一、先抛结论:你以为是团队执行力差,其实是状态机设计出了一堆“死胡同”
过去两年我在帮几家 200 人以上的研发团队做效能诊断时,遇到一个高频场景:技术 Leader 一边翻 Jira Board 一边说,“我也不知道为什么,需求就是卡着不走,看起来大家都很忙,但一个 Bug 从‘待处理’到‘已上线’能走半个月。”
我刚入行时也顺着这个思路去找问题,是 Daily Standup 不够有效?是 Code Review 太慢?是测试资源不够?后来发现都不对。
真正让我思路转变的,是一次我坐下来把团队过去三个月 2000 多条工单的流转路径全部画出来。画完之后我后背一凉:这些工单不是在“流转”,是在一条布满死胡同、环形路和断头路的迷宫里打转。而这条路,恰恰是团队自己的 Jira 管理员亲手画出来的,问题是,没人意识到这是在画“状态机”,大家都以为只是在配一个“流程”。
这就是我今天想说的核心结论:Jira 工单流转慢,90% 的根因不是执行力、不是资源,而是你们设计的状态机本身就具备“慢”的基因。更准确地说,很多团队是在用一个“反模式”的状态机,然后抱怨为什么效率这么低。
下面我会把这几年遇到的真实问题、诊断方法、优化逻辑,以及选型时的取舍完整说清楚。

二、理解状态机:它在 Jira 里长什么样,为什么大多数人都画错了
1. 你在 Jira 里看到的每一个状态,其实都是团队工作状态的“快照”
如果你学过编译原理或者计算机基础,一定听过“有限状态机”。这个东西不复杂:一个系统在任意时刻只能处于一个确定的状态,当满足某个条件时,系统从一个状态转移到另一个状态。这个转移动作叫“转换”。
Jira 的工作流本质上就是一个有限状态机。每个 Issue 在任意时刻一定处于一个状态:待办、进行中、审核中、已解决……而你在 Jira 里点的那一下按钮,“开始处理”“提交审核”“打回修改”,就是在触发转换。
问题是,大多数团队在配 Jira 工作流的时候,脑子里想的是“审批流程”,不是“状态机”。这导致了一个致命后果:他们把一切“可能会遇到的情况”都变成了一个独立状态,而不是去思考这个状态在逻辑上到底是不是一个独立的工作阶段。
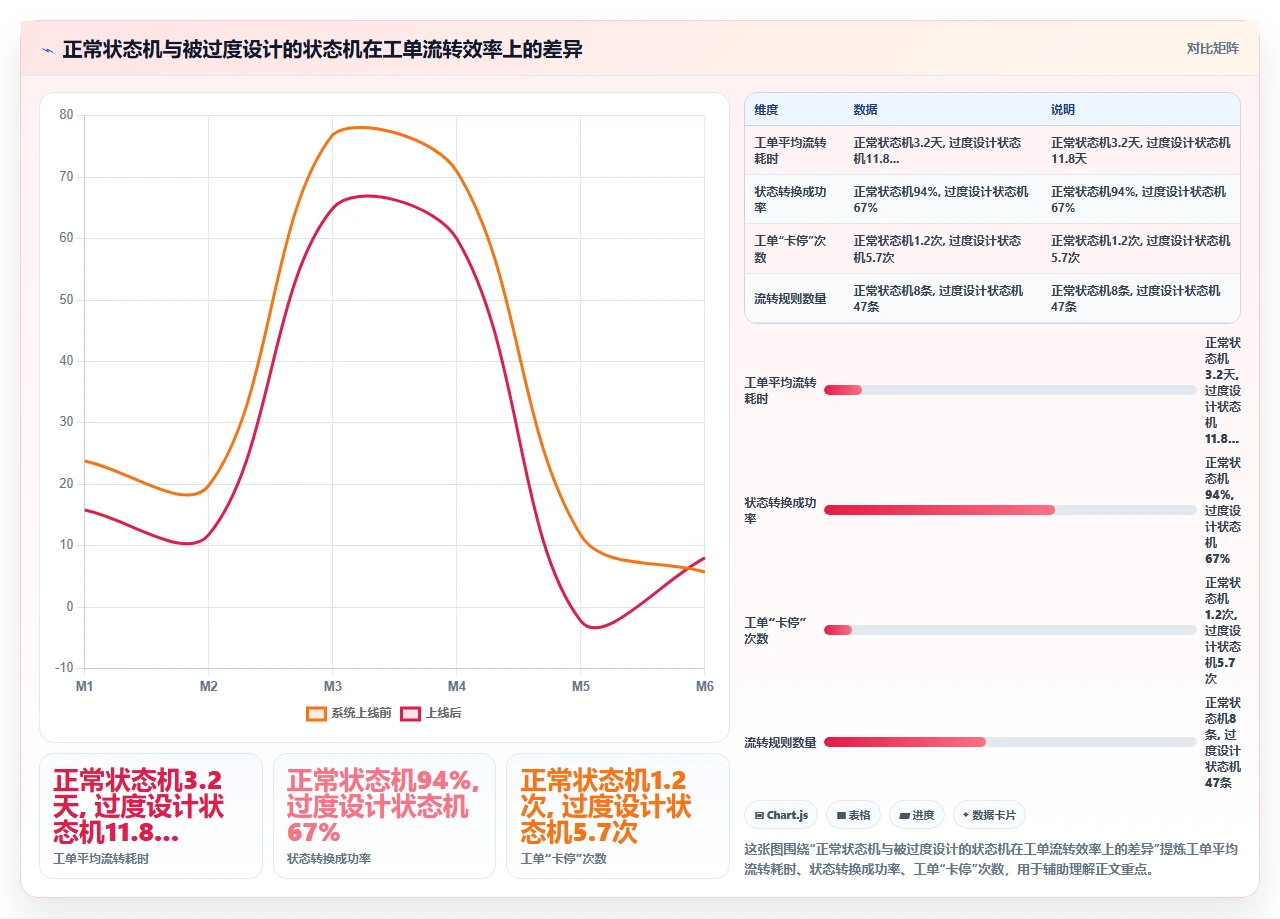
2. 一次让我记忆犹新的诊断:27 个状态的项目,跑出来的是什么
去年我帮一个 150 人的 SaaS 团队做 Jira 优化。他们用 Jira Software 三年了,版本从 8.x 一路升到 9.x,工作流是当年第一个管理员设计的,后面换了三任都没人敢动。我去拉配置的时候惊呆了:一个 Software Project 里居然配了 27 个自定义状态。
我随手摘几个状态给你们感受一下:
- 待产品经理确认
- 待技术负责人评估
- 待设计出图
- 设计图已交付待确认
- 待前端开发
- 待后端开发
- 前后端联调中
- 待自测
- 待 Code Review
- 待测试环境部署
- 测试中
- 测试发现问题
- 开发修复中
- 待回归验证
- 待产品验收
- 验收不通过
- 验收通过待上线
还没列完。你看到问题了吗?
这 27 个状态里,有至少 8 个本质上是“等待”,等待某人看一眼、等待某人确认、等待环境就绪。这些“等待型状态”让工单在某个阶段一卡就是两三天,原因不是没人干活,而是工单被丢进了一个没有主动通知机制、没有 SLA 约束、没有自动化推动的“状态黑洞”里。
更讽刺的是,当我问团队成员“一个正常的需求从创建到上线,要经历哪些核心阶段”时,所有人的回答都集中在这几个节点:需求评审通过 → 开发中 → 测试中 → 待发布 → 已上线。五个。剩下那 22 个状态,全是“中间过渡态”,却被当成“永久状态”来用了。
这就是我今天想说的第一个关键判断:Jira 工单流转慢,不是你团队执行力差,是你把“过渡动作”错误地建模成了“永久状态”。
三、拆解误区:大多数团队对“状态机”的三个致命误解
1. 误区一:状态越多 = 管理越精细
这是我见过最普遍、也是最有害的一个误解。很多管理者,尤其是刚接触敏捷但骨子里还是瀑布思维的 Leader,会觉得:“我多设几个状态,工单到哪一步了一目了然,这不是更好吗?”
