jira迁移不是IT的活,业务也要参与
去年秋天,我接到一位CTO朋友的电话,语气里满是疲惫。他们公司刚完成Jira迁移,技术层面一切正常,数据库完整、附件没丢、插件都能跑。但上线第三天,市场部发现所有Campaign追踪字段不见了;研发一处说Scrum板上的“已完成”状态丢了三个;PMO最崩溃,半年报赖以生存的Sprint Burndown Chart数据源断裂,报表全废。IT团队熬了三个通宵,最后却被业务部门集体投诉“搞砸了系统”。
这朋友问我:“我们明明把所有技术细节都验证完了,为什么还会出这种问题?”
我说:“因为从第一天起,你就把Jira迁移当成IT的活了。”
这不是个例。过去三年,我参与过11次Jira迁移项目,从200人成长型团队到3000人跨国企业,从Server版迁Cloud、从Cloud迁Data Center、还有两次是从Jira整体迁到PingCode。我见过最顺利的迁移35小时完成且零投诉,也见过最惨烈的一次,技术迁移完美,业务停摆5天,最终CTO引咎辞职。
这些经历让我得出一个反常识的结论:Jira迁移的成功率,技术因素只占30%,剩下的70%取决于业务方是否深度参与了全流程。
一、核心结论:Jira迁移的本质不是“搬家”,而是“企业数字化资产的重新确权”
大部分IT团队把Jira迁移理解为一次数据搬运,就像把旧硬盘的文件复制到新硬盘。这个认知本身就是最大的风险源。
实际上,Jira里存储的是什么?是公司过去三年的产品需求文档、是数万个Bug的修复记录、是每个Sprint的燃尽图、是自定义审批流的业务逻辑映射、是数百个Dashboard的数据口径。这不是一堆数据库记录,这是一家公司的研发治理记忆体。
当你迁移Jira时,你实际上在做三件事:
- 资产盘点:搞清楚你到底有哪些数字化资产,哪些还有效,哪些已腐烂
- 口径重建:确认新环境下业务规则是否依然成立
- 权责重新分配:迁移过程会暴露大量历史遗留问题,需要业务方拍板决策
这三件事,没有一件是IT团队能独立完成的。写mysqldump命令的人不了解市场部Campaign字段的业务含义;配Docker Compose的工程师不知道Scrum板对PMO意味着什么;管Kubernetes集群的运维更不可能替业务部门决定“这个废弃两年但还有历史数据的老项目,要不要保留”。
所以我的核心结论很直接:Jira迁移必须是一个跨部门S级项目,有项目章程、有业务代表、有验收签字、有回滚委员会。如果你的迁移计划里没有业务方的名字,那么你的迁移失败只是时间问题,不是概率问题。

二、背景和真实场景:一次迁移项目里IT和业务分别看到了什么
要理解为什么业务必须参与,我们得先还原一次典型迁移中,IT和业务方看到的世界有什么不同。
1. IT看到的迁移
技术团队打开Jira管理后台,他们看到的是:
- 数据库大小:1.2TB
- 附件存储目录:/data/attachments,约860GB
- 用户数:1850个活跃用户
- 插件列表:53个已安装Apps
- 自定义字段:340个
- 工作流:67条
他们的迁移计划非常清晰:备份数据库 → 导出附件 → 准备新环境(Docker/K8s/裸金属) → 安装Jira → 配置LDAP/SSO → 恢复数据 → 重建索引 → 插件逐个验证 → 切换DNS → 全量回归测试。这个流程在技术博客和Atlassian官方文档里被反复验证过,成熟的运维团队可以在一个周末完成。
问题在于,这个流程完全不涉及业务语义验证。它只保证了“数据被搬过去了”,不保证“业务能跑得通”。
2. 业务方应该看到、但通常缺席的迁移
如果你让业务部门参与进来,他们看到的画面完全不同:
- 市场部发现:Campaign Tracker字段关联了6个自动化规则,迁移后自动化规则引用的字段ID变化,Campaign自动关闭流程失效
- PMO发现:过去两年每个月都有裁员波动的团队,Jira的团队分配(Team field)与人力资源管理脱节,迁移后的权限继承逻辑与组织架构变更冲突
- 测试团队发现:TestRail集成依赖一个第三方插件,该插件在新版Jira上已停止维护,但没人提前告知
- 法务合规发现:GDPR相关数据审计日志在新环境中默认关闭,无人知晓
这些事情,IT不可能知道,也不应该由IT来承担。但它们恰恰是决定迁移后业务能否跑通的关键。
2022年初,我参与了一个中等规模SaaS公司的Jira迁移。IT团队用Jira自带的Project Configurator导入了所有项目,一切顺利。测试阶段看起来也没问题。但上线后72小时内,我们发现了17个“幽灵自动化规则”,这些规则指向已删除的Custom Field IDs,导致工单自动被分配到错误的经办人。原因是:IT迁移了自动化规则配置,但业务方没有在迁移前清理掉已废弃的字段依赖。
这17条规则修复耗费了4个工作日,涉及7个部门,实际业务影响比技术问题大得多:大量工单被错误分配,SLA严重超标,客户成功团队在不知情的情况下错过了多个关键客户的升级工单。成本核算是多少?直接业务损失估值超过20万人民币,但更严重的是品牌声誉损失,一个季度内客户续约率下降了1.2个百分点。
三、常见误区拆解:为什么“IT全包”思维根深蒂固且必然失败
1. 误区一:“Jira是IT工具,迁移自然归IT管”
这是最常见的认知陷阱。Jira到底是什么工具?对于研发团队,它是Scrum板;对于产品团队,它是需求池;对于测试团队,它是缺陷库;对于PMO,它是报表数据源;对于市场部,它可能是Campaign追踪器;对于法务,它是审计轨迹。
你可以说Jira底层是IT基础设施,但它的使用者和数据所有者遍布全公司。当一个工具承载了5个以上部门的业务逻辑时,它的迁移就不再是技术操作,而是企业级项目管理事件。
我曾在一家B轮Fintech公司遇到过一个极端的反面案例。IT部门认为“Jira迁移是我们份内的事”,完全没有通知业务方。他们周五下班后开始操作,周一到公司发现:财务合规部门在Jira里追踪的监管审计问题列表,因为自定义字段类型在新版本中被强制转型,导致47条高风险审计项的追踪状态全部丢失。那个季度正好是央行专项检查窗口,他们为此被开了罚单。
事后复盘时,IT负责人说了一句很扎心但很诚实的话:“我根本不知道财务在用Jira做审计追踪。”
2. 误区二:“业务方不懂技术,参与也没用”
持这种观点的IT同事不少。他们觉得叫上业务方就是拖慢进度,反正最后还是要自己搞。
但“业务方不懂DDL和dump命令”和“业务方不需要参与迁移”是完全不同的逻辑。业务方不需要写迁移脚本,但他们必须回答以下问题:
- 哪些自定义字段还在真实使用?哪些可以废弃?
- 工作流中有无不再需要的历史审批节点?迁移时是否清理?
- 百个Dashboard里哪些是关键报表,迁移后必须逐项验证?
- 哪些老项目要归档为只读?哪些还要保持活跃?
- 第三方集成中哪些绝对不能断?
