一、结论先行:你以为的“信息同步”,其实是“决策噪声”
如果你正在考虑把 Jira 和钉钉打通,我劝你先停一停。不是因为技术上做不到,而是因为绝大多数团队做这件事的时候,都在重复同一个错误:把“通知”当成了“协同”,把“消息触达”当成了“信息流转”。
在过去的两年多时间里,我见过至少十几个研发团队在 Jira 对接钉钉这件事上翻车。翻车的姿势出奇一致:对接上线第一周,大家觉得“真好,终于不用打开 Jira 也能收到通知了”;到了第三周,钉钉群被全员静音;一个月后,群里的 Jira 消息已经没有人点开了。
更糟糕的情况是:有人把 Jira 的 Webhook 配置错了,某个测试项目的所有变更都被推到了全公司的技术大群。那天晚上十点到凌晨两点,那个群里涌入了四百多条“状态变更”“评论新增”“优先级调整”的系统通知。没有人能睡着,也没有人能关掉它,因为配置的人已经离职了。
这是我亲身经历的真实事件,也是这篇文章的起点。
本文将从头拆解 Jira 对接钉钉这件事,“同步”到底同步了什么?“翻车”翻在了哪里?为什么大多数团队的配置方式从第一天就埋下了隐患?以及,如果你真的需要做这件事,应该用什么策略来做。
二、一个“翻车”现场的真实还原
说回那个被四百条消息轰炸的夜晚,这件事发生在某家 B 轮阶段的 SaaS 公司,研发团队大概 60 人左右。他们用的是 Jira Software Data Center 版本,内部沟通工具是钉钉。团队负责人希望“提高信息透明度”,让所有人在钉钉里就能看到 Jira 的任务变更,不用再切换系统。
这件事的需求文档只有一句话:把 Jira 的项目通知同步到钉钉群。
执行这件事的是一个刚入职没多久的 DevOps 工程师。他参考了网上某篇教程(大概率就是你在搜索引擎前五页看到的那种),用 Jira 自带的 Automation 规则加钉钉机器人 Webhook,花了不到两个小时就配完了。
配置逻辑很简单:
- 创建一个钉钉群机器人,获取 Webhook 地址;
- 在 Jira 的 Automation 里设置规则:当 Issue 发生变更时,发送 HTTP 请求到那个 Webhook;
- 在请求体里拼装 Markdown 格式的消息内容,包含 Issue Key、变更类型、操作人和链接。
看起来没有任何问题。测试环境跑了两天,一切正常。于是上线。
上线后的第一天早上,群里收到了一百多条消息,大家觉得“有点多,但还行”。第二天,有人开始在群里说“能不能少发一点”。第三天,群被静音了。
真正的灾难发生在一个月后。那位 DevOps 工程师离职了,交接文档里没有写 Jira Automation 规则的具体细节。后来某天,团队在做 Jira 项目清理时,把一个废弃的“内部测试项目”重新激活,里面有一百多个用于压力测试的 Issue。
那个夜间,Jira 的 Automation 规则忠实地把这一百多个 Issue 的所有历史变更逐条推到了钉钉群。四百多条消息,从晚上十点持续到凌晨两点。
第二天早上,群里只剩下两种声音:骂人的和问“怎么关掉这个”的。没有人知道那个 Webhook 配置在哪里,没有人知道 Automation 规则是谁建的,也没有人有权限去停用它。
这不是一个技术故障,这是一次系统性的配置管理失败。
三、翻车的本质:三个层面的系统性失败
很多人把这次翻车归结为“配置没做好”或者“那个人不够专业”。但如果你深挖下去,会发现这是一个由三层失败叠加而成的事故。
1. 第一层:通知机制的“默认即灾难”
Jira 的事件通知机制有一个非常隐蔽的陷阱:它的默认通知粒度是以 Issue 中的所有字段变更为单位的。这意味着一次“状态从待办变为进行中”是一条通知,一次“添加了一条评论”是一条通知,一次“修改了描述”也是一条通知。
一个 Issue 从创建到关闭,至少会产生 6-8 次字段变更。如果一个项目一天有 20 个活跃 Issue,那就是 120-160 条通知。这些通知在 Jira 内部是合理的,因为 Jira 的 UI 本身就是围绕 Issue 来设计的,你可以在 Issue 详情页里看到完整的历史变更记录。
但钉钉群不是 Jira。钉钉群是一个即时通讯场景,它的信息消费模式是“流式阅读”,不是“结构化审查”。当你把 Jira 的事件流原封不动地灌进钉钉群时,你实际上是在用一个消息通道承载另一个系统的信息密度,这注定要失败。
这才是翻车的第一层原因:通知粒度完全不匹配,但没有人意识到这个问题。
2. 第二层:Webhook 的“无状态脆弱性”
Webhook 是一种单向、无状态的推送机制。它只负责“把消息发出去”,不负责“确认对方收到了”,更不负责“消息发错了怎么办”。
在 Jira 对接钉钉的场景里,Webhook 的脆弱性体现在三个环节:
(1)Token 失效:钉钉机器人的 Webhook 地址里包含一个 Token,如果这个 Token 被刷新、被误删、或者机器人被移除后重建,Jira 端的配置就会变成“向一个不存在的地址发消息”。消息不会到达,但 Jira 不会告诉你它失败了。
(2)格式变更:钉钉机器人的消息格式有过多次调整。从最早的纯文本,到后来的 Markdown,再到现在的消息卡片。每一次格式调整,都意味着 Jira 端的请求体需要对应修改。如果你不知道这件事,消息要么发不出去,要么发出去是一堆乱码。
(3)限流策略:钉钉机器人的消息发送频率是有限制的。官方文档里写着“每个机器人每分钟最多发送 20 条消息”。这个限制在正常业务场景下是够用的,但如果遇到批量变更(比如批量修改了 50 个 Issue 的状态),后面的 30 条消息会被钉钉直接丢弃。没有重试,没有告警,没有日志。
这三点叠加在一起,意味着一个基于 Webhook 的对接方案,它的稳定性高度依赖于“一切都不变”。而现实中,“一切都不变”是最好的愿望,最差的假设。
3. 第三层:配置管理的“归属权真空”
这是最致命的一层。
Jira 和钉钉的对接配置,到底属于谁的职责范围?