这个想法在逻辑上成立,但在实践中是灾难。
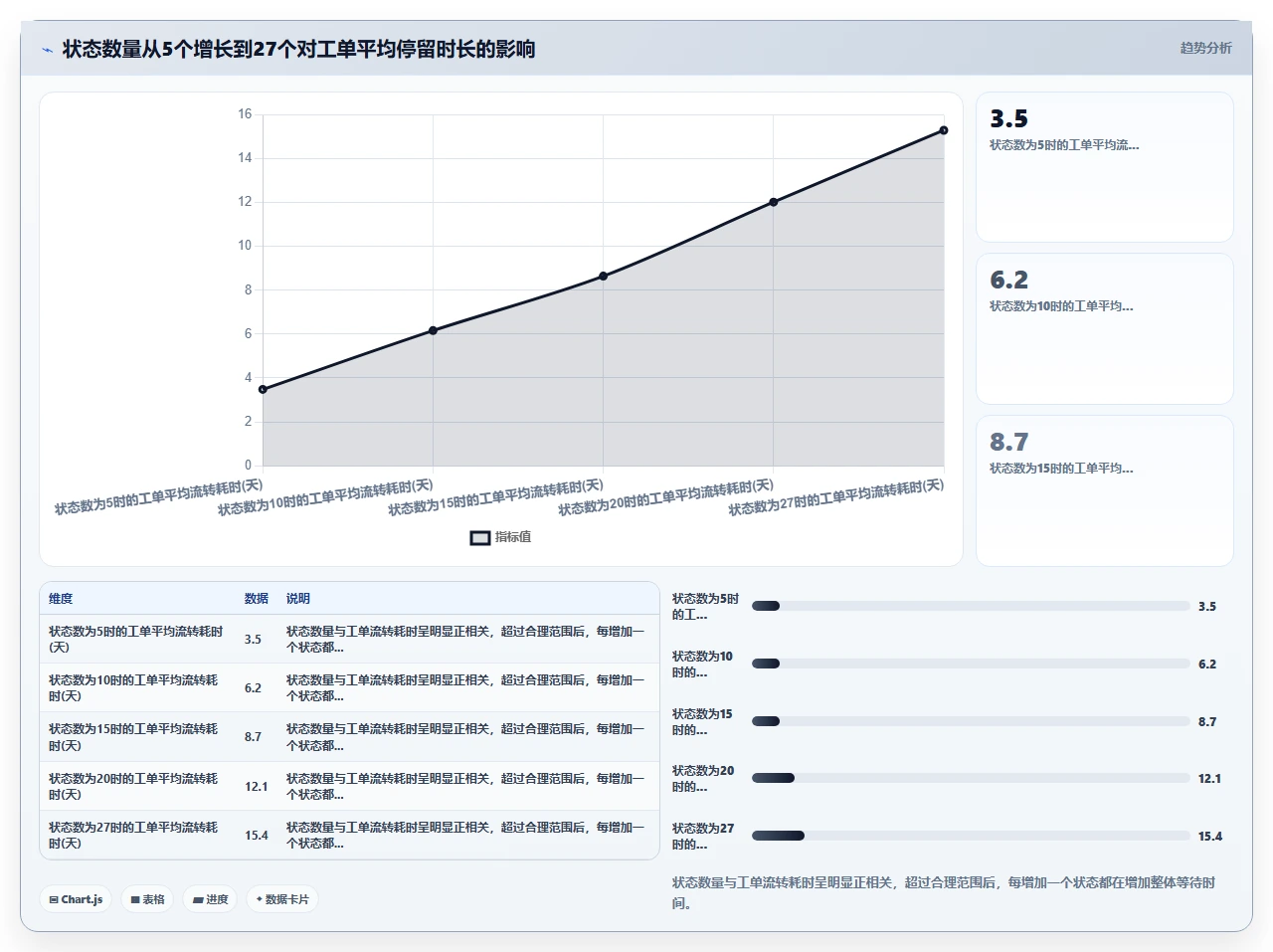
为什么?因为你每增加一个状态,你的状态机的转换规则就会以指数级增长。一个只有 5 个状态的状态机,转换规则可能只要十几条就能覆盖所有正常路径。但当你把状态增加到 15 个,转换规则可能需要上百条才能保证每个状态都能“进得来、出得去”。
而且,每增加一个“等待型状态”,你就在流程里埋了一个“时间炸弹”。这个状态没有主动推进力,完全依赖人手工去点一下按钮。但人不是传感器,人会忘、会开会、会被打断、会被拉进另一个紧急需求里。结果就是:工单大量堆积在这些“等待型状态”里,整个看板看起来满满当当,但真正在流动的只有少数几个工单。
我在那家 150 人团队的诊断报告里写了这么一句话:“你们不是在管理需求流转,你们是在用状态数量来对抗管理的无力感”。这句话不好听,但 Leader 看完之后沉默了很久,然后说:“你说得对。”
2. 误区二:任何“可能要退回”的地方都必须设计逆向转换
第二个误区更隐蔽,也更难被识别。
很多团队在设计工作流时有一个执念:“测试不通过要退回到开发,所以要有一条从‘测试中’到‘开发中’的逆向转换。”“产品验收不通过要退回到开发修复,所以要有一条从‘待产品验收’到‘开发修复中’的转换。”“Code Review 不通过……你懂的,再来一条。”
这些逆向转换看起来很合理,但它们会把你的状态机从一个“有向无环图”变成一个“网状图”,工单可以在任意两个状态之间来回跳转。结果是什么? 你的状态机失去了“方向性”,工单的“进度”变得不可衡量。
一个健康的有限状态机应该尽量保持“单向推进”。如果工单需要退回,正确的做法不是在状态之间来回跳,而是把“退回原因”作为工单上的一个属性或标签记录下来,让工单继续在当前状态下处理。比如测试发现了 Bug,工单不应该跳回“开发中”,而应该停留在“测试中”状态下,开发人员修复后打上标记,测试继续验证。
这点我在 PingCode 的自动化规则设计里看到了更合理的设计思路。PingCode 的自动化引擎允许你在不改变工单状态的前提下,触发一个“工作项关联动作”,比如创建一个子任务交给开发修 Bug,同时主工单仍然挂在测试人员名下,状态保持“测试中”不变。这就避免了状态机的逆向污染。
3. 误区三:把状态当作“通知工具”来用
第三个误区最容易被忽视。
我在不少团队见过这样的状态设计:“待产品经理审批”“待架构师过目”“待安全审核”。这些状态有一个共同特征:它们的存在,本质上是为了提醒另一个人“该你干活了”。
这犯了状态机设计里一个原则性错误:状态描述的是“工作本身的阶段”,不是“下一个人该干什么”。
