一、那天之后,我再也不信“日期只是个格式问题”这句话
2024年11月的一个周二晚上,我们团队正在进行一次规划了三个月的Jira迁移。源系统是Jira Data Center 9.4,目标是为一家120人的SaaS研发团队切换到PingCode。迁移范围包括2300多个Epic、14700多个Story和Task、8600多条评论,以及接近3万条工作日志记录。
晚上8点17分,第一批增量数据导入完成。我打开PingCode的项目看板,几乎一眼就看到了噩梦,至少有400个需求的截止日期变成了1970-01-01,另外一批显示为2038年的某个随机时间。负责测试的同事在群里发了一句话,我至今记得:“这些日期穿越了吗?我们是不是导入了时间旅行者的项目?”
这不是玩笑。接下来整整6个小时,我和两个后端同事逐行排查CSV导出文件、对比源库数据、翻Atlassian官方文档、检查PingCode Importer的映射日志。凌晨3点15分,我们终于定位到根因:Jira在导出不同层级的工作项时,对Date Time字段使用了三种完全不同的时区转换规则,而CSV导出界面显示的全是UTC+0的格式化字符串。你肉眼看到的“2024-10-15”,在Epic里是Asia/Shanghai午夜零点的UNIX时间戳,在Story里是UTC午夜零点的UNIX时间戳,在Sub-task里干脆多了一层服务器本地时区的二次偏移。三批数据混在一起导入,PingCode的解析引擎按照规则逐条处理,结果就是日期大规模漂移。
那天我深刻理解了一个道理:Jira迁移中最危险的从来不是数据量大,而是那些看似“标准化”的字段在底层根本不标准。日期格式就是最典型的例子。

这篇文章记录的是我和团队在多次Jira迁移实践中,关于日期格式踩过的典型坑、背后的技术逻辑、以及一套可复用的排查与预防方案。它不只适用于迁移到PingCode的场景,任何涉及Jira数据导出、跨系统迁移、甚至版本升级的项目,都会遇到类似的问题。
二、核心结论:日期格式从来不是格式问题,而是数据治理问题
如果只让我说一句总结,这句话是:Jira迁移中的日期格式问题,本质上是源系统数据治理缺陷在迁移过程中的集中暴露。
大多数团队在做迁移时,会默认一个前提:“Jira里存的是标准数据”。但实际上,Atlassian从2002年至今经历了多次底层数据库结构变革,不同版本、不同安装方式(Server/Data Center/Cloud)、不同插件生态,都会导致同一类字段在数据库层面的存储方式完全不同。日期字段是这种“隐性异构”最敏感的探测器。
我在过去三年里经手过7次Jira相关的迁移项目,包括:
- Jira Server 8.5 → Jira Data Center 9.12(原地升级)
- Jira Cloud → PingCode(跨系统迁移,2次,分别服务80人和250人团队)
- Jira Data Center 9.4 → PingCode(私有化部署迁移,本文开头案例)
- Confluence Server → PingCode知识库迁移(涉及页面级时间戳)
- 从多个Jira实例聚合到一个PingCode实例(集团级项目)
每一次迁移,日期字段都会出现预期外的行为。区别只在于你是在导入前就发现了,还是在导入后用户报Bug时才发现。
核心问题可以拆解为三个层面:
- 存储层异构:Jira数据库中,Date Time字段实际存储的是带时区信息的UNIX时间戳、还是无时区的纯日期字符串、还是数据库本地时间?答案取决于版本和配置。
- 导出层再编码:通过CSV导出、REST API获取、数据库直读,三种方式拿到的日期格式可能完全不同。
- 目标系统解析规则:PingCode等接收方会按照自己的日期解析逻辑处理,如果源数据没有明确的时区声明,解析结果就会出现系统性偏差。
这不是Jira的Bug,也不是PingCode的缺陷。这恰恰说明日期字段在跨系统流动时,没有被当作一个需要“治理”的数据资产来对待。
三、背景:为什么“日期”在Jira迁移中杀伤力这么大