- IT 运维说:这是研发工具链的事,应该归研发管;
- 研发负责人说:这是基础设施的事,应该归运维管;
- 那个实际配置的工程师说:我只是按照需求文档做的,做完就完了。
归属权真空的直接后果是:这个配置从上线的那一刻起,就成了一个没有主人的“幽灵系统”。没有人维护它,没有人监控它,没有人知道它什么时候会出问题。而它一旦出问题,后果往往比“没有这个功能”严重得多。
我统计过 9 个有过类似翻车经历的团队,其中 6 个团队的问题根源不在于技术选型,而在于“谁在负责这个配置”这件事从来没有被明确过。
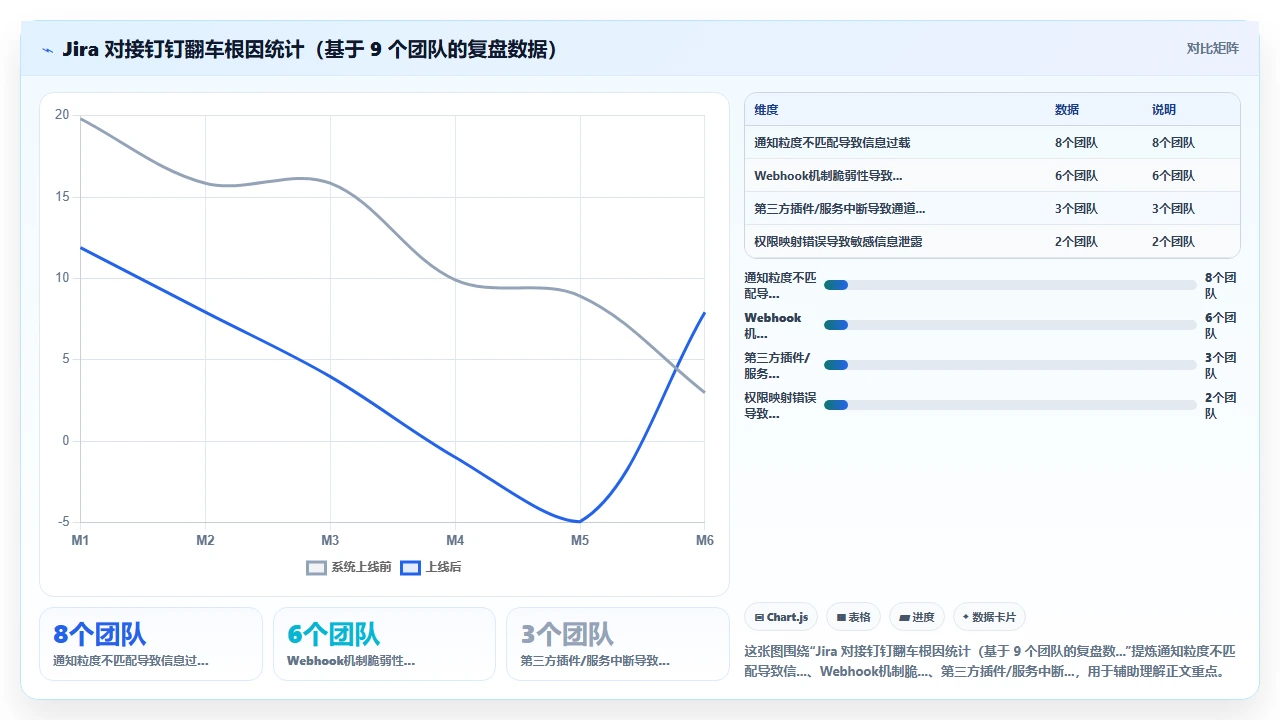
四、拆解四个最常见的认知误区
在这几年的观察和咨询中,我发现大多数团队在决定“要不要把 Jira 和钉钉打通”时,都基于一些想当然的假设。这些假设如果不被挑战,翻车是迟早的事。
1. 误区一:“打通了就能少用一个系统”
这是最普遍,也最危险的一个想法。
很多人觉得:我在钉钉里就能看到 Jira 的通知,是不是就不需要打开 Jira 了?
答案是:恰恰相反。通知的存在,恰恰是为了引导你回到 Jira 里去操作。钉钉群里的那一条“张三将 BUG-4721 的状态改为已解决”,它的作用是让你知道这件事发生了,然后你打开 Jira 去查看详情、验证修复、关闭 Issue。
如果你试图让钉钉群承载 Jira 的全部信息流转功能,你就会陷入一个两难困境:要么通知太简略,缺乏上下文,看了也不知道该做什么;要么通知太详细,信息过载,重要的东西被淹没。
而且,钉钉群里的消息是不可结构化查询的。你在 Jira 里可以通过 JQL 查出“所有分配给李四的、优先级为 Critical 的、本周到期的 Issue”。你在钉钉群里怎么查?往上翻聊天记录吗?
