帮同事看一个CPU过高的问题
-
CPU涨了后掉不下去,最终同事排查出来是 某个依赖升级大版本后下线了默认的公共 redis 配置,(项目较老,很久没人动过)但需要业务方代码里自己配置关闭 redis服务。业务方有信息gap,所以不知道要关闭redis,导致上线后,一直在重试连接redis(多一个请求就多一次重试)
最终我们总结了排查思路,如下,欢迎补充
排查思路
0. 重启实例
部分问题,重启实例就能解决了。
先重启实例,这是必要做的一步,先让服务变得可用。如果后续CPU还是飙升过快,那么可能只能考虑先回滚代码了。飙升不快的话,可以不用回滚,尽快排查问题
1. linux shell 确定是否是node进程造成的
命令一: 较好
-
可以发现,主要是node进程在占用CPU。【相关教程推荐:nodejs视频教程】
[root@*** ~]# 较好PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 680 root 20 0 2290976 168176 34976 S 30.3 2.0 103:42.59 node 687 root 20 0 2290544 166920 34984 R 26.3 2.0 96:26.42 node 52 root 20 0 1057412 23972 15188 S 1.7 0.3 11:25.97 **** 185 root 20 0 130216 41432 25436 S 0.3 0.5 1:03.44 **** ...
命令二: vmstat
-
首先看一个vmstat 2 命令,表示每隔两秒钟采集一次
[root@*** ~]# vmstat 2procs -----------memory---------------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 233481328 758304 20795516 0 0 0 1 0 0 0 0 100 0 0 0 0 0 233480800 758304 20795520 0 0 0 0 951 1519 0 0 100 0 0 0 0 0 233481056 758304 20795520 0 0 0 0 867 1460 0 0 100 0 0 0 0 0 233481408 758304 20795520 0 0 0 20 910 1520 0 0 100 0 0 0 0 0 233481680 758304 20795520 0 0 0 0 911 1491 0 0 100 0 0 0 0 0 233481920 758304 20795520 0 0 0 0 889 1530 0 0 100 0 0
-
procs
r #表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和较好的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。较好的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b #表示阻塞的进程,在等待资源的进程,这个不多说,进程阻塞,大家懂的。
-
memory
swpd #虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free # 空闲的物理内存的大小
buff #Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存
cache #cache直接用来记忆我们打开的文件,给文件做缓冲,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。
-
swap
si #每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so #每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
-
io
bi #块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte
bo #块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
-
system
in #每秒CPU的中断次数,包括时间中断
cs #每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目
-
us #用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy #系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id #空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt #等待IO CPU时间。
-
实践
procs r: 运行的进程比较多,系统很繁忙
bi/bo: 磁盘写的数据量稍大,如果是大文件的写,10M以内基本不用担心,如果是小文件写2M以内基本正常
cpu us: 持续大于50%,服务高峰期可以接受, 如果长期大于50 ,可以考虑优化
cpu sy: 现实内核进程所占的百分比,这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
cpu wa: 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的, 也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)
参考链接: https://www.cnblogs.com/zsql/p/11643750.html
2. 看代码diff
重启实例还没解决,并且确定了是node进程的问题的话,
查看上线commit,检查一下代码diff,看看是否能找到问题点
3. 打运行时的CPU profiler
这个操作方法和我的另一篇如何快速定位ssr服务端内存泄漏问题 类似
-
用node –inspect起服务
-
本地模拟线上环境,用build后的代码,直接build可能会不能用,要控制好环境变量,并且丑化压缩要关掉
-
比如,让一些环境变量(CDN域名等)指向本地,因为打的包在本地,没上传到CDN
-
生成 CPU profiler


如果本地无法模拟出线上的环境?