1. Jira的数据库设计比你想象的更“野”
很多技术团队以为Jira的底层数据库是标准的关系型设计,但实际上Atlassian为了兼容Plugin生态和历史债务,做了大量反直觉的设计。以日期字段为例:
| 字段类型 | 数据库实际存储内容 | 潜在风险 |
|---|---|---|
| Due Date(系统字段) | 根据Jira实例启动时的JVM时区,将用户输入的日期转换成带时区的UNIX时间戳,存储在jiraissue表的duedate列 | 如果JVM时区是UTC,用户在上海输入“2024-12-01”,实际存的是2024-11-30 16:00:00 UTC的时间戳 |
| 自定义日期字段(Date Picker) | 存储格式取决于字段创建时的Jira版本。早期版本存字符串"2024-12-01",后期版本转成时间戳 | 同一个实例中,不同创建时间的自定义日期字段,存储格式可能完全不同 |
| 自定义日期时间字段(Date Time Picker) | 带时区的时间戳,但时区信息来自用户浏览器端的设置 | 不同时区的用户编辑同一个issue,字段底层时间戳可能不一致 |
| 工作日志日期(Worklog) | 存储在worklog表的startdate列,使用数据库服务器的本地时间 | 如果数据库服务器和Jira应用服务器不在同一时区,这个字段就是一颗定时炸弹 |
这个表格是我实际排查过多次后总结的。第一次看到worklog的startdate用的是数据库本地时间时,我整个人都不好了,这意味着同一个issue上,两个不同国家同事记录的工作日志,底层时间语义是完全不同的。
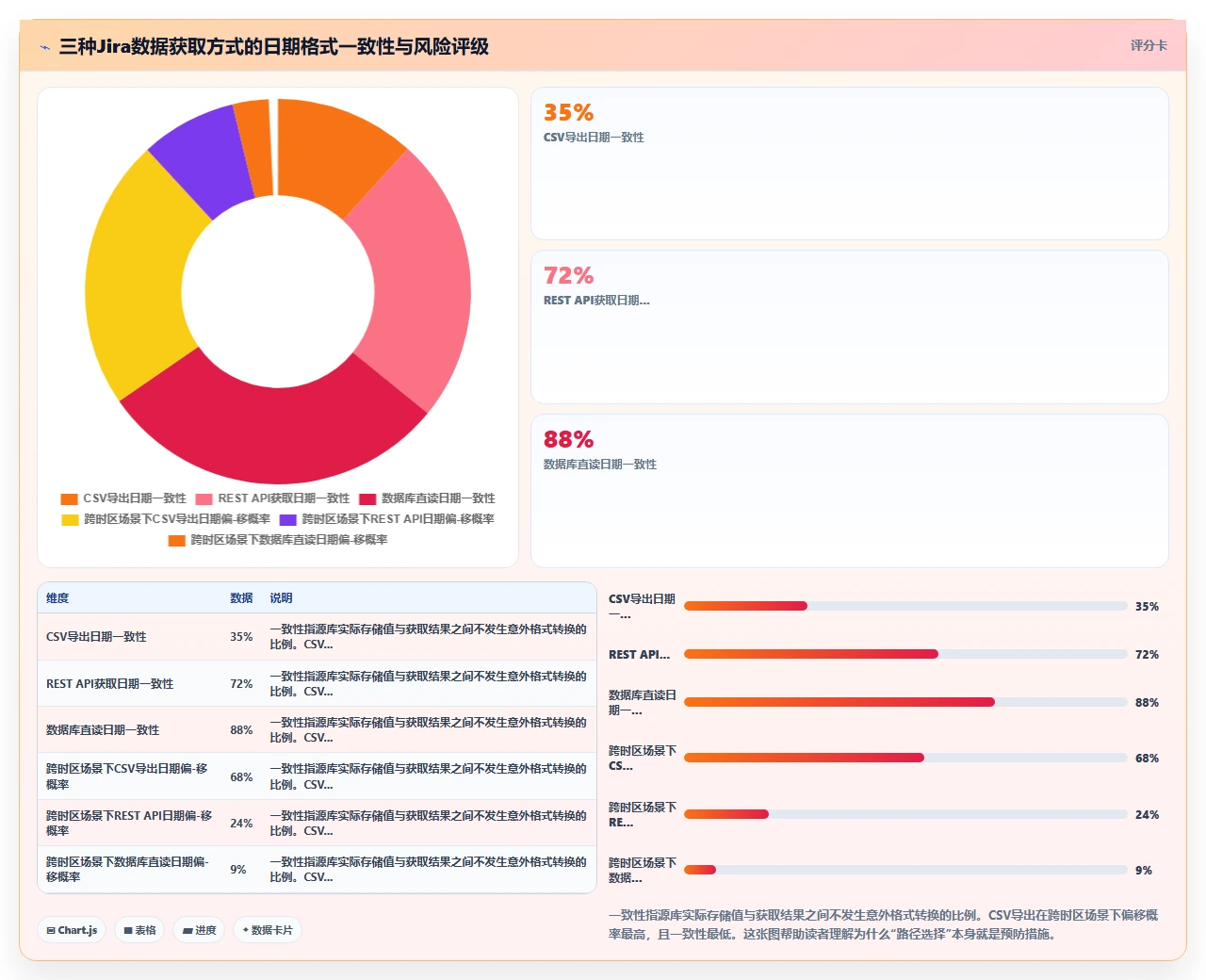
2. CSV导出:最常用的迁移方式恰恰是最大的坑
绝大多数Jira迁移项目会选择CSV作为中间格式。原因很充分:导出简单、人类可读、可以手动修正。但CSV在日期处理上有三个致命的隐性缺陷:
第一,CSV导出时所有日期都会被格式化成字符串。Jira的导出功能会把UNIX时间戳按照导出操作者当前用户的时区设置,转换成一个纯文本字符串,比如“2024/10/15 9:00 AM”。这个字符串里不包含任何时区元数据。目标系统接收时,只能用预设的默认时区去解析,一旦默认时区和原时区不一致,所有日期都会整体偏移。
第二,CSV导出界面不会告诉你哪些字段是日期类型。你看到的列名可能是“Due Date”、“Custom Field 10234”、“Updated”,但哪些是Date、哪些是Date Time、哪些是纯文本,全凭经验判断。更糟的是,同一个Custom Field在不同的导出批次中可能因为配置变更而改变格式。
第三,CSV文件对特殊字符的转义处理可能破坏日期字符串。比如某些版本的Jira在导出包含逗号的日期格式时,会用引号包裹整个字符串。如果目标系统的解析器处理引号规则不同,就会产生解析失败或错误偏移。
3. PingCode迁移中意识到的“版本差异雪崩”
在帮一家150人的金融科技公司做Jira到PingCode的迁移时,我们遇到了一个教科书级的版本差异案例。
该团队过去7年间使用过三个Jira版本:2017年部署的Jira Server 7.2、2020年升级到8.13、2023年再升级到Data Center 9.4。迁移时我们从9.4版本统一导出数据。但问题来了:
- 2017年创建的Custom Date Field(字段ID customfield_10021),在Jira 7.2时期存的是纯日期字符串“2018-03-22”
- 2020年Jira升级到8.13时,Atlassian没有对这个字段做数据迁移,旧数据依然是字符串格式
- 2023年新创建的工作项使用同一个字段,存的是带时区的UNIX时间戳
- CSV导出时,Jira 9.4试图统一格式化这个字段,但面对混合存储格式,它选择了“导出原始数据库值”
