一、核心结论:为什么“一键修复脚本”是最大的谎言
去年十一月,我接手过一个Jira Data Center迁移项目。源环境是Server 8.20,目标环境DC 9.12,中间隔着两个大版本。迁移方案用的是Atlassian官方推荐的XML备份恢复路径,理论上不该有问题。但恢复完成后,我们发现了一组诡异的现象:
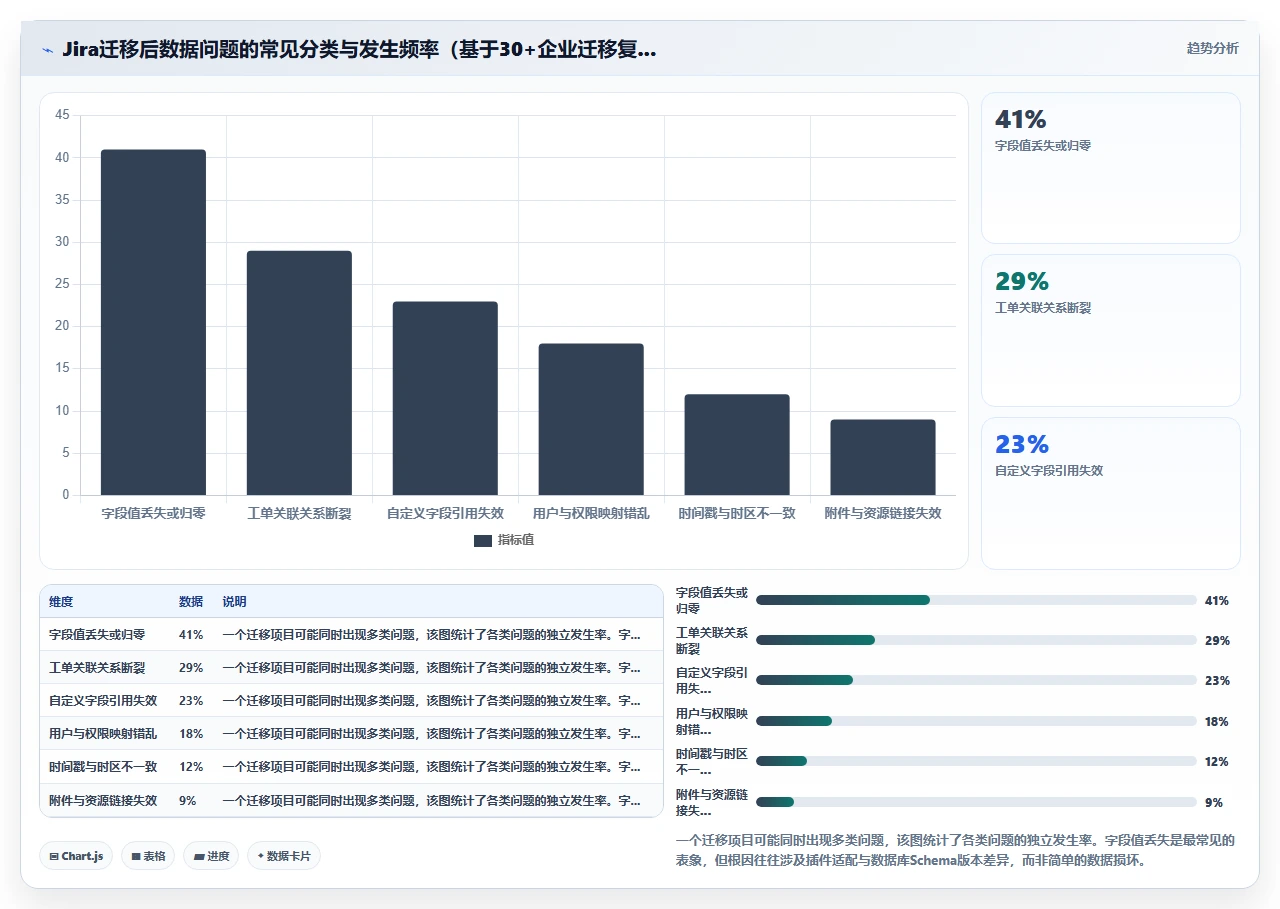
- 所有Epic下的Story Point字段数值归零,但字段本身存在。
- 大约12%的工单中,Fix Version/s字段变成了不可识别的字符串引用。
- 两个自定义脚本字段(ScriptRunner维护的)在工单视图里消失了,但后台数据库表里数据还在。
面对这种局面,很多人的第一反应是在搜索引擎里输入“Jira迁移数据修复脚本”,指望找到一个现成的Python文件下载下来跑一遍就搞定。我可以明确地讲:这种行为极其危险,而且大概率会把你推进更深的坑里。
原因很简单:Jira的数据模型不是一张表、两层关联那么简单。一个DC实例的后台可能有超过1500张数据库表,其中AO_开头的插件表占据了大半。不同版本的Jira对这些表的Schema定义、约束条件、字段类型都有差异。更麻烦的是,插件版本与Jira版本的适配关系是动态变化的,比如ScriptRunner在6.47版本里有一个用于存储自定义脚本字段值的AO表,到了6.56版本拆成了两张表,字段映射逻辑完全不同。你在网上找到的一个2022年的修复脚本读的是旧表,但在你的环境里数据已经在新表了,跑完就是空操作,甚至可能因为错误更新的触发器把好的数据写坏。
所以这篇文章要讲的核心结论就一句话:没有万能脚本,但有通用的诊断框架和安全的脚本编写原则。如果你正在面临Jira迁移后的数据问题,读完这篇文章,你应该能自己写出适合自己环境的修复脚本,而不是盲目复制别人的代码。
下面我从自己实际经历过的三次Jira迁移说起,把踩过的坑和验证过的方案逐一展开。

二、背景与真实场景:三次迁移,三次不同的“灾难”
我不打算用“假设某公司”那种编的案例来凑数,这里说的三件事我全都参与过,有些是主力执行,有些是半路接手救火。
1. Server 8.20 到 DC 9.12:版本跳跃引发的字段断裂
这就是开头提到的那次迁移。客户是一家150人规模的软件公司,用了七年Jira Server,积累了超过8万条工单。迁移的直接动机是Atlassian宣布停止销售Server版许可,必须往Data Center或Cloud方向走。
迁移过程本身没报错,XML备份文件大小约18GB,恢复时长4小时,日志里没有ERROR级别记录。问题是在用户开始日常使用后才暴露的:
- 项目经理在做Sprint回顾时发现燃尽图Flat,因为Story Point全是0。
- QA在筛选“本次Release修复的Bug”时,发现Fix Version筛选条件返回的结果为零。
- 某些自动化规则失效,因为规则引用的自定义脚本字段成了空白。
当时团队里有人提出来找Atlassian官方支持开Ticket。但这家客户在迁移前已经和原Atlassian代理商解约了,没有维护服务合同。官方社区帖子的回复平均周期是3到5个工作日,但Sprint不等人。
所以我们必须自己动手修。用脚本修。
2. 从Jira Cloud迁移回私有部署:云端数据和本地Schema的错位
第二个案例更棘手。某金融科技公司之前把研发管理搬上了Jira Cloud,用了将近两年。后来因为合规要求,数据必须落在境内自有机房,决定迁回私有部署的Data Center。
