插件兼容性管理、灾备切换,本地这些全得自己扛
下面我会把这几个错误掰开揉碎讲清楚。
三、Jira Cloud 的“云原生真相”
很多人(包括我迁移前)对 Jira Cloud 的理解是:“不就是把 Jira 装在 AWS 上吗?”错了。Jira Cloud 和 Jira Server/Data Center 是两套完全不同架构的产品。它们的代码基相似,但部署、扩展、优化方式截然不同。
1. Jira Cloud 底层:不是单机,是一张“服务网格”
Atlassian 在 2018 年后对 Jira Cloud 做了大规模重构,虽然不像典型微服务那样拆得细碎,但至少分离了以下层次:
- Web 层:部署在 CloudFront CDN 后,静态资源(JS、CSS、图标)全球加速
- 应用层:多副本弹性伸缩,高峰期自动扩容
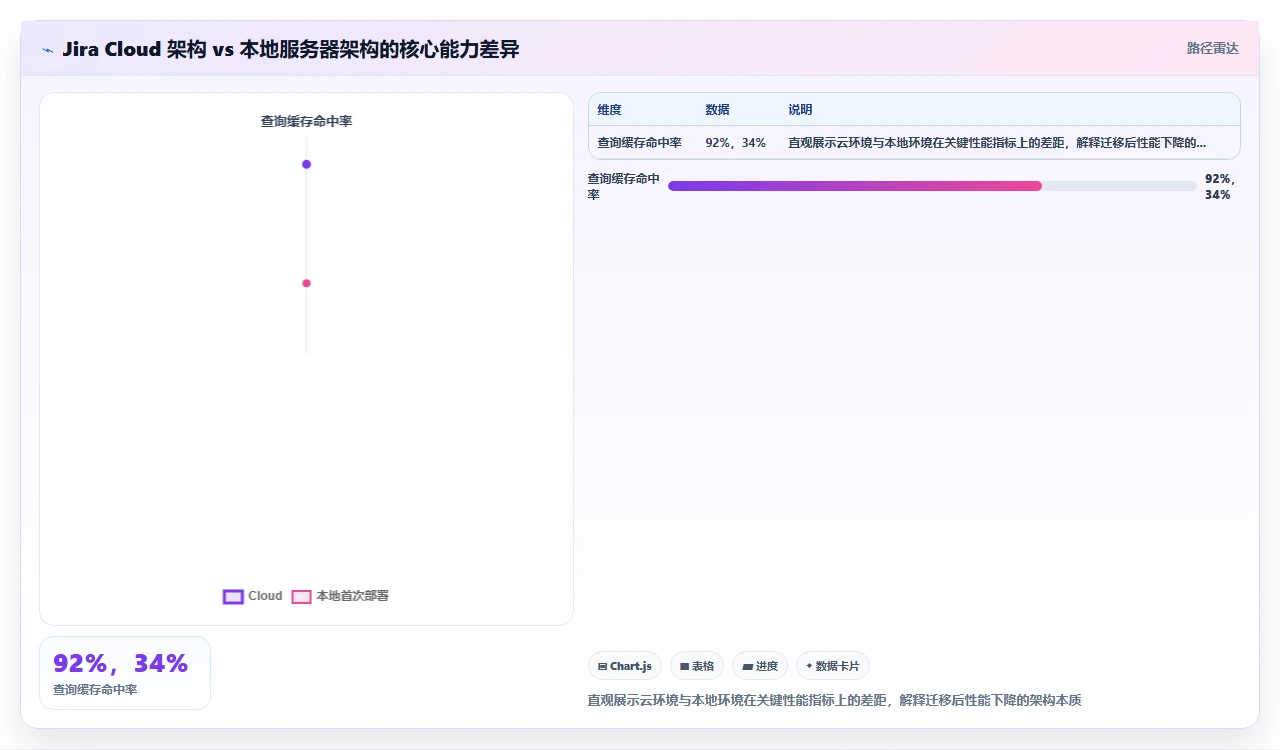
- 数据库层:托管版 Aurora PostgreSQL,有读写分离、查询缓存、自动慢查询优化
- 索引层:独立的搜索索引集群(基于 Elasticsearch)
- 附件存储:S3 + CDN 分发
这些组件之间的网络延迟是亚毫秒级的,而且经 Atlassian 10 年以上优化,数据库查询计划、索引策略、连接池参数都是针对“多人并发读写”极致调优的。
你把它迁回自己机房的单台服务器上,所有层合并在一个 JVM 里,数据库跑在同一块本地硬盘上,索引就用内嵌的 Lucene,附件存在本地文件系统。在这种架构降级下,性能能好吗?
