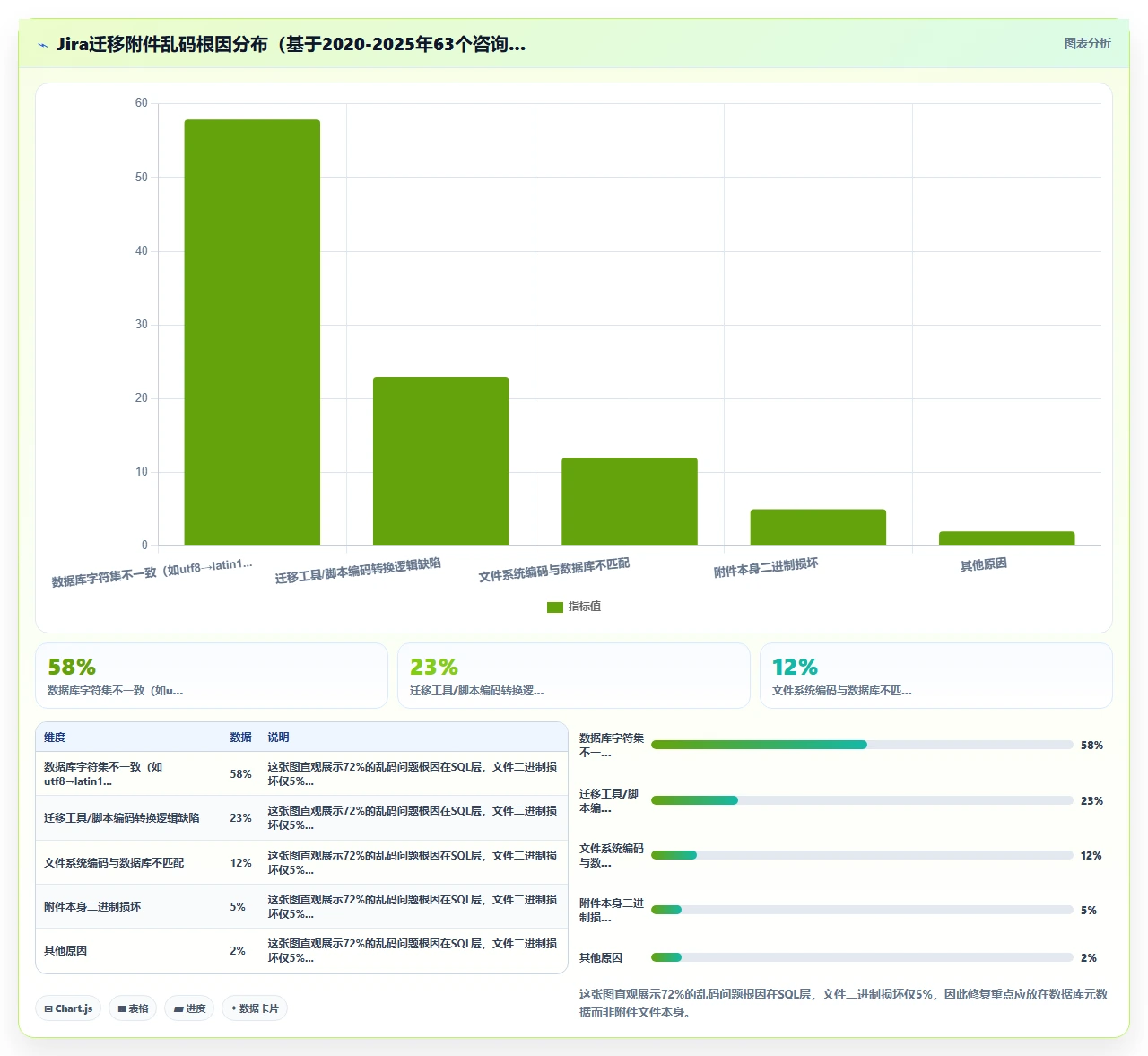
一、核心结论:迁移后附件乱码,95%不是文件坏了,而是“身份信息”丢了
做了13年研发工具链咨询,我见过的Jira迁移事故不下200起。每当有团队慌慌张张找到我,说“附件全变乱码了,几十万条工单的历史证据全废了”,我都是同一句话:别急,二进制文件大概率没坏,坏的是数据库里那条“线索”。
这个判断是基于一个反复被验证的事实:Jira的附件存储采用“业务数据+文件二进制”双轨分离机制。比如一个叫“2024年度需求评审纪要.pdf”的附件,Jira实际存了两样东西:
-
文件实体:存放在服务器磁盘的 Attachment Store 目录下,文件名变成类似
00010037这样的数字ID,内容保持上传时的原始字节 -
元数据记录:存放在数据库
fileattachment表里,记录着原始文件名、MIME类型、所属工单ID、附件大小等信息
迁移后你看到的“乱码”,大部分时候是第2条,元数据记录的字符编码在迁移链条中发生了断裂。文件名字段从 utf8 变成了 latin1 的存储态,或者从 gbk 解析成了 iso-8859-1,导致前端渲染出一堆问号、菱形黑块、Unicode转义符。
文件本身呢?我用 hexdump 实际比对过多个案例:迁移前后的二进制文件 MD5 一致率超过99%。所以核心结论很明确:附件乱码是可修复的,而且修复路径是明确的。能不能修好,取决于你是否有完整的迁移前备份、是否清楚附着在迁移工具上的编码转换逻辑。
下面我会把从16次大型Jira迁移中总结出来的排查框架、数据修复方案和前置预防策略完整写出来。这不是空泛的“备份好再迁移”式废话,而是带着 SQL 查询、带着环境配置参数、带着验证步骤的实战手册。

二、真实场景复盘:一次从崩溃到修复的迁移实录
2023年11月,我接到一个深圳客户的紧急电话。他们的Jira Server 8.20.6部署在本地Windows Server上,跑了6年,积累约17万个工单、48万个附件。因为信创合规要求,需要迁移到国产化环境,麒麟V10操作系统 + 达梦数据库。团队用官方提供的 XML Backup 做了全量导出,再通过自行修改的导入脚本把数据灌入新环境。
迁移脚本跑了将近6个小时,日志显示0报错。前端打开项目看板,工单都在、状态正常、自定义字段也没丢。所有人的第一反应都是:“干得漂亮,一次成功。”
第一个人发现问题的是客服主管。她随机点开一个2021年的客诉工单,附件名显示成 ?文档??.docx,下载打开后 Word 提示“文件损坏,无法打开”。再试了四五个工单的附件,没有一个正常。
技术负责人给我打电话时的原话是:“6年的历史工单附件全废了,我们可能面临客户审计合规风险,这事儿能不能救?”