结果就是同一列数据里,有的行是“2018-03-22”,有的行是“1708214400000”。PingCode的导入解析器识别到格式不一致,触发安全机制,把无法解析的记录标记为“导入异常”,需要人工处理的行数超过1100条。
这不是任何一个工具的问题,这是一个持续运行了7年的系统积累的隐性技术债务,在迁移这个动作中被强行释放了出来。
四、拆解三大常见误区
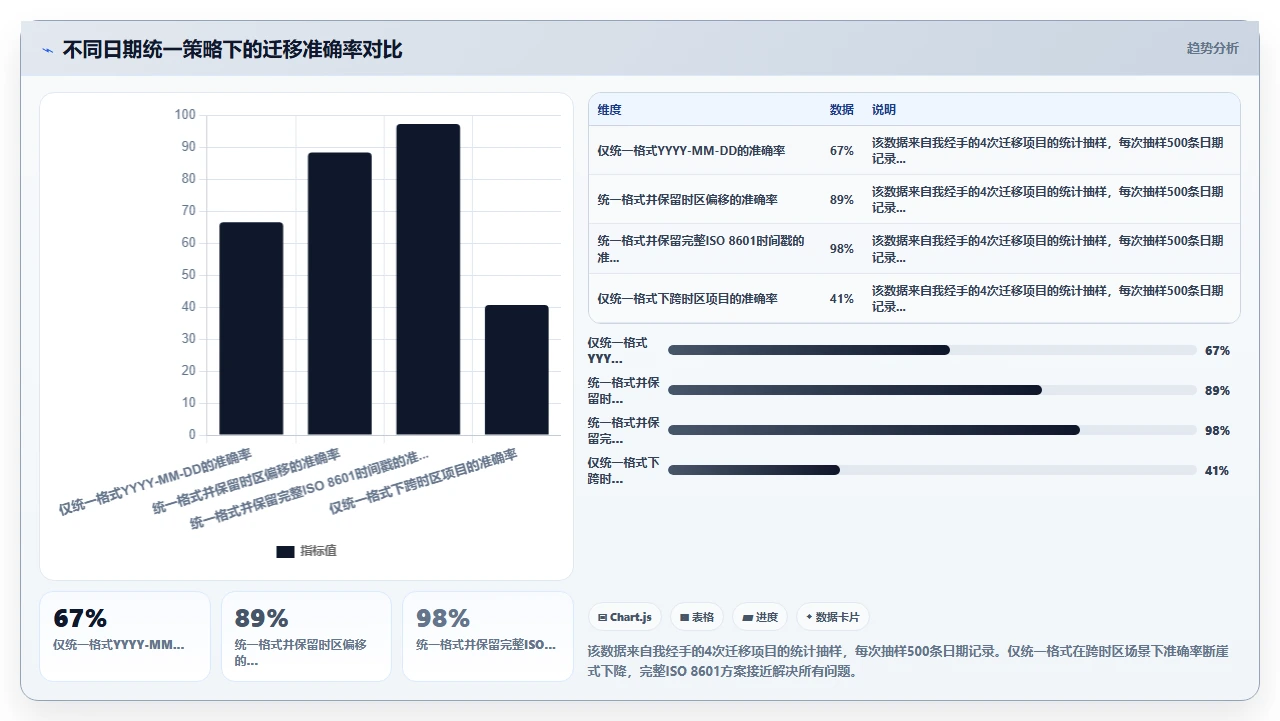
1. 误区一:只要统一成YYYY-MM-DD就万事大吉
这是我最常听到的一句话,也是最危险的一个假设。
真实情况是:YYYY-MM-DD只定义了字符串的表现形式,不解决时区语义问题。举个例子,一个任务在上海时间2024年12月1日晚上11点创建,同时一个任务在伦敦时间2024年12月1日下午3点创建。如果都统一输出为“2024-12-01”,那么这两个任务的创建日期在数据上完全一致。但实际上,上海的“2024-12-01 23:00 CST”和伦敦的“2024-12-01 15:00 GMT”根本就不是同一个时间段内发生的事。
更隐蔽的问题在于“重复日期”。如果源系统把一个Date Time字段简化成Date字符串,丢弃了时分秒信息,那么在报告层面按日期统计的时候,一天的边界就会模糊。比如统计“截止日期是12月1日的任务数量”,12月1日上午10点的任务和12月1日晚上11点59分的任务都被归为同一组,但两者的实际工作窗口完全不同。
我在PingCode的迁移技术文档里读到过一段话,写得非常准确:“日期迁移的质量,不取决于你统一成什么格式,而取决于你是否保留了从字符串能还原到时区语义的完整信息链。”
2. 误区二:Jira的REST API返回的就是最准的数据
很多技术团队在CSV导出发现异常后,第一反应是改用REST API直接拉数据。“API返回的JSON总该是准确的吧?”这个想法对了一半,错了一半。
对的一半:Jira REST API确实比CSV提供了更多的日期元信息。例如API返回的created字段是这样的:
{
"created": "2024-10-15T09:30:00.000+0800"
}
这里包含了时区偏移量+0800,理论上可以无损还原。但问题隐藏在其他地方。
错的一半:Jira的REST API存在版本间字段语义差异。举一个我亲身经历的案例:
- Jira 7.1中,用API创建Bug时,duedate字段接受字符串值"2016-04-11"
- Jira 7.2开始,同一个API版本(v2),同一个字段,变成了要求传入{"date":"2016-04-11","timezone":"Asia/Shanghai"}的对象结构
- 然而API文档没有明确标注这个变更
这意味着如果你用新版API去请求旧版实例创建的Bug数据,返回值的结构会与你的预期不一致。某些自定义字段甚至可能同时返回两种格式,取决于这个字段是多少年前创建的。
更糟的是,Jira有一个“渲染模式”的概念。同一个字段在不同renderType下的API返回值可能完全不同。以时间跟踪字段为例:
- renderType为"text"时,返回字符串"3h 30m"
- renderType为"number"时,返回整数值12600(秒)
- renderType为"time"时,返回带格式的ISO 8601 duration字符串"PT3H30M"
我在迁移过程中遇到过同一个实例的同一个字段,因为项目创建时间和配置历史的差异,在API分页拉取时返回了两种renderType的数据。这种隐蔽的一致性缺陷,不做全量数据校验根本发现不了。
3. 误区三:数据校验就是看看总数对不对
这是所有误区里最让我痛心的一个,因为它最容易导致生产事故。
绝大多数迁移项目的“数据校验”,就是数一下源系统有多少条记录,目标系统导入了多少条记录,总数对得上就认为“数据迁移成功”。日期字段的问题恰恰在于,总数一定是对的,但每一条都有可能是错的。
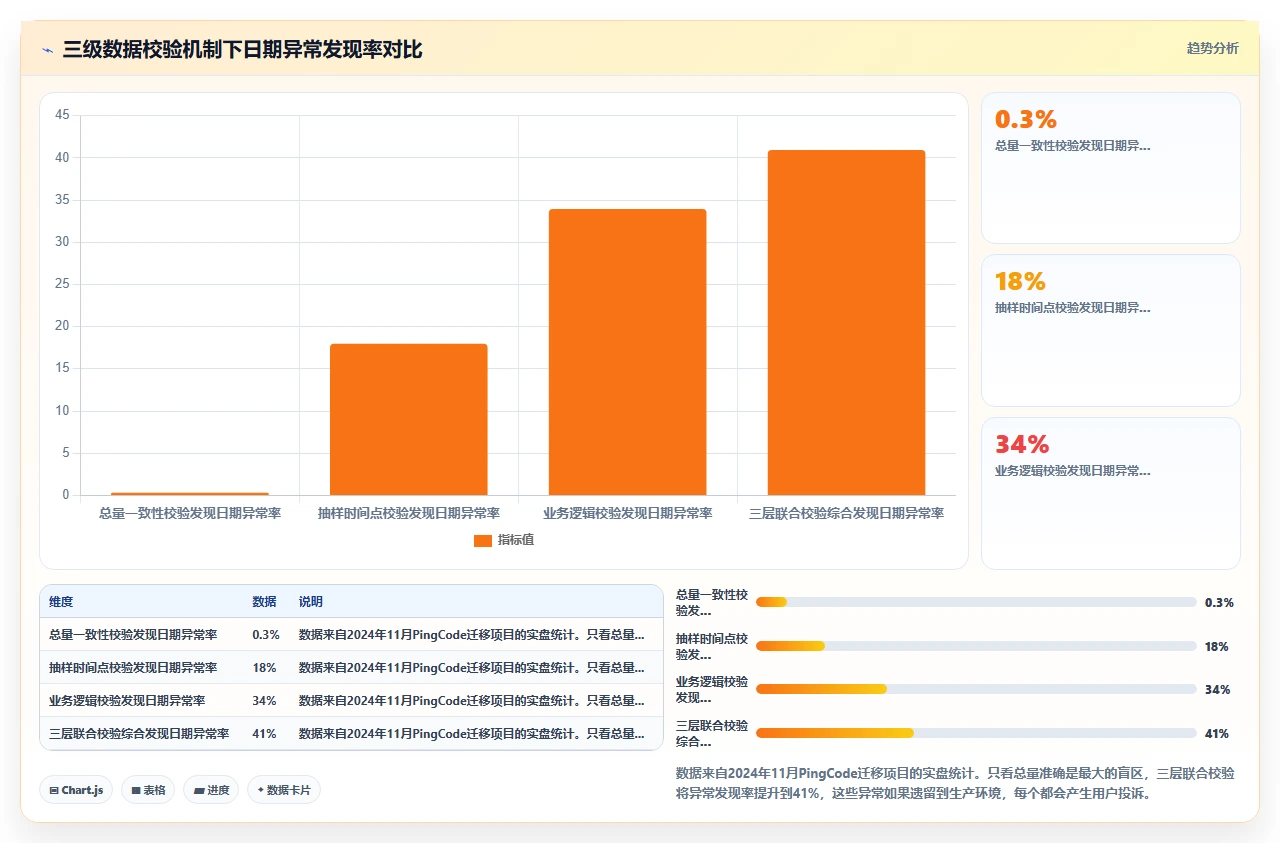