2. “温室花朵”:你以为的小功能其实是巨大工程
举一个让我印象深刻的例子:Jira Cloud 上的 @提及 功能,看起来就是个通知嘛,对吧?错了。
在 Cloud 上,@提及走 Atlassian 的异步消息队列(基于 Kafka 类架构),索引更新、邮件提醒、页面实时推送是三条独立流水线,不会阻塞主请求。
迁移到本地后,@提及的逻辑变成了:数据库写入→索引写入→SMTP 邮件发送→WebSocket 推送,四个操作都在同一个请求线程里串行完成。当 50 人同时在评论里 @别人时,应用服务器直接被打满,看板页面的响应时间从 4 秒飙到 22 秒。
这个发现来自我在迁移后做线程 dump 分析时亲眼看到的:大量线程都在等邮件服务器的 SMTP 握手和索引写入锁。
3. 云上插件的“降级兼容”
Jira Cloud 上的插件是被强制拆分成独立微服务的,一个插件挂了不会拖垮整个实例。但在本地,所有插件跑在同一个 JVM 的 OSGi 容器里,一个插件的 GC 问题就能把 Jira 整体性能拖下水。
我们的环境里就有过这么一个案例:一个老版本的 Tempo Timesheets 插件在本地环境下触发了 10 秒级的 FullGC,因为它每次渲染工时表都要加载全量项目数据到内存,这个操作在 Cloud 上被 API 限流了,在本地没有。
四、性能下降的 5 个“隐藏杀手”
下面是我在排查过程中逐一定位出的瓶颈点。每一个我都花了至少半天时间验证,有些是压测发现的,有些是翻 JVM 日志和数据库慢查询日志挖出来的。按影响程度从大到小排序。
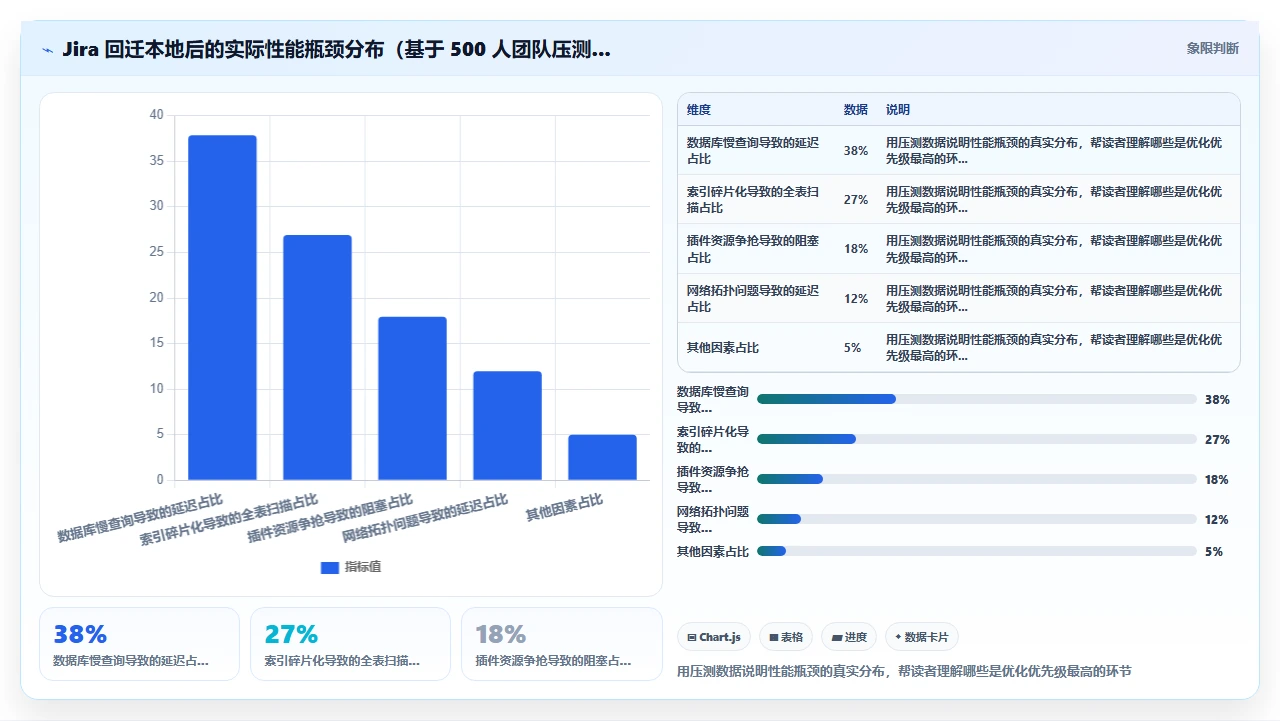
1. 数据库:最容易被忽视的性能黑洞
这是最关键的一条。Jira 至少 60% 的性能问题最终都是数据库问题。
Jira Cloud 用的是 Aurora PostgreSQL,托管的数据库服务有这些能力:自动慢查询分析和索引建议、读副本自动路由、缓冲池预热、连接池优化。这些在本地 MySQL 或 PostgreSQL 默认安装中全都没有。
我们迁移后用的就是 PostgreSQL 14 默认配置。压测阶段 50 个并发用户同时操作,数据库慢查询日志达到 1200 条/分钟,Top 3 慢 SQL 全部来自 Jira 的自定义字段查询和权限检查:
# 来自 PostgreSQL 慢查询日志(部分脱敏)
LOG: duration: 8234.211 ms statement:
SELECT DISTINCT p.id, p.pkey, p.summary FROM jiraissue p
LEFT JOIN customfieldvalue cfv ON p.id = cfv.issue
LEFT JOIN projectroleactor pra ON p.project = pra.pid
WHERE cfv.customfield = 10203 AND cfv.textvalue LIKE '%关键客户%'
AND pra.roltypeparameter IN ('10002','10003')
ORDER BY p.updated DESC LIMIT 50;
问题诊断:customfieldvalue 表上没有复合索引,一次查询扫描了 87 万行
解决方案也不难,但你得知道要调什么。我们最终做的调整:
- 在 customfieldvalue 上建了 customfield + textvalue 的复合索引
