准备
为了方面后续的说明,我们首先建立一个如下的表(MySQL5.7),表中共有5个字段(a、b、c、d、e),其中a为主键,有一个由b,c,d组成的联合索引,存储引擎为InnoDB,插入三条测试数据。强烈建议自己在MySQL中尝试本文的所有语句。
CREATE TABLE `test` ( `a` int NOT NULL AUTO_INCREMENT, `b` int DEFAULT NULL, `c` int DEFAULT NULL, `d` int DEFAULT NULL, `e` int DEFAULT NULL, PRIMARY KEY(`a`), KEY `idx_abc` (`b`,`c`,`d`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (1, 2, 3, 4, 5);INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (2, 2, 3, 4, 5);INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (3, 2, 3, 4, 5);
这时候,我们如果执行下面这个SQL语句,你觉得会走索引吗?
SELECT b, c, d FROM test WHERE d = 2;
如果你按照最左匹配原则(简述为在联合索引中,从最左边的字段开始匹配,若条件中字段在联合索引中符合从左到右的顺序则走索引,否则不走,可以简单理解为(a, b, c)的联合索引相当于创建了a索引、(a, b)索引和(a, b, c)索引),这句显然是不符合这个规则的,它走不了索引,但是我们用EXPLAIN语句分析,会发现一个很有趣的现象,它的输出如下是使用了索引的。

这就很奇怪了,最左匹配原则失效了吗?事实上,并没有,我们一步步来分析。
理论详解
由于现在基本上以InnoDB引擎为主,我们以InnoDB为例进行主要说明。
聚集索引和非聚集索引
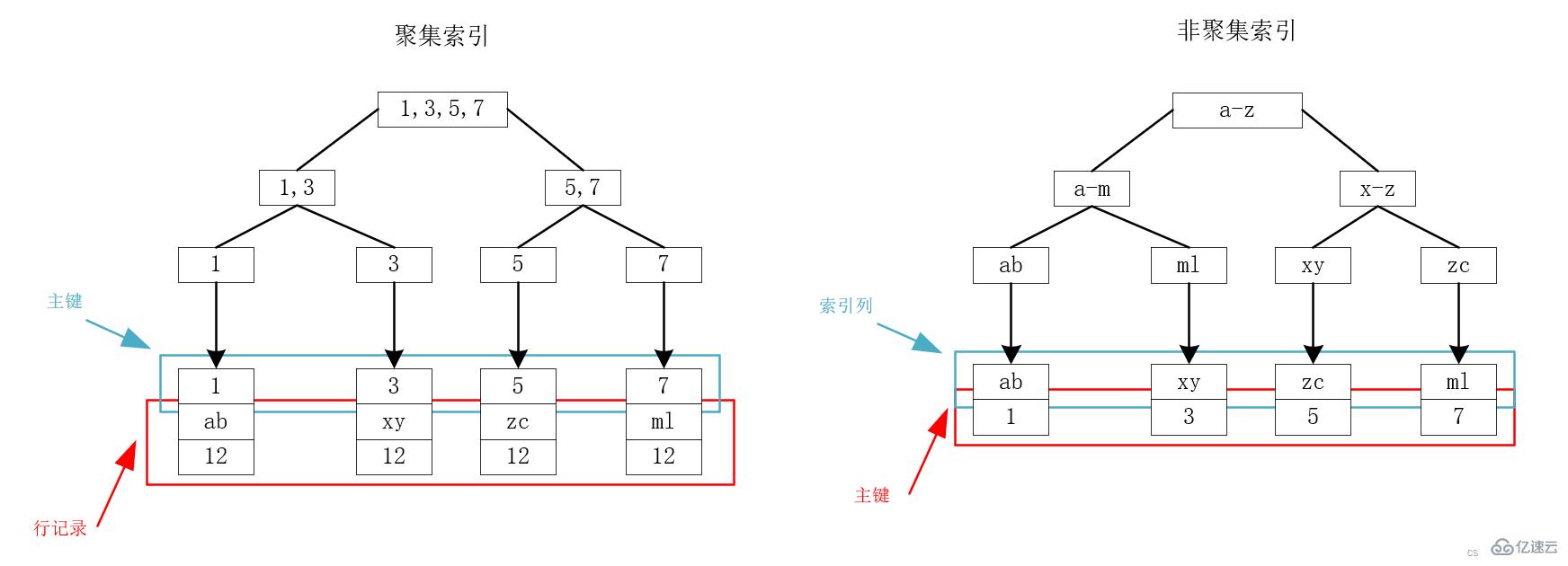
MySQL底层使用B+树来存储索引,数据均存在叶子节点上。对于InnoDB而言,主键索引和行记录时存储在一起的,因此叫做聚集索引(clustered index)。除了聚集索引,其他所有都叫做非聚集索引(secondary index),包括普通索引、少数索引等。
在InnoDB中,只存在一个聚集索引:
-
若表存在主键,则主键索引就是聚集索引;
-
若表不存在主键,则会把名列前茅个非空的少数索引作为聚集索引;
-
否则,会隐式定义一个rowid作为聚集索引。
我们以下图为例,假设现在有一个表,存在id、name、age三个字段,其中id为主键,因此id为聚集索引,name建立索引为非聚集索引。关于id和name的索引,有如下的B+树,可以看到,聚集索引的叶子节点存储的是主键和行记录,非聚集索引的叶子节点存储的是主键。
回表查询
从上面的索引存储结构来看,我们可以看到,在主键索引树上,通过主键就可以一次性查出我们所需要的数据,速度很快。这很直观,因为主键就和行记录存储在一起,定位到了主键就定位到了所要找的包含所有字段的记录。
但是对于非聚集索引,如上面的右图,我们可以看到,需要先根据name所在的索引树找到对应主键,然后通过主键索引树查询到所要的记录,这个过程叫做回表查询。
索引覆盖
上面的回表查询无疑会降低查询的效率,那么有没有办法让它不回表呢?这就是索引覆盖。所谓索引覆盖,就是说,在使用这个索引查询时,使它的索引树的叶子节点上的数据可以覆盖你查询的所有字段,就可以避免回表了。我们回到一开始的例子,我们建立的(b,c,d)的联合索引,因此当我们查询的字段在b、c、d中的时候,就不会回表,只需要查看一次索引树,这就是索引覆盖。
最左匹配原则
指的是联合索引中,优先走最左边列的索引。对于多个字段的联合索引,也同理。如 index(a,b,c) 联合索引,则相当于创建了 a 单列索引,(a,b)联合索引,和(a,b,c)联合索引。
我们可以执行下面的几条语句验证一下这个原则。
EXPLAIN SELECT * FROM test WHERE b = 1;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2 and d = 3;

