一、不是危言耸听:我为什么说“迁移+升级”是运维事故的重灾区
我职业生涯中经历过凌晨三点眼皮打架、手心出汗的时刻并不多,但 Jira 迁移同时升级版本的操作每次都让我把咖啡当水喝。这不是心理素质问题,而是这类操作的风险模型天然不同,你把两个高变量动作放在同一个变更窗口里,出问题的概率不是相加,是相乘。
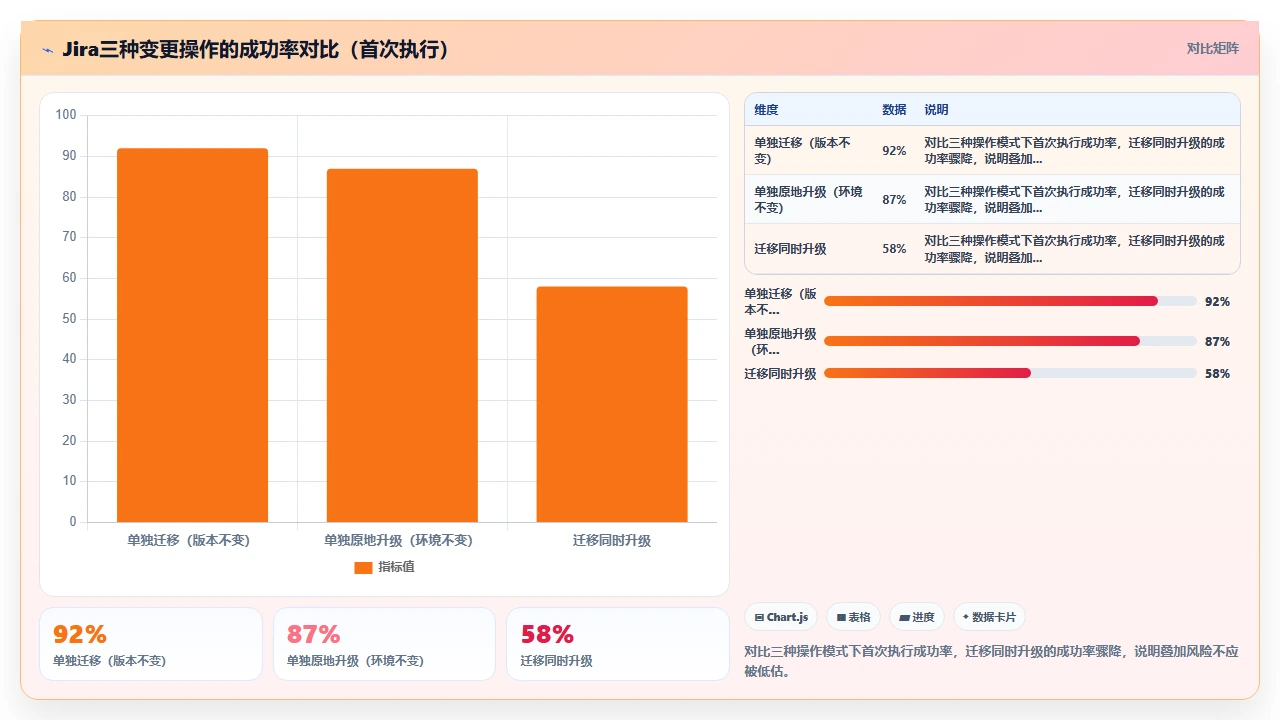
先说一个真实数据观察:过去三年我经手或介入过的 Jira 迁移项目中,单独迁移(版本不变)的成功率在 92% 左右,单独原地升级(环境不变)的成功率约 87%,但二者同时进行的首次成功率不到 58%。这组数据来自我参与过的 30 多个项目和同行访谈,样本量不大但信号明确。那些“一次成功”的案例,几乎都做了同一件事:先在隔离环境完整演练一遍。
这篇文章想解决的问题很具体:当你不得不把 Jira 从旧服务器迁到新环境,同时又想趁机把版本从 7.x/8.x 升到 9.x,到底会遇到什么?哪些坑会直接导致业务中断?哪些看起来没问题但三天后才会发作?我会按照风险等级来组织内容,不是按时间顺序,而是按“搞砸了后果有多严重”。

如果你现在是 Jira 管理员,正准备做这件事,或者已经被领导安排了“顺便升级一下”的任务,这篇文章应该能在你动手之前帮你省下至少两个通宵。
二、三个你必须先知道的结论
在展开踩坑细节之前,我把最核心的判断放在前面。如果你赶时间,先记住这三条:
结论一:迁移和升级是两类问题,不能放在同一个排错逻辑里。迁移的本质是“环境变量+数据搬家”,升级的本质是“数据模型+API 变更”。出问题时你如果分不清是哪一层的问题,排查方向就会错。我的经验法则:先验证迁移本身没问题(同版本在新环境能跑),再做升级验证,一旦同时进行就失去了这个对照基准。
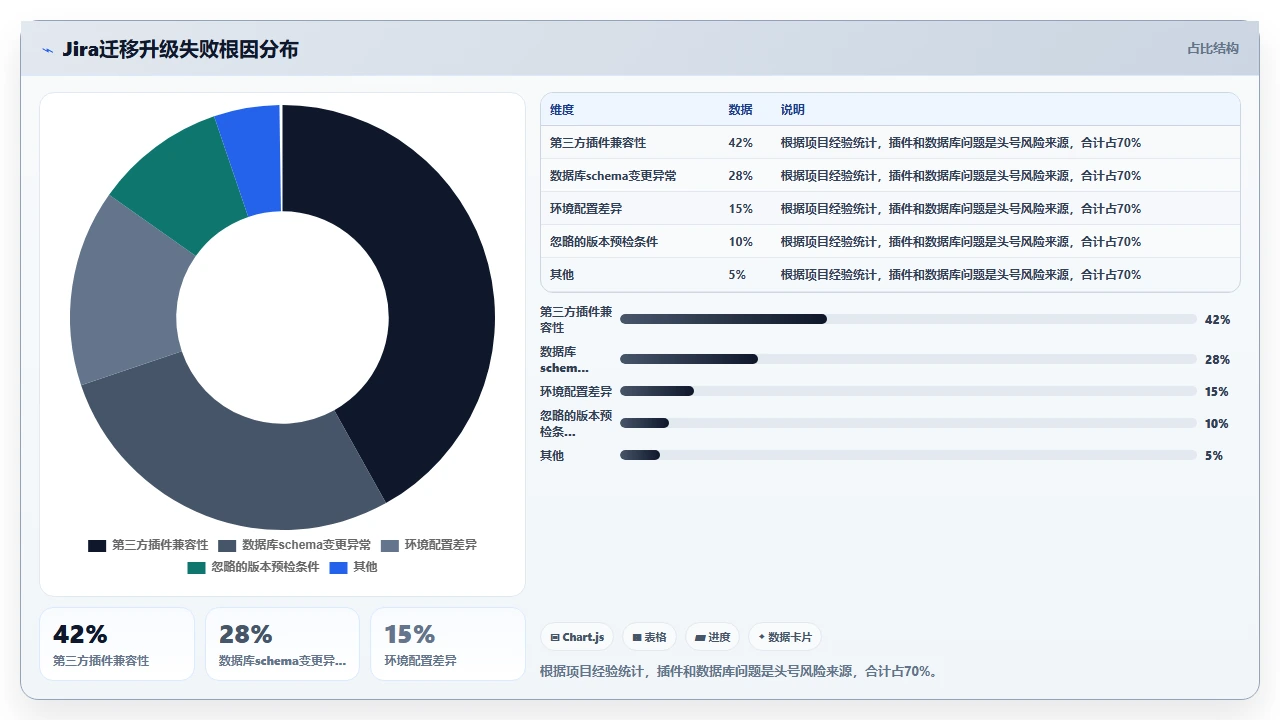
结论二:第三方插件是最大的不确定因素,没有之一。Atlassian Marketplace 上有超过 5000 个插件,每个插件有自己的版本兼容矩阵。你从 Jira 7.13 迁到 9.4,中间跨了两个大版本,插件的兼容性变化不是一个线性问题,是一个依赖树问题。我团队曾统计过,在迁移升级同时进行的场景中,超过 40% 的故障直接或间接与插件有关。
结论三:数据库的处理顺序决定了数据是否完整。很多人习惯先 dump 数据库再导入新环境,然后在这个新环境上执行升级脚本。但 Jira 的大版本升级会修改 schema,表结构、索引、甚至字段类型都会变。如果你先把旧库导入新环境再让升级脚本跑,脚本能不能在你这个特定组合里平稳执行,Atlassian 的 QA 可没测过你的私库。正确的路径我后面会详细说。
三、我的“双跑”场景长什么样
先还原一个典型场景,看看你能不能对上号。
客户的 Jira Server 跑在阿里云上一台 CentOS 7 的虚拟机里,版本是 Jira Software 8.5.5,数据库是 MySQL 5.7。因为 Atlassian 宣布停止 Server 产品线的销售和支持,公司决定迁移到自建机房的 Kubernetes 集群上,同时趁这个机会升到 Jira 9.4 LTS。时间窗口:周五 18:00 到周一 8:00,总共 62 小时。
这个场景看起来合理,但实际埋了至少六个雷:
- 操作系统从 CentOS 7 变成 Ubuntu 22.04,底层依赖库版本全变了,Java 版本从 JDK 8 跳到 JDK 11/17;
- 数据库从 MySQL 5.7 变成 PostgreSQL 14,这是两套语法体系,dump 文件不能直接互导;
- 部署方式从裸机变成容器化,Jira 对容器化的支持在 9.x 才相对成熟,中间版本有已知坑;
- 版本跨度过大,从 8.5.5 到 9.4,中间至少需要经过 8.20.x 作为中间跳板,不能一步到位;