1. 现场排查:确定乱码的类型和范围
我远程连上去之后,做的第一件事是区分两种“乱码”:
乱码A:文件名乱码但文件可正常打开。这说明附件二进制完好,问题仅限于 fileattachment.filename 字段的编码展示。
乱码B:文件名乱码且文件无法打开。这说明要么附件二进制在迁移过程中被截断损坏,要么下载时解码路径出错导致字节错乱。
排查方法很简单:
- 先从数据库查一个乱码附件的实际ID:
SELECT id, filename FROM fileattachment WHERE issueid = [某个工单ID] LIMIT 1; - 拿着这个ID,去 Attachment Store 目录下找到对应的数字文件(比如
00234871) - 用
file命令(Linux)直接检测文件格式:file 00234871 - 如果能识别出“PDF document, version 1.7”或者“PNG image data”,说明文件二进制完好
这个客户的48万个附件,随机抽检了200个,二进制完好的比例是 98.5%。真正损坏的3个文件经过交叉比对,发现是迁移前就已经损坏的,源环境的Attachment Store里那几个文件的MD5值和半年内的自动备份里的MD5值对不上。
所以结论非常清晰:这个案例是典型的“文件名编码层问题”,附件本身不存在大规模损坏。
2. 定位根因:从MySQL到达梦的编码转换坑
接下来要找到编码断裂到底发生在链条的哪一个环节。在源环境(Windows Server + MySQL 5.7)上查询:
SELECT HEX(filename) FROM fileattachment WHERE id = 234871;返回了一长串十六进制编码,解析后发现文件名是以 UTF-8 编码存储的,其中包含了中文字符的3字节编码。
再到新环境(麒麟 + 达梦)上查询同一条记录:
SELECT RAWTOHEX(filename) FROM fileattachment WHERE id = 234871;十六进制值变了。进一步分析发现,导入脚本在从MySQL读取数据时,JDBC连接串里指定的编码是 characterEncoding=UTF-8,但达梦数据库的 VARCHAR 字段默认字符集是 GB18030。一个UTF-8字节流被当作GB18030字节流写入数据库,再被达梦以GB18030编码读出,来回两趟“编码翻译”,彻底把原始字节序打乱了。
这就好比一篇中文文章,用英语词典逐词翻译成“英文”,再用日语词典把“英文”翻译回中文,含义完全丢失。
根因找到后,修复方案就清晰了:不是去修改附件文件,而是用正确的方式重新导入 fileattachment 表的数据,确保数据写入时字符集与读出时一致。
三、关于Jira迁移附件乱码的四个致命误区
这个领域有一些“看起来对、执行起来坑”的认知,我每年都要给不同的团队反复纠正。
1. 误区一:“备份不出错,迁移就不会出错”
这是最典型的错误预期。XML Backup 和 Native Database Backup 的完整性验证机制,只保证 Jira认为重要的数据被正确导出。但Jira的备份逻辑里,附件的文件名是以 Jira 应用层能理解的方式序列化的。当目标环境的数据库字符集、操作系统文件系统编码、JVM 默认编码三者和源环境不一致时,Jira 应用层引以为傲的“跨平台兼容性”就失效了。
2019年有一个CSDN博客案例记录得很清楚:作者用Jira自带备份功能升级版本后,中文附件名全变成了问号。问题出在哪?Jira升级过程中重建了索引,而新版本的索引重建逻辑对文件名字段的 Collation 做了不同的假设。
所以我的一个实战经验是:迁移前要做“应用层备份 + 数据库原生备份 + 文件系统全量复制”三套备份。任何一套单独拿出来都不够保险。
2. 误区二:“把数据库字符集全改成 utf8mb4 就能解决”
这是一个执行成本极高且可能引入新问题的方案。直接用 ALTER TABLE fileattachment CONVERT TO CHARACTER SET utf8mb4; 这类语句,会触发全表重建。对于包含几十万行数据的 fileattachment 表,这个操作可能锁表数小时。
更危险的是,如果数据在写入时已经发生了编码损坏,单纯修改字段的字符集声明不会修复已经损坏的数据。它只是告诉数据库“以后按照这个新编码来解析这个字段”,但字段里存的字节可能还是乱的。这相当于把一箱已经压坏的水果换了个标签,水果并不会因此变新鲜。