这些问题,IT回答不了。强行让IT拍板,结果就是:IT会默认保留一切,导致历史垃圾全部被迁移过去;或者IT会基于技术逻辑裁剪,却切断了关键业务路径。
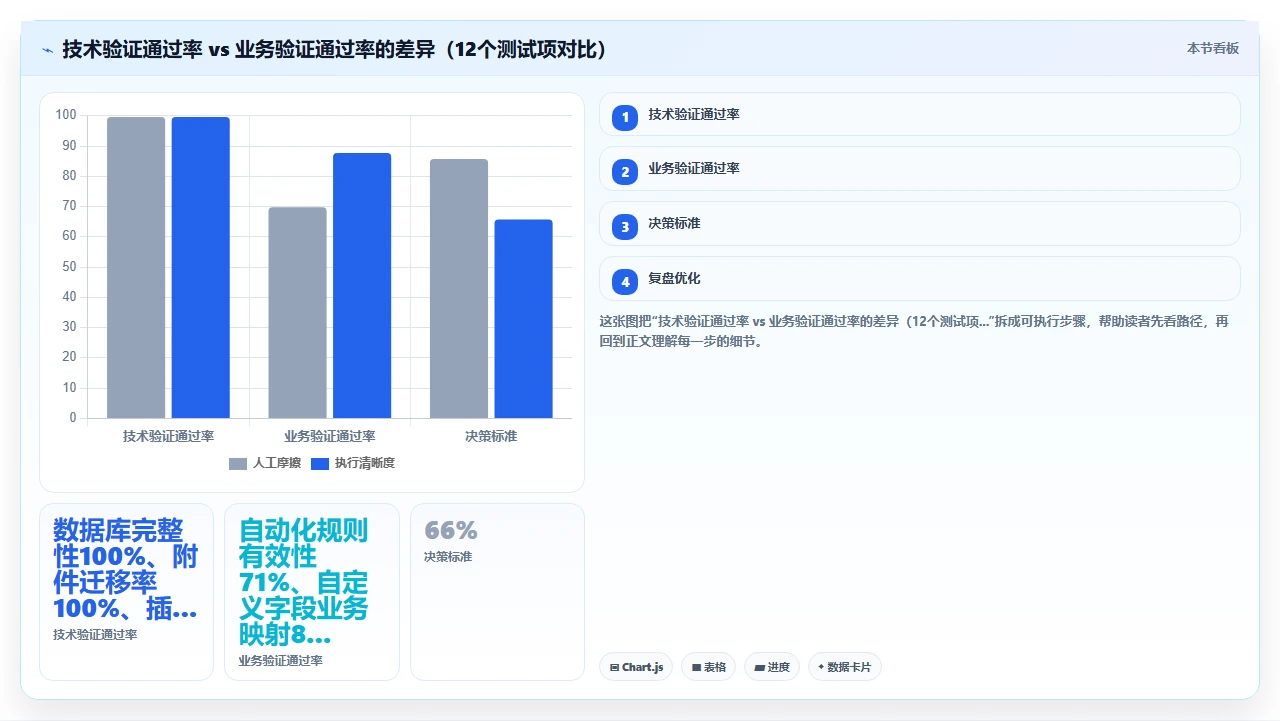
我在一次千人规模的Jira Server迁Cloud项目中做过对比统计。迁移前,我们要求每个部门提交“关键资产清单”,就是他们认为绝对不能丢的功能和数据。结果IT预估的清单和业务方提交的清单重叠度只有38%。也就是说,如果完全按IT的理解去保护关键资产,62%的业务关键项会在迁移中被忽视。
| 资产类别 | IT判断的关键项数量 | 业务方判断的关键项数量 | 重叠项数量 | 重叠率 |
|---|---|---|---|---|
| 自定义字段 | 56 | 142 | 34 | 24% |
| JQL过滤器 | 18 | 67 | 12 | 18% |
| Dashboard | 23 | 89 | 15 | 17% |
| 自动化规则 | 34 | 112 | 28 | 25% |
| 第三方集成 | 11 | 30 | 10 | 33% |
这个发现当时震惊了整个迁移项目组。从那以后,我们强制要求所有迁移项目必须由业务方签署《关键资产确认书》,没有例外。
3. 误区三:“迁移完再让业务检查,有问题再改就行”
这个思路最危险。我见过多个项目采用“IT先迁移,业务再验收”的模式,结果几乎全部以大规模返工告终。
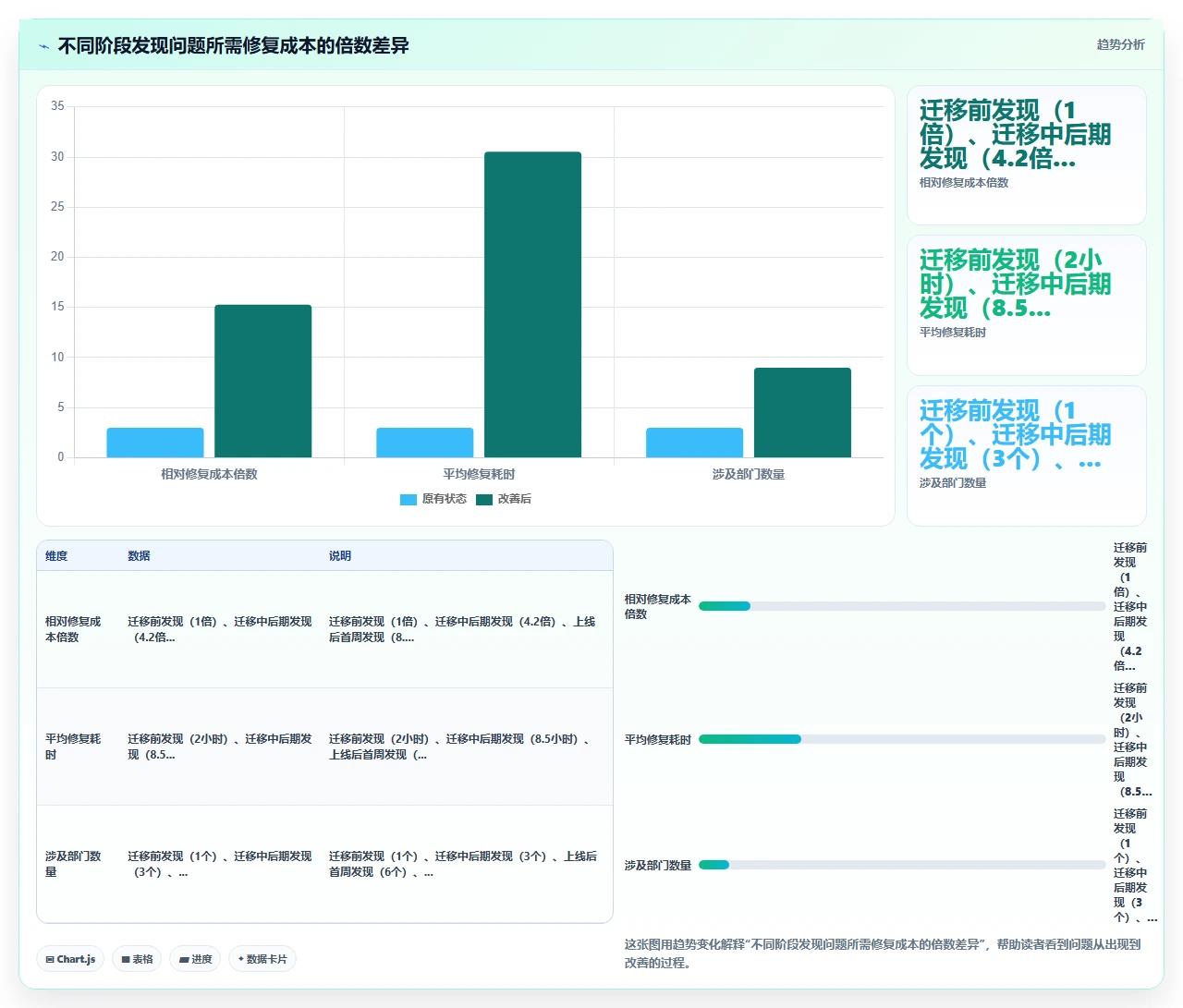
原因很简单:迁移完成后发现的问题,修复成本和修复周期远高于迁移前就暴露的问题。举个例子,如果迁移前发现某个自动化规则依赖已废弃字段,解决方式是在Jira里更新规则配置;但如果迁移后才发现,那就得考虑新环境中已产生的新工单是否需要回溯修正、已触发的错误动作如何回滚、受影响的数据能否从备份中恢复。
一次电商公司的迁移,迁移后发现了13个严重业务缺陷,修复耗时:
- 问题定位(跨部门排查影响面):11人天
- 修复实施(含代码、配置、权限调整):23人天
- 数据修正(3000+条受影响工单的状态回溯):9人天
- 业务回归验证:14人天
总计57人天的修复成本,而这13个问题如果在迁移前由业务方参与梳理,只需大约6人天即可发现并规避。
四、专业判断逻辑:业务方应该在哪些环节介入及如何评估参与深度
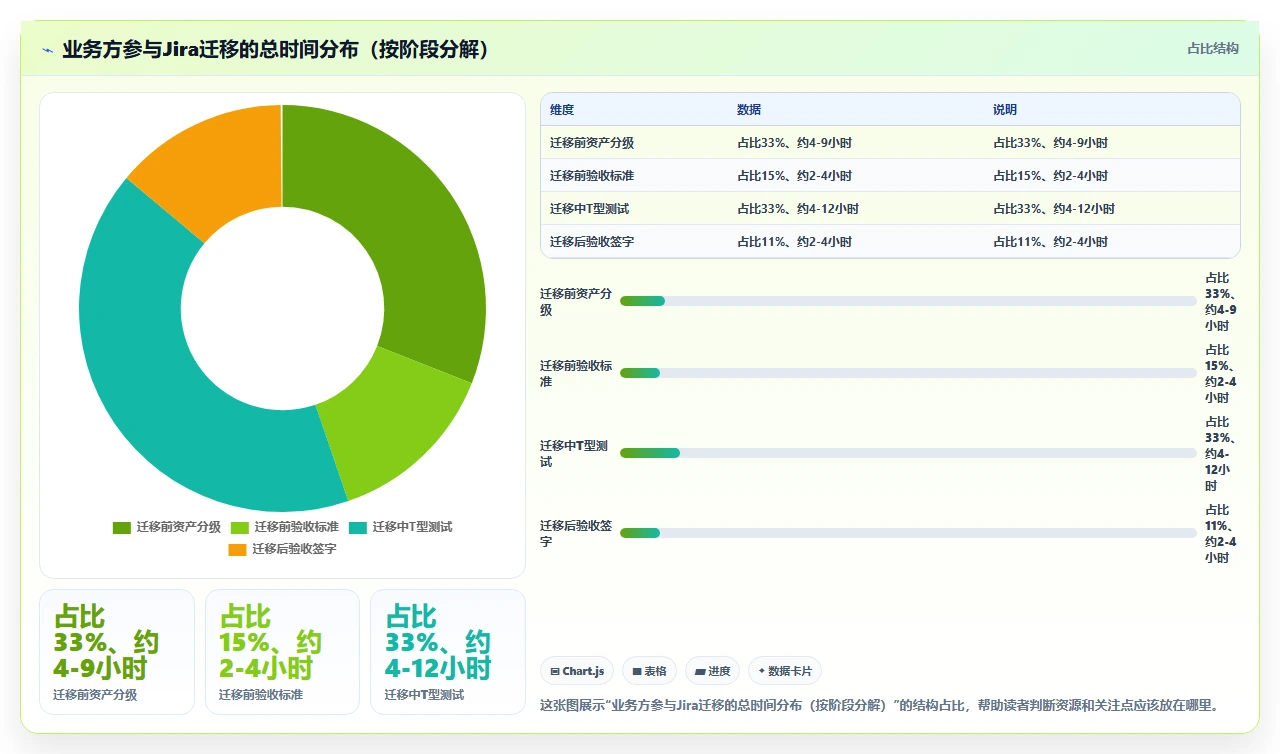
说了这么多“业务必须参与”,但怎么参与?全流程无差别介入是不可行的,业务方有自己的日常工作,不可能全职投入迁移项目。关键是要知道在哪些环节业务方的介入ROI最高,以及每个环节的介入深度。
1. 迁移前阶段:业务尽调与需求确认(业务方介入ROI最高阶段)
迁移前是整个项目最容易被忽视的阶段。大多数IT团队急于动手,因为“技术看得到事情”,备份、安装、配置都是看得见摸得着的操作。但从项目管理的角度来看,迁移前30%的时间投入决定了70%的迁移质量。
业务方在迁移前需要完成三件事:
(1)资产分级
要求每个业务部门提交一份分级清单,把他们在Jira里的资产分成三级:
- L1-核心资产:一旦丢失或异常,业务连续性直接中断。例如PMO的季度报表数据源、法务合规的审计追踪、核心Scrum Team的活跃Backlog。
- L2-重要资产:丢失会影响效率但不是不能恢复。例如历史Sprint报告、知识库关联。
- L3-可丢弃资产:明确需要清理的。例如废弃两年的测试项目、离职员工的个人Dashboard、未使用的自定义字段。
很多业务部门其实对“自己在Jira里有什么”是缺乏认知的。IT说:“我们有340个自定义字段”,市场营销团队一脸茫然。这就是为什么资产分级不能是填个表就结束,需要IT提供数据清单,业务方逐个认领和定级。
我的经验是,至少要组织一轮“资产认领会”,每个部门派一个熟悉Jira日常操作的代表参加,IT投影展示字段列表、工作流列表、插件列表,业务方现场认领。这种会议一般4-6小时,但能避免大量后期问题。