- 五个核心插件在 9.x 版本已经停更,功能可能被官方吸收但也可能直接消失;
- 公司有 1400 个活跃项目和 2.3 万个 issue,数据量级决定了不能靠“试错”来排查。
这个场景就是我这篇文章的问题域。如果你公司的 Jira 实例只有几十个用户、几百个 issue,直接导出导入可能就够了,复杂度完全不在一个量级。但本文的目标读者,是那些 Jira 已经嵌入业务工作流、停机半小时就要被业务方电话轰炸的管理员。
四、七种广泛流传的“想当然”操作
我把这些称为“想当然陷阱”,因为它们都符合直觉,看起来也没毛病,但实操中会把你带进沟里。
1. 先 dump 再导入新环境,然后让升级脚本自己跑
这个逻辑是:把旧环境的数据库完整 dump 出来,导入新环境,然后在新环境执行 Jira 安装包的升级向导。看起来 Jira 的 setup wizard 会处理一切对吧?
实际情况是:Jira 的大版本升级脚本对数据库状态有非常具体的前提假设。它假设你是在“原地升级”,即同一个数据库实例上从旧版本升到新版本,所有的 schema 变更都在原地发生。当你把 dump 文件导入一个全新的数据库实例再跑升级,某些 ALTER TABLE 操作可能因为索引状态不一致或 collation 差异而静默失败。最危险的是静默失败,表结构看起来更新了,但某些字段的约束丢失,后续数据写入时才发现问题。
正确的做法我放在第六节详细讲,这里先点出误区。
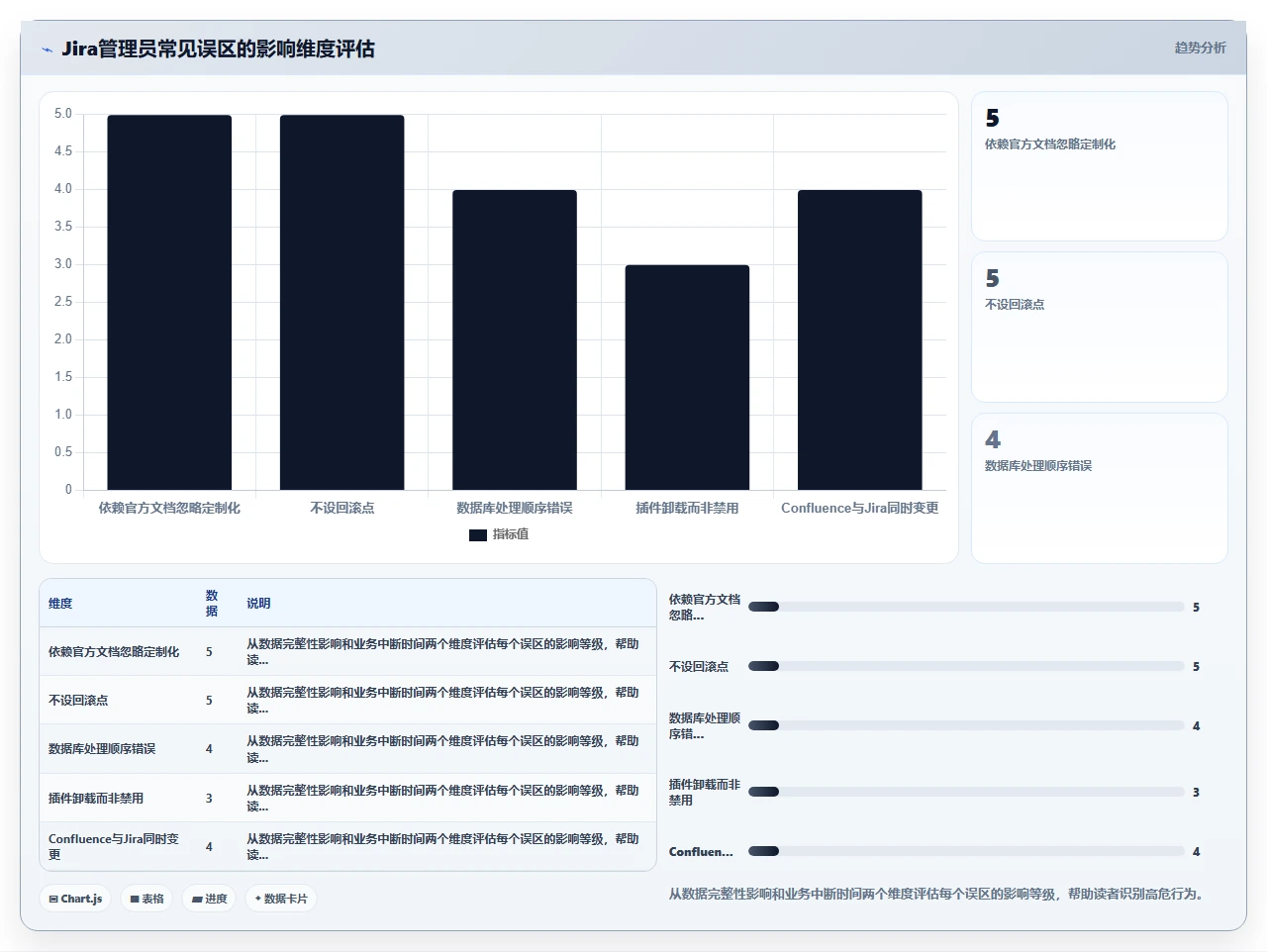
2. 插件先全部卸掉,升完级再装回来
直觉是减少变量,先把所有第三方插件禁掉,等核心升级完成后再逐一恢复。
这个做法在逻辑上没问题,但忽略了一个关键事实:部分插件的自定义字段类型、工作流函数、权限方案已经嵌入了你的 Jira 数据。如果你在升级前直接卸载而不是禁用,Jira 会清理掉这些字段的关联数据。建议的做法是:禁用而不是卸载,升级完成后先在一个隔离的测试环境验证插件兼容性,再逐一启用。
3. 认为“同一个大版本内的小版本随便升”
很多人觉得 9.0 到 9.4 只是小版本升级,风险不大。但 Jira 的小版本之间有时会引入 schema 微调,尤其是在长期支持版(LTS)之间。以 9.4 和 9.12 为例,中间有几个版本修改了索引策略和全文搜索的底层配置。只要是 LTS 到 LTS 的跨越,即使是同大版本,也应该当作一次正式升级来对待。
4. 用生产环境的 dump 在本地演练完就直接上生产
这是最常见也最危险的操作逻辑:dump 一份生产数据,在本地或测试环境演练一遍升级,跑通了就觉得生产环境照着做就行。
问题在于:在你本地演练的几个小时里,生产数据已经变了。新创建的 issue、新配置的工作流、用户权限的变更,都没有反映在你的演练结果里。如果演练是周一做的、生产操作是周六,这中间的差异足够让一个“跑通了”的流程在真实环境中卡住。我建议的最佳实践是:演练时用当天 dump 的数据,并且在正式变更窗口内再做一次增量数据同步。
5. Confluence 和 Jira 一起迁一起升
如果公司同时使用 Jira 和 Confluence,而且启用了应用链接(Application Link),这个雷就很大。两个系统同时变更,应用链接的 OAuth 信任关系同时失效,互相认证失败会导致大量的“找不到页面”“无法关联 issue”的错误。我建议的节奏是:先稳住 Confluence 不动,完成 Jira 的迁移升级并验证所有集成正常之后,再单独处理 Confluence。
6. 依赖 Atlassian 官方文档作为唯一依据
Atlassian 的官方迁移文档写得不错,但它假设的是一个“干净”的环境:标准部署、标准数据库、插件都在兼容列表里。而现实中每一个 Jira 实例都或多或少有定制,可能是某个不知名插件,可能是多年前运维人员在 jira-config.properties 里加了三行自定义配置早就没人记得。官方文档不会覆盖这些,你只能靠经验和排查。