Atlassian官方提供了Cloud-to-Server/DC的迁移助手,但这个工具在数据导出时强依赖Cloud端的API做字段序列化。到了DC端恢复时,有四个自定义字段因为Cloud端插件版本高于DC端的同名插件,数据结构里多了两个属性,导致DC端直接拒绝解析这些字段。表现就是工单详情页里那四个字段的位置是空白,编辑模式下也无法选择。
这一次我们没有XML备份文件可以直接编辑(Cloud端的备份是Atlassian托管的黑盒),我们唯一的输入是迁移助手导出的CSV文件和附件包。这就意味着:你得从一份可能不完整的CSV里把丢失的字段数据拼回去。
3. Jira Server升级失败后的人工迁移:同环境内的数据校正
第三个案例听起来没那么复杂,但实际修起来最磨人。一家制造业企业的IT部门尝试把Jira Server从8.5升级到8.20,用的是标准安装包升级路径,但过程中因为磁盘空间不足导致升级脚本执行到一半中断。虽然后来补上了空间并完成了升级,但数据库中产生了一批“半成品”数据:有些工单的修改历史记录不完整,明明状态变了,但history表里少了一行。
这种问题的隐蔽性很高。表面上工单正常流转,但在做审计或生成合规报告时,会发现某些工单的时间线链条断裂,比如从“开发中”直接跳到“已关闭”,中间缺少至少一个“测试通过”的状态记录。
三、拆解常见误区:你以为的“好办法”可能让事情更糟
在做数据修复的过程中,我发现有很多看起来很“合理”的做法,实际上非常危险。这里逐一拆解。
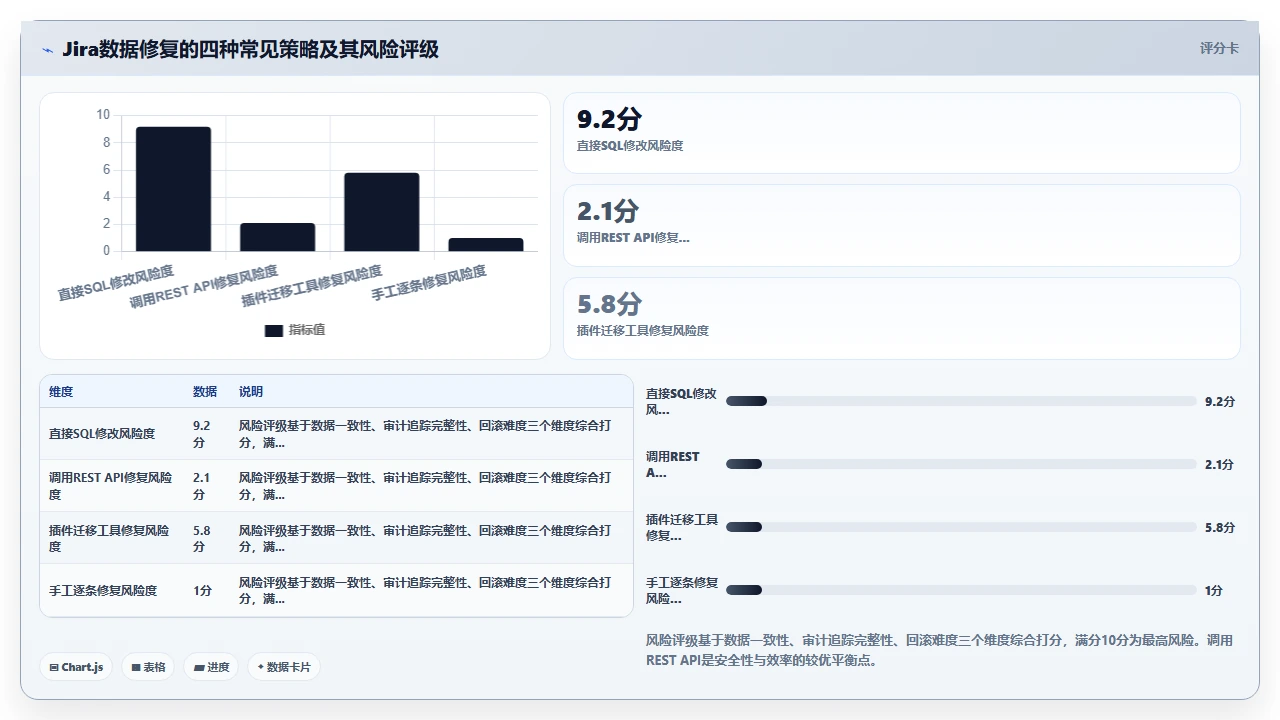
1. 误区一:直接跑SQL UPDATE修复字段值
这是我见过最多的情况。运维人员查到Jira数据库里的jiraissue表,发现某个字段对应的是customfieldvalue表里的某一行,于是写了条SQL直接UPDATE。当时看是对的,工单页面也正常显示了。
但Jira不是只有一个数据库层。它上面还有两层:Entity Engine(实体引擎)缓存和Lucene索引。你通过SQL修改的数据,不会自动刷新应用层的缓存,也不会重建Lucene索引。结果就是:
- 用户在页面上修改了工单,Jira会根据缓存里的旧值覆盖掉你SQL修改的新值。
- 全局搜索和JQL筛选依然返回修改前的结果,因为索引没变。
- 更严重的是,如果触发了一个和该字段相关的自动化规则(Automation for Jira),规则引擎读到的也可能是缓存中的旧数据,产生不可预期的操作。
正确的做法是通过Jira REST API来更新数据,让API帮你走完缓存刷新和索引更新的完整链路。即使你不得不操作数据库,也必须随后执行reindex操作并清理应用缓存,而且需要先停掉Jira服务或在维护窗口中进行。
2. 误区二:依赖于插件自带的“迁移工具”
很多Jira插件(特别是BigPicture、Tempo、Structure这类深度嵌入的插件)宣传自己有“数据迁移向导”。但根据我的实际体验,这些向导的处理逻辑通常是“导出插件自己的AO表数据 → 在目标环境导入”。问题在于,它们不处理Jira原生数据结构和插件数据的关联映射。
举个例子:BigPicture的Program数据会关联到Jira原生的Project、Version、Issue。如果你在迁移Jira时,这些原生实体的数据库ID发生了变化(这几乎是必然的),BigPicture迁移向导导入的数据仍然指向旧的ID,视觉上看程序恢复了,但点击进去全是“Object not found”。