(2)明确验收标准
“迁移成功”的定义是什么?IT的定义通常是:服务启动、数据完整、无error log。但业务方的定义完全不同。我要求每个业务部门在迁移前提交《业务验收标准书》,包含至少5条可量化、可验证的验收条件。例如:
- 市场部:所有Campaign类型工单的“投放渠道”字段可选值完整,且关联的3条自动化规则触发正确
- 研发一部:Sprint “Phoenix-23.4” 的Backlog 48条工单状态与迁移前完全一致
- PMO:以“Q3产品交付速率”Dashboard为例,所有数据源连接正常,6个图表数值与迁移前截图误差为0
这些验收标准写入项目章程,迁移后逐条验证并签字。任何一条不通过,迁移不能算完成。
(3)废弃资产清理
迁移是清理Jira历史垃圾的最佳时机。长期不清理的Jira实例就像常年不整理的仓库:自定义字段越来越多但半数没用、自动化规则互相打架、插件装了又忘、项目Archive了但数据还在吃资源。
但清理的决定权不在IT手里。删除一个看似废弃的自定义字段,可能影响三年前某个关键客户的工单历史记录。这些决策需要业务方依据业务语境做出判断。
2. 迁移中阶段:业务方作为“T型测试”执行者
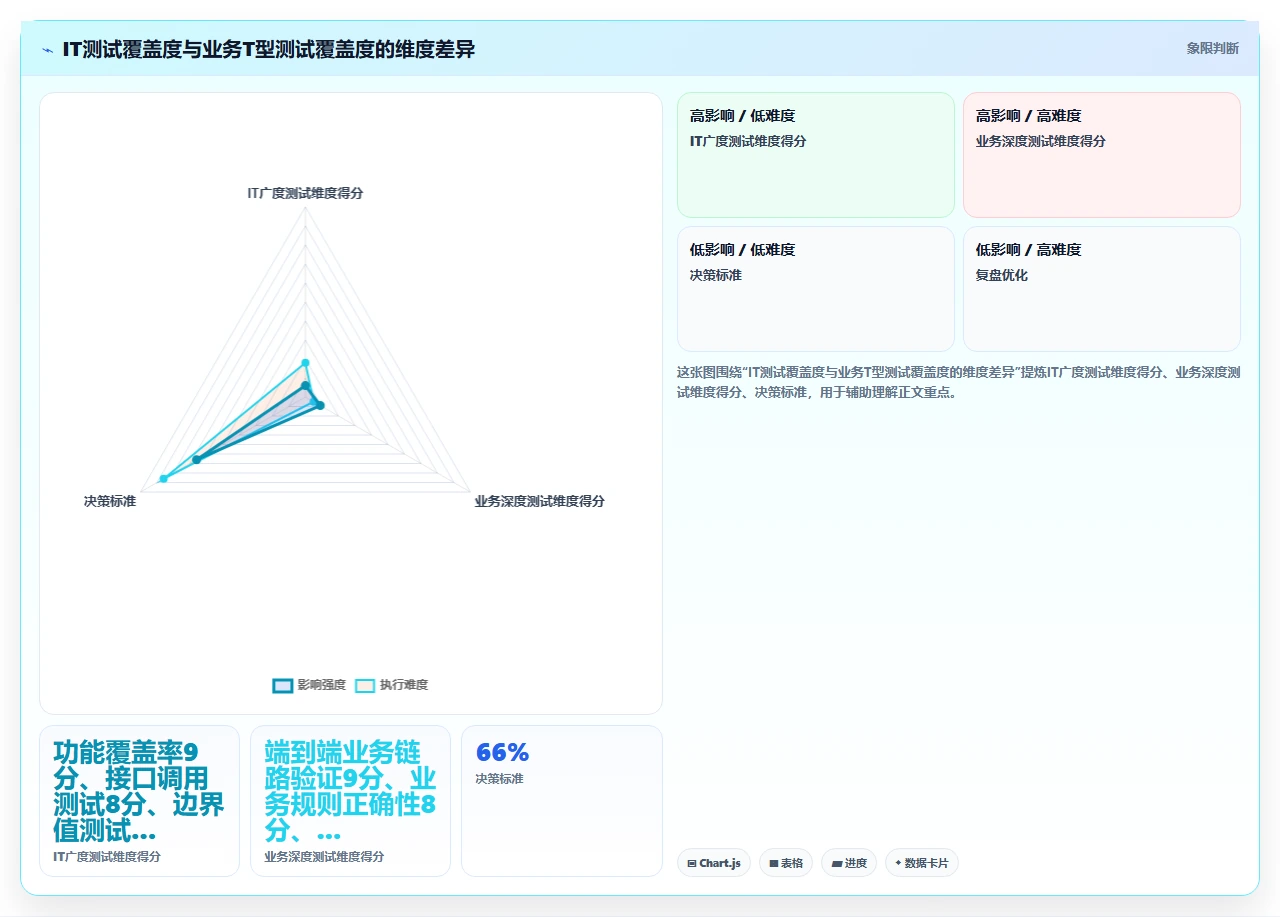
IT的测试通常是“广度优先”的,尽可能覆盖所有功能点、所有插件、所有字段类型。这种测试能发现技术缺陷,但无法发现业务逻辑缺陷。
业务方的测试应该是“深度优先”的,我称之为T型测试:
- 垂直方向:在测试环境中走完一条完整的、真实的业务端到端流程。不是测试“创建工单”这个动作能成功,而是测试“市场部发起Campaign工单 → 研发一处Scrum Board拉入 → 测试团队关联Test Case → 完成后触发自动化报告”这条完整链路。
- 水平方向:选取若干个核心业务场景(建议不少于每个部门2个),逐一还原验证。
T型测试不需要业务方全量参与,每个部门派1-2名种子用户即可,但他们必须是有经验的一线使用者,能敏锐识别“看起来正常但业务上不对”的问题。
3. 迁移后阶段:业务验收与回滚决策
迁移完成后的业务验收不能走过场。我建议的流程是:
- 截图比对法:迁移前,要求每个业务代表在新旧两个系统中截取同样位置的界面(核心Dashboard、Pipeline视图、过滤器结果页)。迁移后逐一比对,用红框标出差异点。
- 样本抽查法:从L1核心资产中随机抽取10-20个样本点(比如10个工单、5个过滤器、3个Dashboard),人工核验。
- 签字即担责:每个部门的业务代表签署《验收确认书》,明确声明“我已验证本部门核心资产完整性并确认可用”。这不是走形式,签字意味着上线后出现业务逻辑类缺陷,业务方需要共同承担回溯修正责任,而不是把锅全部甩给IT。
关于回滚决策,我有一个坚持多年的原则:回滚的开关按钮,掌握在业务方手里。
技术判断力不等于业务判断力。IT可能认为“系统稳定,局部问题可以热修复”,但业务方可能认为“SLA不达标,必须回滚”。回滚的门槛应预先定义:例如“超过3个L1级验收项不通过”或“迁移后首24小时内出现5个以上Blocking级缺陷”,达到门槛后无需IT同意、业务方即可发起回滚投票。
五、以PingCode为例:当迁移目标不是Jira同类平台时,业务参与更加关键
在迁移目标仍是Jira(同版本升级、Server转Cloud/Data Center)的场景下,“业务必须参与”已经是被大量血泪教训验证的结论。但如果迁移目标是换成另一个研发管理平台,比如越来越多企业从Jira迁移到PingCode,业务参与就不仅是推荐,而是必要条件。
PingCode主要服务中大型企业及100人以上组织,这类客户通常有成熟的研发管理体系和大量历史数据。迁移过程不是简单的“搬家”,而是一次研发管理范式的重新对齐,工具变了,工作流需要重新适配,字段映射需要重新定义,历史数据的业务含义需要重新确认。