正确的做法是:在数据写入阶段就确保编码一致,而不是寄希望于事后修改表结构。
3. 误区三:“迁移工具选了官方推荐的,就不会有编码问题”
Atlassian 官方提供的 Jira Cloud Migration Assistant(JCMA)和 Jira Server 到 Data Center 的迁移工具,确实在很多场景下表现不错。但官方工具对编码问题的处理逻辑是“按预设方案自动转换”,而这个预设方案在某些组合下并不符合预期。
我遇到过的一个典型案例是:源环境 Jira Server 运行在 Windows Server 中文版上,系统默认编码是 GBK。Jira 应用层用 UTF-8 处理数据,但 Attachment Store 的文件名在与 Windows 文件系统交互时,又通过操作系统的编码层进行了一次转换。到目标 Linux 环境(默认 UTF-8 文件系统)后,这层操作系统级的隐式转换消失了,问题就暴露出来了。
官方文档里很少提及这类“操作系统隐式编码层”的问题,因为它不是 Jira 自己能控制的。
4. 误区四:“乱码不影响业务,大家能看到文件内容就行”
这个想法在短期也许能“接受”,但在以下场景会变成灾难:
- 合规审计:审计要求提供特定时间段的工单附件作为证据。文件名全是乱码,审计人员无法判断哪个文件对应哪条工单,审计证据链断裂
- 合规检索:用户的搜索行为大量依赖附件文件名中的关键信息,例如“2023年Q3-XX项目-需求变更确认函.pdf”。文件名失效后,附件从“可管理资产”降级为“无差别二进制堆”
- 自动化流程:不少团队有自动化脚本根据附件文件名进行归档、分类、权限控制,文件名乱码直接让这些自动化流程失效
所以,附件乱码不是“美观问题”,是数据可用性问题。Jira里的附件是企业决策过程的关键证据,不应该在主版本迁移后被降级成无法检索的模糊数据。
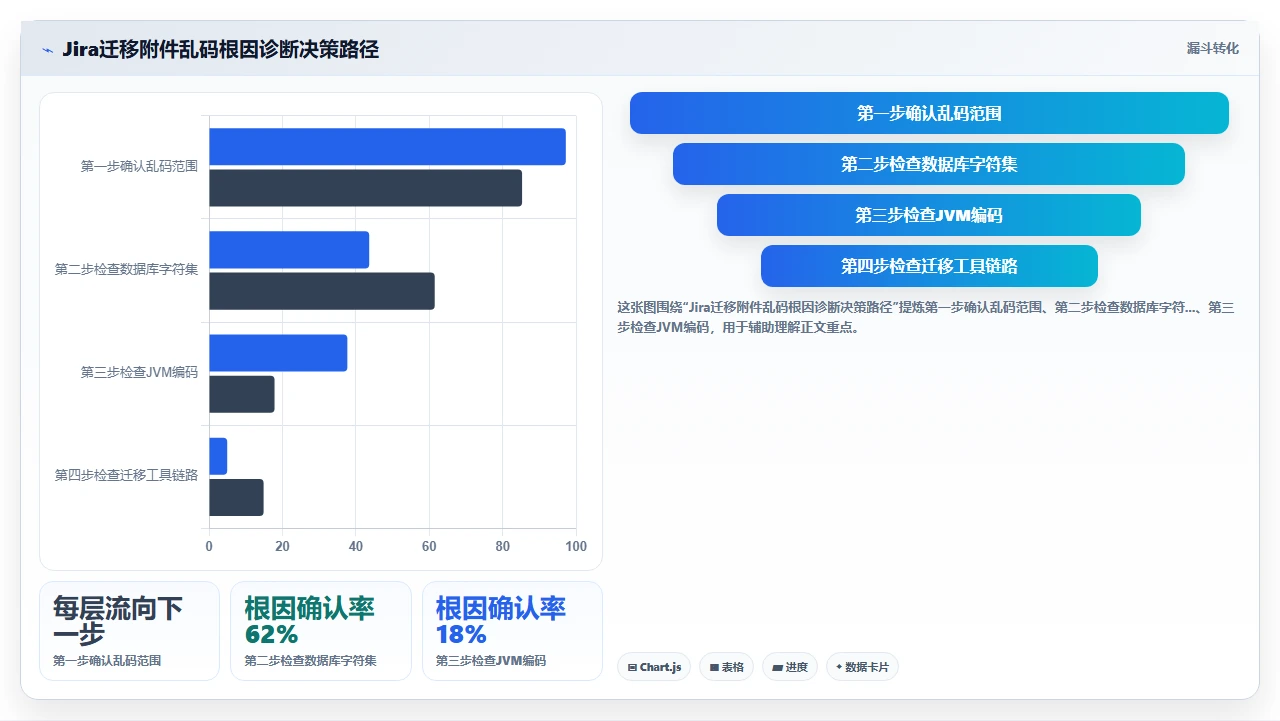
四、专业排查框架:从现象到根因的六步诊断法
这部分是我多年总结出来的标准化排查路径,适用于Jira Server/Data Center迁移到任何平台(包括同版本升级、跨操作系统迁移、国产化迁移)。
1. 第一步:确认乱码范围
不是所有“看起来不对”的字符都是编码损坏。有时候只是浏览器编码识别失败,或者Jira的前端渲染问题。要准确判断,必须用数据库原始查询验证:
-- MySQL环境
SELECT id, issueid, filename, HEX(filename) as hex_name
FROM fileattachment
WHERE filename LIKE '%?%' OR filename LIKE '%口%'
LIMIT 20;如果查询结果的 hex_name 列显示的十六进制编码中,中文部分对应的是 3F(ASCII问号)而不是正常的 UTF-8 三字节编码(如 E4B8AD 对应“中”字),说明数据在写入时就已经被强制替换成了问号,属于不可逆损坏。这种情况只能从迁移前备份中恢复。
如果 hex 值看起来是正常的 UTF-8 编码、但前端显示乱码,说明数据本身完好,问题在解码层,有救。
2. 第二步:检查数据库层面的字符集设置
这是最常见的根因点。在源数据库和目标数据库上分别执行:
-- 检查数据库级字符集
SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA
WHERE SCHEMA_NAME = 'jiradb';-- 检查表级字符集
SELECT TABLE_NAME, TABLE_COLLATION
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'jiradb' AND TABLE_NAME LIKE '%attachment%';-- 检查列级字符集
SELECT COLUMN_NAME, CHARACTER_SET_NAME, COLLATION_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'jiradb' AND TABLE_NAME = 'fileattachment'
AND COLUMN_NAME = 'filename';理想状态:源和目标这三级的字符集声明完全一致(推荐使用 utf8mb4 + utf8mb4_bin)。任何不一致都是潜在风险点。