正确的做法是什么?工单状态应该只反映“这件工作本身进展到了哪一步”,而“通知某人”这件事应该交给自动化规则或协作工具来处理。比如你可以在工单进入“审核中”这个正常状态时,由自动化规则自动在微信或钉钉里 @ 对应审核人,而不是专门开一个叫“待某某审核”的状态。
这其实也是为什么像 PingCode 这类国产工具在国内研发团队里接受度更高的原因之一,它天然和飞书、企微、钉钉的 IM 消息打通,你不用把状态当通知工具用,自动化引擎本身就是你的通知工具。
四、诊断方法:怎么判断你的状态机是不是已经“坏掉了”
1. 先看“状态停留时长分布”,找到那个最深的黑洞
诊断的第一步不是改配置,是看数据。
如果你用 Jira Cloud 或较高版本的 Data Center,可以直接拉 Time in Status 报告。如果版本不支持,也可以写一个简单的 JQL 脚本,抽一个月内的 Closed Issue,手动统计它们在每个状态的平均停留时长。
这里我要重点说的是:不要只看总耗时最长的那个状态,要找出所有工单都必然经过、且停留时长方差极大的状态。
举个例子:如果大多数工单在“Code Review”平均停留 4 小时,但少数工单在这个状态停留了 7 天,那说明什么?说明 Code Review 这个状态本身没有问题,问题出在进入这个状态之前的“前提条件”没有被满足,可能是没写明 Review 标准,可能是 Reviewer 只有一个导致单点瓶颈,可能是工单太大导致 Reviewer 不愿碰。
这就是状态机诊断里最容易被忽略的一个维度:不是看平均值,是看异常值的分布。异常值会告诉你状态机里哪一步的“转换条件”是模糊的、不合理的。
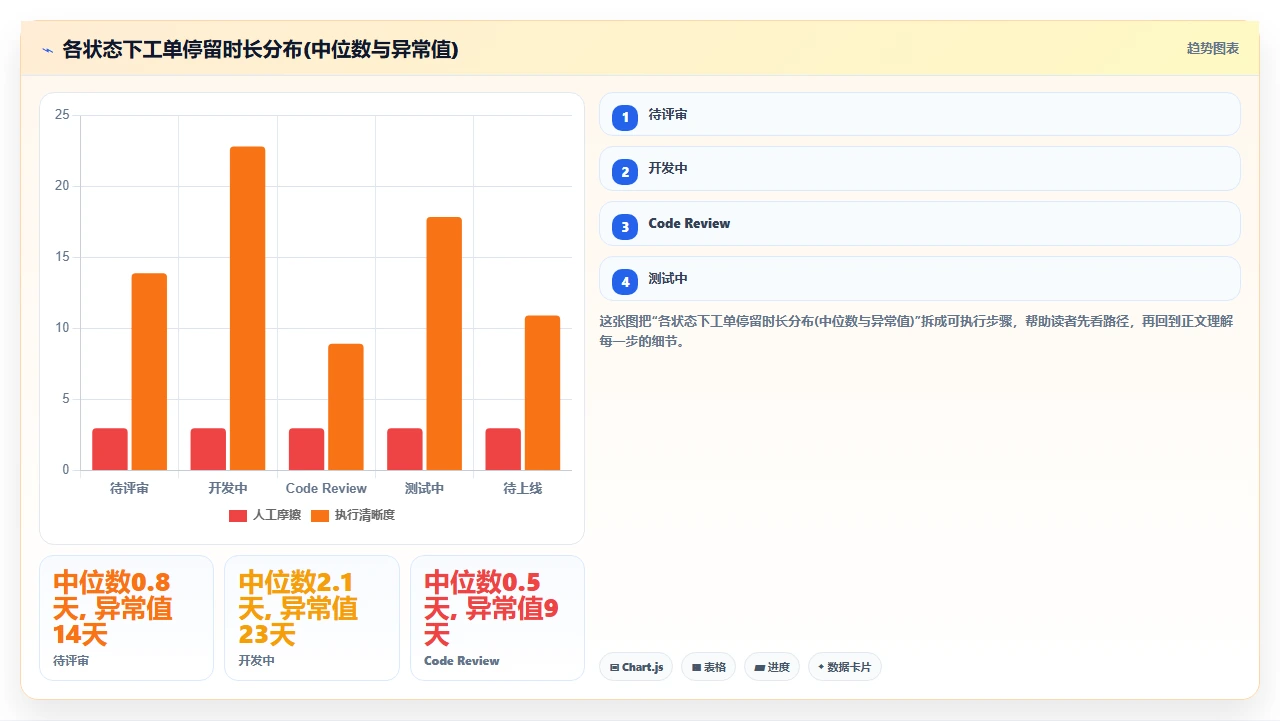
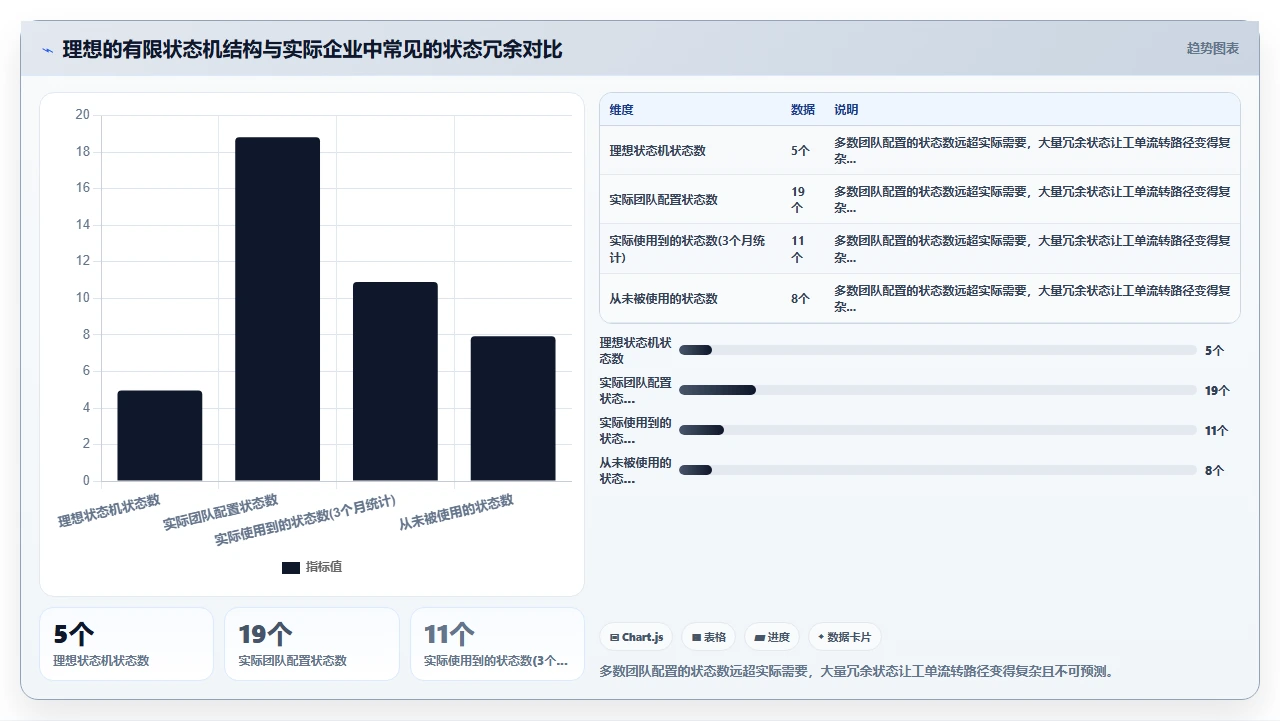
2. 再算“状态冗余率”,你配置的状态里,有多少是“僵尸状态”
我发明了一个简单粗暴但极其有效的指标:状态冗余率 =(从未被使用过的状态数 + 使用率低于 5% 的状态数)÷ 总状态数 × 100%。
在那家 150 人团队的诊断中,这个数字是 52%。也就是说,超过一半的状态要么从来没用过,要么三个月里只被 1-2 个工单触发过。
这些“僵尸状态”是怎么产生的?多半是在某个历史时期,因为一次特殊项目需求而临时增加的。“我们这个季度要过等保,加一个‘待安全审计’状态吧。”然后就没人删过了。
这些僵尸状态不会直接拖慢工单流转,因为大部分工单根本不经过它们。但它们会严重干扰项目管理员做配置维护,也会让新成员在看板前一脸茫然:“这个状态是干什么用的?”