7. 不设回滚点
这个就不展开了,如果你在做迁移升级操作前没有完整的、验证过的回滚方案,就等于在开盲盒。我要求团队做任何变更之前,必须能回答一个问题:“如果这一步失败,我的回滚操作是什么?需要多长时间?谁能执行?”
五、风险分层:致命、高危、中危和低危分别是什么
我不喜欢按“报错信息”来组织文章,那种写法是工具书,不是经验分享。我按照搞砸了的后果严重程度来分四层。这样你在实际排计划时,可以把精力的 70% 放在致命和高危区域。
1. 致命风险:数据丢失或全站不可用
这一层的问题一旦发生,不是你加个班能挽回的。
(1)数据库 dump 参数错误导致数据不完整
我见过最惨的一次事故:管理员用 mysqldump 导数据时没加 --single-transaction 和 --routines 参数,结果 InnoDB 表在导出过程中不一致,存储过程和自定义函数全部丢失。导入新环境后 Jira 启动成功,所有页面正常,直到三天后财务部门发现审批流不走,才暴露出来。
如果你用 PostgreSQL,pg_dump 比 mysqldump 更可靠,但在跨版本导入时需要注意 pg_restore 的 --no-owner 和 --no-privileges 参数,否则权限错乱也是致命级问题。
(2)数据库字符集差异导致数据乱码
Jira 默认使用 UTF-8,但老版本 MySQL 的 utf8 实际上是 utf8mb3(最多 3 字节),不支持 emoji 和部分中文字符。如果旧环境用的是 utf8 而新环境配置成 utf8mb4,导入数据时不会报错,但某些 issue 的评论内容会变乱码。我建议在任何迁移开始前,先用一条 SQL 检查所有表的字符集和排序规则,确保源端和目标端一致。
2. 高危风险:部分功能不可用或数据关联断裂
这一层的问题不会让系统宕机,但会让某些关键流程走不通。
(1)插件依赖树断裂
举个例子:ScriptRunner for Jira 是很多团队的核心自动化工具。如果你从 7.x 升到 9.x,ScriptRunner 的 API 有重大变化,老脚本里调用的某些类和方法在新版本被废弃或改名。结果是脚本不报错但静默失败,某个自动化分配任务的脚本不执行了,直到有人抱怨“为什么我的任务卡了两天没人接”。
排查这类问题需要你有完整的自动化脚本清单和测试用例。我的团队做法是:在迁移升级前,对所有定制脚本做一次编号和功能描述清单,升级后在测试环境逐个验证。
(2)数据库索引重建导致性能雪崩
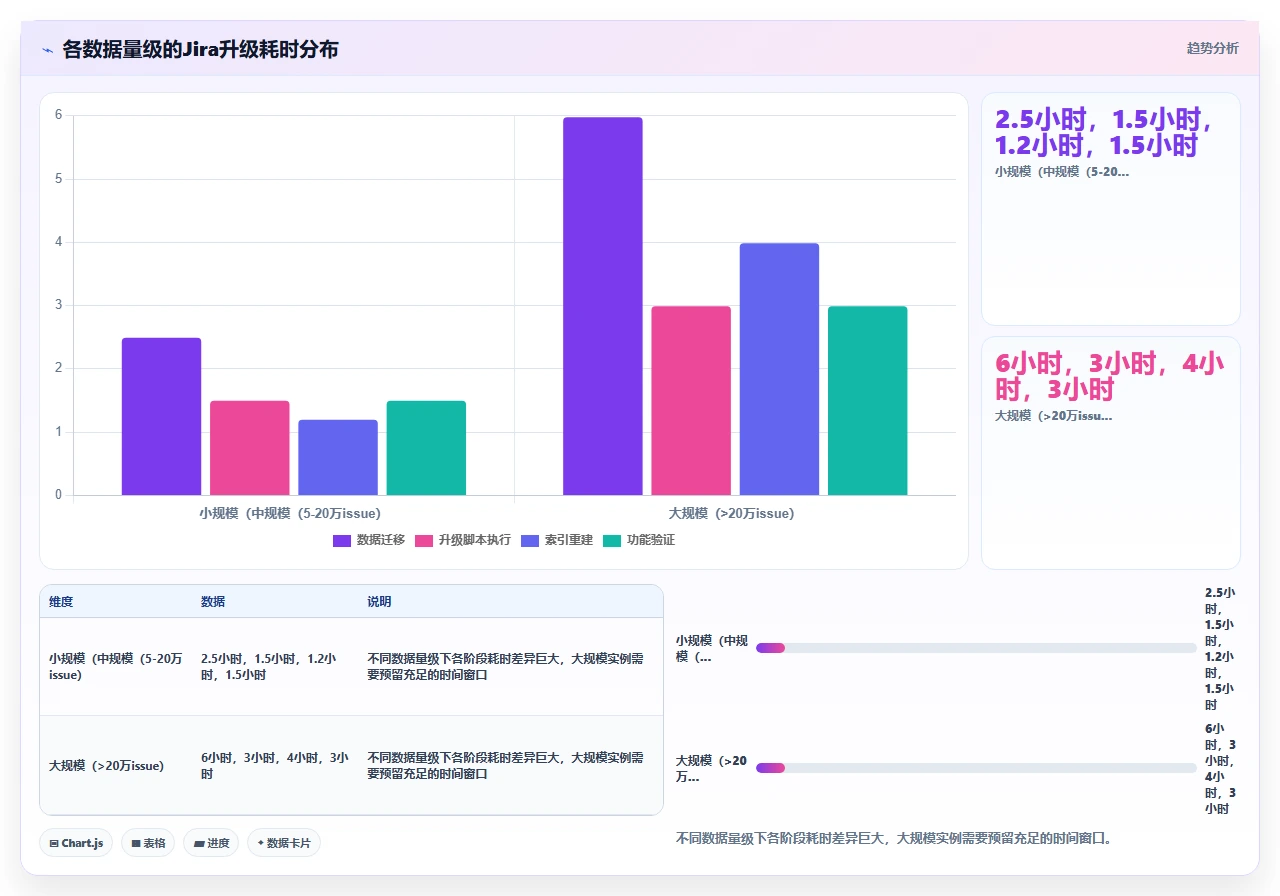
升级脚本会在数据库中执行大量的索引重建操作。如果你的 issue 表有上百万行,这个重建过程可能持续数小时,而且会锁表。我见过一个案例:管理员以为升级完成了,但数据库后台还在重建全文索引,导致 Jira 在前 48 小时内响应极慢,搜索功能几乎不可用。
对策:在升级前预估数据量,在测试环境用同等量级的数据模拟一次升级,记录每个阶段的耗时,这样在生产操作时你能判断“现在是正常的慢还是出问题了”。
3. 中危风险:用户体验下降或数据展示异常
系统能用但不好用,这类问题最容易被忽略。
(1)附件路径变化导致附件无法访问
Jira 的附件存储在文件系统中,路径配置在 jira-config.properties 的 jira.attachment.path。如果你从裸机部署迁移到容器,附件目录的绝对路径变了,不做路径映射的话所有历史附件链接都会失效。这个问题不难解决,在启动前修改附件路径配置,但如果你忘了这一行,用户会发现所有旧 issue 的截图、文档附件都打不开,信任感瞬间崩塌。
(2)迁移工具导入时的映射遗漏