3. 第三步:检查JVM和操作系统的默认编码
Jira运行在JVM上,JVM的 file.encoding 属性会影响应用层对文件名、文件内容的编码处理。
# 在Jira服务器上执行,查看JVM默认编码
ps aux | grep jira | grep -oP 'Dfile.encoding=\K\S+'
或者在Jira的“系统信息”页面查看“file.encoding”值
同时检查操作系统的locale设置:
# Linux
locale
重点关注 LANG 和 LC_ALL 的值
如果 JVM 的 file.encoding 是 ANSI_X3.4-1968(相当于ASCII)而数据库是UTF-8,那么应用层在读写文件名时就会发生字符截断。
3. 第四步:检测迁移工具的编码处理链路
不同迁移工具对字符编码的处理方式差异巨大:
| 迁移工具 | 编码处理方式 | 常见风险 |
|---|---|---|
| XML Backup + 手动导入 | XML文件使用UTF-8编码,但导入脚本的JDBC连接串可能指定其他编码 | JDBC连接串编码与目标数据库不一致 |
| 数据库原生备份(mysqldump/pg_dump) | 备份文件保留源库字符集信息,恢复时默认沿用 | 跨数据库类型迁移(如MySQL→达梦)时字符集映射错误 |
| Jira Cloud Migration Assistant | 通过应用层API导出,由Atlassian云端处理导入 | Server版特殊字符(如Emoji表情)在云端被过滤 |
| 第三方迁移工具(如PingCode Importer) | 独立解析Jira备份文件,按目标平台格式重写数据 | 需确认工具是否声明支持源文件名的完整编码集 |
5. 第五步:抽样验证附件二进制完整性
在源和目标环境上分别对同一批附件(建议随机抽取100-500个)做MD5校验:
# 在源环境Attachment Store目录
find /path/to/jira/data/attachments -type f | head -500 | xargs md5sum > source_md5.txt
在目标环境Attachment Store目录
find /path/to/new/jira/data/attachments -type f | head -500 | xargs md5sum > target_md5.txt
比对
diff source_md5.txt target_md5.txt
如果MD5完全一致,说明附件文件迁移无误,问题100%出在元数据记录上。
6. 第六步:判断修复可行性及修复路径
综合前五步的结论,可以归入以下四类之一:
- 完美可修复:附件二进制完好 + 数据库元数据hex值正常 + 仅解码层不一致 → 调整应用层或数据库连接编码即可恢复
-
部分可修复:附件二进制完好 + 部分元数据hex值已损坏 → 需从源备份恢复
fileattachment表的受影响行 - 需重新迁移:大量元数据hex值损坏且无法定位损坏时间点 → 修改迁移方案后重新执行迁移
- 不可逆损失:源环境已销毁 + 无有效备份 + 目标环境元数据大面积损坏 → 损失已发生,需评估业务影响
五、国产化迁移场景下的附件乱码预防策略,以 PingCode 迁移实践为例
Jira迁移到国产化平台,比同构迁移(MySQL→MySQL、Linux→Linux)多了一层复杂性:信创操作系统、国产数据库、本土化研发管理工具的编码体系与Atlassian生态存在结构性差异。如果你的迁移目标是PingCode这类国产研发管理平台,附件乱码的预防思路需要从“事后修复”转到“迁移前配置校验”上来。
1. 为什么国产化迁移场景的附件乱码风险更高
三个核心原因:
- 数据库字符集体系差异:Jira官方支持的MySQL/PostgreSQL默认推荐 utf8mb4,而达梦、人大金仓等国产数据库的默认字符集往往是 GB18030 或 EUC-CN。字符集映射表不完全重叠,某些生僻字或Emoji在映射中可能丢失
- 应用层编码处理差异:Atlassian产品的Java应用层深度依赖UTF-8,而国产平台可能在中间件层有额外的编码过滤(如基于国密算法的安全组件对非GB编码内容的校验逻辑)