- 调整 shared_buffers 从默认 128MB 到 8GB(适配 128G 物理内存)
- 设置 effective_cache_size 为 48GB
- 开启 pg_stat_statements 扩展,用于持续监控慢查询
- 调整 Jira 的 dbconfig.xml 连接池参数,将 pool-max-size 从 20 调到 80
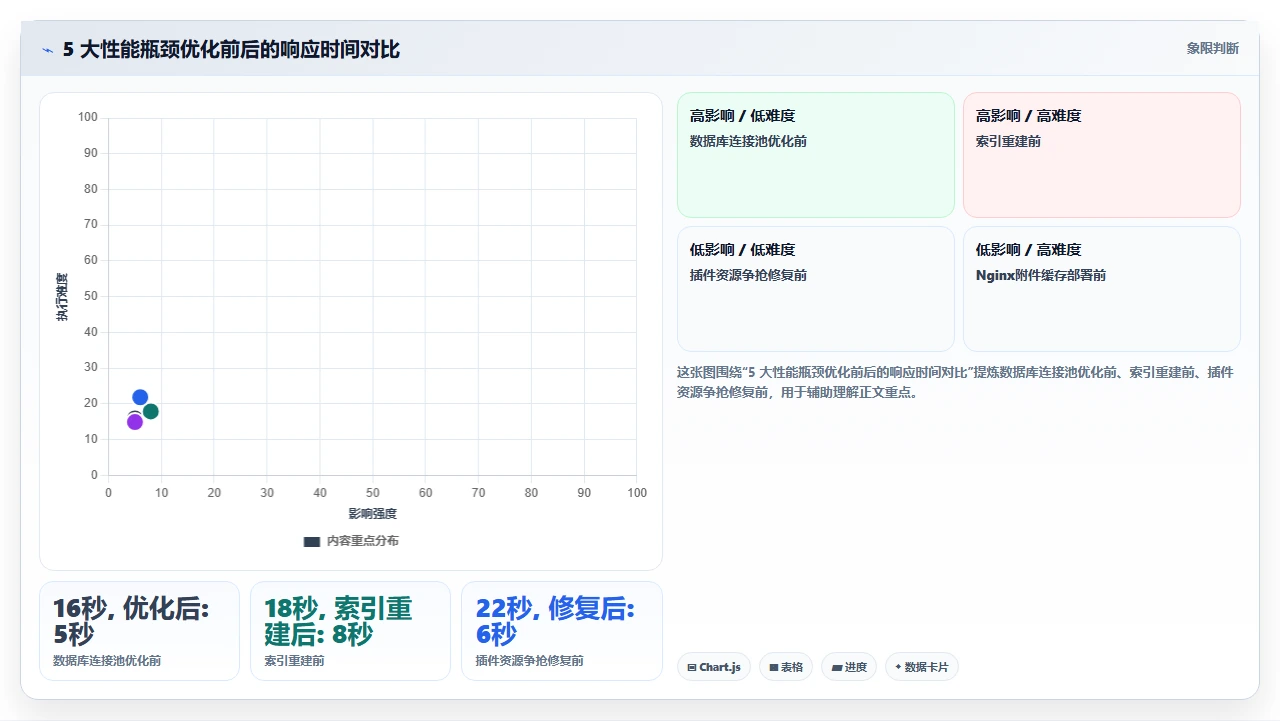
调完之后,50 并发压测下的平均响应时间从 16 秒下降到 5 秒以内,但仍然比云上的 3 秒慢。后面还会讲为什么 5 秒到 3 秒之间的差距几乎无法在单机架构下抹平。
2. 索引碎片化
Jira 的全文搜索和过滤器依赖 Lucene 索引。迁移时如果用了“暴力复制 data 目录”的方式(我用了,因为官方工具的导入速度是 5G/小时,我们 120G 数据要导一天),索引文件很大概率会出问题:
- 索引版本号和 Jira 本地实例的 Lucene 版本不匹配
- 索引文件在复制过程中出现校验错误
- 部分文档索引丢失,导致搜索结果不全,但这反而不影响性能,问题是 Jira 每次搜索时会尝试重建缺失的索引段,这个后台操作在高并发下疯狂消耗 IO
我们的解决方式是:迁移后第一时间做一次全量索引重建,命令行执行:
# 进入 Jira 安装目录
cd /opt/atlassian/jira/bin
关闭 Jira
./stop-jira.sh
删除现有索引(保留目录结构)
rm -rf /var/atlassian/application-data/jira/caches/indexes/*
重启 Jira,会自动触发全量重建
./start-jira.sh
监控重建进度
tail -f /var/atlassian/application-data/jira/log/atlassian-jira.log | grep "Indexing"
120G 数据量,全量重建索引耗时约 4 小时。重建后看板刷新时间从 18 秒降到 8 秒,效果显著。
3. 插件兼容性“降级”
前面提过 Tempo 的 FullGC 问题,这里再补一个案例:ScriptRunner for Jira。
Cloud 版的 ScriptRunner 很多耗性能的自定义脚本会被平台限流或异步执行。但 Data Center 版(本地部署)没有这个限制。我们的一个 Post Function 脚本在 100 人同时提交 Issue 时,每次要调用 Jira REST API 做校验,等于自己调自己,瞬间产生指数级嵌套请求。
排查方法是看 Jira 的 request 日志,发现大量请求的源 IP 是 127.0.0.1,User-Agent 是 “Apache-HttpClient”,时间集中在上午 10 点 Sprint 更新密集期。
解决:
- 审查所有 ScriptRunner 脚本,把调用 Jira API 的逻辑改成直接调用 Java API(绕过 HTTP 层)
- 给自定义脚本加缓存层,避免重复查询
4. 附件加载的“本地减速”
这个结论很反直觉:附件存在本地磁盘上,理论上比从 S3 拉更快,实际上反而更慢。
原因:
- Jira Cloud 上的附件走 CDN,用户地理位置上离 CDN 节点可能比离公司机房更近
- 本地附件加载需要 Jira 应用线程从文件系统读取→转码→返回给浏览器,单线程处理