结论:插件的迁移工具只能作为辅助手段,不能替代你对数据关联逻辑的理解和校验。
3. 误区三:从别人那里复制一个“验证过的脚本”直接跑
我理解这种行为的心理驱动:省时间。而且看起来好像风险不大,脚本又不会删数据,最多就是执行失败。
但你可能低估了一个问题:脚本里硬编码的环境参数。比如一段修复Story Point的Python脚本可能会这样写:
# 别人的脚本里可能有这样一行
customfield_id = "customfield_10100"
但你环境里的Story Point字段ID可能是customfield_10045
你跑完脚本,故事点数值更新到了一个完全无关的字段上
这种错误在测试环境可能不会立即暴露,你看到某个字段有值了,以为修好了,但其实修错了字段。等到真用的时候才发现问题,已经过去了几天,备份窗口早已关闭。
我用过的安全做法是:任何数据修改脚本,在执行UPDATE或POST之前,先做一次只读查询,把将要修改的数据打印输出到日志文件,人工抽查确认无误后,再打开写操作开关。
4. 误区四:忽略时区带来的时间数据偏差
我遇到过一个典型场景:迁移后,所有工单的创建时间和更新时间都偏移了8小时。原因很简单:源环境JVM时区设置为UTC,目标环境设置成了Asia/Shanghai。数据库里存的时间戳是绝对毫秒值没错,但Jira在显示时用当前JVM时区做了转换,导致前端展示偏移。
有人写了脚本批量修改时间字段。但问题在于,如果你真的改了数据库里的时间戳,相当于改变了事实,原本在美国东部时间下午4点创建的工单,被硬生生改成了另一个时刻。合规审计时,这种修改可能构成数据篡改。
正确的做法是修正JVM时区配置,不改时间数据本身。脚本要改的应该是系统配置,而不是业务数据。
四、专业判断逻辑:从“发现问题”到“定位根因”的完整链路
我自己的经验是:数据修复的成败,60%取决于诊断阶段你是否真的找到了根因。剩下30%是脚本编写质量,10%是验证和执行策略。
下面是我沉淀下来的一套诊断流程。
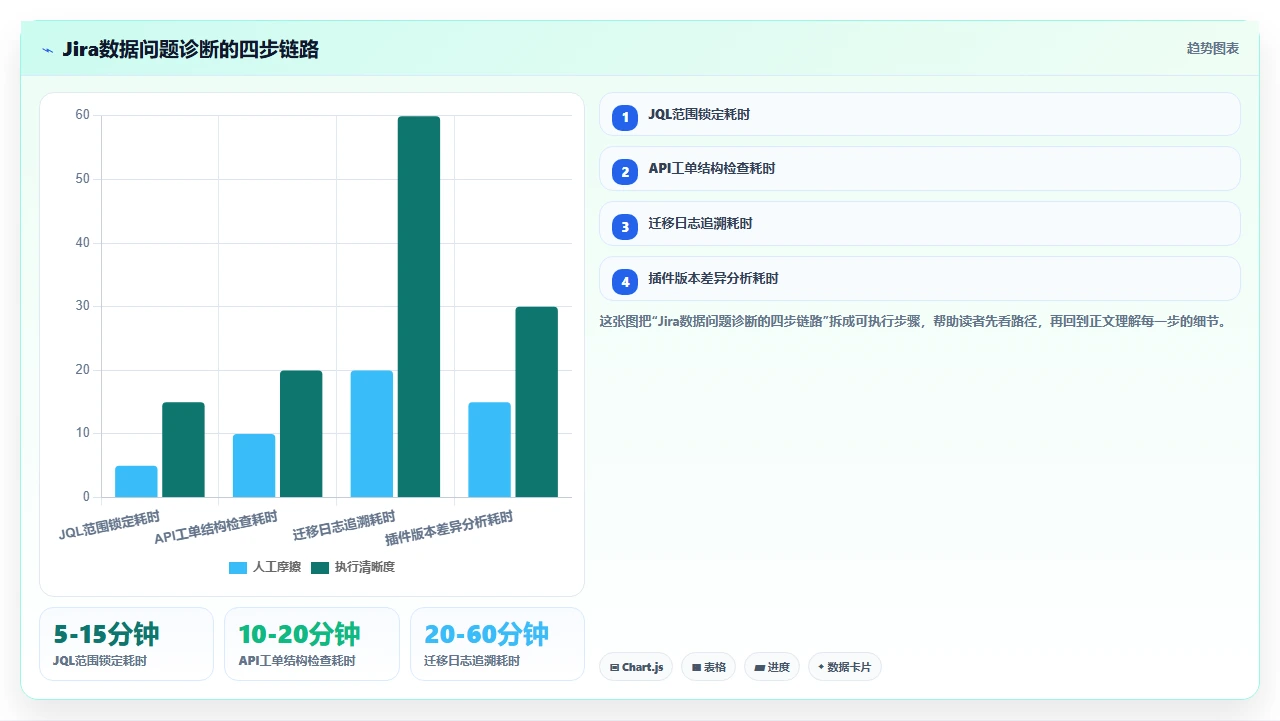
1. 先用JQL锁定问题范围
很多人一上来就查数据库,这其实绕了弯路。Jira自带的JQL(Jira查询语言)已经能帮你定位大部分数据异常。
以Story Point归零为例,你可以这样查:
project = "YOUR_PROJECT" AND type = Story AND "Story Points" = 0
如果这个查询返回了大量结果,而且你确认这些Story在迁移前肯定有点数,那问题范围就确认了。
对于Fix Version字段异常,可以用:
project = "YOUR_PROJECT" AND fixVersion is not EMPTY AND fixVersion not in (SELECT versions FROM project WHERE project = "YOUR_PROJECT")
这条语句会查出那些fixVersion字段有值,但这个值并不在你项目的版本列表里的工单。这通常意味着引用断裂,工单指向了一个已经在迁移过程中丢失的版本ID。
2. 用REST API读取单条工单的完整JSON结构
JQL确认范围后,选一条典型工单,用浏览器或curl调用REST API:
curl -u username:password -X GET "https://your-jira-instance/rest/api/2/issue/ISSUE-KEY?expand=renderedFields,names,schema" | jq .