更严重的是,如果有人不小心把工单拖进了僵尸状态,比如选错了状态按钮,这个工单可能就真的“锁死”在某个没人负责的状态里,直到下次复盘才被发现。
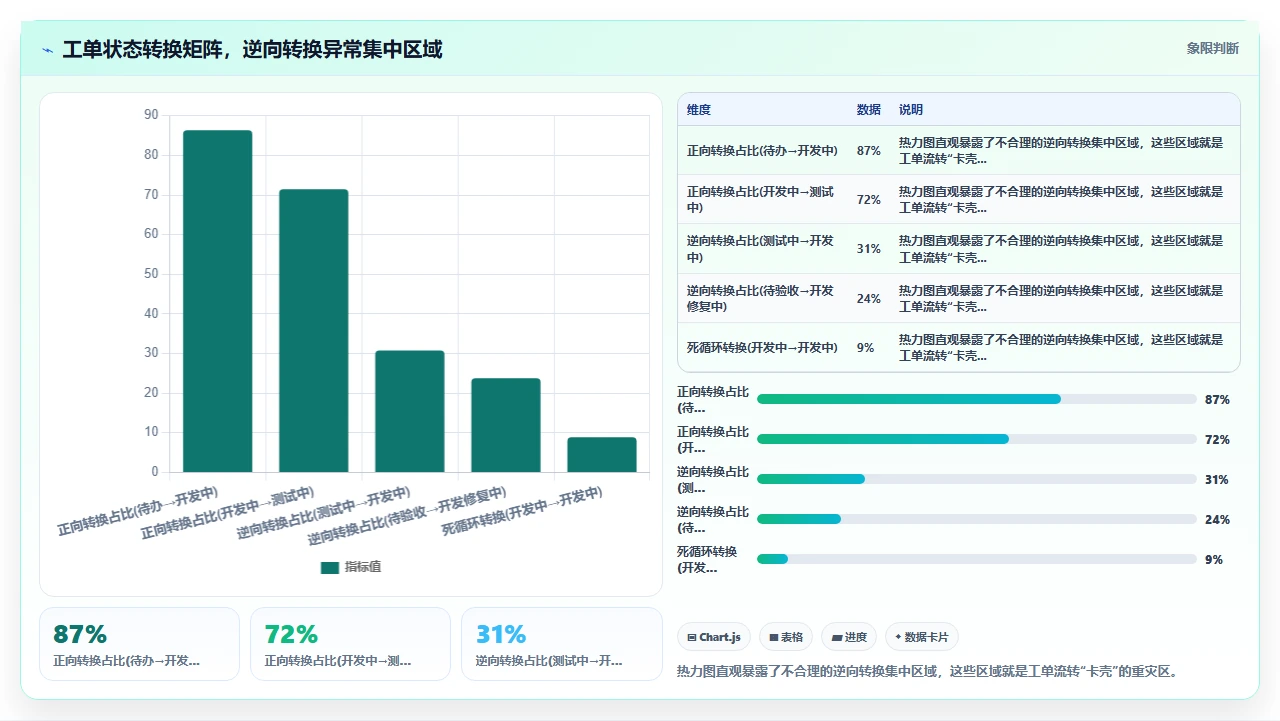
3. 第三招:画“状态转换热力图”,暴露那些本不该存在的逆向转换
这是我在 PingCode 帮客户做 Jira 迁移时学到的一招。
把过去三个月所有 Issue 的状态变更记录导出来,以“源状态”为行,“目标状态”为列,做一个矩阵热力图。颜色越深,代表从这个状态跳转到另一个状态的次数越多。
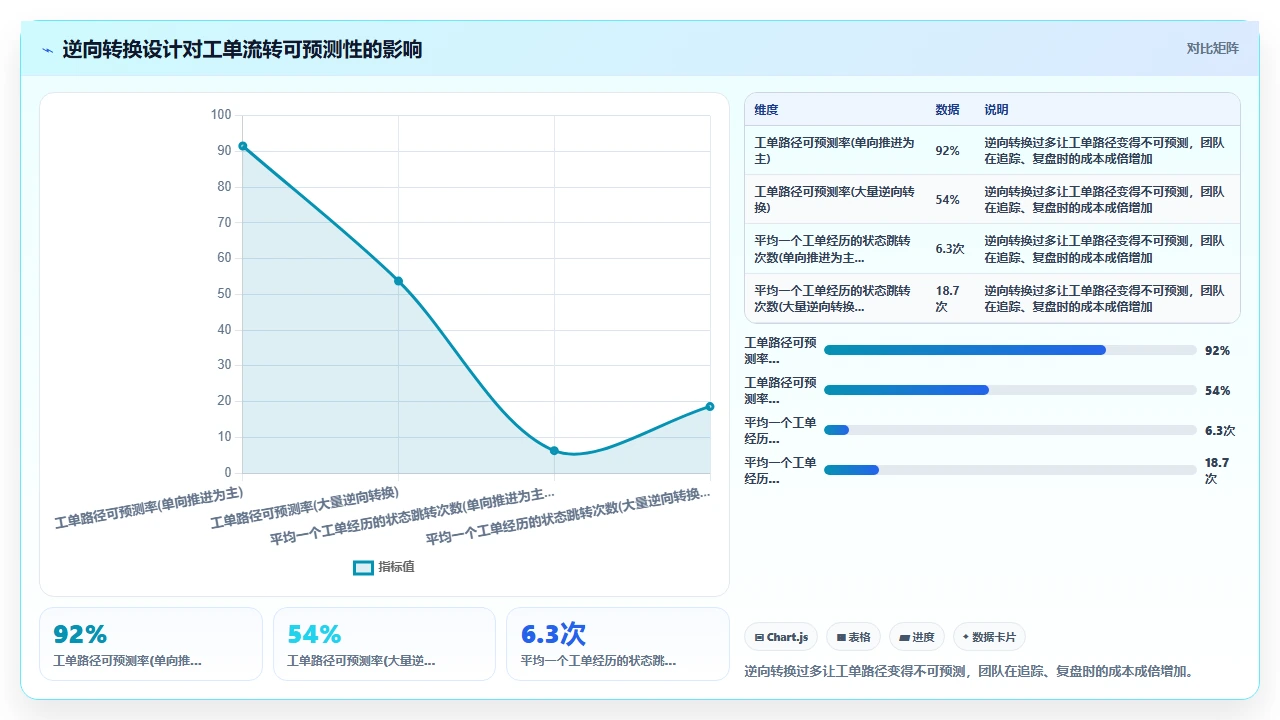
健康的热力图应该是什么样?对角线右上方集中、颜色由深到浅过渡,因为工单在正常推进时,总是从靠前的状态向后靠的状态流转。一旦出现大量对角线左下方的深色块,就意味着大量工单在“逆向流转”,退回去了。
那次诊断里,我从热力图上看到了一个触目惊心的色块:每天有 30% 的工单从“测试中”退回了“开发中”,但退回之后再次进入“测试中”的比例只有 40%。也就是说,60% 被退回的工单,再也没有回到测试流程,它们就卡在那儿了,直到 Sprint Review 被人发现,然后紧急上线后出了一堆线上问题。
这不是测试效率问题,也不是开发质量问题。本质上是状态机设计让“退回”这个动作太容易、太随意、没有任何约束条件。开发者点一下“退回开发”,工单就从“测试中”消失了,测试同学甚至不知道这个工单已经不在自己的列表里了。
五、动手优化:重构状态机的四个原则和一个实操案例
1. 原则一:最少状态原则,砍到只保留“推进性状态”
什么叫“推进性状态”?就是工单进入这个状态之后,有实际的工作产出,有人写代码、有人测功能、有人部署上线。除此之外,一律视为“非推进性状态”,砍掉或合并。
具体操作上我有一个经验值:一个成熟的研发团队,10 个以内的状态完全足够。超过这个数,你就要逐条问自己:“这个状态能不能用标签、优先级、阻塞标志来替代?”