比如下游RPC和本地就是有隔离,那就只能加代码,去打出profile了 nodejs.org/docs/latest…
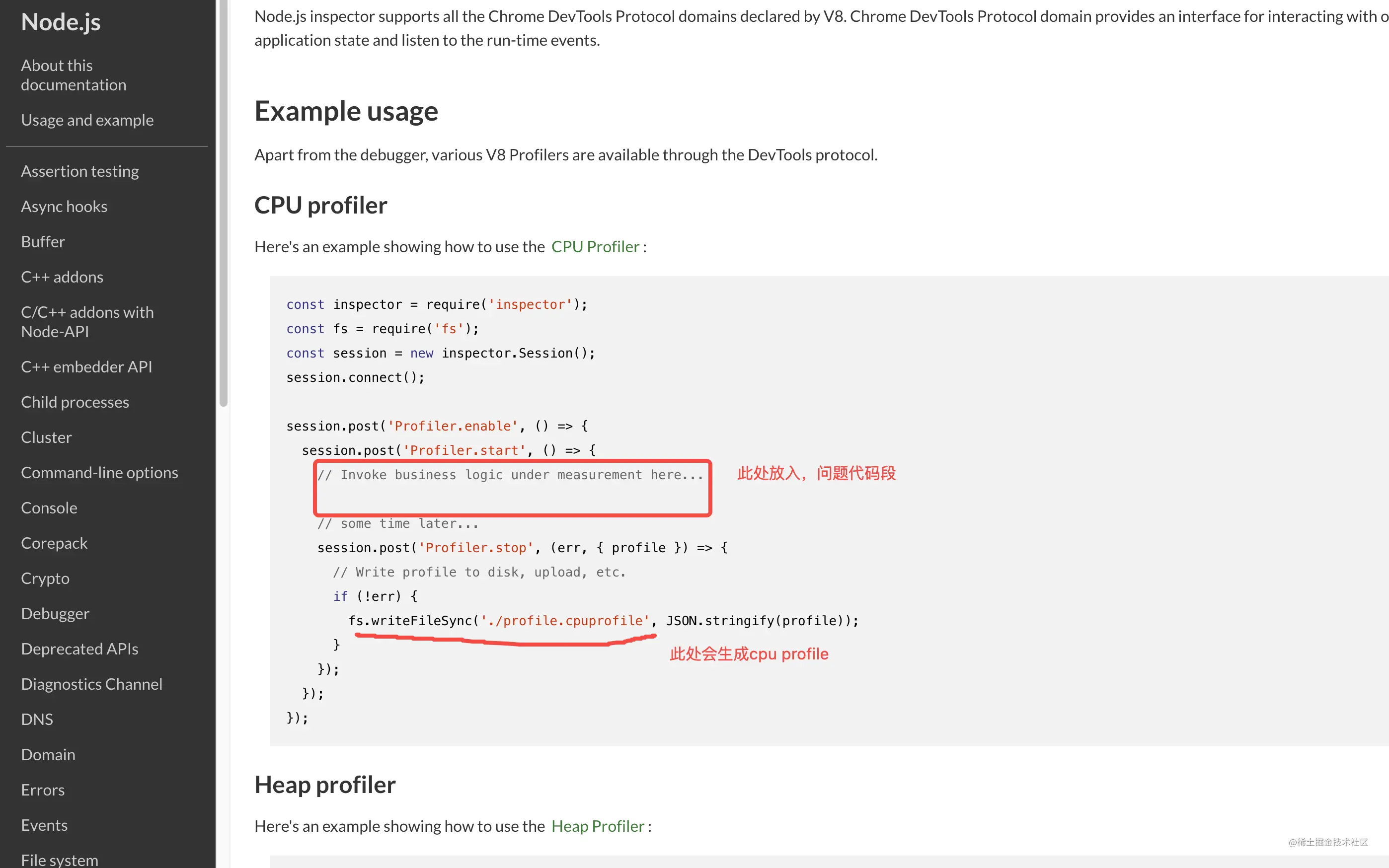
得到profile文件后,用chrome devtool打开
4. 分析 CPU profiler
-
结合 profiler 和 代码diff 去找原因
-
还可以把 profile 文件 上传到 www.speedscope.app/ (文件上传),就能得到cpu profile火焰图 (更详细的使用介绍:www.npmjs.com/package/spe…

5. 压测校验
可以用ab,或其他压测工具
总结
-
重启实例
-
确定是node进程导致的
-
看代码diff
-
生成运行时的CPU profiler
-
结合 profiler 和 代码diff 去找原因
-
压测校验
关于node服务CPU过高如何解决就分享到这里了,希望以上内容可以对大家有一定的参考价值,可以学以致用。如果喜欢本篇文章,不妨把它分享出去让更多的人看到。
文章包含AI辅助创作:node服务CPU过高如何解决,发布者:亿速云,转载请注明出处:https://worktile.com/kb/p/26088
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 