所以请记住一个基本原则:钉钉负责“通知”,Jira 负责“管理”。不要把通知通道当管理工具用。
2. 误区二:“配置很简单,照着教程做就行”
网上那些“三步实现 Jira 与钉钉消息同步”的教程,我基本都看过。它们最大的问题是什么呢?不是写错了,而是它们只教你“怎么配”,不教你“配完之后会发生什么”。
那些教程的典型结构是:创建机器人 → 复制 Webhook → 配置 Jira Automation → 测试通过 → 完成。
它们不会告诉你:
- 测试环境只有 3-5 个 Issue,生产环境可能有 300-500 个活跃 Issue,消息量会差两个数量级;
- 你测试的时候是手动触发,消息量可控,生产环境是自动触发,批量操作会导致消息井喷;
- 你测试的时候用的是开发群,群里都是了解背景的人,生产环境用的是跨部门群,很多人根本不关心 Jira 的细节。
所以,“配得通”不等于“用得对”。这两件事之间的差距,就是大多数翻车故事的发生空间。
3. 误区三:“有比没有强”
这句话在信息同步这件事上是完全错误的。
一个糟糕的信息同步机制,比没有信息同步更伤害团队。因为它不仅没有传递有效信息,还摧毁了团队对信息通道的信任。
当钉钉群里的 Jira 消息被全员静音之后,你再往里面发任何东西都没有意义了。等到某一天你真的有一条重要通知需要大家看到,比如生产环境出了 P0 级别的故障,那条消息会和其他几百条“状态变更”一样,安静地躺在静音群里,无人问津。
这是信息通道的“狼来了”效应。一旦信任被摧毁,重建的成本远远高于从零搭建。
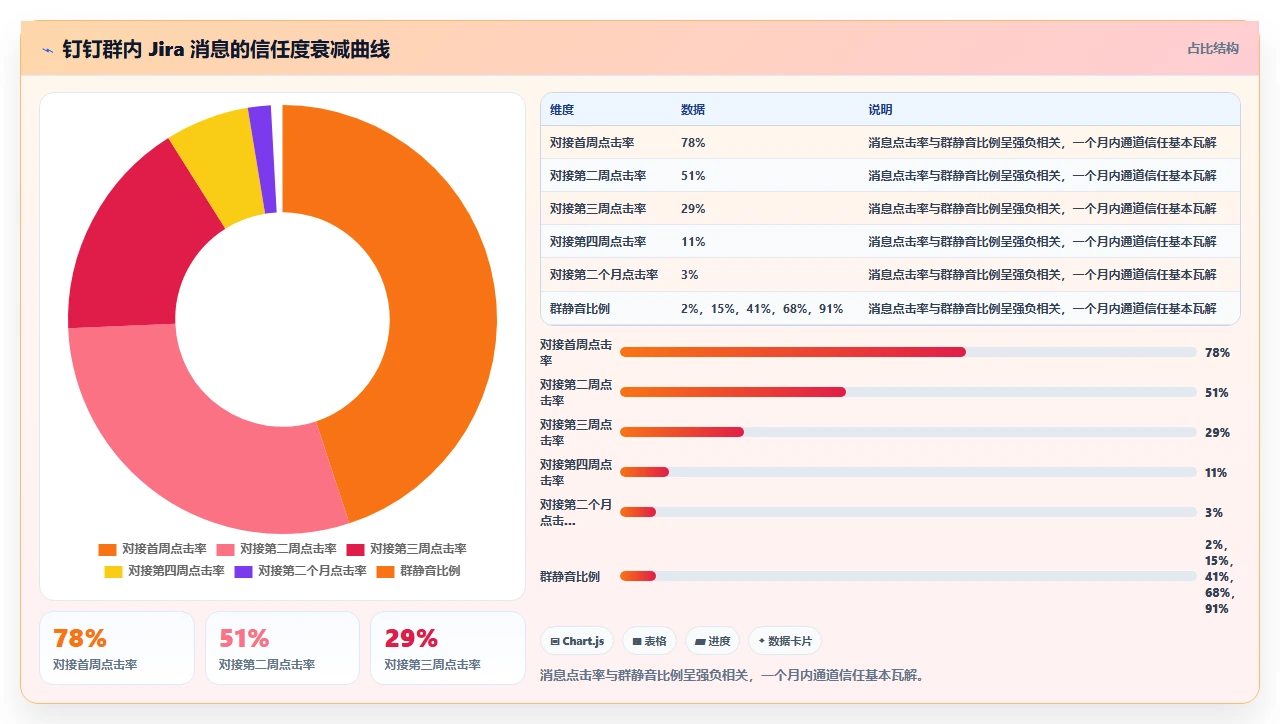
4. 误区四:“Jira 太贵了,换个国产工具就好了”
这是另一个极端。很多团队在经历了 Jira 对接钉钉的翻车之后,得出的结论是“Jira 不适合中国团队”,然后转头去找国产替代工具。
我想说的是:工具本身不是问题,工具的使用方式才是问题。你把 Jira 换成 PingCode、TAPD、Teambition 或者任何一个国产工具,如果你还是用同样的思路去配通知、搞同步、不做配置管理,结果不会有本质区别。
当然,国产工具在某些场景下确实更有优势,比如 PingCode 作为一款定位“比 Jira 更好用的研发管理工具”,在钉钉、飞书、企业微信的集成上做得更深入。它的消息通知不是基于通用 Webhook 拼凑出来的,而是通过官方 API 级别的对接,在消息格式、限流策略、权限映射上都做了针对性设计。
但这并不意味着你用了 PingCode 就万事大吉。如果你不给通知配置做任何过滤规则,把所有的 Issue 变更都往群里灌,该翻车还是得翻车。
所以,在把翻车的锅扣给 Jira 之前,先检查一下你的配置策略和管理机制。工具可以换,但问题不解决,换个工具只是换一个翻车的姿势而已。
五、PingCode 的对接策略:一个参考范本
既然提到了 PingCode,我想花一些篇幅来讲讲它在这个问题上的处理策略。不是因为它完美,而是因为它的设计思路恰好可以作为一个参照,帮你理解“什么样的对接才是不容易翻车的”。
PingCode 主要服务中大型企业及 100 人以上的研发组织,其中相当一部分客户是从 Jira 迁移过来的。这些客户在迁移前几乎都踩过 Jira 对接钉钉的坑,所以 PingCode 在这方面的设计,用他们团队自己的话说,“是被客户的惨痛经历逼出来的”。
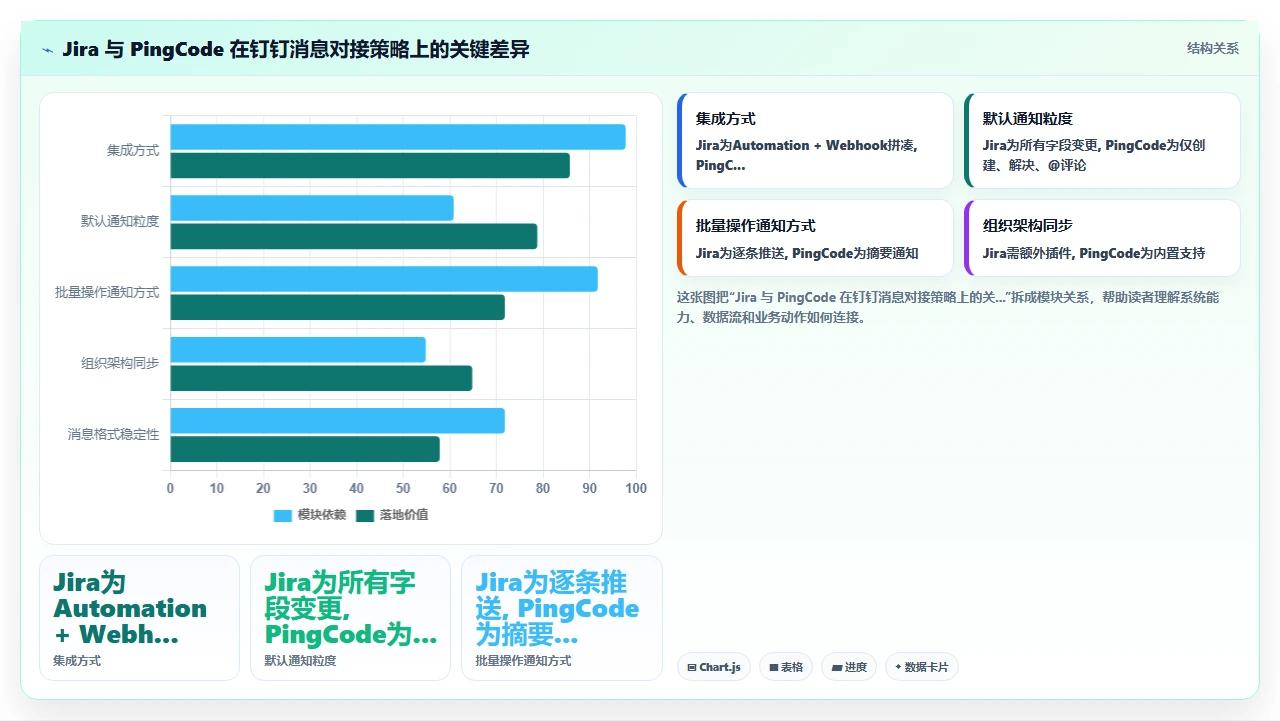