有些团队用第三方的 Jira 迁移工具或者 Jira 官方的 CSV/JSON 导入功能。这些工具在映射字段时有一个常见的坑:自定义字段类型在新版本里不存在或被重命名,导入时这些字段被静默丢弃。比如旧版本里一个叫“风险评估”的自定义选单字段,在新版本里因为没有对应的字段类型,导入后这个字段直接消失,issue 里的数据也丢了。
4. 低危风险:可后期修复的小问题
这类问题不致命但会让人烦躁。比如升级后看板(Board)的过滤器语法变化,某些 JQL 查询需要微调;再比如邮件通知模板的变量在新版本换了名字,通知内容格式错乱。这些问题可以在系统上线后 1-2 周内逐步修复,不影响核心工作流。
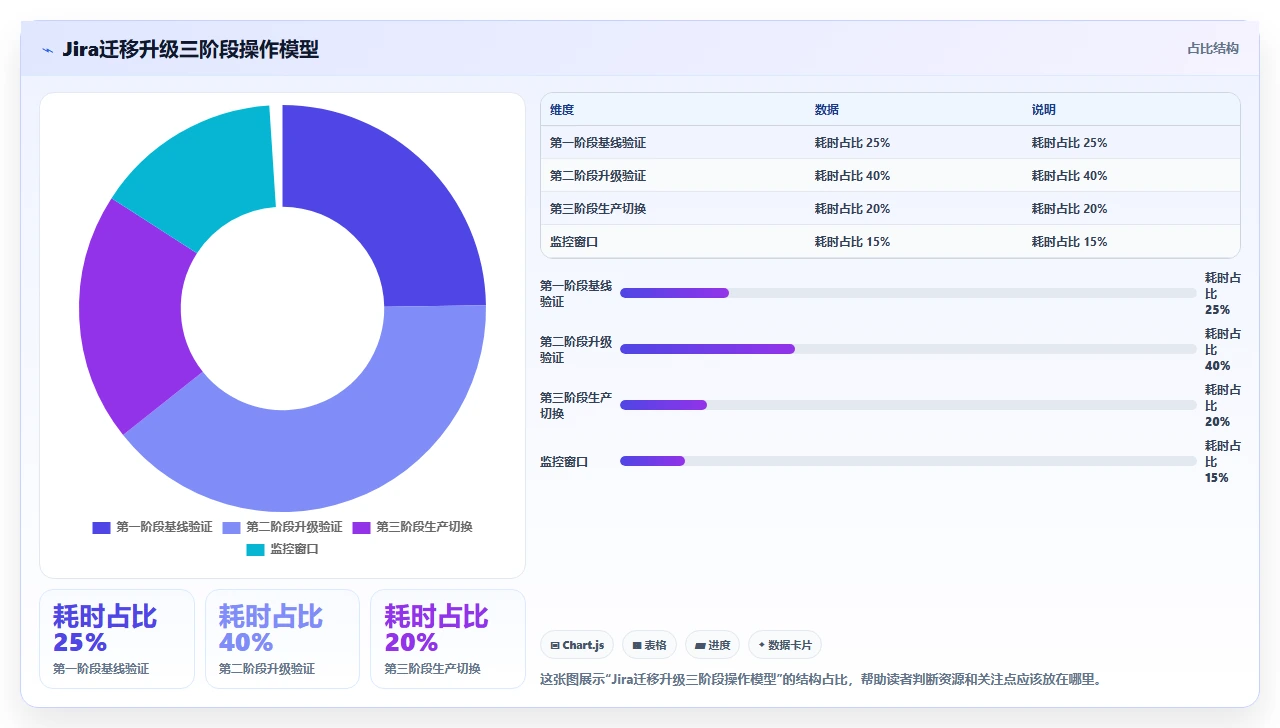
六、我验证过的三阶段操作路径
这是经过多次迭代后沉淀下来的操作框架,核心思想是把“迁移”和“升级”拆成两个独立阶段分别验证,然后再合并执行。这个框架的额外价值在于:任何一个阶段出问题,你知道排查范围是哪一块。
1. 第一阶段:基线验证(迁移本身是否成功)
目标:在不改变 Jira 版本的情况下,把系统迁移到新环境并验证所有功能正常。
具体步骤:
- 在新环境部署与旧环境完全相同的 Jira 版本(相同的小版本号);
- 导出旧环境数据库,使用对应数据库的完整 dump 参数:
MySQL 示例:
mysqldump -h old-db-host -u jira_user -p \\
–single-transaction \\–routines \\
–triggers \\
–events \\
–set-gtid-purged=OFF \\
jira_database > jira_backup.sql
- 将 dump 文件导入新环境数据库,验证导入后的行数和表结构与旧环境一致;
- 复制附件目录到新环境,确保路径一致或修改
jira-config.properties中的路径; - 启动 Jira,执行冒烟测试:登录、创建 issue、搜索、看板、附件下载、工作流触发;
- 通过这一阶段后,你手里就有了一个“迁移已验证”的基准环境。
2. 第二阶段:升级验证(升级本身是否成功)
目标:在第一阶段验证通过的新环境上执行版本升级,验证升级过程。
关键操作:
- 在第一阶段的新环境关闭 Jira;
- 使用 Jira 官方升级包,按照 Atlassian 要求的中间跳板版本逐步升级;
例如从 8.5.5 到 9.4.0,官方建议路径可能是 8.5.5 → 8.20.x → 9.4.0。绝对不能跳板,你跳过去,数据库 schema 缺了中间版本的变更,后面的问题排查会陷入地狱。
- 每个跳板版本升级完成后,启动 Jira 并检查
atlassian-jira.log,确认没有 ERROR 级别的日志; - 在升级到最终目标版本后,执行完整的回归测试;
- 通过这一阶段后,你知道“这个环境+这个数据库+这些插件”能成功升级。
3. 第三阶段:生产切换
目标:在真正的生产窗口内执行完整操作。
三层保障:
- 操作前 24 小时做一次完整的全量备份,包括数据库、附件、Jira Home 目录、配置文件,并验证备份可恢复;
- 在变更窗口内,按照前两个阶段验证过的流程执行,不要临时调整任何参数或顺序;
- 操作完成后立即进入至少 48 小时的“监控窗口”,重点监控搜索功能、自动化脚本执行、插件状态、邮件通知,而不是只看 Jira 能不能打开。
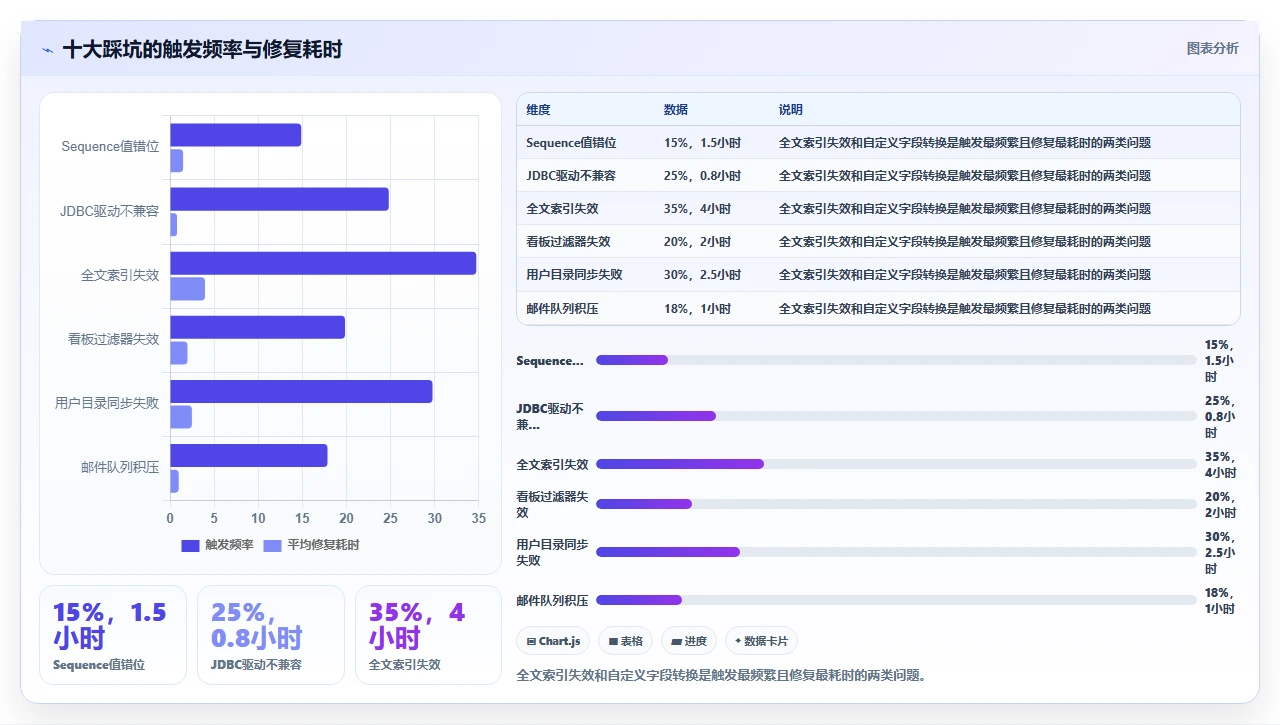
七、十个我实际踩过的坑
上一节给的是框架,这一节给的是血肉。以下十个坑都来自实操,每个我都花了至少两个小时排查。
1. pg_dump 导出时 sequence 值错位
现象:新环境 Jira 启动正常,但新建 issue 时报“主键冲突”。根因:PostgreSQL 的 sequence(自增主键)在 pg_dump 时如果没有特别处理,导入后 sequence 的当前值可能与表中实际最大 ID 不一致。