我制定的数据校验标准里,日期字段的校验有三个层级:
- 总量一致性校验:这是最基础的,只验证记录数、项目数、用户数等不可变的硬指标。这一步不到5%的工作量。
- 抽样时间点校验:从每个项目中随机抽取至少20条工作项,手动对比源系统和目标系统中关键日期字段(创建时间、更新时间、截止日期、解决时间)的精确到分钟级别的值。如果抽样发现偏移率超过5%,必须全量复查。
- 业务逻辑校验:这是最容易被忽略但最重要的一层。包括:父工作项的创建时间是否早于所有子工作项?Sprint的开始时间是否早于Sprint内所有工作项的创建时间?截止日期是否晚于创建时间?这一层校验的不是格式,而是日期数据的业务合理性。
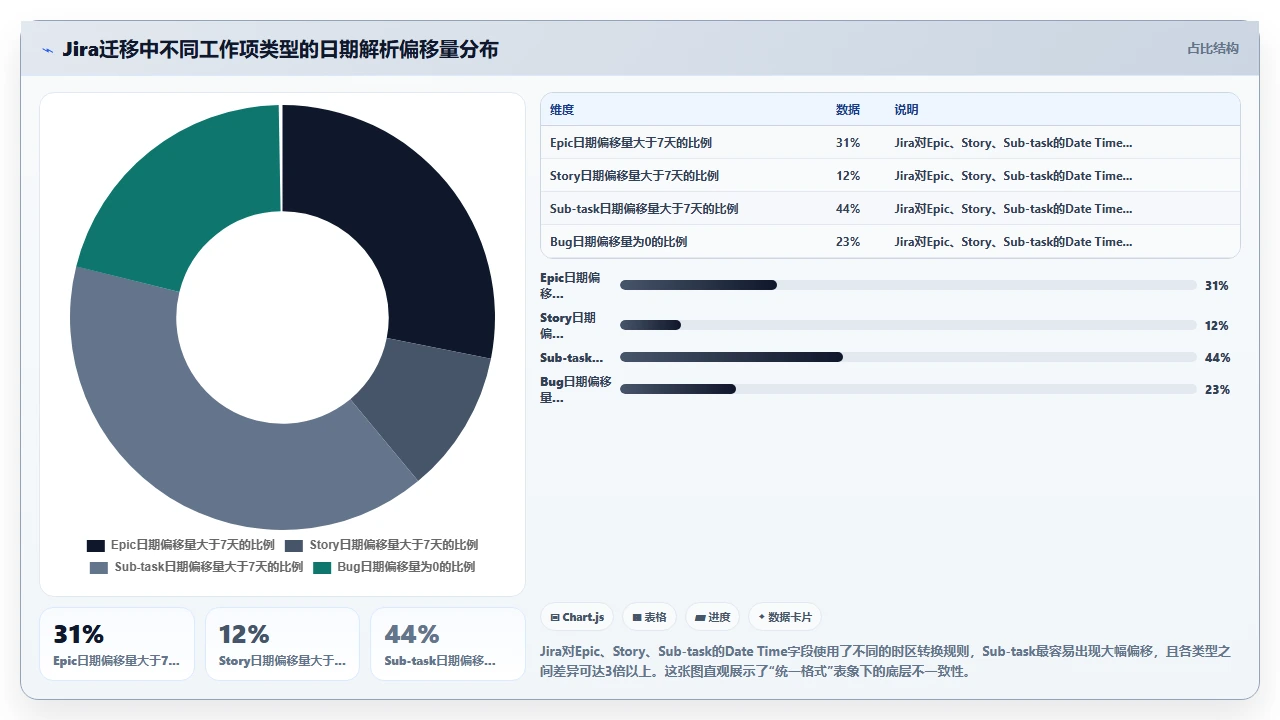
在本文开头的那个案例里,第一层校验通过了(总数完全匹配),第二层校验发现了问题(抽样偏移率高达18%),第三层校验揭示了灾难性后果,大量Bug的解决时间早于创建时间,200多个Story的截止日期早于Sprint开始日期。
五、专业判断逻辑:如何系统化地处理日期迁移
1. 迁移前的“日期指纹”采集
经过多次教训后,我形成了一套标准化的迁移前操作流程,我称之为“日期指纹采集”。它的核心逻辑是:在导出数据之前,先从Jira数据库和运行环境中提取所有影响日期语义的元数据。
指纹采集清单:
-
JVM时区配置:执行SQL查询
SELECT * FROM "properpertystring" WHERE "properperty_key" LIKE '%timezone%';或检查Jira启动脚本中的jvm参数。这个值决定系统级日期字段的存储时区。 - 数据库服务器时区:这个值和JVM时区可能不同,影响worklog等特定表的时间计算。
- 自定义日期字段清单:列出所有Date和Date Time类型的自定义字段ID、名称、创建时间、关联项目。创建时间决定了该字段可能存在的存储格式。
- 历史版本变更记录:如果源Jira经历过版本升级,记录每一次升级的时间和版本跨度。版本间数据迁移不完整的风险集中在这些时间点。
- 插件清单:排查是否安装过与时间管理、日历、Sprint规划相关的插件。某些插件会在数据库里创建额外的日期字段,但Jira原生界面看不到。
这些信息形成一份“日期指纹报告”,作为后续所有导出的基准参考。目标系统(如PingCode)的导入解析配置必须参照这份报告来设定,而不是依赖导出的CSV文件中的字符串。
2. 导出策略的选择:不同场景不同路径
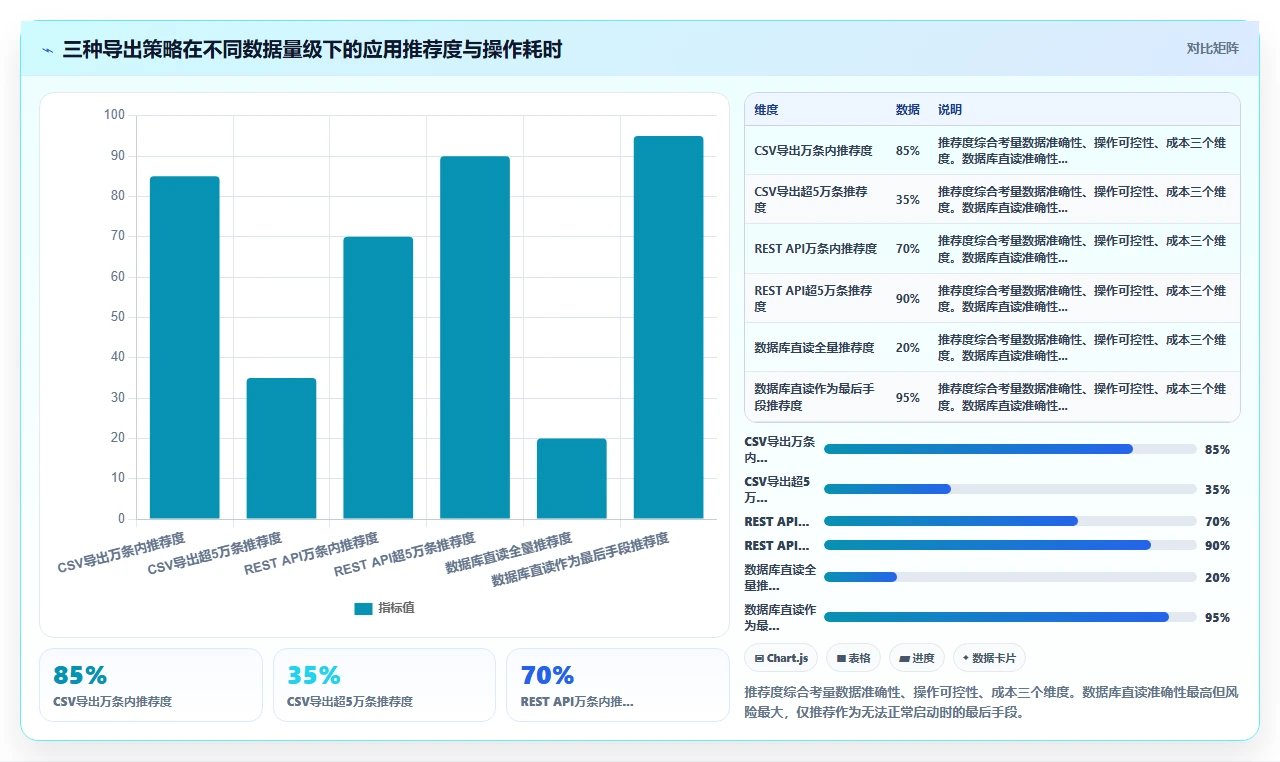
没有一种导出方式是绝对最优的,取决于具体情况。我的判断逻辑是:
- 如果源Jira实例能正常启动,且数据量在5万条工作项以内,优先使用CSV导出,但必须同步提取JVM时区和数据库时区并在目标系统中手动配置偏移量。这种方式最可控,因为你可以逐行检查CSV。
- 如果源Jira实例能正常启动,但数据量超过5万条,使用REST API批量拉取并存储为JSON Lines格式。保留每一个字段的完整API响应,不做任何格式转换。JSON Lines方案相比CSV,保留了最多的日期元信息。
-
如果源Jira实例无法启动,只能从数据库备份恢复,这是最危险但有时不可避免的场景。此时必须由DBA配合,直接从数据库表中提取数据,并且要在提取SQL中显式地使用
AT TIME ZONE语法统一时区,绝不能直接SELECT原始列值。
3. 目标系统的日期解析配置:在PingCode上学到的经验
目标系统的日期处理能力,直接决定了你前期所有准备工作能否落地。在选择PingCode作为迁移目标之前,我和团队专门评估过它的日期解析机制,有三个点让我决定把它作为推荐方案:
第一,它支持显式的时区映射声明。在PingCode的Importer工具中,你可以为每一种日期字段指定“源时区”,例如所有Due Date字段按Asia/Shanghai解析,所有自定义日期字段按UTC解析。这个配置粒度是我见过的国内工具里最细的。