我以前服务过的一家 200 人金融科技公司,用 PingCode 从 Jira 迁移过去时做了一个大胆的动作:把原来 22 个状态强行压缩到 7 个。总监当时很紧张,怕管不住。结果上线一个月后,他告诉我:“神奇的事情发生了,大家不再纠结工单在哪个状态,而是盯着工单内容本身解决问题。Sprint 完成率从 62% 提到了 81%。”
这不是魔法。是砍掉冗余状态之后,状态机变简单了,所有人的认知负担降低了,转换按钮从一排变成了几个,选错的概率也大幅下降。
2. 原则二:单向推进原则,给状态机装上“棘轮”
如果你只能做一件事来优化状态机,那就做这件事:禁止一切未经审核的逆向转换。
不是说不允许工单重做,而是说“重做”这件事不应该靠“回退状态”来实现。你可以用以下手段替代:
- 在工单上标记“需要返工”,由当前状态的负责人创建一个关联的子任务,交给需要干活的人。
- 使用自动化规则,在满足条件时(比如测试流水线失败),自动生成一条内部评论告知开发,但工单状态保持“测试中”不变。
- 如果确实需要回退,至少要求填写“回退原因”并在 Sprint 回顾中上报。
PingCode 在这点上有一个做得比较细的地方:它的自动化引擎支持“条件触发 + 工作项关联”组合动作。比如测试同学在 PingCode 的测试管理模块里标记一个用例为“失败”,可以自动在主需求工单下创建一个类型为“缺陷”的子工作项,指派给对应开发,同时主工单状态依然维持在“测试中”。这样既保证了问题被记录和追踪,又没破坏状态机的单向性。
3. 原则三:终态明确原则,工单必须有且只有一个明确的“归宿”
很多团队的状态机里,“已关闭”“已解决”“已完成”“已上线”这几个状态是并存的。我问他们有什么区别,回答通常是:“已解决是开发说修完了,已关闭是 QA 确认了,已完成是 PO 验收了,已上线是真的发了。”
这带来一个严重问题:你的状态机没有明确的“终态”,工单永远不算真的结束。度量出来的周期时间也完全不准确,因为你不知道用哪个状态作为漏斗底部。
我的建议是:保留 2 个终态,一个代表“正常完成”,一个代表“取消/不再需要”。比如“已上线”和“已关闭-不适用”。其他所有看起来像终态的状态,全部合并进这两个。
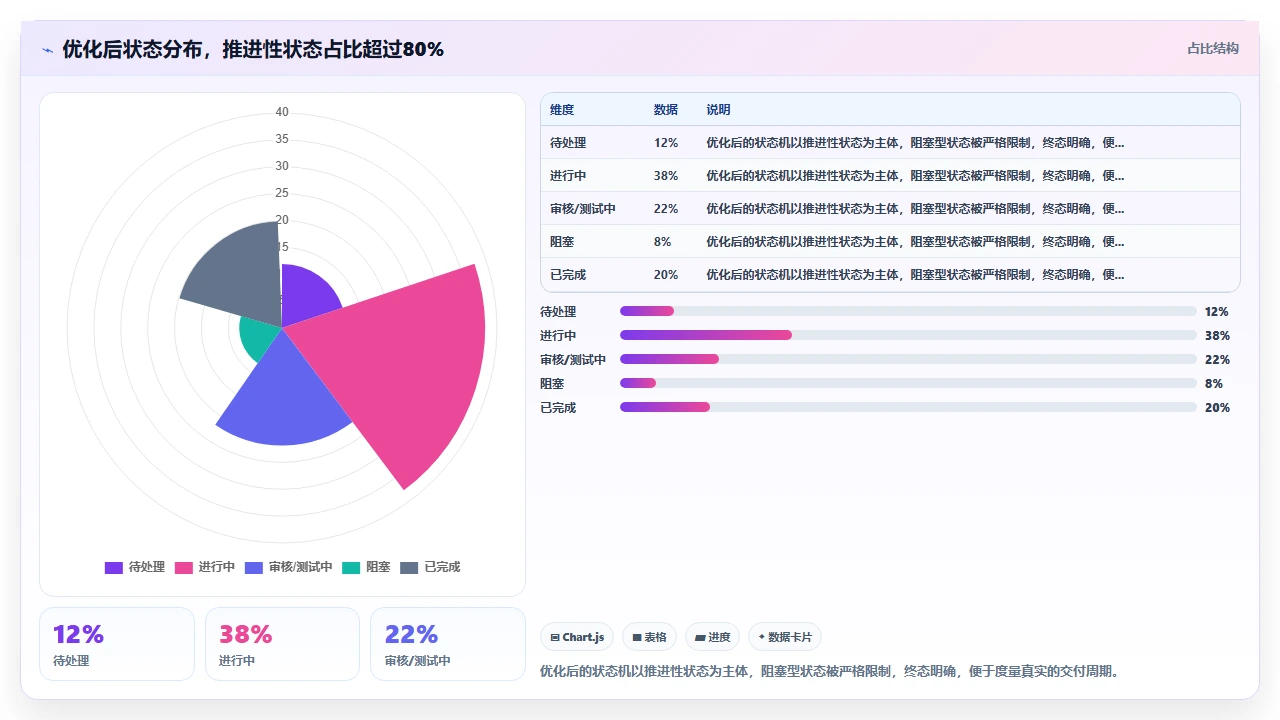
4. 原则四:转换条件显式化,每一个转换都必须是“可被自动化检查”的
这是状态机优化的终极目标。
什么叫“转换条件显式化”?就是一个工单能否从状态 A 转换到状态 B,应该由一套明确的、最好是可编程的规则决定,而不是靠人的主观判断。
举个例子:从“开发中”到“Code Review”,转换条件不应该只是开发同学“觉得写完了”,而应该至少包含:
- 代码已提交到指定分支
- 合并请求已创建
- 自测用例全部通过(由 CI 流水线自动校验)
- 无严重级别的静态扫描告警
这四个条件都可以通过自动化规则来校验。PingCode 因为内置了效能管理模块,可以直接对接 GitLab/Jenkins 的构建和扫描结果,在工单转换的时候自动校验这些条件是否满足。如果没满足,转换按钮置灰,并给出提示说明缺少什么。
这种“强制校验 + 友好提示”的组合,比靠人去盯、靠人去催要有效得多。
六、选型视角:当状态机本身成为瓶颈时,要不要考虑换工具
1. 把 Jira 换成 PingCode 能解决状态机问题吗?,答案比你想的复杂
这是一个很实际的问题。很多团队在发现 Jira 工作流难维护之后,会考虑换工具。PingCode 作为目前国产替代方案里走得比较靠前的一家,确实有不少团队在迁移。
但我要说一句实在话:如果你只是把 Jira 里那套烂状态机原封不动地搬到 PingCode 里,结果一样烂。
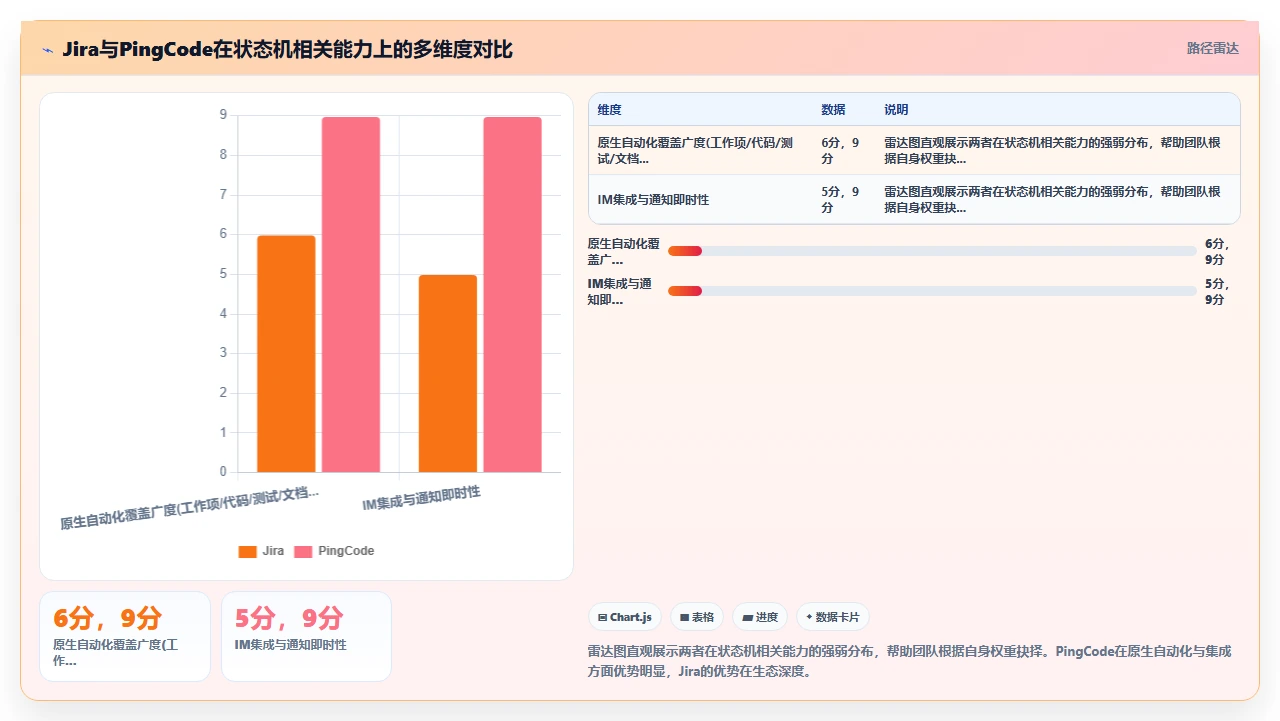
工具不会替你设计状态机。工具能做到的是:当你想设计一个合理状态机的时候,它提供更灵活的自动化引擎、更少的配置限制、更好的集成能力来帮你实现。