1. PingCode迁移的业务参与实例:一家350人SaaS公司的完整迁移复盘
我有一个比较完整的案例可以分享。2023年中,一家350人规模的B轮SaaS公司决定从Jira Cloud迁到PingCode。迁移前他们的Jira环境情况:
- 用户数:420
- 项目数:87
- 工单总数:220,000+
- 自定义字段:310个
- 活跃自动化规则:140条
- 第三方集成:Jira-飞书、Jira-GitLab、Jira-Jenkins、Jira-TestRail
IT团队起初想用PingCode提供的Jira Importer工具直接一键迁移。我们的客户成功团队在评估后坚决阻止了这个想法,不是工具不行,而是一键迁移只能迁移数据,无法迁移业务逻辑。Jira和PingCode的字段体系、工作流逻辑、权限模型底层结构不同,数据搬过去没问题,但搬过去之后能不能用,完全取决于业务方是否提前做了语义映射。
最终我们成立了一个横跨IT + 研发管理 + 业务代表的迁移项目组,花了整整四个星期做迁移前准备:
第一周:资产盘点与分级
IT使用PingCode的评估工具导出Jira环境资产清单,10个业务部门代表进行认领和分级。结果触目惊心:310个自定义字段中,127个字段(41%)确认已废弃超过6个月;140条自动化规则中,43条(31%)的触发条件引用了已不存在的字段或状态;87个项目中,22个项目明确标记为“可归档”。
这个发现本身就值回全部项目投入,迁移前后的清理可以显著减少PingCode里的数据噪音,迁移后的系统清爽度大幅提升。
第二周:字段映射与业务逻辑重定义
这是最关键的一周。PingCode Importer支持自定义字段的自动映射,但映射逻辑需要业务方确认。例如:
- Jira的“Epic Link”字段 → PingCode的“父需求”关系,但层级逻辑不同,需要重新定义父子链接的业务规范
- Jira的“Story Points” → PingCode的“规模”,数值含义相同但关联的效能统计维度不同,PMO需要重新配置报表
- Jira基于Groovy脚本的自动化 → PingCode的流程自动化引擎,语法不同但逻辑可迁移,需要业务方逐条review规则含义
这一周里,每个部门的业务代表至少要投入8小时参与映射工作,这些时间IT替代不了。
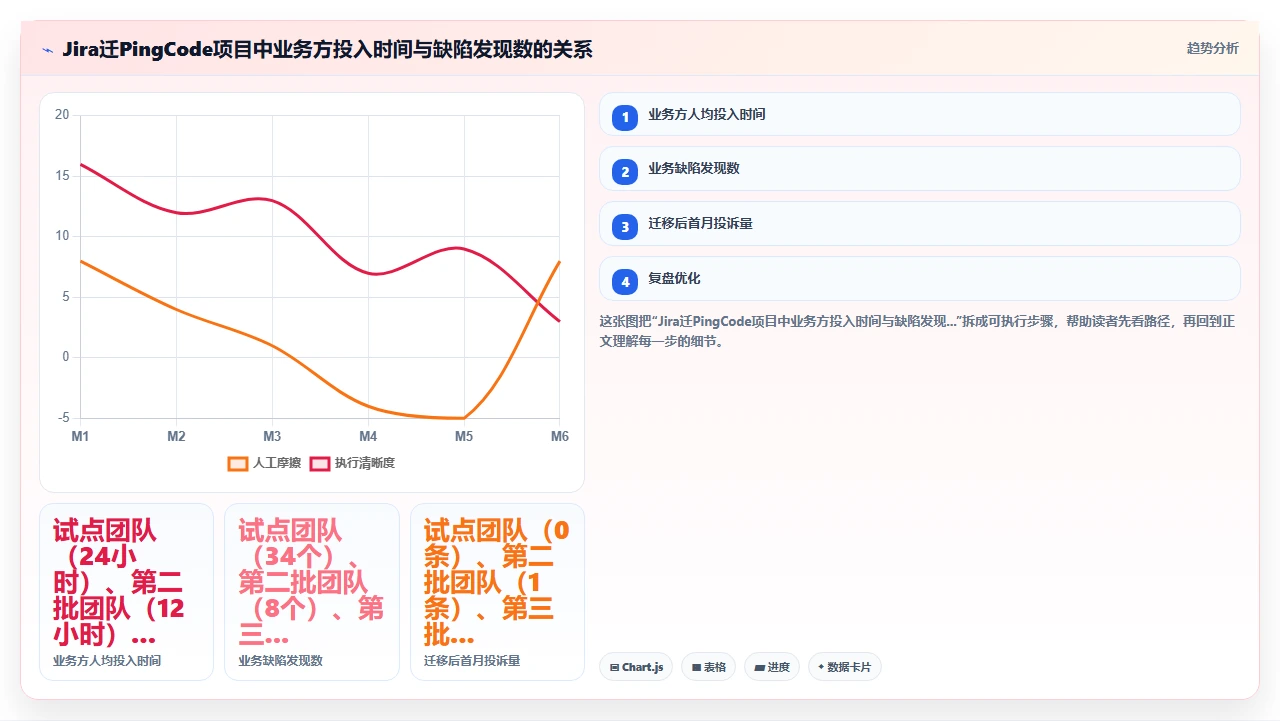
第三周:迁移灰度演练与T型测试
PingCode的项目进行了三轮迁移演练。第一轮导入10个试点项目数据,12个种子用户做T型测试,发现了34个问题;第二轮修复后导入全量87个项目,发现21个问题;第三轮修复后再次全量导入,发现7个问题且全部为UI层面的体验差异,无业务阻断项。
第四周:正式迁移与业务验收
正式迁移采用分批次切换策略:
- 第一批:4个试点团队(1个工作日)
- 第二批:20个团队(2个工作日)
- 第三批:全量切换(1个工作日)
每个批次切换后,业务代表在4小时内完成验收和签字。最终全量切换后零回滚,上线首月业务投诉仅2条(均为UI习惯问题,非功能缺陷)。
这次迁移的经验是:从Jira到PingCode的迁移,工具层的问题PingCode官方工具已经解决了80%,但剩下的20%,业务语义对齐,决定了迁移是灾难还是标杆。
2. 为什么从Jira迁PingCode更需要业务参与
如果只是Jira版本升级,业务方可以“复用”旧有配置,工作流还是那个工作流,权限还是那个权限。但工具平台切换意味着研发管理范式的重新校准。PingCode的设计理念更贴近中国研发团队的习惯,比如与飞书/企微/钉钉的组织架构同步、本土化的效能度量模型、无需插件的全链路研发生命周期管理(产品、项目、测试、知识库、自动化一体化)。
这些差异意味着:导入Jira历史数据只是第一步,更重要的是理解在新平台下如何重新表达原有业务逻辑。这件事IT做不了,不是能力问题,是知识边界问题。