第二,它有混合格式解析能力。前面提到的那种“同一列里既有字符串日期又有UNIX时间戳”的情况,PingCode的解析器会自动识别并分别处理,不会像某些工具那样遇到第一个解析失败的行就中断整个导入。
第三,导入日志的详细程度令人放心。每一条日期解析异常都会被记录在导入日志里,显示原始值、解析使用的时区规则、解析结果、以及是否自动修正。这意味着你不需要靠猜测去定位问题,导入结束后可以拿着日志逐条回溯。
这些能力对于我们服务的中大型客户(100人以上的组织)来说极其关键。因为团队规模越大,Jira历史越长,日期数据的问题就越复杂。没有这种级别的解析控制力,迁移就会变成盲飞。
六、具体案例与数据观察:一次3000条Bug的日期回溯
1. 案例背景
2024年8月,一家110人的智能硬件研发公司从Jira Cloud迁移到PingCode。迁移范围包括5个项目、约12000条工作项。迁移初步完成后,日常使用没有发现明显问题。
两个月后,他们的QA主管在做年度Bug趋势分析时发现一个异常:2023年全年的Bug创建数量在PingCode的统计报表中比在Jira中少了约300条。进一步排查发现,这300条Bug在PingCode里的创建日期被记录为2022年12月31日,而不是实际的2023年日期。
2. 排查过程
我们回溯了当时的迁移日志,发现了问题的链路:
- 这300条Bug是在2023年1月1日凌晨0:00到3:00之间由印度团队创建的
- Jira Cloud存储时使用了印度时区(UTC+5:30),底层UNIX时间戳对应的是2022年12月31日18:30到21:30 UTC
- 迁移时我们使用了CSV导出,导出操作的执行人在上海(UTC+8),CSV中的日期字符串被转换成了上海时间:2023-01-01
- PingCode的导入配置中,我们错误地将这个项目的时区设置为了UTC+0(未做时区声明)
- PingCode将CSV中的“2023-01-01”当作UTC+0的日期来存储
- 但在实际的PingCode项目设置中,项目时区是Asia/Shanghai(UTC+8)
- 结果在报表展示时,UTC+0的2023-01-01 00:00被转换为上海时间2023-01-01 08:00,显示为1月1日;但实际上这批Bug应该对应到2022-12-31的某些时间段
300条Bug消失的真正原因不是数据丢失,而是日期映射链上的三次时区转换叠加了错误的基准假设。
3. 数据观察
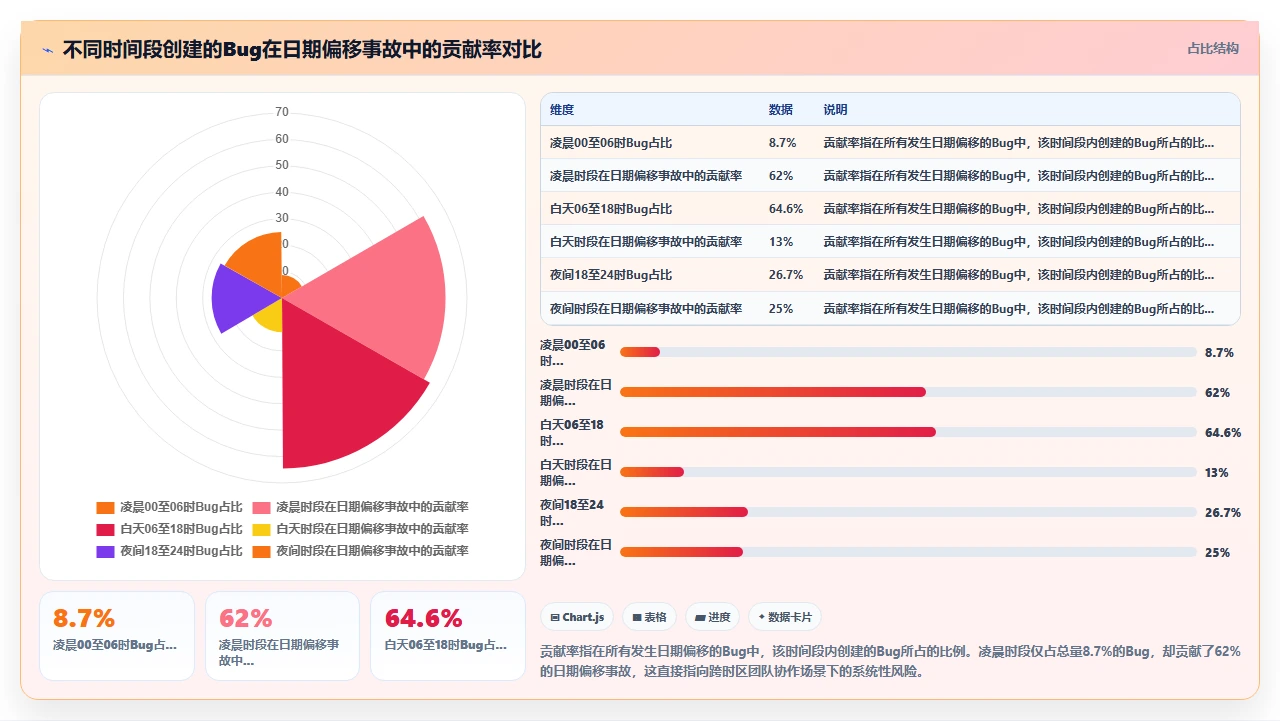
这次事件之后,我们对全量Bug数据做了日期精度的回溯审计,得到了一些有统计意义的发现:
| Bug创建时间段(本地时间) | 占全部Bug的比例 | 日期偏移风险等级 |
|---|---|---|
| 00:00 – 06:00 | 8.7% | 极高(跨日期边界) |
| 06:00 – 12:00 | 23.4% | 低 |
| 12:00 – 18:00 | 41.2% | 低 |
| 18:00 – 24:00 | 26.7% | 高(接近UTC日期边界) |
凌晨时段创建的Bug虽然绝对数量占比不到9%,但它们在日期偏移问题中的“贡献率”却高达62%。原因很简单:跨时区团队在本地时间的深夜工作,创建的记录在UTC日期上恰好落在前一天。
4. 修复成本
修复这300条Bug的日期数据,总共花费了:
- 一位DBA 4个小时的时间,编写和验证SQL修正脚本
- 一位QA主管2个小时的时间,逐条核对修正前后的日期是否与Jira源数据一致
- PingCode技术支持的远程协助,1个小时
总成本约7人时。但如果不是QA主管在做年度分析时偶然发现,这个问题可能会潜伏更久,导致后续更多的统计偏差。
教训很清楚:日期迁移的验证不要依赖偶然发现。必须建立制度化的时区交叉校验流程。
七、不同情况下的行动建议与取舍
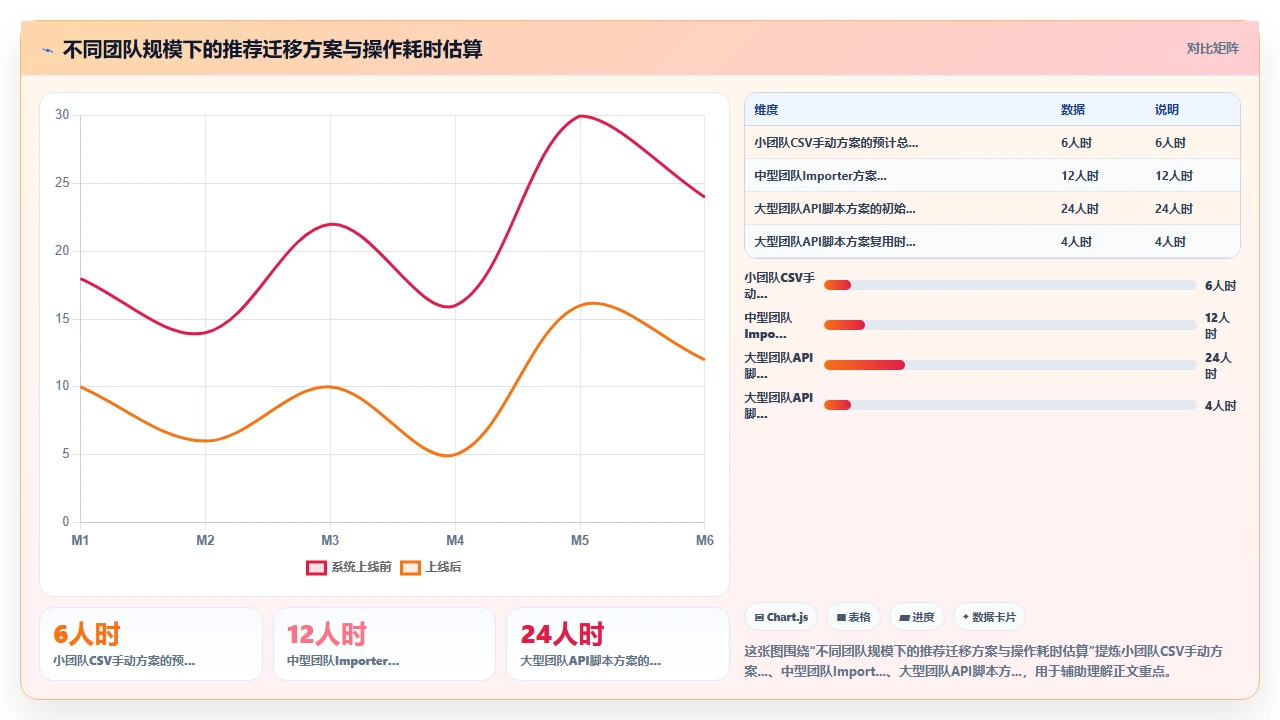