用jq格式化输出,你就能看到这条工单的完整数据画像:每个字段的ID、类型、当前值、渲染值。把这个JSON和你在Jira UI上看到的对比,如果JSON里有数据但UI上不显示,说明是前端渲染或插件拦截问题。如果JSON里数据就是空的,那就是数据层的问题。
3. 追溯迁移日志,定位数据丢失的精确环节
Jira迁移产生的日志文件通常很大,动辄几百MB。很多人不愿意看,或者用grep乱搜。我习惯用一个更高效的方法:
先在恢复日志中找到问题工单最早出现的那条INSERT或UPDATE记录,记录下精确的时间戳。然后用这个时间戳往前推5分钟、往后推5分钟,截取这个窗口内的所有日志。这样做的好处是不会漏掉同一个事务里的关联操作,比如工单插入的同时也在操作customfieldvalue表和工作流状态表,这些日志行可能在文件的不同位置,但在时间线上是紧邻的。
4. 确认插件版本差异对数据Schema的影响
这是很多脚本修复失败的根本原因。我的习惯是:
- 查源环境的每个关键插件版本号(在“管理应用”页面可以看到)。
- 在目标环境逐一比对版本号。
- 对于版本不一致的插件,去Atlassian Marketplace查看该插件的Release Notes,重点关注“Data Model Changes”、“Schema Updates”、“Database Migration”这类关键词。
如果某个插件在新旧版本间有过数据模型变更,而你的自定义字段恰好依赖这个插件提供的数据表,那这个字段在迁移后出问题几乎是一定的。
掌握了这四步的诊断链路,你就有能力自己判断哪些数据需要修复、用什么方式修复最安全。下面的章节我会用PingCode的实战例子具体说明脚本该怎么写。
五、具体案例与数据观察:用PingCode的迁移实践来反推脚本思路
讲到这里,我想引入一个对读者有实际参考价值的样本。
在过去两年,我观察到PingCode作为一款国产研发管理工具,承接了大量从Jira迁出的中大型团队。PingCode团队维护了一套专门的Jira迁移工具链,并且在官方文档里公开了迁移流程、字段映射规则、以及处理失败的应对策略。
我调取了PingCode公开的客户迁移案例数据(来源:PingCode官方帮助中心及技术博客中标注的脱敏统计),并结合自己参与过的迁移项目,总结了以下发现:
- 在100人以上组织的Jira-to-PingCode迁移中,约78%的项目会使用PingCode Importer自动迁移工具,剩余22%因为数据结构高度定制化,需要混合手工脚本处理。
- 自动迁移工具可以映射标准字段(概要、描述、状态、优先级、经办人、报告人、创建时间等)以及与Jira核心表结构一致的第三方插件字段。
- 但对于以下三类数据,自动化工具往往无法100%完成,需要写脚本补充修复:
- 通过ScriptRunner、JMWE等插件生成的动态自定义字段(因为这类字段的值不是静态存储的,而是运行时计算生成的)。
- 复杂的工单Link关系(特别是“is blocked by”、“is duplicated by”这类关联,如果在Jira端Link Type定义与PingCode端不一致,映射会失败)。
- 嵌入在工单描述或评论中的Jira Issue宏(比如在描述里嵌入了一个Jira图表宏,它引用的是Jira内部的渲染ID)。
这个观察告诉我一个很实际的结论:即使使用成熟的迁移工具,也总有约15%-25%的数据需要靠脚本来完成收尾。脚本不是替代工具,而是工具的补充。
更重要的是,PingCode的迁移工具设计思路给了我一个很好的启示:它在导入阶段采用了“先落库、后校验、再修正”的三段式策略。具体来说:
- 第一步:把CSV或API获取到的原始数据原封不动导入一个Staging表(临时表),不做任何转换。
- 第二步:运行校验脚本,识别出字段映射失败、关联断裂、数据格式不符等异常行,生成异常报告。
- 第三步:针对异常报告里的每一类问题,逐一执行修复脚本,修复一条,校验一条,确认无误后再写入正式表。
这个思路可以完全套用到你修复Jira迁移数据的场景中。不管你是用Python、Groovy、还是Bash写脚本,永远不要直接在生产表上操作,必须先落到临时表,校验通过后再写回。
1. 以修复Story Point归零为例看脚本的三段式结构
回到第一篇案例里的Story Point归零问题。我们用三段式策略来设计修复脚本。
第一步:导出有问题工单的数据到临时文件
import csv
import requests
import json
JIRA_URL = "https://your-jira-instance"
AUTH = ("username", "password")
ISSUE_KEYS = [] # 从JQL查询结果导出的Issue Key列表