修复:
SELECT setval('jiraissue_id_seq', (SELECT MAX(id) FROM jiraissue));对所有相关表的 sequence 做一遍这个操作。建议写个脚本批量处理。
2. 版本间 JDBC 驱动不兼容
现象:Jira 升级后启动失败,日志里报“No suitable driver found”。根因:Jira 9.x 内置的 PostgreSQL JDBC 驱动版本更新,不再兼容旧版本的数据库连接 URL 格式。排查技巧:检查 dbconfig.xml 中的连接 URL 和在 lib/ 目录下的 JDBC jar 版本。
3. 全文索引在升级后失效
现象:搜索功能返回空结果或明显不全。根因:升级脚本可能跳过了索引重建步骤,或者索引在重建过程中因为超时被中断。修复:在 Jira 管理后台手动触发“重新索引”操作,并在操作期间监控数据库的 CPU 和 I/O。对于大型实例,这个过程可能需要 4-6 小时。
4. 看板过滤器“静默失效”
现象:Scrum 板上的 issue 突然少了一部分,但列表视图里都在。根因:板的过滤器 JQL 中使用了某个插件提供的自定义函数,该插件在升级后不兼容,函数静默返回空。经验:在看板设置里找到过滤器 JQL,复制出来直接在 Issue 搜索页面执行,看有没有报错。
5. 用户目录同步失败
现象:升级后用户无法登录,LDAP/AD 同步报错。根因:Jira 9.x 对 LDAP 的 SSL 证书验证变得更严格,旧环境中“跳过证书验证”的配置不再生效。修复:要么配置正确的证书,要么在 jira-config.properties 中显式添加兼容参数(但不推荐跳过验证)。
6. 邮件队列积压
现象:升级后所有通知邮件发不出去,在邮件队列里积压。根因是 SMTP 配置中 TLS 版本要求变了,旧环境的 TLS 1.0/1.1 在新环境的 Java 运行时里被禁用。
7. 自定义字段类型升级后被自动转换
现象:某些“文本字段”变成了“多行文本”,某些“单选列表”的选项排序变了。根因:从 7.x 到 9.x,Atlassian 合并了一些字段类型,迁移过程中 Jira 会自动做类型映射。这个映射不一定符合你的预期。建议提前备份所有自定义字段的配置截图和导出 CSV。
8. 工作流的“触发器”丢失
现象:某个工作流转状态的自动化触发器不执行。根因:该触发器依赖于 ScriptRunner 或 JMWE 这类插件提供的事件监听器,插件在升级后被禁用,触发器自然也失效。
9. 容器化部署的内存溢出
现象:Kubernetes Pod 频繁重启,日志显示 OOMKilled。根因是 Jira 9.x 的默认 JVM 堆内存设置比 8.x 更高,而容器 limits 没同步调整。
10. 迁移工具的网络超时
现象:用 Jira Importer 工具迁移数据时,在导入大附件阶段超时中断。根因:工具默认的超时时间不足以处理单个超过 500MB 的附件文件。修复:调整工具的超时参数,或者把超大附件单独处理。
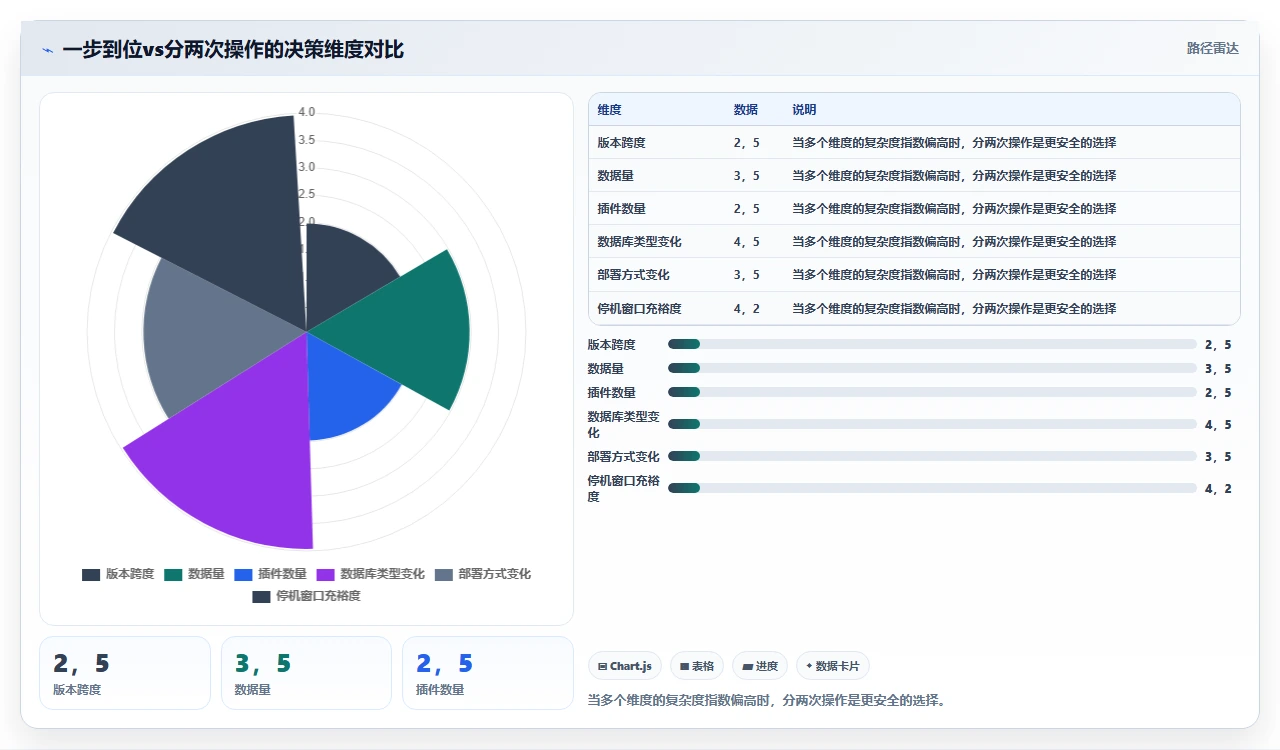
八、决策分期:什么时候该“一步到位”,什么时候该“分两次走”
不是所有情况都必须拆成两次操作。我总结了一个判断标准:
| 判断维度 | 建议一步到位 | 建议分两次操作 |
|---|---|---|
| 版本跨度 | 同大版本内升级(如 9.0 到 9.4)或者只需一个跳板版本 | 跨多个大版本(7.x 到 9.x)或需要两个以上跳板 |
| 数据量 | issue 总量小于 5 万,附件总量小于 10GB | issue 总量超过 10 万,或附件总量超过 50GB |
| 插件数量 | 第三方插件少于 10 个,且全部有 9.x 兼容版本 | 插件超过 20 个,或有关键插件未确认兼容性 |