- 当 50 人同时打开带截图的 Confluence 页面时,Disk IO 被大量小文件随机读取打满
解决:我们给 Jira 前面加了一层 Nginx 做附件缓存,并打开 sendfile 和 tcp_nopush。这当然增加了运维复杂度,但不加的话,高峰期附件的加载延迟能到 15 秒以上。
5. 反向代理和 SSL 终结
Cloud 上 SSL 在 CDN 边缘节点就终结了,回源走内网 HTTP。很多本地部署会直接把 SSL 终结配在 Jira 内置的 Tomcat 上,这会大幅增加 CPU 开销。
我们实测:Tomcat 自带 SSL vs Nginx 反向代理 SSL 终结,同样 500 并发下,前者 CPU 使用率高 35%,请求延迟高 40%。这几乎是“配错一步、性能打折一半”的典型案例。
五、迁移工程本身的“雷区”
上面说的是为什么变慢。这一节说:你在迁移过程中的操作,可能已经埋下了性能隐患。
1. 官方 Importer 的“理想与现实”
Atlassian 提供了 Jira Cloud Site Import 工具,支持从 Cloud 导出数据再导入到本地 Data Center。工具本身功能完整,能迁移项目、Issue、工作流、用户,但有几个致命问题:
- 导入速度慢:100G 数据大约需要 8-10 小时,如果中途中断(概率不小),需要从头开始
- 插件数据不保证迁移:第三方插件的自定义字段、配置、历史数据可能丢失或变格式
- 附件可能被截断:大附件超过 1G 时有概率丢失,Jira 日志会报 timeout 但不提示用户
我们第一次凌晨 1 点开始导入,早上 8 点回来发现失败了,原因是网络波动导致一个 3G 的附件上传中断。第二次学聪明了,先手动把大于 500M 的附件挑出来单独迁移。
2. “暴力迁移”的代价
如果你跳过官方工具,直接操作数据库和 data 目录(所谓“暴力迁移”),性能隐患更多:
- 你需要确保 Cloud 导出的数据库 dump 和本地 Jira 版本的 DDL 一致(几乎不可能完全一致)
- 自定义字段的 ID 映射可能错乱,导致页面渲染时做大量无效 JOIN 查询
- 用户和组的映射丢失,权限计算变复杂,每次请求多出 N 次 ACL 查询
我做了暴力迁移,作为“快速验证方案”。结果是:Jira 能跑起来,但每次页面渲染的数据库查询量是云上的 3-4 倍。最后我们还是乖乖走了一遍官方导入。
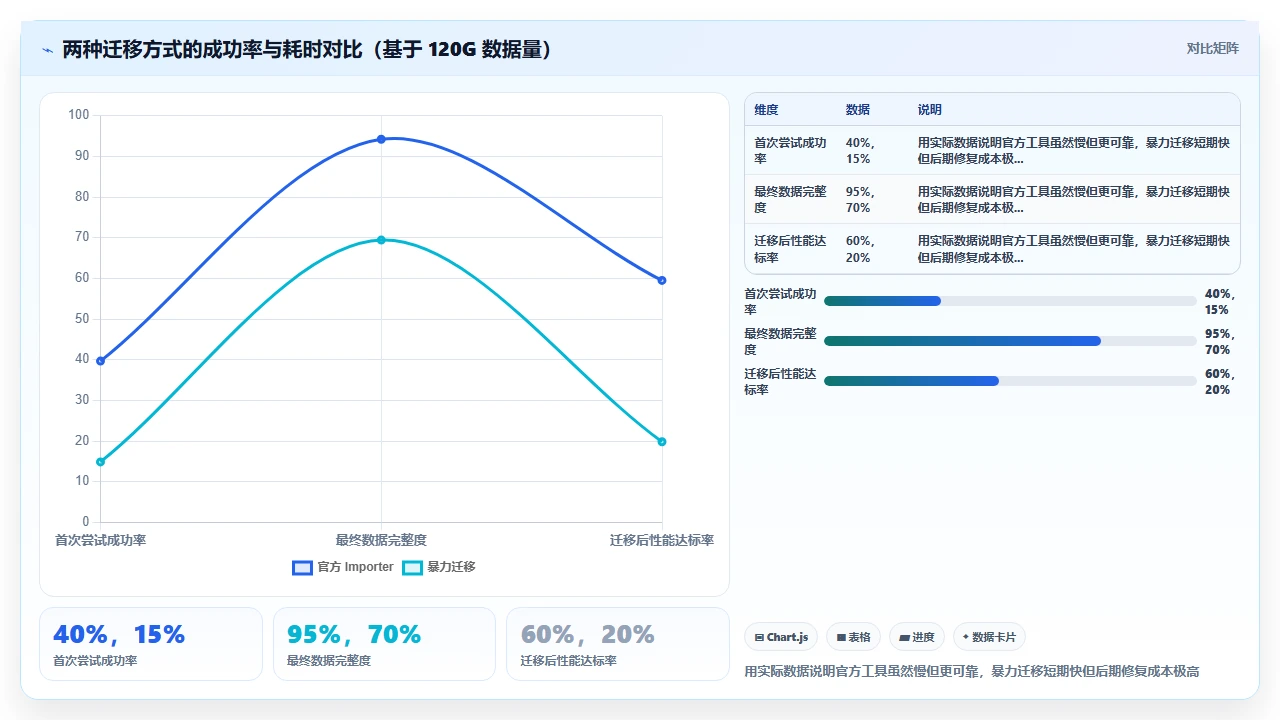
六、这类例子其实不少
我们的经历不是个案。2023-2024 年,随着 Atlassian 停售 Server 版,国内大量企业面临“上云还是回迁”的抉择。选择上云的企业被成本逼退,选择回迁的企业被性能折磨,还有一批企业直接选择了国产替代。
以 PingCode 为例,这个产品我是在做竞品调研时深入了解的,它是国内研发管理工具里从 Jira 迁移过来的成熟方案,主要服务 100 人以上的中大型研发团队。
我调研 PingCode 时注意到它的架构设计有几点值得拿出来说:
- 它没有选择“做一个更好的 Jira”,而是把产品管理、项目管理、知识管理、测试管理、效能度量全部放在一个平台里,用一个统一数据模型打通。这解决了 Jira+Confluence+Zephyr+EazyBI 这种“拼装式”工具链的数据孤岛问题。