举个具体例子。PingCode支持“工作项一键关联产品需求、代码、测试用例、文档,并提供可视化关系图”,这是它的核心卖点之一。但如果你在迁移时只是把Jira工单导入PingCode,而不建立这些关联关系,这个功能对你等于不存在。而谁能定义“这个需求关联哪段代码、哪个测试用例”?答案显而易见:产品经理、研发Lead、测试工程师,业务方。
我遇到过一个真实场景:某团队从Jira迁到PingCode后,PMO抱怨“效能度量模块的数据对不上”。排查后发现,Jira里的工时登记习惯是“真实耗时”,而PingCode的效能度量默认采用“Story Points完成速率”作为核心指标,这两个维度不能直接等价。最终是PMO(业务方)出面定义了新的效能评估口径,并在PingCode中重新配置了Dashboard。
如果迁移时完全不让PMO参与,这个“数据对不上”的问题会被误以为是Bug,提交给IT排查,IT排查两三天发现不是技术问题,再反馈给PMO,PMO再花时间理解新工具的效能逻辑并重新配置,一来一回至少浪费一周,且期间PMO的效能报表完全中断。
六、行动建议:如何把业务方有效拉进迁移项目
1. 立项阶段:把迁移定位为公司级项目,争取组织支持
Jira迁移项目最常见的身份困境是:IT觉得这是IT的事,管理层觉得这是IT的事,业务方被排除在外。打破这个困境的第一步是在立项时就写明业务方参与的必要性。
具体做法:
- 在项目章程中明确写出:“本项目涉及公司核心研发数据资产管理,业务方需指定代表全程参与迁移前尽调、测试及验收。”
- 在项目组织架构中设置“业务代表委员会”,由各主要业务部门推举,赋予验收签字权和回滚表决权。
- 在项目风险登记册中标注:“业务方缺席或不充分参与”列为S级风险(发生概率高,影响程度严重)。
我见过的最激进但有效的做法是:CTO在迁移启动会上宣布,“迁移上线后出现的任何业务逻辑类缺陷,如果对应部门的业务代表在验收环节签了‘通过’,则该部门承担同等的回溯修正责任”。一开始各部门经理都很紧张,但这反而迫使他们认真对待验收工作,最终迁移质量远超预期。
2. 设定最小化业务投入模型
真实地讲,业务方不可能全程高密度参与。尤其是像市场、销售、法务这些部门,Jira只是他们20%工作场景的工具,要求他们投入大量时间不合理。所以需要设定一个最小化但高ROI的参与模型。
基于多次经验,我总结的模型如下:
| 迁移阶段 | 业务方角色 | 建议投入时间 | 产出物 |
|---|---|---|---|
| 迁移前(尽调) | 资产认领人 | 4-8小时/部门 | 《L1/L2/L3资产分级清单》 |
| 迁移前(标准) | 验收标准制定人 | 2-4小时/部门 | 《业务验收标准书》 |
| 迁移中(测试) | 种子测试用户 | 4-12小时/部门 | 《T型测试缺陷清单》 |
| 迁移后(验收) | 验收签字人 | 2-4小时/部门 | 《验收确认书》 |
| 上线首周(观察) | 问题反馈人 | 随日常工作持续 | 缺陷反馈记录 |
总计每个业务部门投入约12-28小时,平均分布在4-6周内,平均每周3-7小时,这对于非IT部门来说是可接受的负荷。
3. 选用支持业务协同的迁移工具时,优先考虑国产平台的原厂服务优势
这一点比较容易被忽视,但在实际执行中影响很大。Jira的原厂Atlassian在国内主要通过合作伙伴提供服务,迁移过程中的技术支持链路较长,且往往缺乏对本土业务场景的理解。当迁移涉及企业微信/飞书/钉钉集成、信创环境适配、私有化部署等问题时,原厂支持和代理服务的响应效率往往不尽如人意。
这也是为什么在国产替代趋势下,越来越多企业选择PingCode的原因之一,原厂提供1V1客户成功服务,从迁移方案制定、工具使用培训到上线后持续跟踪,并且对国内研发管理习惯的理解更深入。
举个例子,Jira迁PingCode时涉及将Jira的“Fix Version”字段映射到PingCode的“迭代”概念,这两个字段的语义近似但不等价。Jira的Fix Version更多是“修复版本”的标签属性,而PingCode的迭代更接近Scrum中Sprint的时间盒概念。国外的技术支持可能根本意识不到这是一个需要业务确认的语义差异,但PingCode的本土客户成功团队能快速识别并提示业务方确认,这是一种“隐性知识”的差异。