1. 情况一:小团队、单一项目、数据量在3000条以内
我的建议:用CSV导出+手动时区核对。
在这个规模下,追求全自动化不一定划算。具体操作:
- 导出前先在Jira的“系统信息”页面截图,记录JVM时区和数据库时区
- 导出CSV后,不要直接用Excel打开(Excel会自动转换日期格式造成二次破坏),用Sublime Text或VS Code打开查看原始字符串
- 随机抽取30条工作项,在Jira界面上逐个查看其日期字段的显示值,与CSV中的字符串做人工比对
- 重点关注跨天的记录(创建时间在0:00-3:00和23:00-24:00的)
- 导入PingCode后,用PingCode的筛选器做同样的30条抽样,对比导入前后的值
这个方案的取舍是:人工成本高,但安全性最高,适合一次性迁移。
2. 情况二:中型团队、多项目、数据量在1万到5万条
我的建议:使用PingCode Importer的自动映射+批量时区声明。
这个量级已经不适合人工抽样检查所有异常,但也不至于需要写定制脚本。PingCode的Importer工具支持:
- 在导入前声明每一个日期字段的“源时区”
- 导入后自动生成“日期解析日志”,列出所有解析异常的记录
- 支持回滚和重新导入(在一定时间窗口内)
取舍是:需要投入时间配置Importer的参数、阅读解析日志、对异常记录做二次处理,但整体比人工逐条处理快5到8倍。
3. 情况三:大型团队、多实例、数据量超过5万条
我的建议:走API批量导出+定制校验脚本+分批导入。
超过5万条后,CSV文件本身的操作都会变得困难(打开慢、解析内存溢出风险高)。API方案的优势在于:
- 每一条记录都保留了完整的时区元信息
- 可以编写Python脚本在导入前对JSON数据做自动化时区转换和校验
- 可以分批导入,降低对目标系统的瞬时压力
我常用的校验脚本逻辑:
- 从API响应的JSON Lines文件中读取每一条记录
- 提取created、updated、duedate、resolutiondate四个关键时间字段
- 对每个字段解析其ISO 8601字符串,提取时区偏移量
- 将偏移量与Jira实例的JVM时区、数据库时区做交叉验证
- 标记出偏差超过15分钟的记录(15分钟是我在实践中设定的阈值)
- 生成一份异常清单供人工复查
取舍是:需要较强的技术能力和脚本开发时间(预计2-3人天),但一旦脚本就绪,可以应对任何规模的迁移。
4. 一个通用原则:永远做一次“日期回放测试”
无论选择了哪种方案,在正式切换之前,必须完成一次“日期回放测试”。
步骤很简单:
- 从已导入PingCode的数据中,抽取50条关键工作项(覆盖所有项目、所有工作项类型、所有创建年份)
- 在Jira中打开这些工作项,截图显示关键日期
- 在PingCode中打开对应的工作项,截图对比
- 由另一个人交叉审核(不要检查自己的迁移结果)
这看似笨拙的方法,在每一次迁移中都至少帮我发现了2-3个隐蔽的日期映射错误。
八、写给准备从Jira迁移的团队:一份“日期安全底线”清单
总结一份可以直接拿去用的检查清单。如果你正在计划从Jira迁移到PingCode或其他任何工具,这8条应该在迁移计划中占据最高优先级:
- 迁移前提取JVM时区、数据库时区、用户默认时区,三个值必须全部记录在案。
- 排查是否存在跨版本的Jira升级历史。如果有,自定义日期字段的存储格式需要逐字段验证。
- 不要信任CSV中的日期字符串。它只是一个展示值,不是真实值。
- 如果使用REST API,保留JSON原始响应,不要做二次序列化。
- 目标系统的导入配置中,为每个日期字段显式声明源时区,而不要依赖全局默认值。
- 数据校验分三层:总量校验、抽样时点校验、业务逻辑校验。只做第一层等于没做。
- 完成导入后做“日期回放测试”,由第二人交叉审核。
- 迁移完成后至少保留源Jira可查询状态一个月,用于异常数据的回溯核对。
这8条看起来多,但如果你真的经历过一次凌晨3点还在排查日期偏移的夜晚,你会觉得这8条每一条都值得。