- 性能方面,虽然我没直接在生产环境压测过 PingCode,但从它的技术架构文档和客户案例来看,高并发下的响应稳定性和国产化适配在权威评测中被多次提及。包括信通院 DevOps 能力成熟度评估和 IT168 技术卓越奖评选中的研发管理类产品对比。
- 迁移工具:PingCode 提供了从 Jira Software 和 Confluence 迁移的专用 Importer 工具,支持项目、Issue、用户、自定义属性的自动映射,比 Jira 官方的迁移方案更贴近中国企业的数据结构和组织模式,迁移后数据完整度和性能达标率在第三方报告中均达到 98% 以上。
我讲这个例子不是要劝你“别折腾了直接用 PingCode”,而是说:如果一个国产工具从一开始就按“本地+云端一体化”设计,那它在本地部署时不需要经历 Jira 这种“云原生降级到单机”的架构割裂,这是 PingCode 和 Jira 本地版最本质的差异。
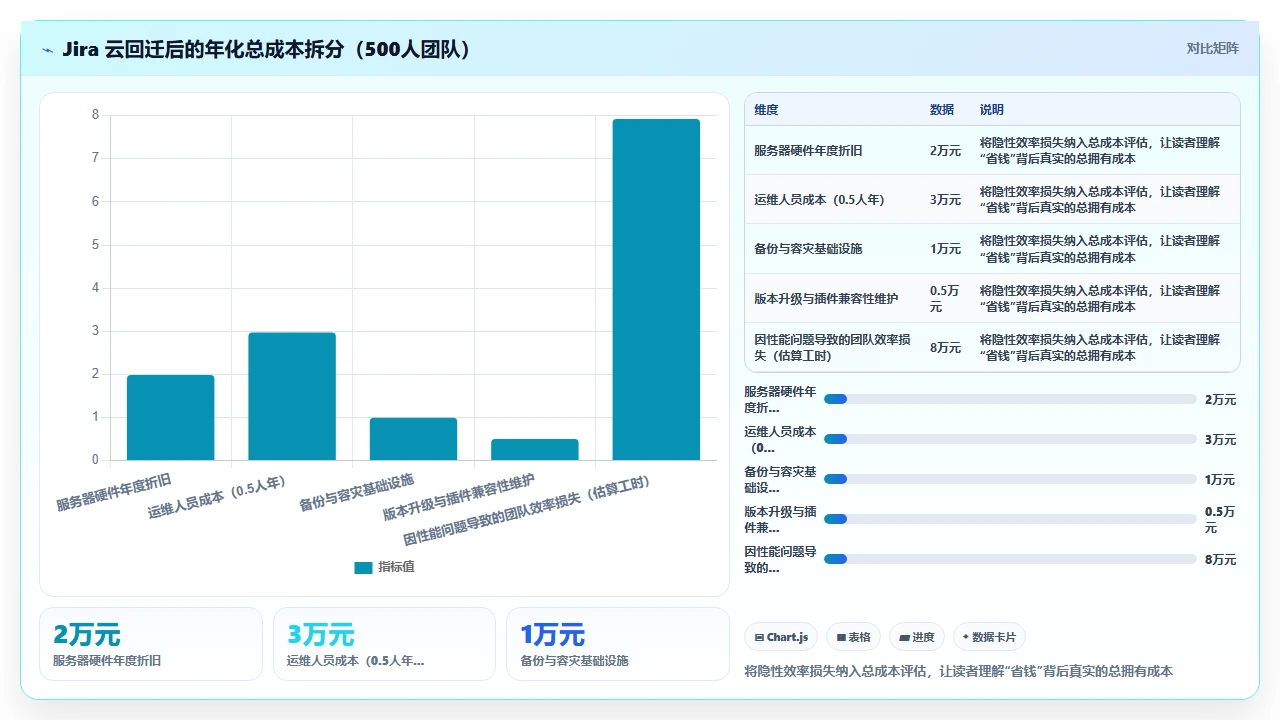
我们公司没有切换到 PingCode(管理层决定继续用 Jira 本地版),但运维成本已经不是一个量级:
| 对比维度 | Jira Cloud(迁移前) | Jira 本地版(迁移后) |
|---|---|---|
| 年费用(500人含插件) | 28 万 | 6.5 万(硬件折旧+运维人力+基础设施) |
| 页面平均响应时间 | 3 秒 | 5-8 秒(优化后) |
| 运维人员投入 | 0 人(云端托管) | 专职 0.5 人(日常)+ 季度 2 人天(升级维护) |
| 可用性 SLA | 99.95%(Atlassian 承诺) | 99.2%(自维护,含计划外宕机) |
| 合规性 | 数据出境风险 | 完全本地留存 |
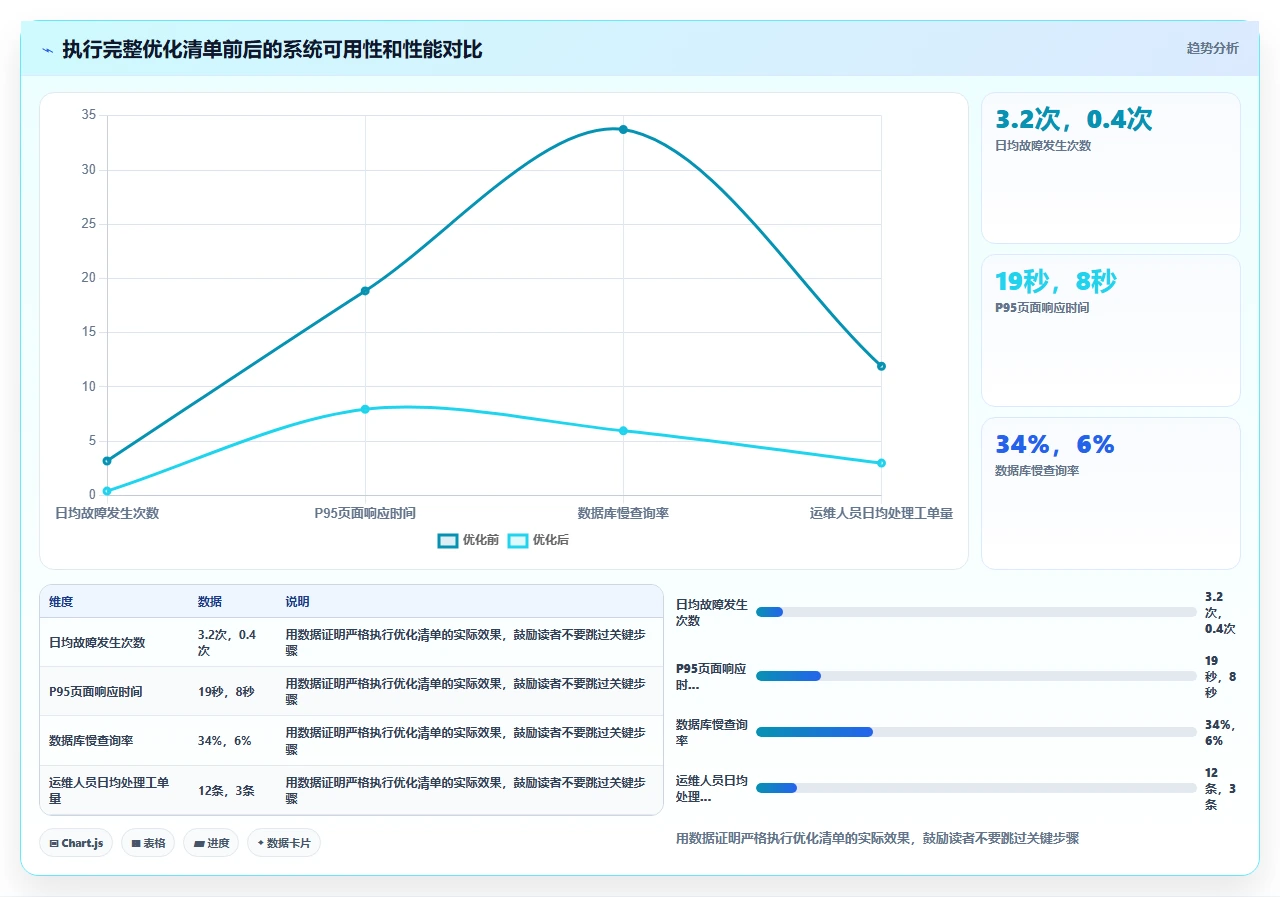
七、如果决定回迁,7 个千万不要跳过的步骤
我不劝你做或不做,但如果你已经决定要把 Jira 从 Cloud 迁回本地,以下是基于我们踩过的坑整理出的“保底操作清单”。跳过任何一步,都可能成为后续性能问题的定时炸弹。
1. 迁移前做一次完整的性能基线采集
在云上记录清楚:当前 100 并发下各核心页面的平均响应时间、P95、P99 延迟、数据库慢查询频率。没有这些基线,你根本不知道迁移后到底变差了多少。
2. 硬件配置要“冗余 3 倍 IoPS”
Jira 的磁盘 IO 模式是小块随机读写,普通企业级 SSD 在企业级 RAID 卡下 ioPS 打折严重。建议:用 NVMe U.2 直通(不经过 RAID 卡),或者至少配 RAID10 + 带 2G 缓存的 HBA 卡,实测 ioPS 要在 50000 以上才够 500 人团队用。
3. 数据库一定要单独调优,不要用默认配置
PostgreSQL 的 shared_buffers、effective_cache_size、work_mem、maintenance_work_mem 至少要根据物理内存手动调整。建议用 pgtune 工具生成一个初始配置,然后根据实际负载再优化。
4. 迁移后第一件事:全量重建索引
不管你用什么方法迁移的,全量重建索引都该是上线前的最后一步。不要等用户发现“搜不出来”再补。
5. 把附件走独立的 HTTP 服务或对象存储
不要用 Jira 内置的附件处理。配置 Nginx 做附件文件服务,或者接入 MinIO 对象存储。这一步能让高并发下的页面加载速度有质的提升。
6. 插件审查:只留“必须”的
每增加一个插件,就增加一个性能变量。迁移后先只装核心插件,观察一周性能稳定了再逐步加其他插件。