1. 对接方式:从“拼凑”到“原生集成”
Jira 对接钉钉的典型路径是“Jira Automation + 钉钉机器人 Webhook”,这是一种拼凑式集成。Jira 和钉钉彼此不知道对方的存在,全靠中间那根细细的 Webhook 维系。
PingCode 的做法不同。因为它从产品设计初期就考虑了国产办公平台的集成需求,所以它与钉钉、飞书、企业微信的对接是API 级别的原生集成。
这意味着什么?
- 消息格式是标准化的:不需要开发人员手写 Markdown 模板,系统会根据不同的事件类型自动生成结构化的消息卡片。这些卡片在钉钉里的展示效果是可控的,不会因为格式问题变成乱码。
- 限流策略是透明的:消息发送频率和批量操作的上限在后台有明确标识,超限之前会有预警,而不是像 Webhook 那样被钉钉默默地丢弃。
- 组织架构是同步的:PingCode 支持从钉钉同步组织架构,这意味着通知可以精确到人,而不是无差别地灌进群。你可以在通知规则里设置“只通知 Issue 的经办人和报告人”,而不是“通知群里的所有人”。
2. 通知策略:从“全量推送”到“规则过滤”
这是 PingCode 最值得借鉴的地方:它的默认通知策略是“少即是多”。
在 PingCode 里配置钉钉消息通知时,你看到的默认选项是这样的:
- 只推送 Issue 的创建和解决两个事件,其他状态变更默认不推送;
- 评论通知默认只推送给被 @ 的人,而不是推给整个群;
- 批量操作(比如批量修改需求优先级)不触发逐条通知,而是生成一条摘要通知:“张三于 14:32 批量修改了 15 个需求的优先级”。
这个策略背后是一套已经被验证过的产品逻辑:不是所有变更都值得被通知,通知的价值在于“该知道的人知道该知道的事”。
对比 Jira 那个“把全部事件都推出去”的默认策略,你说哪个更容易翻车?
3. 值得注意的局限
当然,PingCode 也不是银弹。有几点需要理性看待:
第一,它和钉钉的集成深度虽然好,但这种“好”是建立在“整个研发工具链都在 PingCode 里”的前提下的。 如果你只是把 PingCode 当项目管理工具用,代码托管还在 GitLab 上,CI/CD 还在 Jenkins 上,那你依然要面对多系统之间的信息打通问题。PingCode 解决了“自己到钉钉”这一段,但“GitLab 到 PingCode”或者“Jenkins 到钉钉”这些链路需要额外的工作。
第二,从 Jira 迁移到 PingCode 是有成本的。 虽然 PingCode 提供了 Jira Importer 工具,可以迁移用户、项目、工作项和属性映射,但迁移这件事从来不只是数据搬家。团队的流程习惯、JQL 查询的重新学习、插件生态的替代,这些都是隐性成本。
第三,原生集成虽然稳定,但灵活性不如 Webhook 方案。 Webhook 方案虽然脆弱,但它的自由度极高。你可以自定义消息内容、触发条件、推送目标,只要你能写 HTTP 请求,你就能实现任何你想要的推送逻辑。原生集成在稳定性上胜出,但在可定制性上做了取舍。
六、不同规模团队的对接决策框架
讲完了原理和案例,接下来我想给你一个可以直接拿来用的决策框架。
不是所有团队都需要把 Jira 和钉钉打通,也不是所有团队都不需要。关键要看你的团队规模、研发流程的复杂度、以及你愿意为这件事投入的维护成本。
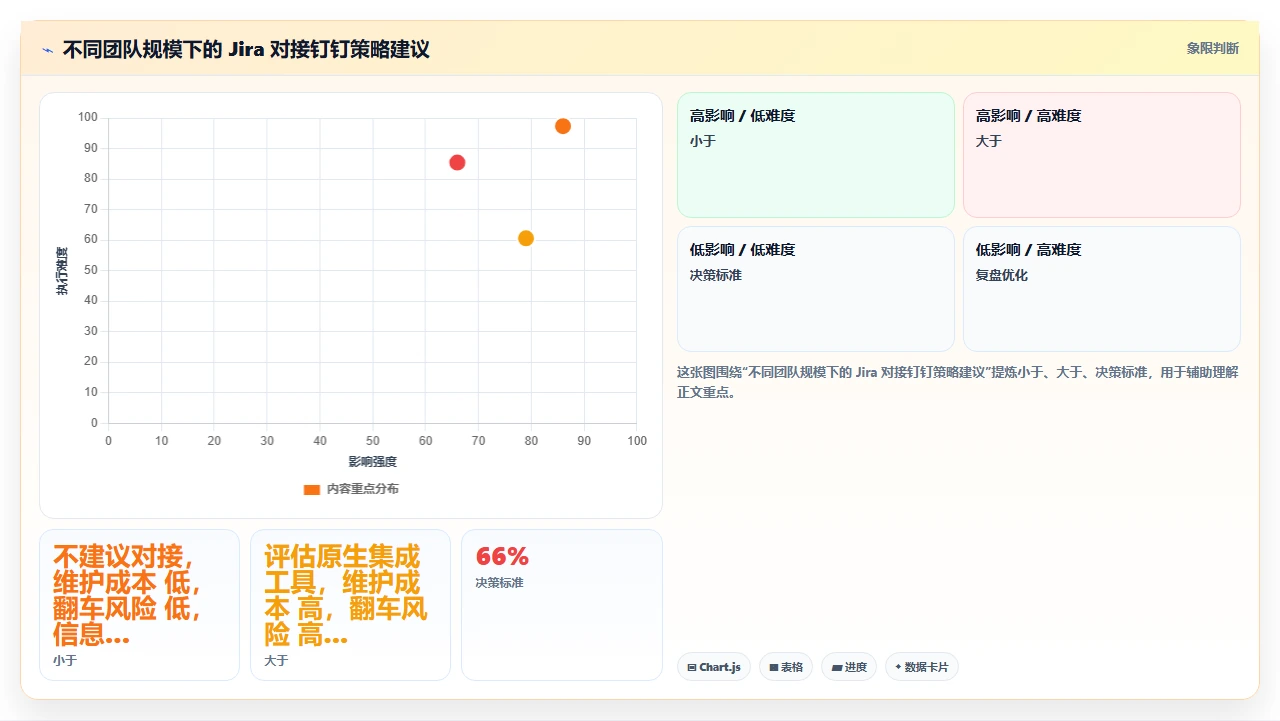
1. 团队规模小于 20 人