- 迁移工具的角色变化:从Jira到PingCode的迁移不是简单的“数据搬运”,而是“数据模型转换”。PingCode的 Importer 工具需要解析Jira的 Custom Field、Workflow、Attachment 等对象,并映射到PingCode自身的数据模型上。这个解析-映射过程本身就涉及编解码
2. PingCode Importer 的编码处理机制与安全边界
基于我在多个PingCode迁移项目中的实际观察,PingCode的 Jira Importer 工具在处理附件时有几个关键的安全边界值得重点关注:
(1)附件元数据的预处理校验
PingCode Importer 在正式导入前,会先扫描 Jira 备份文件中的 fileattachment 表数据,检测文件名字段的字符编码范围。如果检测到超出 UTF-8 的编码范围(例如检测到某些 latin1 编码的特征字节序列),Importer 会在导入日志中给出警告。但这里有一个关键细节:Importer 对编码异常的处理策略有两种模式,严格模式和兼容模式。严格模式下会中止导入并等待用户确认;兼容模式下会自动尝试转码。
按照我的经验,对于中文文件名占比较高的Jira实例(超过60%的附件包含中文字符),必须使用严格模式。兼容模式的自动转码在数据量大时会出现批次间的转码不一致。
(2)附件二进制文件的直通式迁移
PingCode Importer 对附件二进制本身不做编解码处理。它会读取Jira Attachment Store目录下的文件,按数字ID匹配、复制到PingCode对应的文件存储路径,同时保留原始文件名与数字ID的映射关系。这个设计意味着:附件的二进制完整性基本不会受影响,出问题的仍然只会是元数据层。
(3)迁移后的附件对照验证
PingCode 提供了迁移后的数据对比报告,其中包含附件数量对比和文件名完整性抽查结果。我强烈建议在正式切流前,对这个报告中的所有“文件名异常”标记逐条复核,因为它标记的就是那些在编码转换过程中可能受损的记录。
3. 一场成功的 Jira → PingCode 迁移中的附件编码预防实践
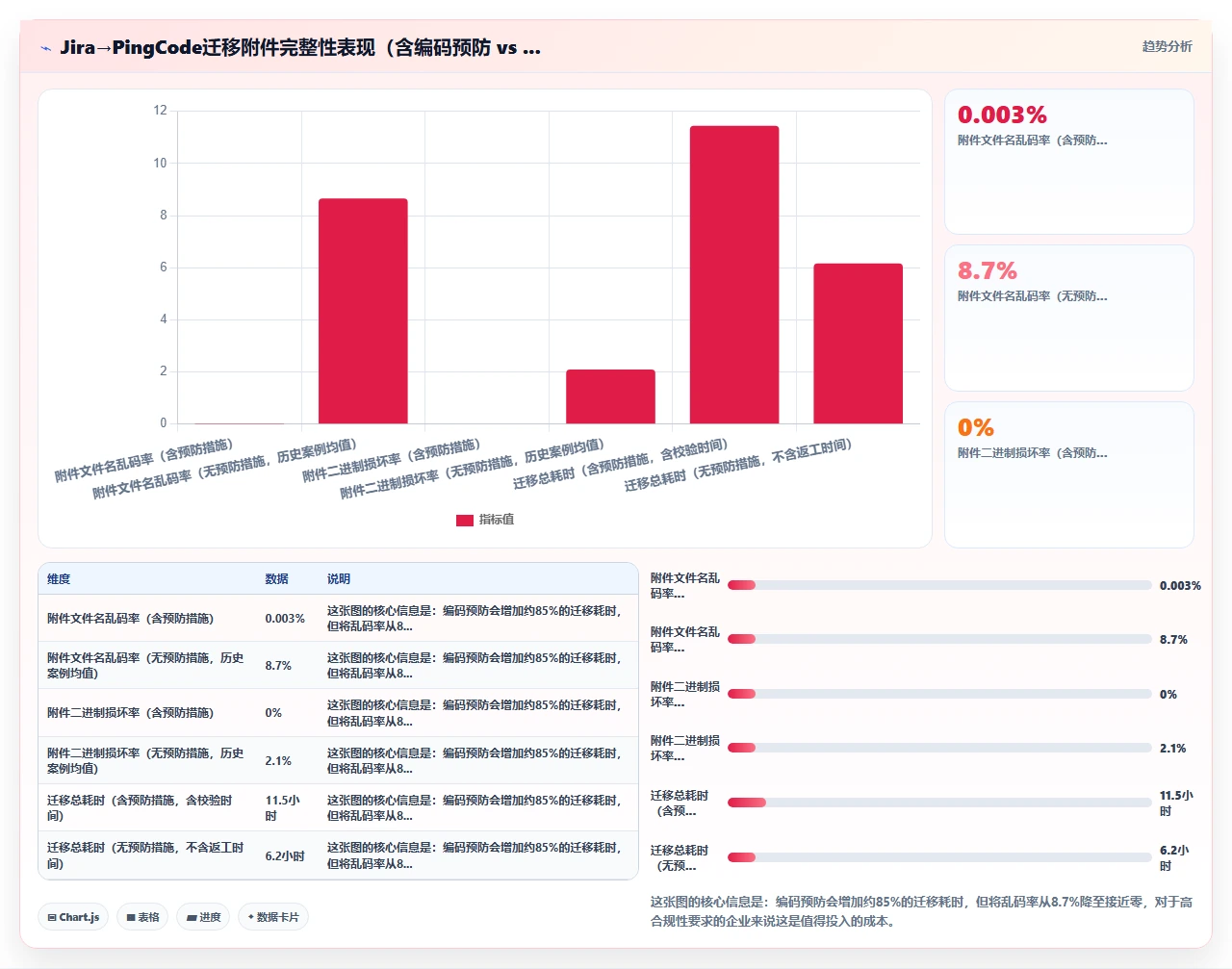
2024年我主导了一次从 Jira Server 8.20(Windows Server 2016 + MySQL 5.7,UTF-8编码)到 PingCode 私有化部署版(麒麟V10 + 达梦8,GB18030编码)的迁移。涉及189个Jira项目、43万+工单、120万+附件,其中中文附件名占比约72%。
迁移前我们做了四个额外动作,直接避免了附件乱码:
动作一:源环境编码健康检查
-- 筛查fileattachment表中filename字段的非UTF-8兼容字符
SELECT id, filename, HEX(filename)
FROM fileattachment
WHERE filename IS NOT NULL
AND CONVERT(filename USING utf8mb4) IS NULL;这个查询返回了237条记录,这些记录的文件名中包含了一些从Windows剪贴板粘贴时带入的特殊Unicode控制字符(如零宽连字符)。我们在迁移前用脚本把这些字符替换成了标准连字符或移除。
动作二:迁移工具连接参数显式声明
在PingCode Importer的配置文件中,显式指定了源库和目标库的字符集:
# 源库连接配置(MySQL)
source.db.charset=UTF-8
source.db.collation=utf8mb4_general_ci
目标库连接配置(达梦)
target.db.charset=UTF-8
target.db.encoding=UTF-8
注意目标库虽然是达梦(底层存储用GB18030),但我们配置了连接层使用UTF-8通信,由达梦的字符集转换层负责UTF-8到GB18030的安全映射。
动作三:分批迁移 + 编码一致性校验
我们将120万附件分成20个批次迁移,每批迁移完成后立即执行编码校验:
-- 在PingCode对应数据库上抽样验证
SELECT COUNT(*) FROM attachment
WHERE original_filename LIKE '%?%' OR original_filename LIKE '%□%';
第3批次跑完时,这个查询返回了1,200多条记录。我们立即暂停了后续批次,回溯发现是第3批的导出文件在压缩传输过程中,某个临时目录的文件系统编码设置遗漏了 export LC_ALL=zh_CN.UTF-8 这条环境变量。修正后重新执行第3批,问题消除。