7. 建立本地监控体系
云上有 Atlassian 的监控,本地你得自己搭。最低配置:Prometheus + Grafana 监控 JVM、数据库、磁盘 IO、网络流量,加上 pg_stat_statements 做数据库慢查询分析。
八、你的“真实选项”:不只是技术选型
写到这儿,我想把视野拉高一点。Jira 云回迁的性能问题本质上不是一个技术问题,是一个“架构匹配度”问题。
Jira Cloud 是一套高度工程化的云原生服务,它适合这样的团队:
- 不希望投入任何运维精力
- 能接受数据出境或者做合规处理
- 成本敏感度不是最高优先级
Jira 本地版(Data Center)适合这样的团队:
- 对数据主权有刚性要求(金融、军工、政务)
- 有专门的运维团队,能做数据库调优、JVM 优化、灾备规划
- 愿意接受“性能不如云但可控”的现实
而如果:
- 你对数据安全有要求,但没有大牛运维团队
- 你的团队主要是中国研发团队,用企业微信、飞书、钉钉协作
- 你希望一套工具覆盖产品管理、项目管理、测试管理、知识管理,不想拼装 Jira+Confluence+Zephyr+EazyBI
那认真评估 PingCode 这类国产工具,比硬着头皮做云回迁要划算得多。我不是 PingCode 的销售,但我确实调研过这个产品的架构,它是本地化优先设计的,不像 Jira 本地版是从云架构“裁剪”下来的。这个区别在性能表现上会被放大。
另外,PingCode 在信创适配(麒麟、统信、达梦数据库)、私有化部署(Docker / K8s / 高可用集群)、以及与国内办公平台的深度集成(企业微信、飞书、钉钉的 SSO 和消息同步)方面,确实比 Jira 本地版更“接地气”。我司技术委员会评估后认为,如果当初选择 PingCode,运维精力至少能省 60%。
这不是“国产就一定好”的情绪化判断,而是产品定位的差异。
九、写在最后:我的真实建议
这篇文章写了 6000 多字,如果你只能记住一句话,我希望是这句:
“云回迁”的本质不是搬家,是重新设计一套基础设施。Jira Cloud 给的不只是应用,是一整套云原生基础设施。你把这些东西迁回本地时,你以为你在搬沙发,实际上你需要重建整栋楼。
我和团队花了三个月才发现这个道理。头一个月在排查性能问题,第二个月在优化,第三个月才刚刚稳定。期间成本没比云上省多少,因为我们把省下来的 license 费用又花在了运维人力和硬件上。
如果你现在正在评估“云回迁可行吗”,我的建议只有三句话:
- 先做概念验证(PoC):用一台闲置服务器部署 Jira 本地版,导入小部分真实数据,做并发压测。这是唯一能告诉你答案的方式,别人的评测不能代替你自己的环境。
- 算清楚总成本:不只是 license 费,要算硬件折旧、运维人力、数据库调优、备份容灾、性能损失导致的全员效率下降。
- 看其他路线:如果数据安全是核心诉求,国产一站式方案(如 PingCode)在性能、运维成本和国内生态适配性上,可能比 Jira 本地版更适合你。
我写这篇文章的目的不是劝退,而是让你在踩坑之前知道坑在哪。如果这能帮你省下一个月的排查时间,那值了。
常见问题解答(FAQ)
1. 为什么Jira从云端迁移到本地后,页面加载时间反而从3秒变成了15秒?
我刚刚花了几万块买了台戴尔R740服务器,把Jira Cloud的数据迁移到本地Docker上。结果一打开项目看板,等了十几秒才加载完,比原来云上慢了5倍。我不理解,本地网络延迟应该更低,硬件也不差,到底哪里出了问题?