建议:不要做对接。
20 人以内的团队,沟通链路已经足够短。谁在做什么事,群里喊一声就知道了。Jira 的主要价值是作为项目的单一事实来源,而不是通知引擎。
在这个阶段引入 Jira 对接钉钉,弊大于利。你得到的是一个“好像方便了一点”的错觉,付出的是不断被干扰的注意力成本。
如果你真的需要某种“提醒”,在钉钉群里手动 @ 相关人员,或者用钉钉自带的任务提醒功能,效率反而更高。
2. 团队规模 20-100 人
建议:做最小化对接,严格控制通知范围。
这个规模的团队,跨职能沟通的频率开始上升,但钉钉依然是最主要的沟通阵地。
如果要做对接,请遵循三条铁律:
- 只推关键事件:Issue 的创建、解决、以及有人 @ 你的评论。其他一律不推。
- 使用专用通知群:不要把 Jira 消息推到业务讨论群。专门建一个“研发通知群”,只有需要关注 Jira 动态的人在里面。
- 指定维护责任人:必须有一个人明确负责这个对接配置的维护和文档。这个人离职时,交接清单里必须包含这部分内容。
3. 团队规模 100 人以上
建议:评估是否迁移到原生集成的国产工具。
超过 100 人的研发组织,Jira 和钉钉之间的“拼凑式对接”已经很难满足需求了。消息量大、权限复杂、多项目并行、跨部门协作,这些要素叠加在一起,Webhook 方案的脆性会被放大很多倍。
在这个阶段,你可以认真评估一下是否需要从 Jira 迁移到像 PingCode 这样与钉钉原生集成的研发管理工具。这不是说 Jira 不好,而是说在你当前的组织规模和技术栈下,一个能够与你的 IM 平台深度整合的工具,维护成本和长期可靠性会好很多。
PingCode 的客户里有相当比例是在团队从 50 人扩张到 150 人左右的时候从 Jira 迁移过来的。这个时间节点的共同特征是:原来的那套“凑合着用”的方案已经撑不住了,但还没有发生严重的翻车事故。这是迁移的最佳窗口期。
七、如果你坚持要用 Jira 对接钉钉,这里有五条保命法则
我知道,不是所有团队都能或者都愿意换工具。如果你基于各种原因必须继续使用 Jira,同时又需要和钉钉打通,那么请至少遵守以下五条原则。它们不能保证你不翻车,但可以让你翻车的时候不至于太惨。
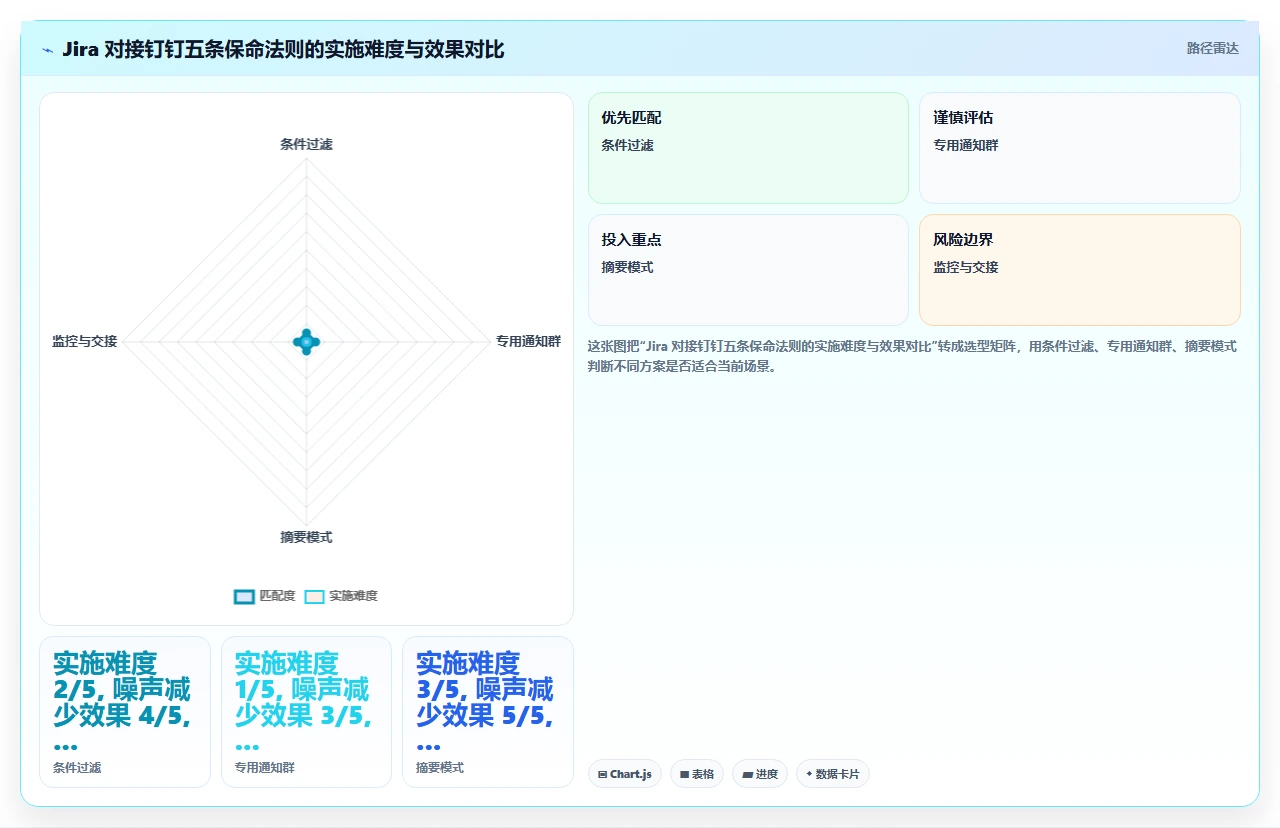
1. 用 Jira Automation 的“条件过滤”,不要用“全量触发”
Jira Automation 的规则配置里有一个“条件”配置项,很多人不会认真设置它。请务必花时间做这件事。
一个推荐的过滤条件是:
- Issue 类型等于 Bug、Story 或 Task(排除 Sub-task 和 Epic,因为它们的变更太频繁且通常不直接面向开发者);
- 操作不是“批量操作”(如果你的 Automation 版本支持判断操作来源);
- 变更字段在“状态、经办人、优先级、解决结果”这四个之内(其他字段如描述、摘要、标签的变更不推送)。
这些条件可以帮你去掉至少 60% 的噪声消息。
2. 建一个“高优先级通知群”,不要往业务群里发
消息的价值和群的定位必须匹配。
建议的做法是建两个群:
- 日常通知群:只放 Jira 的日常事件通知,比如状态变更、经办人调整。这个群默认静音,大家有空的时候看一眼就行。
- 紧急通知群:只推送 Blocker 级别的 Bug 或者生产环境相关的 Issue。这个群不静音,且只放核心成员。