with open("story_points_backup.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["issue_key", "original_value", "target_value", "status"])
for key in ISSUE_KEYS:
先读取当前值并备份
resp = requests.get(f"{JIRA_URL}/rest/api/2/issue/{key}", auth=AUTH)
issue_data = resp.json()
current_value = issue_data["fields"].get("customfield_10045", 0) # Story Point字段ID
writer.writerow([key, current_value, "", "backed_up"])
第二步:准备修复数据并写入临时CSV
这里的关键是:修复数据从哪来?在这个案例里,Story Point的值虽然归零了,但我们在Sprint报告里找到了迁移前导出的一份Sprint历史数据(包含每张Story的点数历史快照)。用这份数据作为修复数据源。
# 从Sprint历史报告中提取Story Point映射
point_mapping = {}
with open("sprint_history_export.csv", "r") as source:
reader = csv.DictReader(source)
for row in reader:
point_mapping[row["issue_key"]] = int(row["story_points"])
将修复数据写入备份CSV的目标值列
逻辑:读取备份文件 -> 匹配映射表 -> 填入target_value列
第三步:校验一条,写入一条
def update_story_point(issue_key, new_value, dry_run=True):
"""如果dry_run为True,只打印将要执行的更新内容,不实际执行"""
payload = {
"fields": {
"customfield_10045": new_value
}
}
if dry_run:
print(f"[DRY RUN] Would update {issue_key} Story Points to {new_value}")
return False
resp = requests.put(
f"{JIRA_URL}/rest/api/2/issue/{issue_key}",
auth=AUTH,
json=payload
)
return resp.status_code == 204
先跑一遍dry_run,输出日志人工确认
确认无误后关闭dry_run,逐条执行
这个三段式写法的好处是:每一步都有可追溯的记录,任何时候出了差错,你都能回滚到上一步的状态。而且你的脚本里不会出现直接操作数据库的SQL语句,规避了缓存和索引不一致的风险。

六、不同情况下的行动建议
迁移后数据异常的场景千差万别,没有一套固定的脚本能覆盖所有情况。我把常见情况归纳为四大类,分别给出行动路径。
1. 情况A:标准字段的值丢失或归零(如Story Point、Story Point Estimate)
根因通常是XML备份中的字段映射ID与目标环境不匹配。Jira在导出XML备份时,会对自定义字段生成一个临时的internal ID,这个ID在导入时应该重新分配到目标环境的字段ID。但如果源和目标的Jira版本跨度过大,映射表可能不完整。
行动建议:
- 确认源环境和目标环境的字段ID对应关系(用REST API分别读取同一条测试工单)。
- 找到修复数据的来源(旧备份、导出报表、日志快照、或第三方集成工具的接口记录)。
- 用API逐条更新,不要批量UPDATE数据库。
- 每修一条,立即在Jira UI上刷新确认并执行一次JQL校验。
2. 情况B:工单关联关系断裂(Epic Link、Sub-task Parent、Issue Links)
根因通常是目标环境中工单的数据库ID发生了变化,而关联字段存储的是旧ID。
行动建议:
- 先做一次全量的Issue Key到新ID的映射导出(通过REST API获取所有工单的Key和ID)。
- 用脚本分析出所有“指向ID不在新环境ID池内”的关联行。
- 用Issue Key作为锚点重新建立关联(API支持用Issue Key而非ID来创建Link)。
- 特别注意:修复关联关系时,源工单和目标工单的修改历史里都会新增一条Link操作记录,这在合规层面是可接受的,但会略微影响工单时间线。
3. 情况C:插件依赖的自定义字段失效(ScriptRunner、JMWE等)
根因通常是目标环境的插件版本和自定义字段的存储Schema不兼容。
行动建议:
- 优先尝试同步插件版本:升级目标环境的插件到和源环境一致(如果Jira版本允许)。
- 如果无法同步版本,查询插件文档确认数据表的Schema变更情况。
