分页查询的优化方式:1、子查询优化,可通过把分页的SQL语句改写成子查询的方法获得性能上的提升。2、id限定优化,可以根据查询的页数和查询的记录数计算出查询的id的范围,然后根据“id between and”语句来查询。3、基于索引再排序进行优化,通过索引去找相关的数据地址,避免全表扫描。4、延迟关联优化,可以使用JOIN,先在索引列上完成分页操作,然后再回表获取所需要的列。
本教程操作环境:windows7系统、mysql8版本、Dell G3电脑。
分页查询的效率在数据量大的时候尤为重要,影响到前端响应和用户体验。
分页查询的优化方式
1、使用子查询优化
这种方式先定位偏移位置的 id,然后往后查询,这种方式适用于 id 递增的情况。
子查询优化原理:https://www.jianshu.com/p/0768ebc4e28d
select * from sbtest1 where k=504878 limit 100000,5;的查询过程:
首先会查询到索引叶子节点数据,然后根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。像下图左边这样,需要查询100005次索引节点,查询100005次聚簇索引的数据,最后再将结果过滤掉前100000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有100000次随机I/O查询到的数据是不会出现在结果集当中的。
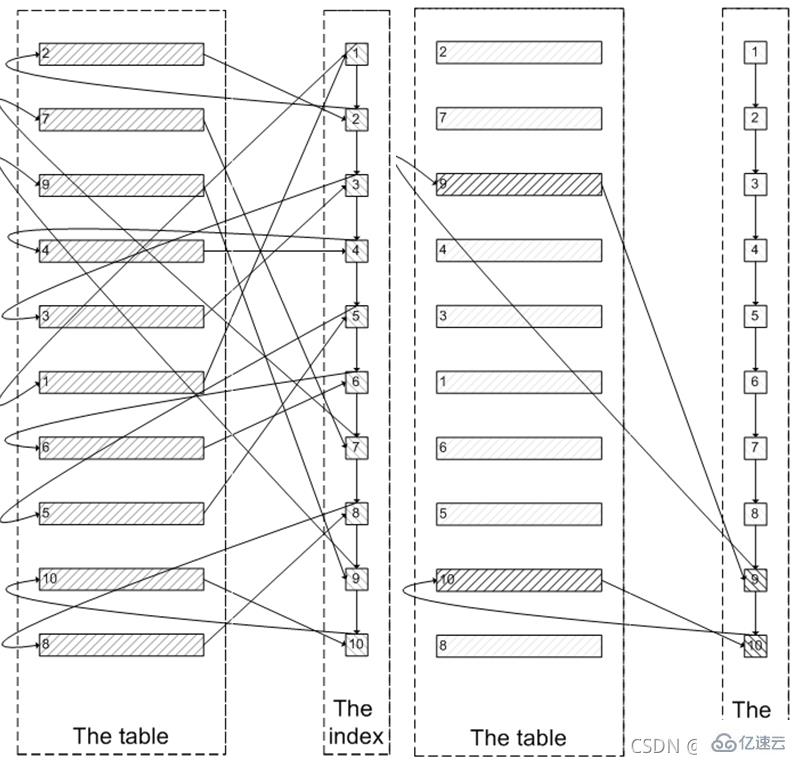

既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于上图右边的过程。这就是子查询优化,这种方式先定位偏移位置的id,然后往后查询,这种方式适用于id递增的情况。如下所示:
mysql> select * from sbtest1 where k=5020952 limit 50,1;mysql> select id from sbtest1 where k=5020952 limit 50,1;mysql> select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10;mysql> select * from sbtest1 where k=5020952 limit 50,10;
在子查询优化中,谓词中k是否有索引,对查询效率有很大影响,上述语句没有使用索引走全表扫描需要24.2s,走了索引后只需要0.67s。
mysql> explain select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10;+----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+| 1 | PRIMARY | sbtest1 | NULL | index_merge | PRIMARY,c1 | c1,PRIMARY | 8,4 | NULL | 19 | 100.00 | Using intersect(c1,PRIMARY); Using where || 2 | SUBQUERY | sbtest1 | NULL | ref | c1 | c1 | 4 | const | 88 | 100.00 | Using index |+----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+2 rows in set, 1 warning (0.11 sec)
但是这种优化方法也有局限性:
-
这种写法,要求主键ID必须是连续的
-
Where子句不允许再添加其他条件
2、使用id限定优化
这种方式假设数据表的id是连续递增的,则我们根据查询的页数和查询的记录数可以算出查询的id的范围,可以使用 id between and 来查询。
假设数据库中表的id是连续递增的,则可以根据查询的页数和查询的记录数计算出查询的id的范围,然后根据id between and语句来查询。id的范围可以通过分页公式计算得到,比如说当前页面大小为m,当前页数为no1,则页面最大值为max=(no1+1)m-1,最小值为min=no1m,SQL语句可以表示为id between min and max。
select * from sbtest1 where id between 1000000 and 1000100 limit 100;
这种查询方式能够极大地优化查询速度,基本能够在几十毫秒之内完成。限制是需要明确知道id的情况,不过一般在分页查询的业务表中,都会添加基本的id字段,这为分页查询带来很多便利。上述SQL还有另一种写法:
select * from sbtest1 where id >= 1000001 limit 100;
可以看到执行时间上的差异:
mysql> show profiles;+----------+------------+--------------------------------------------------------------------------------------------------------------+| Query_ID | Duration | Query |+----------+------------+--------------------------------------------------------------------------------------------------------------+| 6 | 0.00085500 | select * from sbtest1 where id between 1000000 and 1000100 limit 100 || 7 | 0.12927975 | select * from sbtest1 where id >= 1000001 limit 100 |+----------+------------+--------------------------------------------------------------------------------------------------------------+
还可以使用in的方式来进行查询,这种方式经常用在多表关联的时候进行查询,使用其他表查询的id集合,来进行查询:
select * from sbtest1 where id in (select id from sbtest2 where k=504878) limit 100;
使用in查询的方式要注意某些mysql版本不支持在in子句中使用limit。
3、基于索引再排序来优化
基于索引再排序是利用索引查询中有优化算法,通过索引再去找相关的数据地址,避免全表扫描,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存效果会更好。在MySQL中可以使用如下语句:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
这种方法适用于数据量多的情况(元组数上万),较好ORDER BY后的列对象是主键或少数索引,使得ORDER BY操作能利用索引被消除但结果集是稳定的。比如下面两个语句:
mysql> show profiles;+----------+------------+--------------------------------------------------------------------------------------------------------------+| Query_ID | Duration | Query |+----------+------------+--------------------------------------------------------------------------------------------------------------+| 8 | 3.30585150 | select * from sbtest1 limit 1000000,10 || 9 | 1.03224725 | select * from sbtest1 order by id limit 1000000,10 |+----------+------------+--------------------------------------------------------------------------------------------------------------+
对索引字段id使用order by语句后,性能有了明显的提升。
4、使用延迟关联来优化
和上述的子查询做法类似,我们可以使用JOIN,先在索引列上完成分页操作,然后再回表获取所需要的列。
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id;
从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
5、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
select * from t5 where id>=1000000 limit 10;

6、使用临时表优化
使用临时存储的表来记录分页的id然后进行in查询
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
关于“mysql分页查询如何优化”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“mysql分页查询如何优化”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
文章包含AI辅助创作:mysql分页查询如何优化,发布者:亿速云,转载请注明出处:https://worktile.com/kb/p/29520
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 