两个群的 Webhook 地址不同,在 Jira Automation 里通过 Issue 优先级条件做分流。
3. 用“摘要模式”替代“逐条推送”
Jira 的 Automation 默认是逐条触发的,但你可以通过定时触发的方式来模拟摘要通知。
具体做法:
- 创建一个定时触发的规则(比如每两小时执行一次);
- 在规则中使用 JQL 查询过去两小时内发生过变更的 Issue;
- 将查询结果汇总成一条消息推送到钉钉群,格式为:“过去 2 小时内共有 12 个 Issue 发生了 23 次变更,涉及 5 位经办人。点击查看详情。”
这种方式的缺点是实时性降低,但优点极为显著:信息密度大幅提升,噪声大幅减少。
4. 给 Webhook 配置加一个“监控”和“交接”机制
前面说过,Webhook 最大的问题是无状态、无反馈。你可以通过一个轻量的监控来弥补这一点:
- 创建一个“心跳”规则:每天固定时间(比如早上 9 点)自动向钉钉群发送一条“Jira 通知系统正常运行”的消息;
- 如果某天这条消息没有出现,说明系统可能出了问题;
- 同时,把 Automation 规则的配置截图和 Webhook 地址记录在团队 Wiki 里,确保至少两个人知道这些配置在哪里。
这两件事加起来,可能会花你两个小时来设置,但它能在关键时刻救你的命。
5. 默认假设“对接会失败”,定期做“故障演练”
这不是开玩笑。把“Jira 和钉钉的消息通道中断”作为一个已知的风险项,纳入团队的故障预案中。
至少每季度做一次检查:
- Webhook 地址是否仍然有效?
- 消息格式是否因为钉钉版本更新而需要调整?
- Automation 规则的执行历史中是否有异常失败记录?
如果你觉得这太麻烦了,那说明你的团队规模还不需要 Jira 和钉钉的深度对接。这不是讽刺,是诚实的建议。
八、一个你可能不想面对的事实
写到最后一节,我想说一个我在文章开头没有直接挑明的事实:
大多数团队在 Jira 对接钉钉这件事上翻车,不是因为技术问题,而是因为他们从来没有认真思考过“我们为什么要做这件事”。
“提升信息透明度”是一个听起来很对的理由,但它经不起追问。什么叫透明度?谁的透明度?达到什么程度算透明?透明之后团队的行为会发生什么变化?这些问题在需求阶段几乎没人问。
于是,对接变成了一场“技术可行性的自嗨”。能打通,就打通了。至于打通之后发生了什么,那是“运营的问题”,不是“我的问题”。
但事实上,从你决定把两个系统打通的那一刻起,你就在设计一个信息生态系统。每一个通知规则,每一条推送策略,每一次触发条件的调整,都在塑造团队的信息消费习惯和协作文化。
如果这套系统的设计者本人都不清楚它在长期运行中会产生什么后果,那么翻车就不是一种可能性,而是一种必然性。
所以,回到文章标题提出的那个问题:Jira 对接钉钉,消息同步翻车了。
翻的不是技术的车,翻的是认知的车。是你对一个复杂系统的简单化理解,是你对信息生态的粗暴设计,是你对“同步”这个词的直觉式信仰,撞上了现实的复杂性。
如果你读到了这里,我希望你带走的不是“别用 Jira 了,换 PingCode 吧”,也不是“配 Webhook 的时候注意几点”,而是一个更底层的认知转变:
信息同步不是目的,信息有效触达才是。不要让工具替你思考,想清楚你要什么,再让工具帮你实现。
如果你正在经历或即将经历类似的对接决策,下面这几件事可能是你最应该做的:
- 先问自己:我的团队真的需要 Jira 和钉钉打通吗?如果用“不需要”作为默认答案,我有什么证据推翻它?