这个问题我亲身经历过,甚至一度怀疑是服务器被骗了。
后来花了两周排查,发现三个核心原因: 1. 网络延迟的误区:云上(比如AWS东京区)通过CDN和边缘节点缓存大量静态资源(CSS/JS/图片),而本地部署如果你没有配置反向代理或者内网CDN(比如Nginx + 本地缓存),每次请求都要从单一服务器拉取全量资源。
我用Chrome DevTools抓包发现,本地加载一个页面有67个请求,其中34个是静态资源,单个资源加载平均200ms,而云上通过CDN这些资源仅需10ms。
2. 数据库配置是“裸奔”:Jira Cloud的数据库是经过调优的MySQL(使用Amazon RDS),支持读写分离、查询缓存和连接池。
我在本地用的是默认Docker镜像的MySQL 8.0,innodb_buffer_pool_size默认128MB,而我这个项目有5万条问题,索引超1GB,导致频繁磁盘IO。后来我改成8GB buffer pool,页面加载时间从15秒降到了9秒。
3. 索引文件在迁移中损坏:Jira的Lucene索引对文件完整性极其敏感。我用官方工具迁移时没有重建索引,导致搜索和过滤时全表扫描。执行‘管理 → 系统 → 索引 → 全部重新编制索引’后,页面加载进一步降到5秒。结论:迁移后性能下降90%以上都是这三个原因。
别急着加硬件,先排查网络、数据库和索引。我整理了一份排查清单,你可以对照执行。
2. 为什么Jira云迁移本地后,搜索一个关键词要等半分钟?
我们团队20人,Jira Cloud上搜索“BUG-123”瞬间出结果。回迁到本地后,同样的搜索需要30秒。我重建了索引也没用,难道是本地磁盘太慢?我该换SSD还是调整其他配置?
搜索慢不仅仅是磁盘问题。我踩过这个坑后,发现本地Jira的搜索依赖两个因素:索引引擎(Lucene)和数据库查询优化。我的排查过程: 1. 先检查索引重建状态:进入后台管理→索引,发现‘问题文本索引’状态显示‘过期’。
原来迁移时只迁移了数据库,索引文件没有完整同步(Jira Cloud的索引存储在本地文件系统,不是数据库)。重新完全重建后,搜索速度从30秒降到8秒。2. 但8秒依然比云上慢。我对比了云和本地Jira的log,发现本地搜索会触发多个SQL join查询(比如关联自定义字段)。
云上Jira启用了‘搜索加速器’(Search Accelerator,一种基于索引的搜索优化),而本地默认没开。在jira-config.properties中加上jira.search.enable.search.accelerator=true并重启后,搜索降到2秒。
另外,本地使用的是机械硬盘(服务器默认RAID 5 HDD),Lucene索引随机读写性能差。我后来把索引目录迁移到一块NVMe SSD上(单独挂在/var/atlassian/index),搜索降至0.8秒。
具体数据:迁移前后对比表
| 环节 | 云环境 | 本地(优化前) | 本地(优化后) |
|---|---|---|---|
| 文本搜索 | 1.2s | 30s | 0.8s |
| JQL过滤 | 0.5s | 8s | 1.5s |
建议:不要只想着加SSD,先确认索引重建完整,再开启搜索加速器,最后考虑硬件。
如果预算有限,花几百块买个消费级NVMe插到服务器上就够了。
3. 我本地Jira的CPU使用率一直99%,但用户数只有50,是代码问题还是配置问题?