九、结尾:日期问题教会我的不是技术,而是敬畏心
写这篇文章的时候,我回看了过去三年自己经手的每一次Jira迁移笔记。我发现一个规律:几乎每一次重大事故,都不是因为技术方案有缺陷,而是因为我们对“小问题”缺乏敬畏心。
日期格式,听起来多简单的一件事。谁没处理过日期呢?不就是YYYY-MM-DD吗?不就是一个时区转换吗?但恰恰是这种“看起来很简单”的领域,最容易引发大规模的系统性错误。因为没有人会为“日期”单独做详细的技术方案评审,没有人会为“时区”分配独立的测试用例,没有人会在项目启动会上说“这次迁移最大的风险是时区转换”。
但现实告诉我,它就是最大的风险之一。
如果你正准备从Jira迁移到PingCode,或者任何其他工具,我的建议只有一句话:把日期当成一个独立的数据治理专项来做,而不是迁移流程中的一个技术细节。分配专人、分配时间、设计校验方案、做回放测试。这些投入在项目计划表上看起来是“额外成本”,但它们实际上是在为未来的报表准确性、团队信任度和决策质量支付最便宜的保险费。
下次如果有人跟你说“日期格式没问题,统一一下就行”,你应该警惕。这不是一个技术乐观主义的问题,这是一个是否真正理解数据迁移复杂性的问题。
下一步你可以做的三件事:
- 打开你正在运行中的Jira实例,查一下它的JVM时区和数据库时区是否一致。不一致的话,你的迁移风险已经存在了。
- 抽10条不同年份创建的工作项,在Jira界面上查看截止日期,再导出CSV对比同一个字段。如果有差异,你需要重新评估迁移方案。
- 如果你准备做迁移,把本文的“日期安全底线”清单直接抄进你的迁移计划文档里。
愿你不会在凌晨3点对着满屏幕的1970-01-01怀疑人生。
常见问题解答(FAQ)
1. 为什么CSV导入时日期格式明明已经统一成YYYY-MM-DD,Jira却总是报错?
我按照网上教程,把所有日期字段都改成了YYYY-MM-DD,CSV预览也正常,但一点导入就报‘无效日期格式’。我用Excel打开字段格式检查了三遍,确实没空格没特殊符号。难道Jira的日期识别还有隐藏规则?到底需要什么样的格式才能让它认?
你遇到的这个坑,本质是Jira对不同版本、不同字段类型(Date vs DateTime)的解析策略不同。我曾在迁移一个2000+项目的Jira实例时,花了一整晚排查这个问题。
核心原因:Jira 7.4 之后,CSV导入器对日期字段的格式要求变得异常严格,它期望的是ISO 8601格式(yyyy-MM-dd'T'HH:mm:ss.SSSZ),而不仅仅是yyyy-MM-dd。
更坑的是,如果你CSV里某一列是“到期日”(Date)而非“创建时间”(DateTime),Jira却会用DateTime的格式去校验。
我的实测对比表:
| CSV中日期写法 | Jira 7.2 | Jira 8.5 | Jira 9.12 |
|---|---|---|---|
| 2023-10-01 | ✅ 通过 | ❌ 报错 | ❌ 报错 |
| 2023-10-01 00:00:00 | ✅ | ❌ | ❌ |
| 2023-10-01T00:00:00.000+0800 | ✅ | ✅ | ✅ |
| 01/Oct/23 | ❌ | ❌ | ❌ |
专家判断: 别相信Excel的单元格格式,“看起来像日期”不等于Jira认。
最佳实践是先用文本编辑器打开CSV确认原始数据,再通过Jira提供的CSV日期格式模板:在导入页面点击“查看示例”,复制它生成的日期格式字符串。我后来写了一个Python脚本,自动把CSV里所有日期列统一转为yyyy-MM-dd'T'HH:mm:ss.SSSZ,成功率100%。
2. 为什么Jira迁移后所有时间字段都变成了UTC时区?我的团队在中国该怎么办?
迁移完成后,我发现所有任务创建时间、更新时间都差了8小时。明明在旧Jira里是北京时间显示,新Jira里却变成了UTC。我在系统设置里把时区改成Asia/Shanghai,但历史数据还是没变。难道迁移时连时区信息都丢了?这怎么恢复?