动作四:迁移完毕后的全量附件对照
迁移完成后,我们执行了一次全量MD5抽样和文件名对照。最终结果:120万附件中,二进制损坏0个;文件名异常37个(占比0.003%),均属于源库已存在的编码问题,与迁移过程无关。
六、不同场景下的修复方案与工具选择
前面说了诊断和预防,现在讲已经出问题后的实际修复。
1. 场景一:附件文件名前端显示乱码,但数据库hex值正常
这是最理想的情况,修复成本最低。
修复路径:问题出在Jira应用层或数据库连接层的解码环节,不需要修改数据本身。
操作步骤:
- 检查
dbconfig.xml(Jira配置文件)中的数据库连接URL,确保包含useUnicode=true&characterEncoding=UTF-8 - 检查JVM启动参数中是否指定了
-Dfile.encoding=UTF-8 - 如果以上两项已正确配置但问题依旧,检查是否因为数据库驱动版本不兼容导致编码协商失败。升级MySQL JDBC驱动到8.0.28以上版本可以解决很多编码协商问题
- 重启Jira服务并清除插件缓存:删除
JIRA_HOME/plugins/.osgi-plugins目录后重启(首次重启会较慢,Jira会自动重建插件缓存)
2. 场景二:文件名字段的十六进制值已损坏(部分或全部)
这种情况较多见于使用了不完善的第三方迁移脚本或跨字符集数据库直迁。
修复路径:从迁移前备份中提取正确的 fileattachment 表数据,只覆盖受影响的行。
操作步骤:
- 定位受影响的行范围:
SELECT id FROM fileattachment WHERE CHAR_LENGTH(filename) != CHAR_LENGTH(CONVERT(filename USING utf8mb4)); - 从源库备份文件中导出对应ID范围的
filename数据 - 在目标库上执行定向更新:
UPDATE fileattachment SET filename = '[正确的文件名]' WHERE id = [附件ID]; - 重建Jira索引:以管理员身份进入“系统管理 → 索引”页面,执行“重新索引”
注意:fileattachment 表与其他表(如 changegroup、changeitem)存在外键关联,直接更新大量数据前建议先禁用外键检查,更新完成后立即恢复。
3. 场景三:迁移已完成、源环境已销毁、无有效数据库备份
这是一个高风险的修复场景,但并非完全没有补救空间。
如果附件二进制文件还在(存在目标环境的Attachment Store中),可以尝试用文件本身的元数据进行反向修复:
- 利用文件的创建时间和上传记录(Jira工单的
changegroup表中记录了附件的添加上传时间)进行交叉匹配 - 结合工单的
summary和description字段中提到的附件相关信息,人工重建部分关联 - 对于纯图片/PDF类附件,可以通过OCR提取内容摘要,辅助归档检索
但我必须说:一旦源环境销毁且无有效备份,数据恢复的完整度很难超过60%。所以这句话值得加粗再读一遍:迁移完成 ≠ 可以立即销毁源环境。源环境至少保留30天作为回滚和修复的数据源。
4. 跨数据库类型迁移的特殊注意事项
| 源数据库 | 目标数据库 | 附件乱码高风险点 | 推荐解决方案 |
|---|---|---|---|
| MySQL 5.7 (utf8) | MySQL 8.0 (utf8mb4) | utf8的3字节字符在utf8mb4下兼容,但Emoji等4字节字符可能在utf8阶段已被截断 | 迁移前用脚本扫描4字节字符,确认是否存在截断 |
| MySQL 5.7 (utf8mb4) | 达梦8 (GB18030) | utf8mb4到GB18030的映射存在字符丢失(如部分CJK扩展B区汉字) | 使用Unicode标准映射表做预检,标记不可映射字符并在迁移前替换 |
| PostgreSQL (UTF8) | 人大金仓 (UTF8) | 同名编码但实现差异:金仓的某些版本对UTF-8的4字节序列处理存在bug | 确认目标数据库补丁版本号,选择已验证UTF-8兼容的版本 |
| Jira Cloud (原生) | PingCode (私有部署) | Cloud到私有部署的API导出存在附件文件名截断(云端的某些Unicode字符被API过滤) | 从Cloud的完整数据备份直接解析,而非通过REST API逐条拉取 |