接着,我们尝试一条不符合最左原则的查询,它也如图预期一样,走了全表扫描。
EXPLAIN SELECT * FROM test WHERE d = 3;

详细规则
我们先来看下面两个语句,他们的输出如下。
EXPLAIN SELECT b, c from test WHERE b = 1 and c = 1;EXPLAIN SELECT b, d from test WHERE d = 1;
id|select_type|table|partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra |--+-----------+-----+----------+----+-------------+-------+-------+-----------+----+--------+-----------+ 1|SIMPLE |test | |ref |idx_bcd |idx_bcd|10 |const,const| 1| 100.0|Using index|id|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra |--+-----------+-----+----------+-----+-------------+-------+-------+---+----+--------+------------------------+ 1|SIMPLE |test | |index|idx_bcd |idx_bcd|15 | | 3| 33.33|Using where; Using index|
显然名列前茅条语句是符合最左匹配的,因此type为ref,但是第二条并不符合最左匹配,但是也不是全表扫描,这是因为此时这表示扫描整个索引树。
具体来看,index 代表的是会对整个索引树进行扫描,如例子中的,列 d,就会导致扫描整个索引树。ref 代表 mysql 会根据特定的算法查找索引,这样的效率比 index 全扫描要高一些。但是,它对索引结构有一定的要求,索引字段必须是有序的。而联合索引就符合这样的要求,联合索引内部就是有序的,你可以理解为order by b,c,d这种排序规则,先根据字段b排序,再根据字段c排序,以此类推。这也解释了,为什么需要遵守最左匹配原则,当最左列有序才能保证右边的索引列有序。
因此,我们总结最后的原则为,若符合最左覆盖原则,则走ref这种索引;若不符合最左匹配原则,但是符合覆盖索引(index),就可以扫描整个索引树,从而找到覆盖索引对应的列,避免回表;若不符合最左匹配原则,也不符合覆盖索引(如本例的select *),则需要扫描整个索引树,并且回表查询行记录,此时,查询优化器认为这样两次查找索引树,还不如全表扫描来得快(因为联合索引此时不符合最左匹配原则,要不普通索引查询慢得多),因此,此时会走全表扫描。
补充:为什么要使用联合索引
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
“MySQL索引最左匹配原则是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
文章包含AI辅助创作:MySQL索引最左匹配原则是什么,发布者:亿速云,转载请注明出处:https://worktile.com/kb/p/24047
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 