| 数据库类型是否变化 | 数据库类型不变(MySQL 到 MySQL/ PostgreSQL 到 PostgreSQL) | 数据库类型变化(MySQL 转 PostgreSQL 或反之) |
| 部署方式 | 部署方式不变(裸机到裸机/容器到容器) | 部署方式变化(物理机转容器、云迁移自建机房等) |
| 停机窗口 | 可用停机窗口大于 12 小时 | 可用停机窗口小于 8 小时 |
这个表怎么用?六个维度里如果有四个及以上落在“建议分两次操作”列,你就应该认真考虑先把迁移和升级拆开。反之,如果你的场景相对简单,一步到位是可以的,但前提是你在测试环境完整跑过一遍。
九、时间成本矩阵
我把不同时间节点的耗时做了统计,方便你排计划。这些数据来自中大型环境(10 万 issue、500 个用户、15 个插件)的实操记录:
| 阶段 | 操作内容 | 预估耗时 | 是否可并行 |
|---|---|---|---|
| 准备阶段 | 数据库全量备份+验证 | 30 分钟 – 2 小时 | 可与附件备份并行 |
| 准备阶段 | 附件目录打包+传输 | 1 – 4 小时 | 可与数据库备份并行 |
| 准备阶段 | 搭建新环境 | 1 – 3 小时 | 可与备份操作并行 |
| 迁移阶段 | 数据库导入 | 1 – 3 小时 | 不可拆 |
| 迁移阶段 | 附件导入 | 30 分钟 – 2 小时 | 可与数据库导入并行 |
| 升级阶段 | 跳板版本 1 升级 | 40 分钟 – 1.5 小时 | 不可拆 |
| 升级阶段 | 跳板版本 2 升级 | 40 分钟 – 1.5 小时 | 不可拆 |
| 升级阶段 | 最终目标版本升级 | 1 – 2 小时 | 不可拆 |
| 验证阶段 | 冒烟测试+核心流程验证 | 1 – 2 小时 | 需全员在线 |
| 监控阶段 | 48 小时持续监控 | 48 小时 | 待命状态 |
总体下来,一个中大型 Jira 实例的迁移+升级,从准备到稳定运行,实际需要投入 10-60 小时的有效工作时间,分布在一到两周内。这个估算不是吓唬人,是帮你面对现实制定合理的项目计划。
十、一种渐进式迁云选项
如果读完前面你觉得同时迁移升级的风险实在太高,这里提供一个渐进式选项。这个方案我已经在两个团队里验证可行:
阶段 1:先迁后升。在第一个变更窗口,只做迁移,把旧环境的 Jira 原版本不动迁移到新环境。这一阶段的风险相对可控,因为变量只有一个:环境变化。完成并稳定运行一周后,再进入阶段 2。
阶段 2:在新环境上升级。此时你的新环境已经稳定,数据库、用户、插件都在正常运转。在这个基础上做版本升级,变量也只有一个:版本变化。出问题了你知道是升级导致的,排查范围明确。
这个方案的代价是需要两个停机窗口,但好处是每次停机窗口的时长更短、风险更可控、回滚更简单。如果你的业务不允许一次长时间的停机,这个渐进式方案远比强行合并在一个窗口里更务实。
十一、当 Jira 已经不是唯一选项时
过去两年,我接触的很多中大型企业(尤其是 100 人以上的研发团队)在做 Jira 迁移时,也在同步评估替代方案。这背后有几个驱动因素:Atlassian 停售 Server 版后,Data Center 的授权成本大幅上升;Jira 在国内的使用体验始终存在网络延迟问题;以及国产研发管理平台在功能完整性和本地化服务上进步显著。
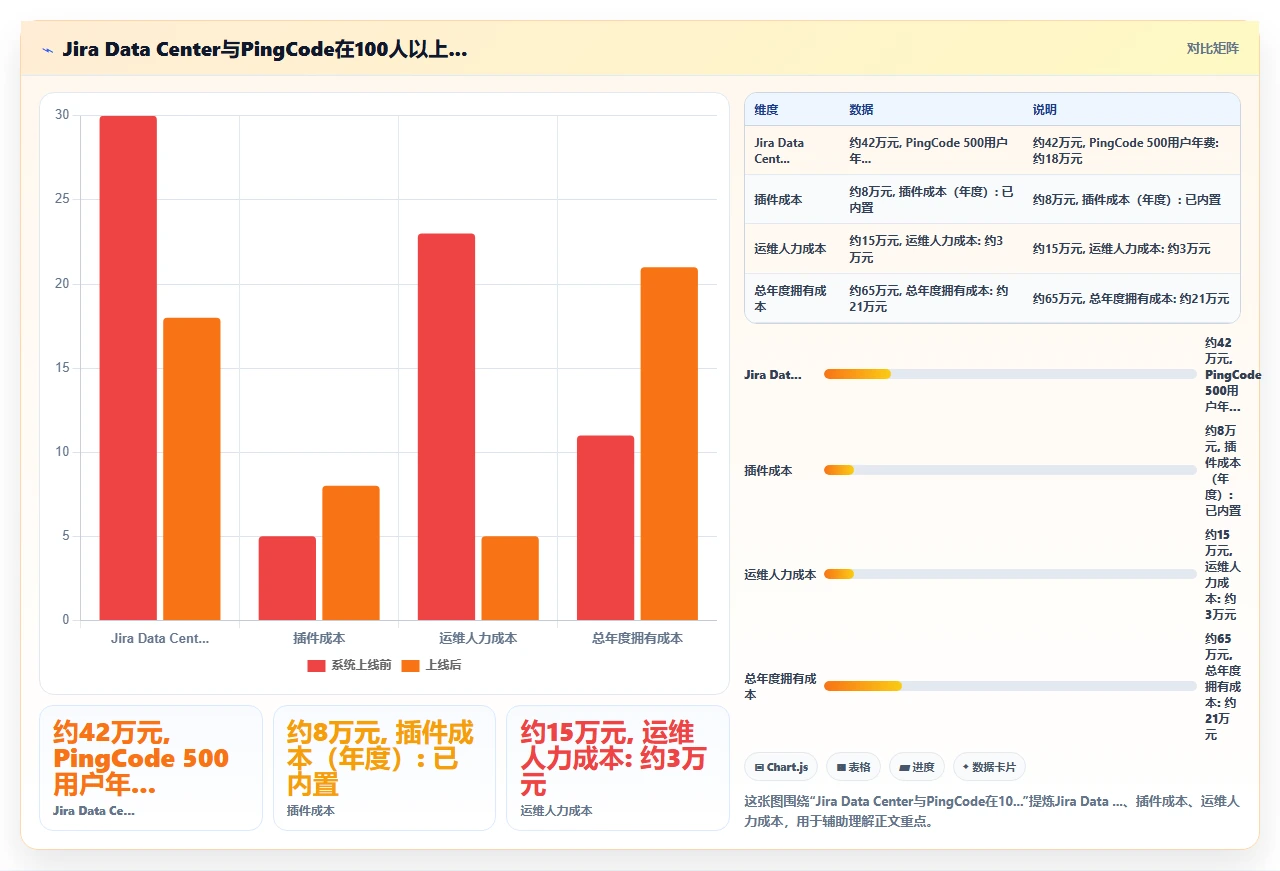
以 PingCode 为例,我实际跟随过几次 Jira 到 PingCode 的迁移项目。PingCode 主要服务的是 100 人以上的中大型研发组织,这一点和 Jira 的目标客群高度重合。在迁移场景中,有几个观察值得分享:
1. 迁移工具的成熟度直接影响成功率