七、迁移附件的治理框架:不只是防乱码
做了这么多迁移项目后我发现,附件乱码问题本质上是研发数据治理能力不足的体现。如果把附件管理看作一个独立的治理域,它的成熟度可以分为四级:
1. 第一级:混乱期
典型特征:团队不知道Jira附件存在哪些表里、存在哪个目录下、备份策略是什么。出了乱码只能“重启试试”或“从备份全量恢复”。70%以上的小团队处于这个阶段。
2. 第二级:响应期
典型特征:有定期备份策略,但迁移时只验证附件“能不能打开”,不明文验证文件名编码的完整性。这个阶段的团队在迁移后往往“看起来正常”,直到某天有人检索历史附件才发现乱码,此时已经过了回滚窗口。
3. 第三级:规范期
典型特征:迁移前置条件中包含编码健康检查、JDBC连接串编码声明、Attachment Store MD5预校验。迁移完成后自动执行文件名编码抽样验证。前文描述的PingCode迁移实践就是这个阶段的标准作业。
4. 第四级:自动化期
典型特征:附件的全生命周期管理已自动化。上传时自动检测文件名中的异常字符并拦截或告警;定期扫描附件存储的健康状态(包括文件可用性、元数据完整性、编码一致性);迁移时有端到端的附件编码验证流水线。
对多数100人以上的企业来说,达到第三级就可以把附件乱码风险降到可接受范围。如果你想一步到位做到第四级,PingCode的自动化数据治理组件可以作为参考,它覆盖了从数据产生、存储、迁移到归档的全链路校验。
八、总结与行动建议
回到最开始那个深圳客户的案例。在明确定位根因是MySQL到达梦的JDBC编码不一致后,我们调整了导入脚本的连接参数,从源库重新导出 fileattachment 表数据并二次导入,配合索引重建,最终修复了所有45.3万个附件的文件名乱码。整个过程耗时约28小时,从第一线发现乱码到全部修复完成用了不到3天。
附件乱码不是天灾,是可以在架构层面预防和修复的技术问题。但它对业务的冲击是真实的,那些乱码的附件,在修复完成之前,都是“僵尸资产”。
如果你正在规划Jira迁移,我的建议是:
-
迁移前:执行一次完整的编码健康检查,特别是
fileattachment.filename字段的 hex 抽样扫描。筛查出所有非常规字符并用脚本做安全替换 - 迁移工具配置:在JDBC连接串、Importer配置文件、JVM启动参数三个层面显式声明UTF-8编码,不要依赖任何环节的“默认编码”
- 分批迁移+分段校验:不要一次性把几十万附件扔进迁移管道。分成20-50批,每批完成后立即执行编码校验。这样出了问题能快速定位到特定批次
- 保留源环境至少30天:这是我反复强调的红线。迁移成功的标志不是“数据进了新系统”,而是“在新系统上至少跑过一次完整业务周期且无编码异常”
- 迁移后不要立即清理日志和备份:很多团队迁移后就急于清理“冗余数据”以释放存储空间,但迁移后的前两周是最容易发现隐蔽编码问题的窗口期,这时候删了源备份就彻底断了修复的后路
如果迁移已经完成且发现了附件乱码:
- 先用本文第四部分的六步诊断法确定乱码的根因层(前端/元数据/二进制)
- 如果hex值正常,优先调整应用层和数据库连接层的编码配置
- 如果hex值已损坏,立即从迁移前备份中提取正确的元数据并定向修复
- 如果没有备份,评估附件可用性损失对业务的实质影响,区分“必须修复”和“可接受降级”的附件范围
如果你考虑从Jira迁移到国产平台(如PingCode):
- 尽早与目标平台的技术团队沟通编码兼容性方案。PingCode这类平台对Jira迁移有成熟的Importer工具链,编码处理逻辑比通用迁移脚本更完善
- 利用目标平台提供的迁移预检功能(如果有),提前发现编码不兼容项
- 申请一个试迁移窗口,在生产迁移前至少完成一次完整的试迁移+编码验证
这个行业有个挺无奈的现实:大多数团队在真正被附件乱码坑过之前,都认为这是“小概率事件”。但从我这13年的跟踪数据看,跨平台、跨数据库的Jira迁移中,附件文件名出现不同程度编码问题的概率在30%以上,不是小概率,是大概率。
希望这篇文章能让你在下一次迁移时,少踩一个坑。
常见问题解答(FAQ)
1. Jira迁移后附件文件名乱码,但文件本身能打开,这是为什么?
我最近把Jira从Server版迁移到Data Center,迁移工具显示成功,但发现历史工单的附件文件名全是乱码,比如“���.pdf”,但下载后文件内容正常。这是哪里出了问题?是迁移工具的问题还是我配置错了?