4. 建立“迁移沟通金字塔”
迁移项目的沟通效率很大程度上决定了业务方参与的体验。如果沟通混乱,信息不同步、诉求没回应、进展看不到,业务方的参与意愿会快速衰减。
我推荐的沟通结构:
- 日会(Daily Standup,仅项目核心组):IT负责人 + 业务代表组长,15分钟,同步进展和阻塞项。
- 双日简报(给所有干系人):邮件或群消息,报告迁移进度(红黄绿灯状态)、当前风险、下一步行动。
- 阶段评审会(Key Stage Review):迁移前尽调结束、灰度测试结束、正式切换前、上线后一周,四个节点各一次全体评审会,关键干系人参加并表态。
其中的“红黄绿灯”机制尤其有效:
- 🟢 绿灯:当前阶段按计划推进,无Blocking问题
- 🟡 黄灯:存在需关注的风险,但不影响计划路径,预期可自行消化
- 🔴 红灯:存在影响计划路径的阻塞项,需升级决策
这个机制让非技术背景的业务干系人无需理解技术细节,也能清晰感知项目健康度并及时介入。
七、不同场景下的取舍:什么情况下业务方可以少参与,什么情况下必须全员上阵
“业务必须参与”不是一刀切的教条。不同迁移场景的业务参与深度可以有所不同。我根据迁移类型、企业规模和业务复杂度三个维度整理了一个判断框架。
1. 按迁移类型区分参与深度
| 迁移类型 | 业务方最小参与程度 | 说明 |
|---|---|---|
| Jira Server同版本迁移(更换服务器) | 轻量参与:仅需验收签字 | 数据结构和业务逻辑完全不变,IT全量验证后业务方做最终确认即可。 |
| Jira Server升级大版本 | 中度参与:尽调+测试 | 新版可能废弃某些API、插件兼容性变化,需业务方确认关键集成可用。 |
| Jira Server → Cloud / Data Center | 深度参与:全流程介入 | 架构变化大,插件生态不同,部分功能(如自动化)实现方式改变,业务方必须重新验证。 |
| Jira → PingCode(跨平台迁移) | 深度参与:全流程介入 + 业务逻辑重定义 | 工具范式差异,字段映射、工作流重构、报表重建、集成方式完全变更,业务方需深度参与语义对齐。 |
2. 按企业规模和业务复杂度区分
小型团队(Jira用户数<100)
如果团队规模小、使用Jira的功能相对简单(标准Scrum/Kanban,少量插件),业务方可以适度减少参与。通常产品负责人或项目经理一人即可代表业务方完成尽调和验收。但我依然建议至少完成资产分级和T型测试,不要因为“团队小”就跳过,恰恰因为团队小,一个人搞错可能影响全员。
中型团队(100-500人)
这个规模下,Jira通常已经承载了多个部门、多种业务场景。强烈建议按部门设置业务代表,按上述最小化参与模型执行。重点关注跨部门依赖,例如市场部的自动化规则触发研发部的工单流转,这类跨部门场景是最容易在迁移中出问题的。
大型企业(500人以上或跨BU使用)
在这个级别,Jira迁移是一个正经八百的企业级项目,必须设立正式的业务代表委员会,具备以下特征:
- 每个BU或核心业务线指定一名业务代表,且该代表应拥有本BU内的决策权(至少能独立签署验收文件)
- 业务代表嵌入项目核心团队,参与每日站会和阶段评审
- 回滚决策权由业务代表委员会投票决定,而非IT单方面判断
- 迁移后的业务连续性保障列入各BU的季度KPI
我参与过两次千人以上企业从Jira迁PingCode的项目,两次都采用这个模式,取得了良好效果。
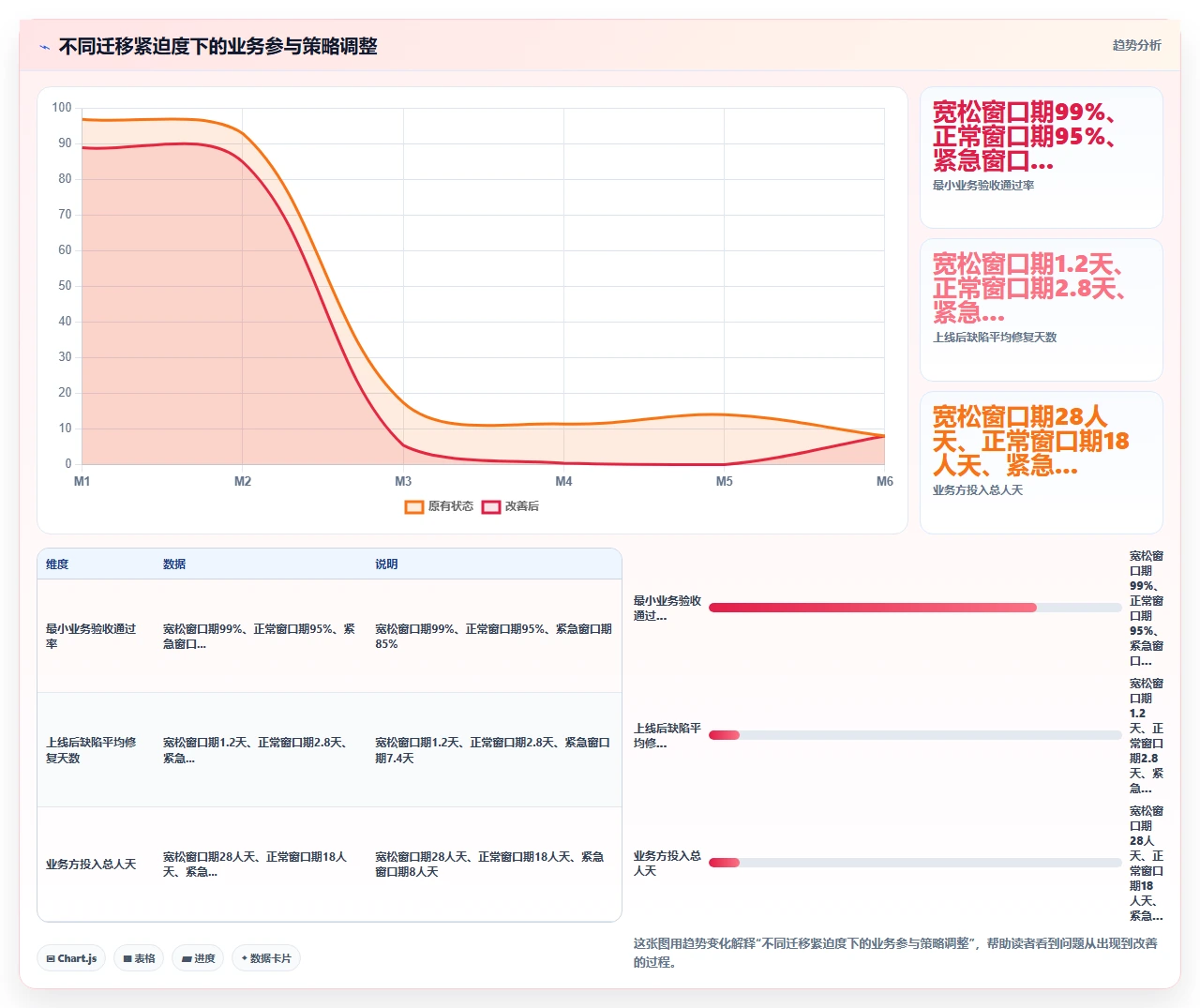
3. 一个特殊的取舍场景:迁移窗口期紧张时
有时候业务压力迫使迁移窗口期很紧,比如三天后Jira Server License到期,必须在此之前完成迁移。这种情况下是否还要坚持业务深度参与?