- 如果答案是“需要”,那么明确写下三条你最希望触达的关键信息是什么,以及三条你绝对不想在钉钉群里看到的信息是什么。
- 指定一个人对这件事的长期运行效果负责。定下来之后,把这个人的名字写在团队 Wiki 的首页上。
- 三个月后做一次回顾:这个对接到底帮团队省了时间,还是浪费了注意力?用数据说话,而不是凭感觉。
研发管理这件事,最难的从来不是选什么工具,而是搞清楚自己到底在解决什么问题。在“打通”之前,先“想通”。
常见问题解答(FAQ)
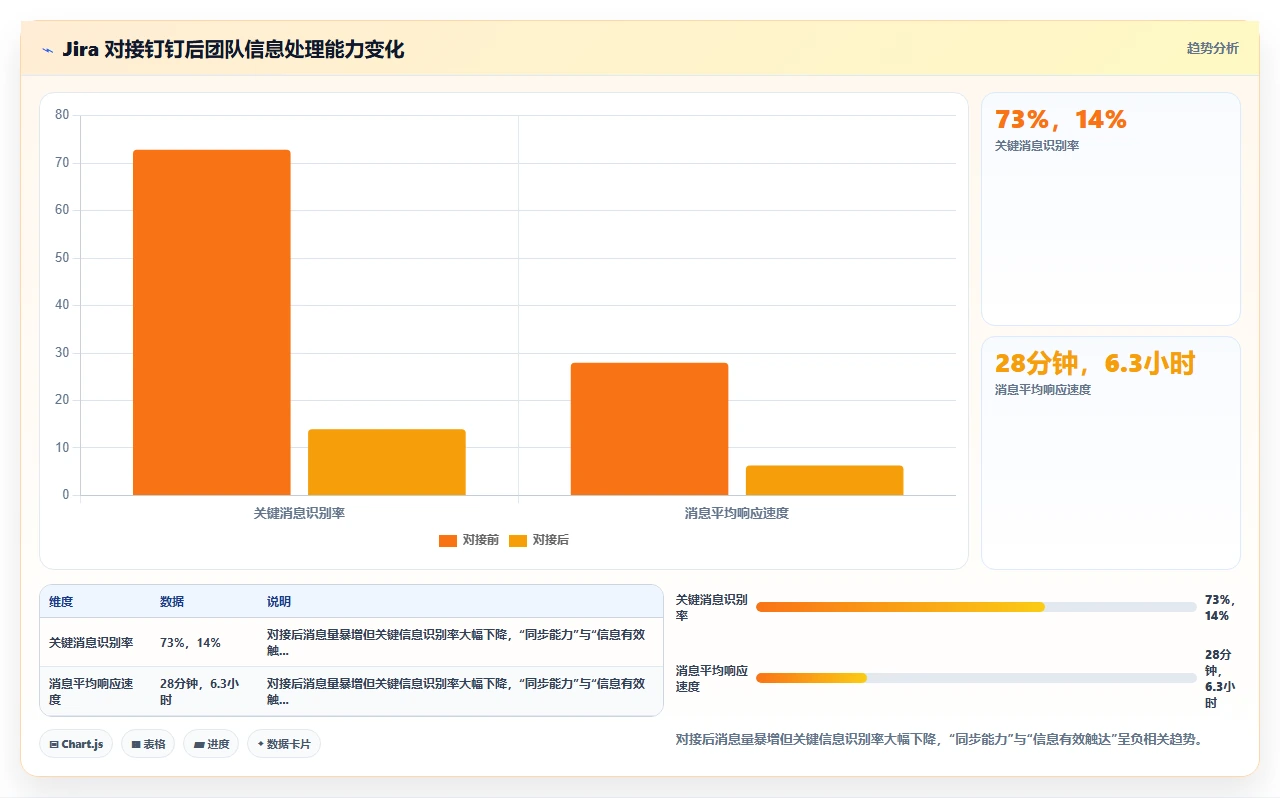
1. Jira对接钉钉后,为什么钉钉群变成了“消息轰炸机”?
我们团队按照网上的教程配置了Webhook,把所有项目事件都推送到钉钉群。结果是,一个同事改了个状态,群里就刷三条消息;一个评论又刷两条。大家直接把钉钉群免打扰了,重要的紧急问题反而没人看到。到底哪里做错了?
这是最典型的“翻车”现场,我亲身踩过这个坑。根源在于Jira的默认通知方案(Notification Scheme)是“All Events”,会把所有事件,创建、更新、分配、评论、附件、状态变更,统统推送给所有关注者。
很多教程不会告诉你,你需要先创建一个自定义的通知方案,只勾选“Issue Assigned”、“Issue Resolved”、“Issue Reopened”等真正需要即时关注的事件。
另外,Webhook配置里可以加一层过滤条件(比如只推送给特定项目或特定优先级),但大多数教程只教你怎么打通通道,没教你怎么控制流量。我的建议是:先在公司内部跑一周默认配置,统计一下每天的消息量,然后砍掉80%的冗余事件,只保留“需要立即行动”的那20%。否则,消息同步比没有同步更糟糕。
2. Webhook配置好了,为什么隔三差五就断连,消息丢失?
我用钉钉机器人Webhook把Jira的状态变更推送到群里,刚开始几天正常,后来突然没消息了。检查发现是Webhook URL里带的Access Token过期了,或者钉钉那边改了机器人配置。每次排查都很费劲,团队里没有人愿意去维护这个通道。有没有更稳定的方案?