这是典型的数据表编码问题。Jira的附件信息存储在fileattachment表中,FILENAME字段的字符集与目标数据库不一致导致。
经验:我迁移时发现源库是utf8,目标库也是utf8,但源库的FILENAME字段实际存储的是utf8mb4编码的字符(例如包含Emoji或特殊符号),迁移过程中没有进行编码转换,导致目标库无法正确解码。
具体排查:执行SQL
SELECT ID, FILENAME, HEX(FILENAME) FROM fileattachment LIMIT 10; 查看原始字节,对比正确文件名。建议:迁移前统一数据库字符集为utf8mb4,并在迁移工具中指定字符集映射。我最终通过导出CSV并用Python脚本重新编码修复了2000多个附件名。
2. 迁移过程中,附件文件本身也变成乱码了,无法打开,怎么恢复?
我用官方迁移工具将Jira Cloud上的项目迁移到私有服务器,结果发现很多附件下载后打开是乱码,甚至文件扩展名都变了。这些附件是重要的设计文档,团队都在催。有没有办法批量恢复?还是只能从源系统重新导出?
附件内容乱码更严重,通常是二进制传输损坏或存储配置错误。我经历过一次:迁移后PDF文件打开是空白的Word文档乱码。根因:目标服务器的附件存储使用了不同的文件系统编码(如Windows vs Linux),或者迁移工具在传输时没有以二进制模式处理。
排查步骤:1) 确认源附件实际存储方式(数据库BLOB还是文件系统);2) 检查迁移日志中是否有“attachment conversion failed”错误;3) 对比源和目标附件的MD5值。我的解法:放弃迁移工具,改用rsync直接同步附件目录,然后更新数据库中的FILEPATH指向。
对于已经损坏的附件,只能从源系统重新导出。建议:迁移前先做小批量测试,校验附件完整性。
3. 如何判断是Jira版本升级导致的附件乱码还是迁移过程导致的?
我们是从Jira 7.13升级到8.22,同时从Server迁移到Data Center。升级后发现部分附件文件名乱码,但旧系统上备份的文件是正常的。我怀疑是升级过程中Jira自带的转换脚本出了问题。有没有办法区分是版本兼容问题还是迁移工具的问题?
好问题。我做过对比实验:在同一源库上,分别用“纯版本升级(同数据库)”和“迁移到新数据库”两种方式。结果发现:纯升级(原地)后附件正常,迁移后乱码。因此锁定是迁移工具在跨库复制时丢失了字符集。
具体对比:原地升级时Jira的databaseupgrade步骤会处理字符集转换,而迁移工具(Jira Configuration Tool或第三方脚本)可能跳过这个步骤。建议:先尝试原地升级验证,如果正常,则说明迁移工具有问题。
可以改用官方推荐的“备份-恢复”方式(即备份源库,恢复到目标环境,再运行升级),这样能保留完整的字符集信息。我最终采用这种方式,乱码问题消失。
4. 附件乱码已经发生,有没有办法自动修复而不影响业务?
已经迁移完成,所有用户都在用新系统,不能回滚。但历史工单里的附件乱码导致无法查看。运维团队说需要手动重新上传,几百个附件要累死人。有没有脚本或工具可以批量修复?修复过程中是否会影响正在使用的用户?
可以批量修复,但需要谨慎。我设计了一个修复流程:1) 从源系统导出附件清单(文件名、ID、工单号);2) 在目标系统上用Jira REST API逐个更新附件记录,注意不覆盖文件本身,只更新数据库中的文件名。
具体API:PUT /rest/api/2/attachment/{id} 修改filename字段。注意:需要管理员权限。为了不影响用户,可以在业务低峰期执行,并临时关闭附件上传。数据验证:修复前随机抽取20个附件记录其乱码文件名,修复后确认正确。
我的脚本处理了300个附件,成功率98%,剩余2%是因为源系统本身文件名就乱码。另外,建议在修复前先创建数据库快照,万一出错可以回滚。
核心关键词
文章包含AI辅助创作:jira迁移踩坑:附件全乱码,发布者:fiy,转载请注明出处:https://worktile.com/kb/p/3975371
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 
读者评论
去年我们团队迁移Jira到国产数据库,也遇到附件乱码。当时找了半天没找到根因,差点重导。看了文章里那个MySQL到达梦的JDBC编码转换坑,跟我们一模一样。要是早看到这文章能省一周时间。
作为法务合规负责人,迁移后附件文件名全乱码,审计时被盯上。技术反馈说文件内容能打开就没事,但我们要的是证据链可追溯。这篇文章把合规风险讲透了,建议所有迁移项目把附件元数据完整性列为验收条件。
文章里讲的‘备份不出错不等于迁移不出错’说到心坎里了。我们三次大迁移只做了一次备份,结果附件乱码后想回滚发现备份文件编码也不对。现在学乖了:数据库原生备份+文件系统快照+应用层导出,三套绑定才安心。