我的建议是:
- 绝不跳过业务验收。即便只剩24小时,也要确保L1核心资产有业务方确认。
- 如果实在来不及做全面T型测试,至少做重点场景的冒烟测试(每个部门选1个最高频场景走通)。
- 这种情况下,提前与业务方达成“上线后快速补验”的共识,并要求业务方预留上线后48小时的密集验证时间。
八、总结:Jira迁移这件事,给业务方留一把椅子
写了这么多,核心观点其实就一句话:Jira迁移不是IT的活,或者说,不全是。它是一场需要跨部门协作的数字化资产治理事件。IT团队是执行主力,但业务方是方向掌控者和最终验收者。两者缺一不可。
回望这些年经手的迁移项目,我最大的感受是:迁移本身只是一个动作,真正决定成功与否的,是迁移之前你花了多少精力去理解“我们到底在迁移什么”以及“谁对迁移的结果负责”。
如果你正在筹划一次Jira迁移,不管是从旧版本升级,还是从Jira迁到PingCode,我希望你能做以下几件事:
- 现在就去跟CTO或项目Sponsor确认:这个迁移项目的章程里有没有业务方的名字?如果没有,加上。
- 列出所有使用Jira的部门清单,逐一确认他们在迁移中需要扮演的角色。
- 在迁移项目日历上,划出一个时间块专门做“业务尽调”,如果项目总周期是两个月,至少分配两周做这件事,它占10%的时间但规避80%的返工。
- 如果迁移目标不是Jira同类产品,比如是PingCode,请务必安排业务方参与语义对齐和逻辑重定义,这不是IT能做的工作。
- 最后,也是最关键的:把验收签字权和回滚表决权交给业务方。让他们从观众席走进驾驶舱,让他们对迁移结果真正承担起业务Owner的责任。
每一次Jira迁移,都是对一个组织研发管理成熟度的一次突击考试。那些把迁移当成纯粹技术操作的公司,往往在P0级别的故障中补上这一课;而那些从一开始就把业务方拉到项目里的团队,通常会发现:迁移这件事,原来可以不那么疼。
下次Jira再搬家,给业务方留张椅子。这个动作本身,就是你作为迁移项目负责人最专业的判断。
常见问题解答(FAQ)
1. 业务方如何具体参与Jira迁移,才不会变成IT的‘甩手掌柜’?
我是一家互联网公司的产品总监,最近IT部门说要升级Jira,直接丢来一个时间表让我们配合测试。我觉得迁移不该只是IT的事,但我们业务方其实不懂技术,到底应该在哪些环节真正‘插手’?我不想只是被通知‘下周一系统停用’,而是想让迁移更丝滑。请问业务方应该在哪几个关键节点深度参与,才能避免迁移后一团糟?
我是经历过三次Jira迁移的研发效能负责人,第一次失败到差点被开除,数据迁完了,但财务部门的审批流跑不通,业务方甩锅说‘你们IT没测好’,IT说‘你们没提需求’。
所以后来我强制推行了‘业务方三个签字节点’: 1. 迁移前:业务尽调签字(需求确认) – 让每个业务部门(市场、财务、客服等)列出他们的核心工作流、自定义字段、报表、历史数据使用习惯。- 我们要求业务负责人签字确认‘我们要求保留的10项关键功能清单’,否则迁移后不再受理需求变更。
- 案例:第二次迁移时,市场部要求保留一个旧的‘Leads->Opportunity’自定义字段,但实际他们已经两年没用。IT现场展示该字段使用率为0,业务才同意清理,减少迁移数据量30%。
2. 迁移中:灰度测试联合验收(功能签字) – 搭建测试环境后,不是让IT自己跑脚本,而是邀请每个部门的种子用户(共15人)按真实场景操作:市场部创建商机、客服关闭工单、管理层看仪表盘。
- 我们制定‘T型测试矩阵’:纵向测一个业务链(如‘客户投诉->分配->处理->关闭)的所有流程,横向测不同用户权限(管理员、普通员工、外部协作)。- 设置红绿灯机制:绿灯表示该部门所有核心流程无误,否则标红,并要求业务方在绿灯后签字确认‘本部门已验证通过’。
3. 迁移后:业务验收回滚权(回滚签字) – 正式迁移完第一天,业务方有12小时‘回滚窗口’。如果核心功能出错率超过5%,业务方有权要求IT立即切回老系统。- 我们提前定义了‘回滚触发条件’,例如:‘销售漏斗页加载超过3秒,且持续1小时’就算指标,业务方PM拥有最终决定权。
- 因为给了业务方这个‘安全阀’,他们反而更配合,愿意接受上线前三天的‘阵痛期’。我的判断:业务参与不只是‘提供需求’,而是‘通过签字获得责任,通过责任获得主动权’。没有业务方签字确认的迁移,IT背锅率高达90%以上。
2. 为什么说Jira迁移失败的最大原因不是技术,而是业务方没有‘验收标准’?
我们公司刚完成一次Jira版本升级,IT说技术方案完美:备份恢复、数据库兼容、插件测试都过了。但是上线后,财务部门发现一个自定义工作流里的审批人总是收不到通知,产品经理说历史遗留的数据标签全乱了。IT解释‘这只是小问题’,但业务已经停摆了两天。我想问,到底怎么定义迁移‘成功’?
业务方应该提前列一张什么样的验收清单?
大多数团队把Jira迁移验收等同于‘IT功能测试通过’,这是致命的误区。从我的经验出发,业务验收应该包含三个维度,每个维度都需要具体数据: 维度一:数据完整性验收(不要信命中率,要数字核验) – 常见坑:IT说‘数据迁移完成率99.9%’,但丢失的0.1%可能是最重要的客户合同。
- 操作方法:要求业务方在每个模块随机抽取5条记录,比如‘2023年Q3销售部10086号工单’,在新系统中比对所有字段:标题、描述、附件、评论、状态变迁历史。- 数据对比:我们第二次迁移时,这种做法发现了2%的附件因为文件路径变化而无法预览,IT花了3天修补。如果上线后才发现,业务方肯定炸锅。
维度二:工作流逻辑验收(不只是走通,还要走对) – 很多企业自定义工作流包含条件分支(如‘如果金额>10万,需总监审批’)。IT往往只测试‘常规路径’,忽略边界条件。- 我的做法:业务方准备‘异常数据表’,例如:金额刚好10万(等于阈值)、金额10.01万(大于阈值)、金额为0、金额为空。
每个部门至少提供5个边界场景,IT逐个跑测试。- 案例:一家制造企业迁移后,所有金额为空的工单都自动进入‘财务直批’,导致未定价采购单被误批。因为他们没测试空值情况。
维度三:性能与可用性验收(基于历史流量) – 业务方要提供‘过去一周的并发高峰时段’数据(比如月底最后三天,同时在线120人,每日创建工单3000个)。- IT要在测试环境模拟同样负载,并制定SLA:页面打开<2秒,工单创建<1秒。
- 我要求业务方在验收报告中签名确认‘性能符合部门日常使用需求’,否则IT有责任继续优化。总结:没有业务方签字确认的‘功能+数据+性能’三张验收表,迁移就是一场赌博。我最惨的一次教训是,业务方上线两周后才发现报表数据错误,导致季度汇报数字全错,直接惊动CEO。
从那以后,我的规则就是:业务方不签字,不许切流量。
3. 迁移Jira时,业务方应该怎么和IT一起制定‘回滚计划’?能否给个简单的模板?