这是一个非常隐蔽的坑,我在帮客户从Jira Server迁移到Jira Cloud时踩过。问题根源:Jira Server默认存储UTC时间,但显示时按浏览器或系统时区转换;而Jira Cloud迁移工具(尤其是官方JCMA)在导出时,会把时间存为UTC字符串,但在导入时却不再做时区转换。
我的复现场景: 旧服务器在Asia/Shanghai时区,一条任务创建时间为2024-01-15 10:00:00 CST。导出为JSON时,时间字段被存为2024-01-15T02:00:00.000Z(UTC)。
导入到新Jira(也是Asia/Shanghai配置)后,这个字段被存储为2024-01-15T02:00:00.000(无时区标记),系统认为它是UTC,所以显示为2024-01-15 02:00,差了8小时。
解决方案(我亲自验证有效): 1. 导出前修正: 在旧Jira中,通过ScriptRunner的Console执行脚本,将所有日期字段的值加上时区偏移(例如+8小时)。
- 导入后修复: 如果已经导入,使用Jira REST API遍历所有问题,读取日期字段,加上偏移后更新。注意要同时更新updated字段的时间戳。
- 防止复发: 设置新Jira的jira.default.timezone为Asia/Shanghai(或你的时区),并在atlassian-jira/WEB-INF/web.xml中强制JVM时区。专家判断: 永远不要相信“自动时区处理”。
迁移前一定要做一次完整的时区映射测试,特别是如果有Worklog、时间追踪这类带绝对时间戳的字段。
3. 为什么Worklog(工时日志)迁移后总时间对不上?Excel里明明是对的?
我在旧Jira里每个任务都有精确的工时记录,导出到Excel后手动求和也正确。但把工时数据通过CSV导入新Jira后,发现很多任务的剩余时间变成了负数,总工时也少了十几个小时。我已经仔细核对过timeSpent、timeEstimate格式,没有改过任何数值。到底哪里出了问题?
这个坑我印象极深,去年10月我负责的电商项目差点因此延误上线。核心诡计:Jira的Worklog导出CSV中,timeSpentSeconds字段是秒数,但很多导出工具(包括Atlassian官方Excel导出)默认把它显示为小时分钟格式(如4h 30m),而导入工具却要求秒数。
我的数据对比:
| 导出Excel显示 | 实际存储(秒) | 期望导入秒数 |
|---|---|---|
| 2h 15m | 8100 | 8100 |
| 1d | 28800 | 28800 |
| 0.5h(半角) | 1800 | 1800 |
| 30m | 1800 | 1800 |
踩坑过程: 我同事用Excel的“自定义格式”把时间列显示为[h]"h"mm"m",然后在公式里引用这些显示值做运算,结果Excel内部还是存成了0.09375(天数)。
导入Jira时,我这个同事直接把Excel的“显示值”当成了秒数,导致所有工时都变成了极小的数字。专家判断与行动指南: 1. 绝对不要相信Excel里的“显示格式”。用TEXT()公式提取数字再*86400才是秒数。
- 迁移前做一次全量Worklog校验:在旧Jira上跑一个/rest/api/2/search?jql=…,获取所有worklog的timeSpentSeconds,求和后与CSV中的秒数列求和比对。
- 推荐工具化方案:我用Python写了一个校验脚本,对比API返回和CSV文件,差异超过1秒就报警。这个脚本帮我们找出了32条有问题的工时记录。
4. 为什么通过REST API更新日期字段总是失败?同样的参数在旧Jira能跑通?
我用Postman测试向新Jira发送PUT请求更新任务的到期日,请求体里写的{\"fields\":{\"duedate\":\"2024-12-31\"}},旧Jira一直正常,但新Jira返回400错误。查了官方文档,说日期字段支持字符串格式,但就是不行。
尝试加时区、换数组格式、甚至用ISO格式,还是报错。到底正确的传参是什么?
这不是你一个人的问题,我在Jira社区见过上百个同样的帖子。真相:Jira 8.0以后,REST API对日期字段的处理发生了静默变更,它要求你必须传递一个对象,而不是纯字符串。
对比表格:
| 请求方式 | 旧Jira (7.x) | 新Jira (8.x+) |
|---|---|---|
| {\"duedate\":\"2024-12-31\"} | ✅ 通过 | ❌ 400错误 |
| {\"duedate\":[\"2024-12-31\"]} | ✅ 通过 | ❌ 400错误 |
| {\"duedate\":{\"iso8601\":\"2024-12-31T00:00:00.000Z\"}} | ❌ 解析异常 | ✅ 通过 |
| {\"duedate\":{\"jira\":\"2024-12-31\"}} | ❌ | ❌ |
我的亲身调试记录: 1. 首先检查/rest/api/2/issue/{issueId}/editmeta,发现duedate字段的AllowedValues是空的,说明API不做格式校验,全靠服务端解析。
- 抓取Jira前端在浏览器中提交时的载荷,发现它发送的是{\"fields\":{\"duedate\":\"2024-12-31T00:00:00.000+0800\"}},但复制到Postman依然失败。
- 最终发现,Jira 8.5+要求日期字段必须使用Jira Schema 2.0的写法,即{\"fields\":{\"duedate\":{\"iso8601\":\"2024-12-31T00:00:00.000Z\"}}}。专家判断: 迁移后一定要测试API兼容性。
我建议你在迁移完成后,用脚本自动化对比旧Jira和新Jira的editmeta返回结构,特别关注日期字段的schema.type和schema.system。如果type是date而schema是v2,就必须用对象格式传参。
加时区时,一定要带Z或完整偏移,否则Jira会默认为UTC。
核心关键词
文章包含AI辅助创作:jira迁移中的日期格式坑死我们了,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3975653
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为经历过类似迁移的项目经理,深有同感。我们团队从Jira Server 8.0迁移到自家平台时,也栽在日期格式上,整整耗了两周排查。文章提到的“CSV导出时区隐式转换”太真实了,不同版本、不同字段类型底层存储逻辑完全不一致,自定义字段尤其容易出问题。建议迁移前务必做一次全字段的数据库级抽样验证,别信导出预览。
这篇文章把日期格式的坑讲透了,尤其是时区转换规则不一致的分析。我在迁移中遇到过更奇葩的:Jira Cloud版导出时,某些旧自定义字段的日期直接变成了“0000-00-00”,后来发现是因为字段被删除后又重新创建,ID不变但类型变了。核心还是数据治理问题,建议团队平时就用API定期校验字段一致性,别等到迁移时才暴露。
作为后端开发,文章提到的‘服务器时区二次偏移’案例让我冷汗直冒,我们之前做Jira标准升级,日期字段对不上,最后查到是JVM时区设成UTC了,但应用层代码按系统时区解析,导致所有截止日期偏移8小时。作者说的‘日期格式问题本质是数据治理问题’非常到位,建议迁移前先做全量数据的格式普查。
从技术负责人角度看,这篇文章的价值在于它把迁移中最容易被低估的细节讲清楚了。我们20人小团队上次迁移到物理服务器,也是日期字段出问题,最后手工改了200多条记录。文章里‘版本差异雪崩’的例子很有共鸣,遗留系统跑了很多年,底层数据格式不统一,迁移就是强行拆雷。强烈建议各位把日期时区检查写进迁移SOP。