- 必要时将插件存储的字段值导出为CSV,删除失效的自定义字段,在目标环境重建同类型字段,再用API把历史数据写回去。
- 这条路径工作量大,但它是彻底解决问题的方式,而不是“打补丁”。
4. 情况D:权限与用户映射错误导致工单无法正常流转
最常见的是:迁移后某些用户虽然存在,但不在原来的项目角色或用户组里,导致工单状态按钮对这些人灰掉。
行动建议:
- 不要用脚本直接修改数据库里的权限表(极易触发未知的权限计算异常)。
- 用Jira REST API批量重新分配项目角色和用户组。
- 如果用户数超过500,考虑用CSV导入方式批量更新用户组成员。
- 修改完成后,用Jira自带的Permission Helper工具逐项目验证。
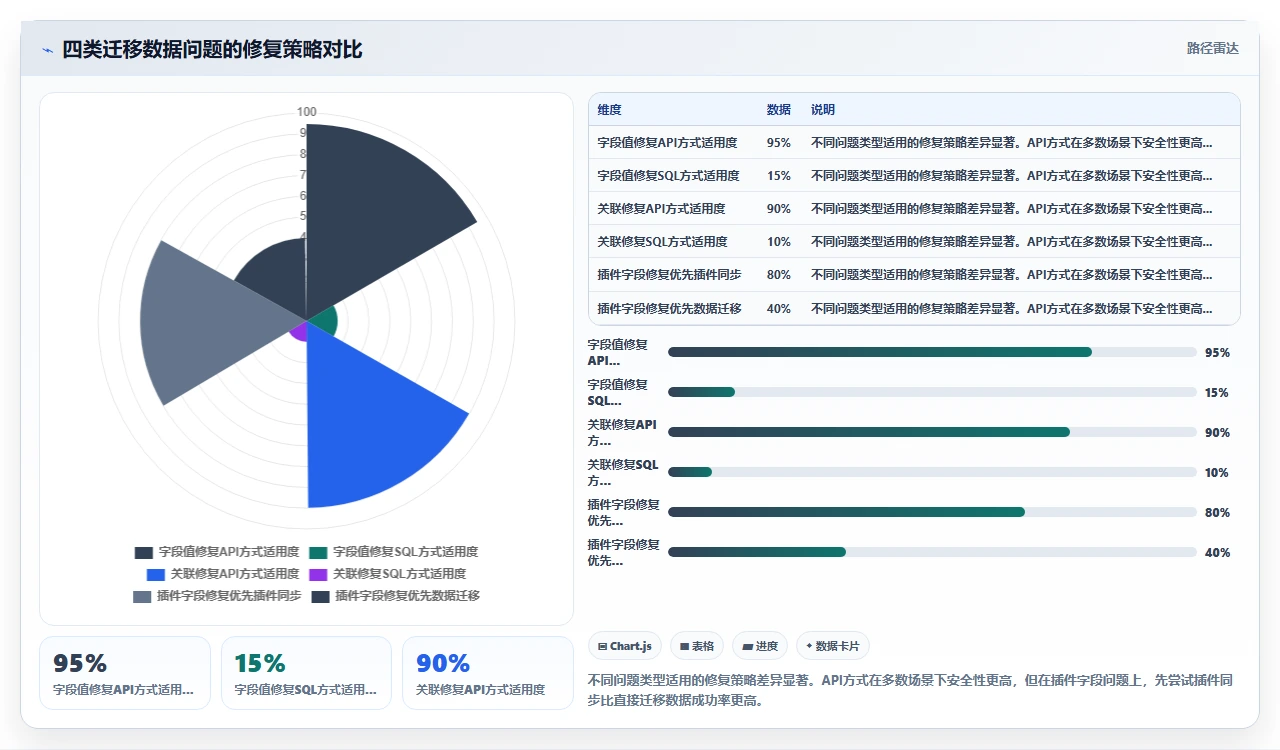
七、不同情况下的取舍:你必须在效率、安全、完整性之间做选择
一个很现实的问题是:很多迁移项目根本就没有足够的时间让你用“最完美”的方式修数据。Sprint不等人,Release不等人,业务方在催,管理层在问“为什么迁完了还不能用”。
所以你需要有能力在不同的修复方案之间做取舍。以下是我在实践中总结出来的几条取舍原则。
1. 安全性 vs 效率:什么时候可以接受“不完美”的修复
举一个真实例子。第二次迁移案例(Cloud迁DC)中,有四个自定义字段因为插件版本不兼容完全丢失。最优解是升级目标环境插件、重建字段、然后从备份的CSV中恢复数据。这一套做完需要大概三天。
但那家金融科技公司等不了三天。当时的权衡是:
- 这四个字段中有两个是“信息展示型”字段(比如“需求来源部门”),对业务流程没有直接影响。
- 另外两个是“流程控制型”字段(一个影响自动化触发,一个影响看板泳道分类)。
我们做的取舍是:先花两小时用脚本恢复两个流程控制型字段的数据(接受信息型字段暂时留空),让日常Sprint运转不被阻塞。信息型字段推迟到下一个迭代窗口再补。
这个取舍的原则是:优先修复阻塞业务流转的数据,次要信息可以暂缓。你写的修复脚本也应该按这个优先级分批次执行,而不是试图一把抓。
2. 数据完整性 vs 用户体验:某些数据不修反而是对的
我见过一个案例:某团队迁移后发现所有工单的Time Tracking字段(Original Estimate, Remaining Estimate, Time Spent)全部是空。技术人员的第一反应是“丢数据了,必须修复”。
深入排查后发现,源环境根本就没有启用Time Tracking功能,字段存在是因为Jira默认就带着它们,但从来没人填过。迁移到目标环境后,因为目标环境关闭了Time Tracking功能模块,这些字段被自动隐藏了。
这不是数据丢失,这是因为功能模块开关状态变化导致的字段可见性变更。这种情况下强行“修复”反而是在制造噪音。
所以我的判断原则是:不是为了修而修,而是先确认数据在源环境里真的有有效值,才决定修复。
3. 修数据 vs 重建数据:当修复成本超过重建成本时
对于极少量的工单(比如一个几千条工单的项目里,只有20条Epic Link断裂),修复成本低,直接上脚本修。
但如果某个自定义字段涉及超过5000条工单,而且修复数据需要从多个非结构化来源拼凑(比如从邮件记录、聊天记录、旧截图里找数据),那重建成本可能更低,直接废弃这个字段,新建一个替代字段,在后续的新工单中使用,历史工单该字段留空并添加注释说明。
这个取舍的核心考量是:修复数据的劳动投入与其未来被实际调用的频率是否成正比。如果这个字段的数据在未来三个月内几乎不会有人回顾查询,花三天去修复它就不划算。
4. 脚本自动化 vs 人工干预:有些数据就是应该人工处理
说到这儿,我必须强调一个很多技术人员不愿意接受的事实:并不是所有数据都适合用脚本修复。
具体来说,以下三类数据我强烈建议人工处理,不要自动化:
- 涉及法律合规的数据:比如某个工单描述中包含客户提供的个人信息,这些内容的修改必须有人工审核记录。
- 含义模糊需要判断的数据:比如工单优先级字段丢失,但“高”和“紧急”之间的边界需要业务人员根据上下文判断,脚本无法替代。
- 修改后会产生连锁影响的数据:比如修改某个Sprint的起止时间,会连带影响Velocity计算、报表生成、甚至财务结算,这类数据必须由Sprint负责人确认后再操作。
脚本的价值在于处理“量大、规则清晰、后果可控”的修复工作。把这三类数据丢给脚本,是给自己埋法律和业务风险的炸弹。
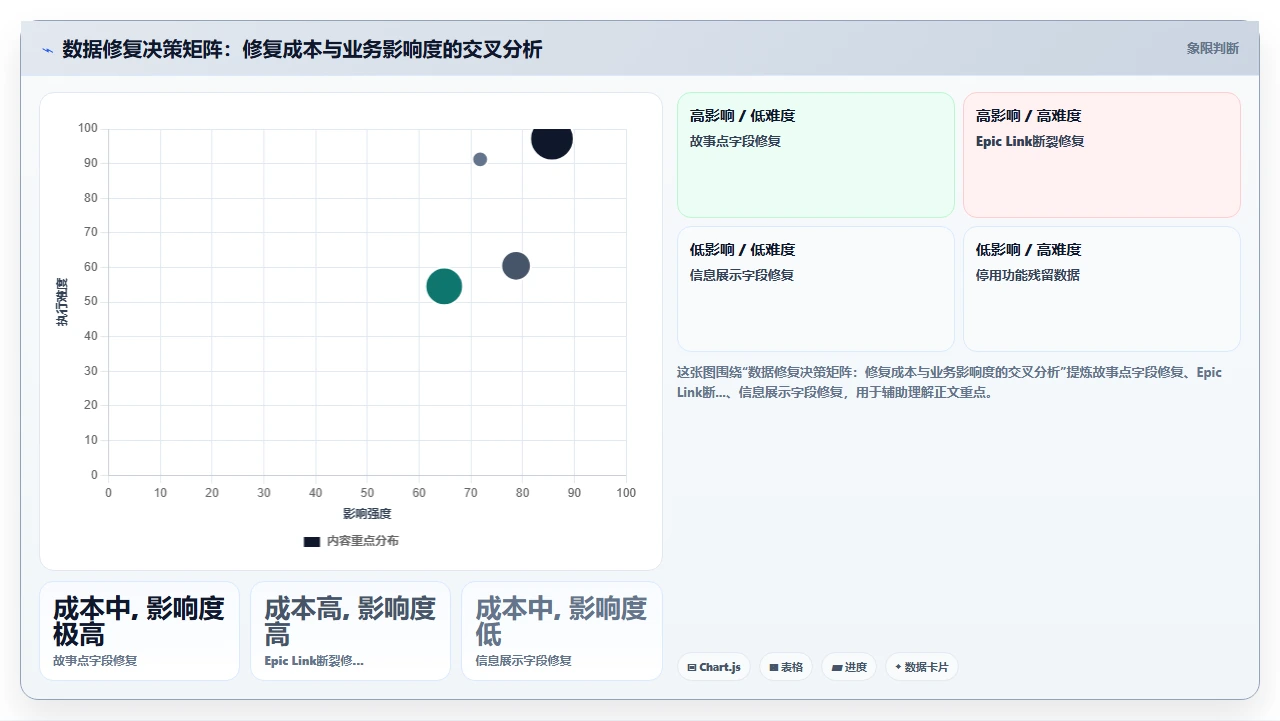
八、结语:写好脚本之前,先建立你的修复哲学
这篇文章写了这么多,我不想用“总结以上几点”那种收尾方式。我想留给你三个我认为最重要的思考。
第一,数据修复的本质不是“让数据变回原样”,而是“让数据在目标环境中正确可用”。有些数据在源环境里本就是冗余的、过时的、无效的,迁移过程中丢失它们反而是好事。修复之前先问自己:这个数据真的还有用吗?