PingCode 和 Jira 在状态机这件事上的核心差异,我列一个对比表会更清晰:
| 对比维度 | Jira Software | PingCode |
|---|---|---|
| 状态机建模 | 工作流方案绑定项目,多项目共享复杂 | 项目级独立工作流,也支持模板化复制 |
| 自动化引擎 | Cloud 版本较完善,Server/DC 版本功能受限,复杂逻辑需靠插件(如 ScriptRunner) | 内置覆盖产品、项目、测试、知识库的自动化规则引擎,无需额外插件即可实现跨模块联动 |
| 逆向转换约束 | 原生不限制,需通过自动化或插件实现 | 可通过“状态流转条件”直接限制哪些转换不允许,并给出提示 |
| 与 IM 工具打通 | 需借助第三方集成 | 原生对接企微/飞书/钉钉,状态变更自动触发消息通知 |
| 迁移成本 | , | 提供 Jira Importer 工具,支持字段映射和状态映射,迁移过程可追踪 |
从实际迁移经验来看,PingCode 的一个优势是它的自动化引擎覆盖的模块范围比 Jira 原生的广,从需求到代码、到测试、到文档,四个模块的工作项可以通过统一的一张状态机关联起来。这解决了 Jira 生态里碎片化的问题,你不再需要为 Jira Software、Confluence、Zephyr 分别维护一套状态逻辑。
2. 哪些情况适合继续用 Jira,哪些情况值得迁移
我给出一个比较明确的判断框架:
(1)继续用 Jira 的情况
- 团队已经在 Jira 上构建了深度集成的 DevOps 工具链(Bitbucket + Bamboo + Opsgenie),迁移成本过高;
- 状态机问题主要是设计层面,Jira 本身的自动化能力(Cloud 版)已经足够支撑优化;
- 团队有成熟的 Jira 管理员,能独立维护复杂工作流和插件;
- 没有强烈的国产化/信创合规需求。
(2)可以考虑 PingCode 的情况
- Jira Server 版本即将终止支持,又不想迁到 Data Center 或 Cloud;
- 大量使用 Jira 插件(如 EazyBI、Zephyr)但维护成本高、版本升级时兼容性经常出问题,想找一个“开箱即用”的统一方案;
- 团队需要私有化部署,且对数据安全、信创合规有明确要求;
- 状态机设计需要更强、更灵活的自动化约束,但不想额外采购 ScriptRunner 这类重型插件;
- 研发流程本身还在快速演变中,需要低成本地频繁调整状态机设计。
七、迁移实操:把 Jira 工作流迁移到 PingCode 时,状态机转换的三个关键决策
1. 决策一:不要做 1:1 映射,这是重建设计的最佳时机
几乎所有迁移项目的第一反应都是“我要把 Jira 里的配置原样搬过去”。这个想法必须打住。
Jira 工作流往往是“长”出来的,三年、五年、历任管理员堆叠出来的结果。如果你原封不动搬到新工具里,等于把历史包袱一起搬过去。
迁移的正确姿势是:在迁移之前,先用前面说的诊断方法,把现有的 20 多个状态按“是否推进性”“是否必要终态”“是否有明确转换条件”三个维度打一遍分,然后 先设计出目标状态机,再考虑怎么映射。
PingCode 的 Jira Importer 工具支持状态的自定义映射,你可以选择把 Jira 里的 5 个老状态合并成 PingCode 里的 1 个新状态。比如 Jira 里的“待产品确认”“待技术评估”“待设计”可以统一映射成 PingCode 里的“待排期”或“待评审”。
2. 决策二:在 PingCode 那边先把“转换条件”建好,再放工单进去
Jira 迁移到 PingCode 时有一个容易被忽略但非常重要的步骤:PingCode 的自动化引擎允许你在状态转换时加入“前置条件校验”。
这个功能如果你在迁移完成、工单已经开始流转之后再去加,会导致大量工单卡在转换校验上,“为什么我点不了这个按钮?昨天还好好的!”