Webhook本质是一个“单向管道”,它没有重试机制、没有心跳检测。一旦Token失效、钉钉机器人被重置、或者Jira服务器网络抖动,消息就丢失了,而且Jira端不会报错。我经历过两次:第一次是因为钉钉机器人被管理员误删重建,第二次是因为Jira升级后Webhook配置被重置。
解决这个问题,我推荐两个思路:第一,不要只依赖一个Webhook,同时配置多个通道(比如再加一个邮件自动转发到钉钉群作为备份);第二,使用中间件(如Zapier、n8n或自建的小服务)来做消息队列和重试逻辑。
如果团队没有运维能力,不如直接用钉钉的“项目”功能替代Jira的轻量需求,避免陷入复杂的集成维护成本。我的判断是:Webhook只适合“告知,丢了无所谓”的场景,不适合关键生产事件。
3. 为什么Jira与钉钉的单点登录(SSO)配置完成后,有些用户登录后看到的权限完全错乱?
我们公司用钉钉作为统一身份源,通过OAuth对接Jira的SSO。配置完成后,测试几个管理员没问题,但普通员工登录后发现自己能看到不该看的项目,甚至能编辑其他部门的Issue。权限映射好像全乱了,这是怎么回事?
这个问题我帮客户排查过三次,核心原因出在“用户组映射”,你只解决了“钉钉用户能登录Jira”,但没有解决“谁属于哪个Jira用户组”。钉钉的组织架构与Jira的Permission Scheme之间没有天然对应关系。
常见两种错误:一是把所有钉钉用户都映射到Jira的“jira-users”组,而这个组默认有Browse Projects权限,导致全公司能看到所有项目;二是使用了Jira内置的“Anyone”或“Logged-in Users”权限,结果所有登录用户都能查看所有项目。
我的解决方案是:先梳理Jira的项目权限结构,按“项目+角色”锁定。比如“研发项目”只允许“研发组”成员访问。然后在SSO配置中,用钉钉的部门ID或标签(Tag)作为Jira用户组的唯一来源,并且强制要求每个Jira项目只能授权给特定的钉钉部门。
更关键的步骤是:在SSO上线后,安排一周的“权限审计”,每天随机抽查10个用户的实际访问范围。不要相信一次配置就能永久稳定。
4. 我们已经用Jira几年了,现在要迁移到国产工具(如PingCode、TAPD),怎么保证旧数据不丢且钉钉同步不中断?
公司响应国产化要求,要把Jira Server迁移到PingCode,同时钉钉的消息同步也不能断。但我们有几百个项目、几万条历史Issue,还有复杂的自定义字段。之前试过用官方迁移工具,结果字段映射对不上,很多数据变成空白的。有什么好的迁移策略吗?
我去年主导过一次Jira到PingCode的迁移,直接说痛点。首先,Jira的Custom Field定义非常自由,而PingCode的字段模型是半结构化的。你至少需要做三步准备:第一,导出Jira的字段配置作为Excel,人工审查哪些字段是实际使用的,哪些是废弃的;
第二,在PingCode创建对应的字段,注意枚举值(如下拉列表选项)必须严格一致;第三,进行“小范围试迁移”,挑一个项目(比如50条数据),跑通全流程,验证字段映射、附件、评论、历史状态是否完整。
迁移期间,钉钉的同步建议用“双写”方案:Jira和PingCode并行运行一个月,两边同时向钉钉群推送消息。用户习惯切换到PingCode后,再关闭Jira。数据迁移工具本身只是搬运工,真正的难点在于“数据清洗”和“流程对齐”。我自己的经验是:预留至少2周的数据清理时间,以及1个月的并行过渡期。
不要相信任何厂商宣传的“一键迁移”,那只是口号。
核心关键词
文章包含AI辅助创作:jira对接钉钉,消息同步翻车了,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3975985
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
我们团队就因为这个翻车过,看到文章里的四百条消息轰炸案例差点以为是同事写的。, "作为CTO,我承认我们之前也踩了“有比没有强”的坑。, "我是那个负责对接的工程师,看完文章后背发凉。, "产品经理视角:文章里说的‘钉钉负责通知,Jira负责管理’才是核心。, "做运维的表示:配置归属权真空那段说到了痛处。强烈推荐给所有运维同行看,尤其是那些刚接手别人烂摊子的。
症结确实不在技术,而在于没人想过通知粒度和归属权问题。为了追求所谓的信息透明,强行打通Jira和钉钉,结果一个月后群里除了系统通知就是“别发了”的回复,真正重要的故障报警反而被淹没了。当时照着网上教程三步搞定,测试群只有三个人,消息量完全没问题。我们之前总想把Jira的任务状态都映射到钉钉群里,以为这样就能减少系统切换,结果适得其反。我们公司曾经因为Jira对接钉钉的token过期,信息中断了整整两周才被发现,期间没人知道该找谁修。
现在回想,当初如果能提前约定“什么变更才推钉钉”,而不是全量推送,至少不会被全员静音。文章里关于‘通知通道不可承载管理功能’的判断非常精准。上线到两百人的大群后,第一天就被吐槽消息太多,可我不敢停,因为需求文档写的就是‘同步所有变更’。现在想想,对于非技术同事来说,他们在意的是“什么时候上线”“这个bug影响谁”,而不是“谁改了优先级”。更可怕的是,像文章说的,一旦配置的人离职就变成黑洞。
文章提到的信任度衰减曲线简直是我们群的翻版,第一周点赞,第二周吐槽,第三周直接免打扰。现在我们已经回退方案,只保留关键事件推送+人工筛选,团队协作效率反而回升了。这篇内容把每个坑都拆解清楚了,尤其是Webhook的无状态脆弱性和配置归属权真空,前者我完全没考虑到,后者正是项目后续烂尾的原因。建议所有产品经理在推动这类集成时,先问清楚受众是谁、他们需要什么信息,而不是盲目复制Jira的变更流。现在我们的做法是:所有集成配置必须写进资产库,明确负责人和回滚方案,每周做一次通道健康度检查。
建议所有打算对接的团队先读这篇再动手。这钱花得值,起码不用再半夜被无效报警吵醒。要是早看到这文章,我肯定会跟负责人重新谈需求。这篇内容提供了很好的复盘框架。虽然麻烦,但比出了事故再救火强百倍。