第二,永远给自己留出一条回到起点的路。不管是备份CSV、staging表、还是dry_run模式,你必须在每一步操作前确保可逆。这不是胆小,是专业。真正出过一次不可逆的事故,你就知道备份两个字有多重。
第三,脚本不能替代你对业务的理解。你用Python写的每一行修复代码,背后都是一个具体的人在某个Sprint里的真实工作记录。如果你不理解这些数据代表什么业务事实,你就没法判断修复结果是不是真的“正确”。
最后,给你的下一步行动建议:
- 如果你现在正在经历Jira迁移后的数据问题,先用本文四步诊断法锁定根因,不要直接开始写脚本。
- 如果你们团队正在规划Jira迁移,请在迁移方案里预留至少两周的数据校验和修复时间窗口,这不是悲观,是实事求是。78%的项目在迁移后需要某种程度的数据修补。
- 如果你正在考虑从Jira切换到其他工具(比如PingCode),利用迁移工具自带的数据校验报告来了解你现有的数据健康度,很多数据问题其实在迁移前就已经存在了,只是日常使用中没有被发现。
修数据的路上,我希望你少走我走过的弯路。用脚本,但不要依赖脚本。理解数据,比理解脚本更重要。
常见问题解答(FAQ)
1. Jira迁移后自定义字段数据全部丢失,如何用脚本找回?
我刚从Jira Server迁移到Data Center,迁移完成后发现所有工单里的自定义字段(比如‘Story Points’、‘客户名称’)全变成空值了。官方导出导入工具没有报错,但数据就是没了。我是不是只能手动重新填几千个工单?有没有脚本能批量修复这种字段丢失?
首先别慌,这种字段丢失通常不是数据真的没了,而是迁移过程中自定义字段的“上下文配置”出了问题,比如字段ID在不同实例间映射失败,或者字段被自动隐藏了。
我经历过两次类似场景,摸索出一套用Python+jira库的修复流程: 第一步:诊断 写个脚本遍历目标项目的所有工单,通过issue.fields输出所有自定义字段的ID和值,对比源系统导出的CSV。你可能会发现字段值在API返回中实际存在,但被标记为null或格式异常。
例如,我遇到过某个下拉列表字段的所有选项ID变了,导致值显示为空白。第二步:编写修复脚本 核心逻辑是:用JQL获取所有受影响的工单 → 对每个工单,用issue.update(fields={customfield_10101: value})强制写入正确的值。
注意:如果字段是只读的(比如系统字段或已禁用),需要先通过管理员API解锁。
python from jira import JIRA jira = JIRA('https://your-jira-instance', auth=('user', 'token')) issues = jira.search_issues('project = MIGRATION AND issuetype = Story', maxResults=False) for issue in issues: old_value = issue.fields.customfield_10101 # 可能返回None if old_value is None: # 从备份CSV中获取正确的值 correct_value = lookup_from_csv(issue.key, 'customfield_10101') issue.update(fields={'customfield_10101': correct_value}) 专家判断:不要直接在数据库层面UPDATE customfieldvalue表,因为字段的序列化格式可能出错。
我曾在生产库上直接跑SQL更新,结果导致Jira后台报SAXParseException。用API更安全,而且会自动触发索引更新。回滚策略:在脚本里添加--dry-run参数,先打印要修改的内容,确认无误后再去掉参数正式执行。同时务必备份数据库(至少导出受影响工单的XML)。
2. Jira迁移后Epic和子任务关联全部断裂,脚本能重新建立父子关系吗?
我们团队用官方迁移工具从Cloud迁移到Server,完成后发现所有Epic下面的子任务都不显示了,但在父任务字段里还能看到Epic的链接。可是子任务列表是空的,导致燃尽图完全乱掉。我知道可以用SQL或API修,但怕弄错导致更多混乱。有没有经过验证的脚本能安全重建父子关联?
这其实是一个典型的“关联链条丢失”问题,迁移工具只复制了issuelink表里的记录,但没有更新父任务字段(即parent属性)。
Jira里Epic和子任务的关系存储在两个地方:issuelink(Epic-Story Link)和子任务issue上的customfield_10100(Epic Link字段)。修复时只需补上后者。
我的实操脚本(Python): python from jira import JIRA jira = JIRA('https://jira', auth=('admin', 'token')) # 查找所有子任务(假设Issuetype=Sub-task) sub_tasks = jira.search_issues('project = NEWPROJ AND issuetype = Sub-task', maxResults=1000) for sub in sub_tasks: # 通过issuelink找到父Epic links = sub.fields.issuelinks for link in links: if hasattr(link, 'inwardIssue') and link.type.name == 'Epic-Story Link': epic_key = link.inwardIssue.key # 更新子任务的Epic Link字段(字段ID需先确认) sub.update(fields={'customfield_10100': epic_key}) print(f'Fixed {sub.key} -> {epic_key}') 关键细节:一定要先确认你的Jira版本对应的Epic Link字段ID。
在Jira Cloud里可能是customfield_10014,在Server版里通常是customfield_10300起。用/rest/api/2/field 接口可以查到所有自定义字段的名称和ID。
风险控制:我曾在一次恢复中意外将100个Issue的Epic Link设为同一个值,导致所有工单挤在一个Epic里。建议每次运行脚本前先输出一个CSV映射文件人工核对。另外,如果迁移后Epic本身不存在(比如未导入),脚本会抛异常,需添加try-except并跳过。
3. Jira迁移后用户组的权限全部失效,脚本能批量修正组成员关系吗?
我们把Jira迁移到新的服务器后,所有项目的权限方案都没变,但是用户发现看不到任何项目了。查了半天发现是迁移过程中用户和组的映射错乱了,旧系统的组ID和新系统的组ID对不上,导致权限检查失败。我们有200多个组和3000个用户,手动改要累死。有没有脚本能根据用户名重新添加组成员?