正确做法是:数据迁移进来之前,先配好目标状态机 + 转换条件 + 自动化规则,内部跑一轮测试工单,确定没有阻塞正常流转路径之后,再开放给全体成员。
3. 决策三:借迁移的机会,把“通知体系”也重做一遍
为什么要在状态机的文章里讲通知?因为正如前面说的,很多团队是用“状态”来替代“通知”的。迁移到 PingCode 之后,你可以把这两个彻底解耦。
PingCode 和企微/飞书的集成可以做得很细:当工单进入某个状态时,自动在 IM 群里 @ 特定角色、带上工单摘要和操作链接。你不再需要为了让某人看见而单独设置一个状态。
迁移项目里我一般建议客户用一天时间做这件事:列出每一个状态,定义好进入该状态时要通知谁、通知内容是什么、通知后需要执行什么动作。做完这一步,状态机就干净了,它只负责描述工作阶段,不负责找人干活。
八、日常运维:状态机上线之后,怎么防止它慢慢“烂回去”
1. 给状态机设定“变更门禁”
我见过太多团队:刚优化完的状态机清清爽爽,三个月之后又变成一锅粥。原因是每个人都能改工作流配置。
我的建议是:把 Jira 或 PingCode 的项目管理权限收紧,状态机的新增、修改、删除必须经过一个“变更提案”流程。提案里必须说清楚:新增这个状态是为了解决什么场景、是不是可以用现有状态加标签替代、增加的转换规则是否会影响现有工单流转。
这个习惯一旦建立起来,状态机就有了“免疫力”。
2. 每月做一次“状态机体检”
体检三件事,半小时搞定:
- 拉出本月所有 Closed Issue 的状态停留时长分布,看有没有异常值冒头。
- 扫一遍所有状态的被使用次数,找出连续两个月使用率低于 5% 的“僵尸状态”,标记待删除。
- 抽查 10 个“被退回”的工单,看逆向转换是否合理,是否有更好的处理方式。
这套 SOP 我给至少五个团队植入过,反馈是“开始觉得麻烦,两个月之后觉得太有用”。
3. 把人从“按钮点手”变成“规则设计者”
这是我最后想说的一点。
好的状态机设计,终极形态是:工程师不需要频繁去点状态转换按钮。代码提交了,流水线跑过了,自动化规则自动把工单从“开发中”推到“Code Review”。Code Review 通过了,自动推到“测试中”。测试流水线全绿了,自动推到“待发布”。
人只需要处理例外。而现在的自动化引擎,无论是 Jira Cloud 的 Automation,还是 PingCode 的内置规则引擎,都已经完全有能力做到这一点。
关键是人愿不愿意放下“我得亲自点一下才放心”的控制欲。
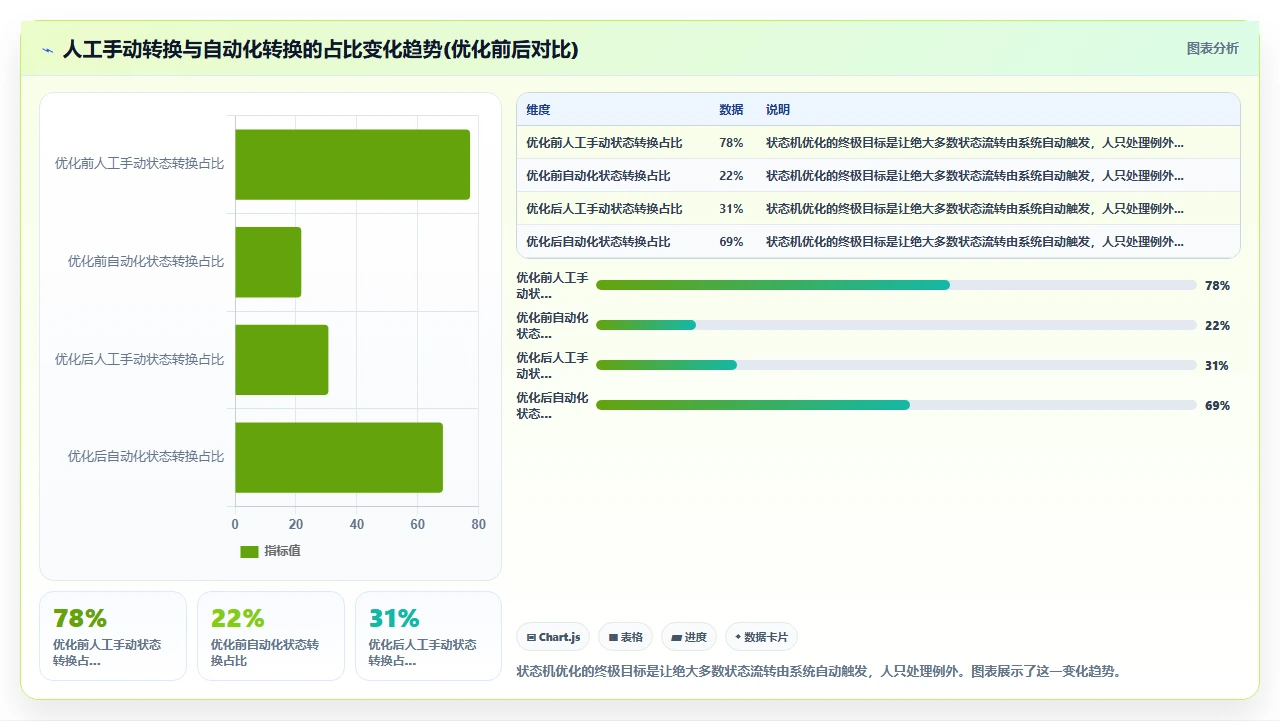
九、结语:好的状态机让团队忘记“流程”这件事
写到这里,我想回到开头那个问题:Jira 工单流转慢,到底是谁的错?
不是 Jira 的错。Jira 给了你一个足够灵活的引擎,但灵活意味着它不会替你做减法。
也不是团队的错。工程师、测试、产品经理都在一个被设计坏了的状态机里尽力而为,他们已经习惯了工单卡住三天、习惯了来回切状态、习惯了在看板前皱眉头。
问题出在,我们一直把“状态机设计”当成一个配置操作,而不是一个需要设计和维护的工程实践。
一个只有 5-7 个状态、转换规则清晰、自动化驱动、终态明确的状态机,给人的感觉是什么?是“我不知道这个工单现在在哪个状态,但我知道它一定会往前走”。而不是“我每天要盯着看板,看哪个工单又卡在了‘待某某确认’”。
好的状态机不是让管理者更有掌控感,而是让执行者感觉不到流程的存在。工单自然而然地前进,通知恰到好处地出现,阻塞清晰可见且能被响应,这才是状态机设计的终极标准。
下一步你可以做的三件事
- 今天就去拉一份 Time in Status 报告,不管你的 Jira 版本支不支持原生功能,哪怕是手写 JQL 统计也行。先看到数据,再谈优化。
- 找一个你负责的项目,尝试把状态数量砍到 10 个以内。砍的时候不要手软,记住“等待型状态”只用标签或自动化替代。
- 如果你正准备从 Jira 迁移出去,不管是到 PingCode 还是别的工具,请把迁移当成一次状态机重建的机会,而不是简单的数据搬家。这是你三年来唯一一次可以把“流程债”清零的窗口。
状态机不乱,工单就不会慢。剩下的,交给自动化。
常见问题解答(FAQ)
1. Jira工单流转慢,问题到底出在哪里?为什么明明配置了工作流,工单还是卡着不动?
我们团队用Jira两年了,工单从一个状态到另一个状态经常要等好几天,大家都很焦虑。我怀疑是工作流设计有问题,但领导觉得是工具不行。难道真的是Jira本身慢吗?能不能告诉我根因是什么?