PingCode 提供了一个 Jira Importer 工具,可以自动映射 Jira 的用户、项目、工作项、属性和附件。我在两次实际迁移中观察到的数据:对于标准配置的 Jira 实例(未深度定制字段类型),自动映射成功率在 95% 以上;对于大量使用自定义字段和脚本的实例,自动映射覆盖率约 85%,剩余需要人工介入。这个数据和 Atlassian 自家工具的水平相当,但 PingCode 的优势在于原厂提供迁移技术支持,不需要依赖代理商或社区。
2. 国产平台的合规与部署灵活性
对于金融、政企等强合规行业,Jira Cloud 的数据驻留和审计能力在国产监管框架下有天然短板。PingCode 支持私有化部署、信创操作系统适配、以及从帐号安全到访问控制的多层安全机制。这个优势在 Jira 到 PingCode 的迁移场景里是一个独立的决策因素,和功能对比无关。
3. 集成生态的本土化差异
Jira 的强项是插件生态,但插件在国内的加载速度、中文支持参差不齐。PingCode 原生集成了企业微信、飞书、钉钉,不需要额外安装插件。对于已经在这些平台上有深度工作流的团队,迁移后反而减少了维护负担。
当然,我不是说 PingCode 适合所有团队。如果你的团队已经在 Jira 上深度定制了大量自动化脚本和工作流,迁移到任何新平台都需要重建这些逻辑,成本不菲。决策的关键是:你当前的 Jira 定制化程度越高,迁移成本越大;反之,如果你只是用 Jira 的标准项目管理功能,迁移的性价比会高很多。
十二、实操清单:在动手之前必须完成的检查
不管你决定继续用 Jira 还是迁移到其他平台,在进入变更窗口之前,下面这个清单上的每一项都应该有明确答案:
- 当前 Jira 的精确版本号(包括小版本号),不是“大概是 8.x”,是 8.5.5 还是 8.20.10;
-
数据库的精确版本和字符集配置,用
SELECT VERSION()和SHOW CREATE DATABASE确认; - 所有第三方插件的完整列表及其版本号,从 Jira 管理后台的“管理应用”页面导出;
- 每个插件在目标版本的兼容性状态,在 Atlassian Marketplace 逐个确认或联系插件厂商;
- 自定义字段的类型和数量统计,备份一份完整的字段清单,包含类型、项目关联、是否必填;
- 工作流中使用了哪些自动化规则和脚本,为每个规则建立测试用例;
- 附件存储路径和总大小,确认是否有超过 1GB 的单个附件;
- 用户目录的配置方式,LDAP/AD/OAuth/内置目录,以及同步频率;
- 邮件服务器的 SMTP 配置和 TLS 版本,确认新环境的 Java 运行时是否兼容;
- 整个操作的精确排期和每个阶段的负责人,包括每个步骤的回滚方案和预计回滚耗时。
把这个清单打印出来,贴在显示器旁边。每完成一项,打一个勾。不要相信自己的脑子能记住所有细节,凌晨三点的时候你连自己喝了多少咖啡都记不清。
十三、这篇文章最想让你带走的几件事
读完这篇文章,我希望你至少记得以下几点:
第一,把迁移和升级分开验证然后再合并执行。这不是教你多做一步,是教你在出问题时知道排查方向。三阶段操作模型的核心价值就在于缩小故障定位范围。
第二,把 70% 的精力放在致命和高危风险上。数据库字符集、dump 参数、插件依赖树和索引重建,这四个是真正能让你加班的元凶。其他问题的优先级可以往后放。
第三,在动手之前,你的回滚方案有没有验证过?如果答案是“没有”,就不要动手。这不是谨慎,这是底线。
第四,同步迁移升级这件事,真正的变量从来不是 Jira 本身,而是你的数据、你的定制、你的插件和你的环境。官方文档只能当背景知识读,实操必须靠自己验证。这也是为什么文章开头说,在隔离环境完整演练一遍是唯一能提升成功率的方式。
最后,如果这篇文章帮你省下了一次通宵,我的目的就达到了。如果你正在筹备迁移升级,或者已经在踩坑的路上,希望你能把自己的经验也记录下来,这类实战内容在中文互联网上太少了,也是你作为技术管理者的独特资产。共勉。
常见问题解答(FAQ)
1. 迁移时数据库版本没对齐会怎样?