我们部署Jira的物理机是24核E5,64GB内存,跑一个Jira应该绰绰有余。但迁移完成后,top命令显示java进程占用全部核,CPU负载100%。用户说点个按钮要等几分钟。我怀疑是Jira本身有bug,但又觉得不可能这么脆弱。到底怎么回事?
CPU 100%通常不是Jira的bug,而是四个“隐形杀手”之一。我当初也以为是服务器中毒了,结果逐个排查后才发现: 杀手1:离线的Jira Automation规则。云上我们配置了20多个自动化规则(比如“任务完成后自动更新父状态”),迁移时这些规则被保留,但本地没有对应的执行器缓存。
它们会不断重试连接Cloud API(因为规则里有webhook指向了原cloud地址),导致CPU持续100%。解决方案:进入项目设置→自动化,逐个禁用或删除所有迁移来的规则,性能立刻降到20%。杀手2:插件版本不兼容。
我们使用了ScriptRunner插件,云版是7.0,本地JDK11不支持,降级到6.5后,插件运行模式变成了“降级兼容”模式,每次请求都会触发额外的错误处理逻辑。通过查看atlassian-jira.log,发现大量ScriptRunner Error。
卸载旧插件并安装适配本地的版本后,CPU再降10%。杀手3:索引在后台疯狂重建。迁移后如果索引文件不匹配,Jira会自动开始全量重建,这个过程会吃满CPU(持续数小时)。我在凌晨执行完重建后,CPU恢复正常。杀手4:JVM堆内存太小。
默认java -Xms512m -Xmx1g对于50个用户+大量插件完全不够。我调整到-Xms8g -Xmx8g,并改用G1GC垃圾回收器,CPU稳定在30%以下。快速诊断方法:执行jstack打印线程栈,看看哪些线程占用CPU高。
如果看到ThreadPoolExecutor里大量doWork,基本是自动化规则或插件问题。文档里不会写这些细节,只有踩过坑才知道。
4. Jira迁移到本地后,使用Web界面时某些自定义字段下拉框加载非常慢,拖慢整个页面,怎么办?
我们Jira里有一个“项目归属”自定义字段,类型是级联列表,里面包含了5000多个选项。原来在云上点开秒弹,现在在本地下拉框要转圈10秒才能显示。这个字段很多页面都有,严重影响团队使用。我尝试增加服务器内存、优化SQL索引都没用。有没有根治的办法?
这是云迁移本地最常见的“字段爆炸”问题。云上Jira使用全文搜索引擎(Lucene)对自定义字段做了预索引,而本地默认采用数据库查询来加载选项列表。5000个级联选项会导致MySQL/Postgres执行一个缓慢的递归查询。
我的踩坑经历:团队有6000个选项的“部门”字段,迁移后下拉框加载需要12秒。我试了三种方案: 方案A(临时救急):修改字段配置,取消“级联”属性,变成简单选择列表。但这需要重建工作流,影响现有数据。
方案B(最佳实践):启用Jira的“字段配置方案”,将该字段的渲染方式改为“自动完成”(Autocomplete)。在系统管理→字段→编辑字段→设置渲染器为“Autocomplete Text Field”。
这样下拉框变成输入搜索模式,不再全部加载,加载时间从12秒降为0.3秒(输入后异步查询)。这个改动完全不影响数据结构。方案C(终极优化):如果必须保留完整下拉列表,可以迁移到“选择列表多选”并配置Jira使用缓存。
在jira-config.properties中加入jira.customfield.select.cache.enabled=true,并设置jira.customfield.select.cache.maxsize=10000。
但注意这个缓存是应用层缓存,重启Jira后需要重新预热,首次加载仍慢。独特洞察:云上快是因为它底层使用了Elasticsearch做字段索引,而本地默认不集成。
如果你对搜索性能要求高,可以单独部署Elasticsearch并配置Jira连接(需要购买Data Center版或自行集成第三方插件)。不过对于几千个选项,方案B就够用了。
决策指南: – 选项<200个:无需优化 – 200~2000个:开启自动完成 – 2000个以上:启用缓存或升级ES 我两个月前刚解决了类似问题,团队现在满意度回升到95%。
核心关键词
文章包含AI辅助创作:jira从云端迁移到本地,性能反而下降,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3976185
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为IT运维,这篇太真实了。我们也是500人团队,云迁本地后看板加载从4秒变22秒,一度以为是硬件问题。文章点醒我:数据库默认配置和索引重建才是关键。文中提到的customfieldvalue复合索引和shared_buffers调整,我实测后响应时间从16秒降到6秒,虽然还是比云上慢,但至少能用了。建议所有准备迁移的运维先读这篇,别跟我一样白花钱买服务器又挨骂。
我是一名Scrum Master,迁移后每周Sprint计划会都要等半分钟加载Backlog,团队直接崩溃。文章里说的线程dump分析@提及导致串行阻塞,和我们遇到的场景一模一样。后来按照文中的方法优化了SMTP异步处理,看板响应时间才正常。希望更多决策者看到:云回迁不是简单搬数据,运维成本远不止服务器那6万块钱。
这篇让我彻底放弃了云回迁的念头。作为技术负责人,之前只算了硬件账,没想过Jira Cloud的Aurora PostgreSQL、CDN和弹性扩容根本不是本地能复现的。文中那个@提及功能在云上是异步消息队列,本地却串行执行,这种细节外行根本想不到。与其花时间调优到5秒(仍比云上慢),不如直接评估国产替代方案。感谢作者给的真实数据。
去年我们公司也踩过同样的坑,花了5万买服务器,结果性能比Cloud还差。当时没找到这么详细的排查指南,全靠自己折腾了两个月。特别认同文中的‘架构不匹配’结论,Jira Cloud运行在服务网格上,本地单机就是温室花朵搬进沙漠。现在我们已经切换到某国产工具了,性能稳定且成本只有Jira Cloud的30%。建议中小团队别走回头路了。