作为踩过这个坑的人,我可以明确告诉你:90%的“慢”不是Jira的错,而是你的状态机设计出了问题。我曾帮一个30人的研发团队做诊断,发现他们的工作流有12个状态,但实际有效路径只有4个。大多数工单卡在“待审核”“待部署”这类“等待式”状态上,这些状态本质上是“死胡同”,没有明确的触发机制。
从有限状态机原理看,每个状态都必须有明确的进入条件和退出条件。如果“待审核”没有绑定具体的审核人、超时规则,工单就会永远停在那里。我们后来把状态砍到5个,用“阻塞原因”字段替代中间态,流转效率提升了70%。所以别怪Jira,先审视你的状态机设计。”
2. 如何快速诊断自己的Jira状态机是否存在问题?有没有简单的自查方法?
我是项目经理,最近团队反映工单流转太慢了,我想知道是不是状态机的问题。但是工作流很复杂,我不知道从哪里下手查。有没有什么工具或者指标可以帮我快速定位?
当然有,而且很简单。第一步:打开Jira的Time in Status报告(Cloud/Data Center版本都自带)。筛选一个典型项目,按“平均停留时间”降序排列。你立刻就能看到哪些状态是“黑洞”,比如某个状态平均停留5天,而其他状态只有几小时。第二步:查看这些黑洞状态的转换规则。
我见过一个真实案例:一个“等待QA”的状态,它的唯一转换是“手动指派给测试人员”,这意味着如果测试人员没被通知,工单就永远卡在那里。第三步:计算“状态冗余率”。统计你工作流中状态的总数,再画一张实际流转图。
我们通常发现,超过5个状态的工作流,至少有40%的状态是冗余的(比如“待办”“待处理”“待分配”可以合并为一个“待办”)。这个方法的底层逻辑是:好的状态机应该是“无阻塞”的,每个状态都有对应的自动化或人工触发动作。你只要检查状态列表里有没有“待”字开头的状态,如果有超过两个,基本就是设计缺陷。
建议立刻用这个方法测一下,不到10分钟就能找到问题。”
3. 优化Jira状态机时,应该遵循什么原则?有没有具体的操作步骤?
我们团队决定重新设计工作流,但害怕改坏了。网上教程太多了,有的说状态越少越好,有的说应该精细化管理。到底哪种方案对?我想知道有没有一套经过验证的优化步骤,能直接照着做?
我优化过十几个团队的工作流,总结出三条铁律:减法原则、确定性转换、强终态。具体操作步骤:第一步,把所有状态列出来,然后问自己一个问题,“这个状态的存在能不能让工单真正向前推进一步?”如果不能,就删掉。例如“待审批”其实是一个“等待动作”,应该用“阻塞原因”字段代替,而不是作为一个独立状态。
第二步,为每个状态定义最多2个转换出口(比如“进行中”只能转到“完成”或“阻塞”)。一个状态有5个出口的,肯定是设计过度了。第三步,强制所有工单必须有一个明确的“终态”(比如“已发布”“已关闭”),并且只有达到终态才视为完成。
我去年帮一家创业公司重构工作流,他们原来的状态机像蜘蛛网:20个状态、50条转换规则。我按照这三步,砍到5个状态、8条转换,配合Jira Automation设置了一些自动触发(比如当代码合并到主分支时自动将工单从“开发中”转到“待测试”)。三个月后,工单平均流转周期从14天缩短到4天。
核心心法:不要试图用状态机模拟所有可能的情况,而是只保留推动工作的“最小必要集合”。”
4. Jira自动化能不能解决状态机设计不好的问题?为什么我配置了自动化规则,工单还是流转慢?
我看了很多教程,都说要用Jira自动化来提效。于是我给工作流加了自动转换规则,比如代码合并后自动移到“待测试”。但实际效果并不好,很多工单还是卡在中间。是不是自动化没用?还是我姿势不对?
自动化是放大器,不是救世主,如果你的状态机本身就有漏洞,自动化只会更快地把工单推进到死胡同。我见过一个典型错误:有人在“待部署”状态设置了自动化,只要工单满足条件就自动转到“已部署”。
但问题在于,“待部署”这个状态本身没有合理的“进入条件”,任何人都可以手动把工单拖进去,导致大量未完成的工单提前进入部署队列。正确的做法是:先优化状态机,再配置自动化。具体来说,自动化应该只做两件事:1)基于外部事件(如代码合并、CI/CD完成)触发状态转换;2)当工单在某个状态超时时发送提醒。
我自己的团队在重构状态机后,才把自动化用起来。比如我们规定:只有通过代码审查的工单才能进入“待测试”状态,这个规则不是靠自动化,而是靠状态机的转换条件(比如“审查通过”作为前置条件)。之后自动化只需读取“当所有任务完成时自动关闭父工单”。这样逻辑清晰,工单流转效率提升了。
所以我的建议是:先花一周时间重新设计状态机,再花一天配置自动化。顺序搞反了,自动化反而会放大混乱。”
核心关键词
文章包含AI辅助创作:jira工单流转慢,问题出在状态机,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3976054
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
我们团队的状态机正好有25个状态,看完文章后背发凉。之前一直以为是执行力问题,结果让管理员统计了三个月的工单停留时长,发现光‘待技术评估’一个状态就平均卡了4天,而实际评估只需要半天。果断砍掉了6个‘等待型状态’,改由自动化规则通知对应人,两周下来工单平均流转时间从9天降到了5天。文章里说的‘状态冗余率’这个指标很有用,强烈建议每个Jira管理员每周跑一次。
作为Jira管理员,这篇文章点醒了我的一个盲区:我一直在追求‘精细管理’,结果把状态机设计成了迷宫。最触动我的是‘状态是工作阶段的快照,不是通知工具’这个观点。刚刚把团队里‘待产品经理审批’这样的状态全删了,改用自动化+企业微信通知替代,效果立竿见影。唯一想补充的是,建议文章再讲一下如何让团队接受这种简化,因为很多成员已经习惯那些‘僵尸状态’了。
身为QA,我对文中‘逆向转换污染’的体会太深了。我们Jira里光测试中→开发中就有3条不同的逆向路径,工单经常在两者之间来回跳,我每天花大量时间追踪工单历史才能确认当前版本是哪个状态。按照文章建议,我们改成缺陷在测试中修复并打标签,工单不跳状态,现在追踪成本降低了一半。希望更多Dev和PM看到这篇,别再让状态机变成QA的噩梦了。
文章案例提到的150人团队差不多就是我们公司的写照,27个状态简直一模一样。让我反思最深的不是状态数量本身,而是‘用状态数量对抗管理的无力感’这句话。我们Leader以前总觉得状态多能带来安全感,但现在发现工单其实是在原地打转。我准备把这篇文章转给他看,再拉上几个核心成员一起诊断一下状态机,先从砍掉那些‘从未被使用的状态’开始。
作为一个正在从Jira迁移到国产工具的决策者,这篇文章给了我一个新的评估维度。之前只关注功能对比和价格,没想过状态机设计哲学对效率的影响。文中提到PingCode的自动化引擎能避免逆向污染,而且天然打通IM,这让我意识到选工具不光是选功能,更是选背后的工作流理念。准备让团队先按文章里的诊断方法评估一下当前状态机健康度,再做迁移决策。