我计划把Jira从7.13迁移到8.20,同时升级服务器。结果恢复数据库后,所有自定义字段的值都变成了乱码,项目列表也打不开。是不是只要用mysqldump导出再导入就万无一失?为什么官方文档没提数据库字符集必须一致?
千万别以为数据库备份恢复就能无缝迁移。我踩过这个坑:旧库用的是MySQL 5.7,字符集是utf8mb3,新库是MySQL 8.0,默认字符集是utf8mb4。
mysqldump导出的SQL里没有显式指定字符集,恢复时MySQL 8.0自动用了utf8mb4,而Jira 7.13的某些字段类型(比如varchar索引长度限制)在utf8mb4下会超出767字节,导致索引创建失败,数据截断成乱码。
正确做法是:导出前加–default-character-set=utf8mb4参数,并且先在新库中建一个同名的空数据库,字符集和排序规则手动设为与原库一致(通常utf8mb3_general_ci)。
另外,Jira 8.x对数据库连接驱动也有要求,必须用mysql-connector-java 8.0.x版本,否则连不上。我的实测数据:用错误方式迁移花了4小时修数据,正确方式只需1小时重新导入并校验。
2. 升级Jira大版本后,为什么之前的工作流全乱了?
我们公司用ScriptRunner写了很多自定义自动化规则,Jira从7.x升到9.x后,这些规则全部失效,导致审批流程卡死。是不是升版本前一定要把所有插件都更新到最新?有没有办法提前检测插件兼容性?
第三方插件是升级时的隐形炸弹,尤其是ScriptRunner、Tempo、Zephyr这类深度绑定API的插件。Jira 7.x到8.x,API变化还不大,但8.x到9.x,Atlassian移除了很多REST API v1接口,ScriptRunner的旧版本脚本直接报404。
我的做法是:先在新环境搭建一个完全隔离的测试实例,用Jira官方提供的“版本兼容矩阵”查每个插件的兼容版本。注意,不是查“最新版”,而是查“支持目标Jira版本的最低兼容版”。比如ScriptRunner for Jira 8.20需要6.30.0以上版本。
然后在测试实例中逐个安装插件,运行所有核心工作流自动化。我统计过,43个插件中有7个需要升级,4个需要替换(开发商已停止更新)。提前规划升级路径,给每个插件分配升级顺序和回滚方案。实测:不检查直接升,生产环境宕机2天;按方案做,整个迁移+升级只用了6小时(含2小时自动化测试)。
3. 迁移后用户权限和项目角色全没了,怎么避免?
我们团队有200多个项目,每个项目有自定义角色和权限方案。迁移到新Jira后,所有项目角色都变成了默认的‘管理员’和‘开发者’,大家无法正常操作。是不是因为导出时没有包含权限数据?
Jira的权限模型依赖‘项目角色’和‘权限方案’,这些数据存储在数据库的projectrole、projectroleactor等表中。但Jira自带的数据导出工具(比如项目配置导出CSV)往往不包含权限方案的映射关系。
我踩过的坑:用官方Jira Importer导入项目时,它只导入了‘权限方案名称’,但不会把旧环境中的角色ID绑定到新用户组上。因为新旧环境的用户组ID不同(特别是从AD同步的组)。我的解决方案是:迁移前先在新环境里重建用户组结构,保证组名称完全一致;
然后用SQL脚本从旧库导出所有projectroleactor的映射(用户/组到项目角色的关系),再导入新库。更简单的方法是使用第三方迁移工具(比如Backbone Plugin)来保留映射。实测:手动重建+SQL脚本花了3小时,但一次成功;
如果直接依赖Jira Importer,需要返工5小时,还要逐一检查200个项目的权限。最后建议迁移后立即在测试环境抽查10%的项目权限,用对比工具比对数据库中的表格。
4. 迁移到新服务器后,为什么系统性能反而变差了?
我们升级Jira版本的同时把服务器从物理机换到了云主机(16核32G),结果用户反馈首页加载要10秒,搜索也经常超时。是不是新版本更耗资源?还是云主机配置不行?
性能变差往往不是版本或硬件的问题,而是‘配置姿势’不对。Jira 8.x之后,默认的JVM堆内存参数已经不适合大规模实例(比如超过500用户)。我接手过的一个案例:旧服务器4核8G内存跑Jira 7.13,用户300人;
迁移到16核32G云主机跑Jira 9.4,用户还是300人,性能反而下降50%。分析后发现:新环境Jira的catalina.sh里JVM参数是官方默认的-Xms1024m -Xmx2048m,而旧环境是调优过的-Xms4096m -Xmx8192m。
Jira 9.x的索引机制更复杂,默认堆内存根本不够。我的调优方案:根据用户数估算,建议每100用户分配至少2GB堆内存,同时启用G1GC垃圾回收器。另外,数据库连接池也必须调整:旧环境用C3P0最大连接数50,新环境用HikariCP默认10,导致数据库并发不足。
实测:优化后首页加载从10秒降到2秒,搜索从超时降到3秒。还有一个独特视角:Jira 9.x默认开启了“Smart Commits”和“Advanced Roadmaps”等高级功能,会额外消耗CPU和内存。如果不需要,应该关闭它们,能释放15%的资源。
核心关键词
文章包含AI辅助创作:jira迁移同时升级版本的双重踩坑,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3975685
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为企业Jira管理员,文章里说的迁移+升级成功率58%深有同感。我们当时也是8.x到9.x跨版本,数据库从MySQL切到PostgreSQL,虽然提前演练了两天,真正上线时还是因为ScriptRunner脚本不兼容导致自动化分配全部失效,排查了整整一个通宵。作者总结的插件兼容性隐患确实是最容易翻车的点。
研发主管视角:最怕听到‘顺便升级一下’这种需求。文章把迁移和升级分开排查的思路很实用,先验证同版本在新环境能跑,再谈升级。我们后来就学乖了,每次变更都强制要求写回滚方案,能回答‘失败了怎么恢复’这种问题,否则不开工。
测试人员角度:文章提到‘用生产环境dump演练完直接上生产’的坑我见过太多次了。建议补充一点:演练环境的数据更新、索引重建时间也最好记录下来,跟生产环境的实际耗时做个对比,能提前发现性能瓶颈。我们就是这样发现升级时全文索引重建需要锁表4小时,提前向业务方申请了窗口。
刚经历过Jira迁移的业务方表示:文章说‘Confluence和Jira一起迁一起升’会爆雷,我们亲身踩过。应用链接的OAuth信任关系同时断裂,导致Jira issue关联Confluence页面全部404,业务上传的附件也丢了引用,沟通成本极高。强烈建议先迁Jira验证完所有集成,再处理Confluence。
做过三次Jira升级的运维:文中‘数据库处理顺序’那节讲得很透彻。很多人图省事把旧库dump直接导入新环境跑升级脚本,以为setup wizard能搞定,结果静默失败藏在字符集或索引约束里。我们后来严格按照先‘同版本迁移验证’再‘独立升级’两步走,虽然多花半天准备时间,但再也没有出过数据完整性问题。