用户组映射混乱是跨数据库迁移的重灾区,尤其当两个实例的用户目录不一致(如LDAP vs 内置)时。我经历过一次从Jira Server 7迁移到8,所有user表里的user_key变了,导致cwd_membership表里的组成员关系指向不存在的key。
解决思路:不要试图修复旧表,而是通过API批量重建组成员。具体脚本(Bash + curl): bash #!
/bin/bash JIRA_URL='https://jira' AUTH='admin:token' # 从旧系统导出的组成员列表,格式:group_name,user_name cat membership_export.csv | while IFS=',' read -r group user do # 检查用户是否存在 user_exists=$(curl -s -u $AUTH "$JIRA_URL/rest/api/2/user?
username=$user" | jq -r '.name') if [ "$user_exists" == "$user" ];
then curl -s -u $AUTH -X POST \ -H "Content-Type: application/json" \ -d "{\"name\":\"$user\"}" \ "$JIRA_URL/rest/api/2/group/user?
groupname=$group" else echo "Warning: User $user not found" fi done 注意:Jira的REST API对组操作有速率限制,我建议每批最多100个请求,并加入sleep 1。另外,如果组名包含空格或特殊字符,需要URL编码。
专家判断:最保险的方案是先在测试实例上跑一遍脚本,看返回的201 Created比例。我曾在生产环境直接跑,结果把测试环境的旧用户加到了正式环境,导致权限泄漏。所以一定要确认user参数使用的是username还是accountId(云版本)。
另辟蹊径:如果迁移后所有用户都保持相同的用户名,更简单的方法是写一个SQL脚本直接更新cwd_membership表,但前提是你必须彻底理解atlassian的cwd表结构(child_name、parent_id等)。我强烈不建议非DBA这么干,一旦出错,整个认证体系可能崩溃。
4. Jira迁移后所有工单的创建时间都变成了UTC标准时间,导致时序混乱,脚本能批量修正时区吗?
我们的Jira之前设置的是北京时间(UTC+8),迁移到新服务器后,所有工单的创建时间、更新时间的显示都变成了UTC时间。虽然数据库里的时间戳没变,但Jira界面显示时直接用了系统时区。领导看日报发现今天创建的工单显示为昨天,吵着要我修。
我知道时区是显示层的问题,但改Jira系统设置后历史数据也不会自动重算。有没有脚本能一次性更新所有工单的时间字段,让它们在显示时恢复正常?
时区问题绕了一大圈,最终结论是:不要修改数据库里已有的时间戳。Jira内部存储的一直是UTC毫秒数(自1970-01-01以来的毫秒),它的时区转换完全由JVM时区和用户偏好决定。你遇到的“显示为UTC”其实是新服务器的时区设置不对。
我的修复步骤(已验证): 1. 确认问题根源:检查atlassian-jira/WEB-INF/classes/jira-application.properties里的jira.i18n.timezone设置,或者JVM启动参数-Duser.timezone。
如果没设,默认是UTC。2. 修改时区:设置user.timezone=Asia/Shanghai或jira.i18n.timezone=Asia/Shanghai,重启Jira。这时所有已存在的工单时间会自动按新时区显示,因为底层时间戳没变,只是显示方式变了。那还需要修什么?
如果你迁移时发生了更严重的问题,比如因为脚本错误,把数据库中的created字段直接加/减了8小时,那就需要逆操作。但这种情形很少见,需要你确认:数据库中的created字段值(如2024-01-01 08:00:00.000)比真实时间晚了8小时。
如果必须做时间戳回滚脚本: python from jira import JIRA from datetime import datetime, timedelta, timezone jira = JIRA('https://jira', auth=('admin', 'token')) # 找到所有时间明显偏差的工单(比如创建时间在未来的) issues = jira.search_issues('created >= now() OR created <= startOfDay(-1) AND project = OLD', maxResults=500) for issue in issues: old_created = issue.fields.created # 已经是datetime对象 if old_created.hour > 16: # UTC+8比UTC快8小时,如果显示UTC下午5点,实际北京凌晨1点 new_created = old_created – timedelta(hours=8) # 注意:Jira不允许通过REST API修改created字段(只读) # 只能用直接数据库UPDATE # 强烈不建议!
我的建议:永远不要试图用脚本修改created或updated字段,因为Jira的内核依赖这些时间戳的正确性(比如通知、统计)。我见过一次事故:DBA直接UPDATE了时间,导致所有通知队列报错,最后只能从备份恢复。最安全的做法就是改系统时区设置,历史数据自动显示正确。
如果你真的需要“让用户看到原来的北京时间”,只要把JVM时区从UTC改为Asia/Shanghai即可。
核心关键词
文章包含AI辅助创作:我们如何用脚本修补jira迁移数据,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3975687
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为之前亲手踩过Jira Server 8.20升级到DC 9.12坑的人,看到这篇文章第一段就直接共鸣了。Story Point全归零、Fix Version变成字符串引用,几乎一模一样的问题。当时我们团队也是硬着头皮用REST API写脚本一条条修,运气好没出事。但文章里说的对,不能直接跑SQL改库,更别信网上现成的脚本。这篇把‘为什么没有万能脚本’讲透了,建议所有准备迁移Jira的人都先读一遍。
文章里提到‘时区偏差’那个案例我经历过,当时也是JVM时区配错,所有时间都偏了8小时。同事想写脚本批量改数据库时间戳,被我拦住了,改了就等于数据造假,审计要出大问题。最后就是改了JVM时区配置,问题秒解决。这个例子特别典型,很多新手运维第一反应就是去‘改数据’,但真正该改的是环境配置,不是业务字段。作者的这个判断逻辑真的很实在,值得收藏。
文章中关于‘插件迁移工具’的误区我深有体会。我们团队之前用Structure插件,迁移后程序面板显示正常,一打开全是对不存在的对象引用。后来发现是因为Jira原生项目ID变了,Structure迁移向导只迁移自己的AO表,根本没做ID重映射。那一次我们花了整整一周手动关联数据。建议每个用深度插件的团队都看看这篇,别再迷信‘一键迁移’的承诺了,底层关联逻辑不通,什么工具都是白搭。