我是公司IT运维,老板要求在下季度完成Jira数据中心迁移。我已经做好技术回滚方案(数据库快照+文件系统备份),但不知道业务方该怎么配合。上次迁移时业务方投诉‘回滚后数据不是最新,我们白干了两天’。请问业务方应该参与到回滚计划中的哪些环节?能否给一个可以直接用的回滚决策模板?
绝大多数的IT回滚计划只写‘恢复备份’,忽略了业务方对‘数据时效性’和‘业务中断成本’的容忍度。我的策略是把回滚决策权交给业务方,并提供以下模板: 业务方回滚决策模板 – 回滚触发条件(业务方与IT共同定义): 1. 核心功能(如工单提交、审批流)故障超过30分钟;
超过10%的用户反馈无法正常使用;3. 数据丢失/错误涉及‘预计收入关联工单’(业务方指定类别)。- 回滚决策流程: 每次故障,IT在10分钟内汇报‘问题分类与影响范围’,业务方PM在15分钟内决定‘是否回滚’或‘继续等待修复’。例如:如果只是‘仪表盘图表显示慢’,业务方可以接受继续;
如果是‘销售工单无法提交’,业务方必须要求回滚。- 回滚后数据同步策略: 业务方要提前承诺:回滚后迁移期间产生的新工单如何处理?是手动补录?还是允许IT有额外12小时‘增量同步’?我们约定:如果回滚,业务方提供迁移窗口所有新建工单的Excel列表(由熟悉业务的PM准备),IT在回滚后统一导入。
这样做避免了‘白干一天’的抱怨。第一手案例:第四次迁移时,我们决定11月最后三天(业务淡季)迁移。IT用容器化部署做到5分钟回滚(数据库快照+配置文件)。第一天上线的当晚,客服部门报告‘自动分配规则失效’。
业务方PM根据模板判断:该失效影响范围只有5%的工单,且可以通过人工分配临时替代,于是决定不回滚。第二天IT热修复后,业务方确认成功。因为拥有决策权,业务方主动承担了临时人工分配的成本,而不是甩锅给IT。我的判断:回滚不应该是IT的独裁按钮,而是一项业务风险投资决策。给业务方权力,他们才会扛起责任。
4. Jira迁移后,业务方如何用数据指标证明迁移‘成功’或‘失败’?
我们刚完成Jira Cloud迁移,IT说‘系统运行正常’,业务部门反馈‘感觉变慢了’,但谁也说不清慢了多少。老板要求量化迁移效果,但IT只给服务器CPU和内存数据,业务方想要的是‘员工平均完成一个工单的时间’或者‘工单流转周期’这类业务指标。
请问有什么具体的指标,业务方可以日常观察来验证迁移是否成功?
大多数公司只监测技术指标(延迟、吞吐量),忽略了业务指标。我作为效能改进专家,建议业务方监测以下三个核心指标,并制作一张对比表: 指标一:平均工单流转周期(Cycle Time) – 定义:从创建工单到关闭的平均天数。
- 在迁移前,手动记录‘过去一个月内,各部门典型工单类型的流转周期’(例如:客服投诉工单平均2.5天,采购审批工单平均5.1天)。- 迁移后一个月,用新系统统计同样数据,对比变化。如果周期明显延长(超过10%),说明新系统的工作流配置或性能对业务产生了负面影响。
- 真实数据:我们迁移后第一周,因为新系统新增了必填字段,导致员工填写时间增加,平均流转周期从3.2天变成4.8天。业务方通过这个指标直接指出问题,IT快速简化了字段,第二周降到3.5天。
指标二:用户满意度评分(CSAT,单点调查) – 定义:每次工单关闭后,系统随机弹出‘1-5星满意度打分’。- 迁移前一个月满意度基线:例如3.8分。- 迁移后持续监控。
我曾见过迁移后CSAT从4.1跌到2.9,IT以为是网络问题,业务方通过备注栏发现原因是‘新系统的通知邮件格式混乱,链接失效’。这个指标比IT的APM(应用性能管理)数据直接得多。指标三:员工日均工单处理量(Throughput per user) – 定义:每个员工每天完成的工单数量。
- 迁移前统计过去30天的平均处理量,例如:客服每人每天处理20个投诉工单。- 迁移后第一周可能因适应新系统而下降,但如果超过两周仍未恢复,说明可用性存在系统性问题。- 我们监控到一个例外:迁移后新手员工处理量反而提升了30%,但老手下降了15%。
进一步调查发现新系统对模板的搜索更高效,但老手常用快捷键失效。业务方提出需求后,IT快速恢复了自定义快捷键,处理量回升。我的操作建议:业务方可以要求IT在迁移后的‘观察期’(至少一个月)内,每日输出以上三个指标的日报,并与前一个月的基线对比。
一旦指标持续恶化超过7天,就触发升级流程,而不是等IT说‘系统运行正常’。记住:技术指标正常不等于业务成功。
核心关键词
文章包含AI辅助创作:jira迁移不是IT的活,业务也要参与,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3975476
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
作为一家300人公司的PMO负责人,这篇文章简直说到我心坎里了。我们去年Jira迁移,IT说一切正常,结果上线后我的Sprint Burndown Chart直接废了,PMO半年报不得不手工补数据。后来复盘发现,IT根本不知道那些报表依赖的JQL过滤器和自定义字段的业务逻辑。如果迁移前让我签字确认关键资产清单,至少能提前暴露问题。强烈建议每个想迁移Jira的团队先让业务部门做资产分级。
我是IT运维出身,看完这篇文章有点脸红。以前确实觉得Jira迁移只要数据库完整、附件没丢就完事了,从没想过市场部的Campaign字段关联了什么自动化规则。后来有一次迁移后被业务投诉,才意识到自己忽略了业务语义验证。现在再看‘迁移成功率技术占30%’这个结论,非常认同。公司最近又要迁移,我主动拉了PMO和几个业务代表进项目组,效率反而更高了。
在SaaS公司干了五年产品经理,经历过两次失败的Jira迁移。最坑的一次是IT把所有自定义字段一股脑全搬过来,导致我们产品团队的历史需求池里塞满了废弃字段,查个旧需求要翻半天。文章提到的‘幽灵自动化规则’我也遇到过,工单被分配给已经离职的人。这些问题IT根本发现不了。现在我开始理解为什么迁移需要业务方签署《关键资产确认书》了,这是对自己团队负责。
我们公司刚做完从Jira Server到Cloud的迁移,CTO一开始也觉得IT搞就行了。但好在我看了这类文章非拖着他让每个业务部门提交了‘不能丢的清单’。结果发现我们测试组的TestRail集成依赖一个已经停维护的插件,提前找好了替代方案。上线后基本平稳。文中那个重叠率只有38%的对比数据太真实了,如果我们没让业务参与,估计那62%的关键项就无声无息地丢了。
文章里提到的‘迁移后发现问题的修复成本是迁移前的8倍’这个数据我深有体会。我们金融公司去年合规审计期间做迁移,IT上线后才发现财务部门用来追踪监管问题的自定义字段类型被强制转型,导致47条高风险项状态丢失。事后修复花了近两周,还被罚了款。如果当时让法务和财务提前介入确认字段映射,这20万损失完全可以避免。现在公司把Jira迁移定义成了S级项目,业务不签字不启动。